MongoDB高可用模式部署
首先准备机器,我这里是在公司云平台创建了三台DB server,ip分别是10.199.144.84,10.199.144.89,10.199.144.90。
分别安装mongodb最新稳定版本:
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-2.4.12.tgz
tar -xzvf mongodb-linux-x86_64-2.4.12.tgz
mv mongodb-linux-x86_64-2.4.12 /usr/lib
做个软连接或者按照官方的做法把mongo shell都添加到环境变量:
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongo /usr/bin/mongo
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongos /usr/bin/mongos
ln -s /usr/lib/mongodb-linux-x86_64-2.4.12/bin/mongod /usr/bin/mongod
分别创建存储数据的目录:
mkdir -p /data/mongodb && cd /data/mongodb/ && mkdir -p conf/data conf/log mongos/log shard{1..3}/data shard{1..3}/log
分别配置启动config服务器:
mongod --configsvr --dbpath /data/mongodb/conf/data --port 27100 --logpath /data/mongodb/conf/confdb.log --fork --directoryperdb
确保config服务都启动之后,启动路由服务器(mongos):
mongos --configdb 10.199.144.84:27100,10.199.144.89:27100,10.199.144.90:27100 --port 27000 --logpath /data/mongodb/mongos/mongos.log --fork
分别配置启动各个分片副本集,这里副本集名分别叫shard1,shard2,shard3:
mongod --shardsvr --replSet shard1 --port 27001 --dbpath /data/mongodb/shard1/data --logpath /data/mongodb/shard1/log/shard1.log --directoryperdb --fork mongod --shardsvr --replSet shard2 --port 27002 --dbpath /data/mongodb/shard2/data --logpath /data/mongodb/shard2/log/shard2.log --directoryperdb --fork mongod --shardsvr --replSet shard3 --port 27003 --dbpath /data/mongodb/shard3/data --logpath /data/mongodb/shard3/log/shard3.log --directoryperdb --fork
接下来配置副本集,假设使用如下的架构,每台物理机都有一个主节点,一个副本节点和一个仲裁节点: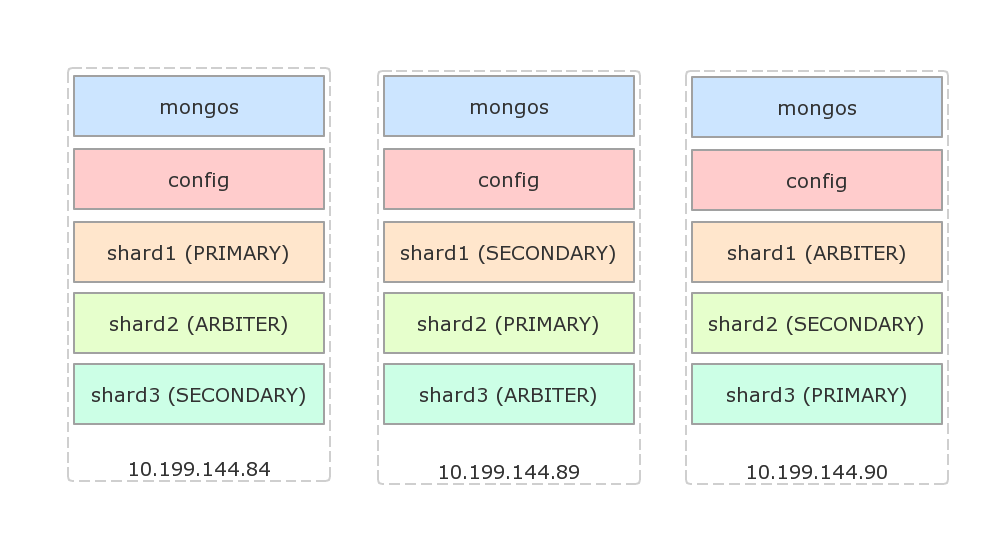
配置shard1(登陆84,没有显式指定主节点时,会选择登陆的机器为主节点):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard1',
members: [
{_id: 84, host: '10.199.144.84:27001'},
{_id: 89, host: '10.199.144.89:27001'},
{_id: 90, host: '10.199.144.90:27001', arbiterOnly: true}
]
});
配置shard2(登陆89):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard2',
members: [
{_id: 84, host: '10.199.144.84:27002', arbiterOnly: true},
{_id: 89, host: '10.199.144.89:27002'},
{_id: 90, host: '10.199.144.90:27002'}
]
});
配置shard3(登陆90):
mongo --port 27001
use admin
rs.initiate({
_id: 'shard3',
members: [
{_id: 84, host: '10.199.144.84:27002'},
{_id: 89, host: '10.199.144.89:27002', arbiterOnly: true},
{_id: 90, host: '10.199.144.90:27002'}
]
});
下面设置路由到分片集群配置,随便登陆一台机器,假设是84:
mongo --port 27000
use admin
db.runCommand({addShard: 'shard1/10.199.144.84:27001,10.199.144.89:27001,10.199.144.90:27001'});
db.runCommand({addShard: 'shard2/10.199.144.84:27002,10.199.144.89:27002,10.199.144.90:27002'});
db.runCommand({addShard: 'shard3/10.199.144.84:27003,10.199.144.89:27003,10.199.144.90:27003'});
查看配置好的shard:
mongo --port 27000
use admin
db.runCommand({listshards: 1});
结果:
{
"shards" : [
{
"_id" : "shard1",
"host" : "shard1/10.199.144.84:27001,10.199.144.89:27001"
},
{
"_id" : "shard2",
"host" : "shard2/10.199.144.89:27002,10.199.144.90:27002"
},
{
"_id" : "shard3",
"host" : "shard3/10.199.144.90:27003,10.199.144.84:27003"
}
],
"ok" : 1
}
其中仲裁(ARBITER)节点没有列出来。
下面测试分片:
mongo --port 27000
use admin
db.runCommand({enablesharding: 'dbtest'});
db.runCommand({shardcollection: 'dbtest.coll1', key: {id: 1}});
use dbtest;
for(var i=0; i<10000; i++) db.coll1.insert({id: i, s: 'str_' + i});
如果dbtest已经存在,需要确保它已经以id建立了索引!
过上一段时间之后,运行db.coll1.stats()显式分片状态:
{
"sharded" : true,
"ns" : "dbtest.coll1",
"count" : 10000,
...
"shards" : {
"shard1" : {
"ns" : "dbtest.coll1",
"count" : 0,
"size" : 0,
...
},
"shard2" : {
"ns" : "dbtest.coll1",
"count" : 10000,
"size" : 559200,
...
}
}
...
}
可以看到,这里分片已经生效,只是分配不均匀,所有的数据都存在了shard2中了。分片key的选择策略可以参考官方文档。在2.4版本中,使用hashed shard key算法保证文档均匀分布:
mongo --port 27000
use admin
sh.shardCollection('dbtest.coll1', {id: 'hashed'});
使用hashed算法之后,做同样的测试,插入的数据基本均匀分布:
{
"sharded" : true,
"ns" : "dbtest.coll1",
"count" : 10000,
...
"shards" : {
"shard1" : {
"ns" : "dbtest.coll1",
"count" : 3285,
"size" : 183672,
...
},
"shard2" : {
"ns" : "dbtest.coll1",
"count" : 3349,
"size" : 187360,
...
},
"shard3" : {
"ns" : "dbtest.coll1",
"count" : 3366,
"size" : 188168,
...
}
}
}
更多资料,请参考MongoDB Sharding。
在应用程序里,使用MongoClient创建db连接:
MongoClient.connect('mongodb://10.199.144.84:27000,10.199.144.89:27000,10.199.144.90:27000/dbtest?w=1', function(err, db) {
;
});
MongoDB高可用模式部署的更多相关文章
- hadoop和hbase高可用模式部署
记录apache版本的hadoop和hbase的安装,并启用高可用模式. 1. 主机环境 我这里使用的操作系统是centos 6.5,安装在vmware上,共三台. 主机名 IP 操作系统 用户名 安 ...
- CentOS6下OpenLDAP+PhpLdapAdmin基本安装及主从/主主高可用模式部署记录
下面测试的部署机ip地址为:192.168.10.2051)yum安装OpenLDAP [root@openldap-server ~]# yum install openldap openldap- ...
- Haproxy+Keepalived高可用环境部署梳理(主主和主从模式)
Nginx.LVS.HAProxy 是目前使用最广泛的三种负载均衡软件,本人都在多个项目中实施过,通常会结合Keepalive做健康检查,实现故障转移的高可用功能. 1)在四层(tcp)实现负载均衡的 ...
- LVS+Keepalived 高可用环境部署记录(主主和主从模式)
之前的文章介绍了LVS负载均衡-基础知识梳理, 下面记录下LVS+Keepalived高可用环境部署梳理(主主和主从模式)的操作流程: 一.LVS+Keepalived主从热备的高可用环境部署 1)环 ...
- openstack pike 集群高可用 安装 部署 目录汇总
# openstack pike 集群高可用 安装部署#安装环境 centos 7 史上最详细的openstack pike版 部署文档欢迎经验分享,欢迎笔记分享欢迎留言,或加QQ群663105353 ...
- MongoDB 高可用集群副本集+分片搭建
MongoDB 高可用集群搭建 一.架构概况 192.168.150.129192.168.150.130192.168.150.131 参考文档:https://www.cnblogs.com/va ...
- MogoDB(6)--mongoDB高可用和4.0特性
5.1.MongoDB 用户管理 1.用户管理1.1.添加用户为 testdb 添加 tom 用户 use testdb db.createUser({user:"tom",pwd ...
- MongoDB 高可用集群架构简介
在大数据的时代,传统的关系型数据库要能更高的服务必须要解决高并发读写.海量数据高效存储.高可扩展性和高可用性这些难题.不过就是因为这些问题Nosql诞生了. 转载自严澜的博文——<如何搭建高效的 ...
- gitlab高可用模式
高可用模式 企业版 社区版 我们这里说一下成本比较低的主备模式,它主要依赖的是DRBD方式进行数据同步,需要2台ALL IN ONE的GitLab服务器,也就是通过上面安装方式把所有组件都安装在一起的 ...
随机推荐
- js将map转换成数组
/** * map转数组. * * @param {Map}map * map对象 * @return 数组 */ Share.map2Ary = function(map) { var list = ...
- HDU 5795 A Simple Nim (博弈) ---2016杭电多校联合第六场
A Simple Nim Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Tota ...
- VS2010中“工具>选项中的VC++目录编辑功能已被否决”解决方法
转自:http://blog.csdn.net/chaijunkun/article/details/6658923 这是VS2010的改变,不能够在“工具-选项”中看到“VC++目录”了. 但是呢, ...
- Adaboost算法结合Haar-like特征
Adaboost算法结合Haar-like特征 一.Haar-like特征 目前通常使用的Haar-like特征主要包括Paul Viola和Michal Jones在人脸检测中使用的由Papageo ...
- Stanford大学机器学习公开课(五):生成学习算法、高斯判别、朴素贝叶斯
(一)生成学习算法 在线性回归和Logistic回归这种类型的学习算法中我们探讨的模型都是p(y|x;θ),即给定x的情况探讨y的条件概率分布.如二分类问题,不管是感知器算法还是逻辑回归算法,都是在解 ...
- linux下安装pymssql
WIN下安装PYMSSQL,由于我没有系统管理权限,无法安装, 那只好在LINUX下面安装罗.. 以下这个文章帮助我搞定. http://blog.csdn.net/five3/article/det ...
- hdu 4666:Hyperspace(最远曼哈顿距离 + STL使用)
Hyperspace Time Limit: 20000/10000 MS (Java/Others) Memory Limit: 65535/65535 K (Java/Others)Tota ...
- hdu 4622 **
题意:Suppose there are the symbols M, I, and U which can be combined to produce strings of symbols cal ...
- (三)WebRTC手记之本地视频采集
转自:http://www.cnblogs.com/fangkm/p/4374610.html 前面两篇文章介绍WebRTC的运行流程和使用框架接口,接下来就开始分析本地音视频的采集流程.由于篇幅较大 ...
- jsp放在web-inf下的注意事项
转自:http://dejazhan.iteye.com/blog/1708785 web-inf目录是不对外开放的,外部没办法直接访问到(即不能通过URL访问).所有只能通过映射来访问,比如映射为一 ...