SQLServer学习笔记<>.基础知识,一些基本命令,单表查询(null top用法,with ties附加属性,over开窗函数),排名函数
Sqlserver基础知识
(1)创建数据库
创建数据库有两种方式,手动创建和编写sql脚本创建,在这里我采用脚本的方式创建一个名称为TSQLFundamentals2008的数据库。脚本如下:
同时往数据库表插入一些数据,用户后续对数据库的sql的练习。在这里有需要的可以下载相应的脚本进行数据库的初始化。我放到百度云上面,请戳
我:http://yun.baidu.com/share/link?shareid=3635107613&uk=2971209779,提供了《Sqlserver2008技术内幕》这本书的电子版和脚本。
(2)在这里对TSQLFundamentals2008数据各个表进行表说明一下:
数据库表界面如下:
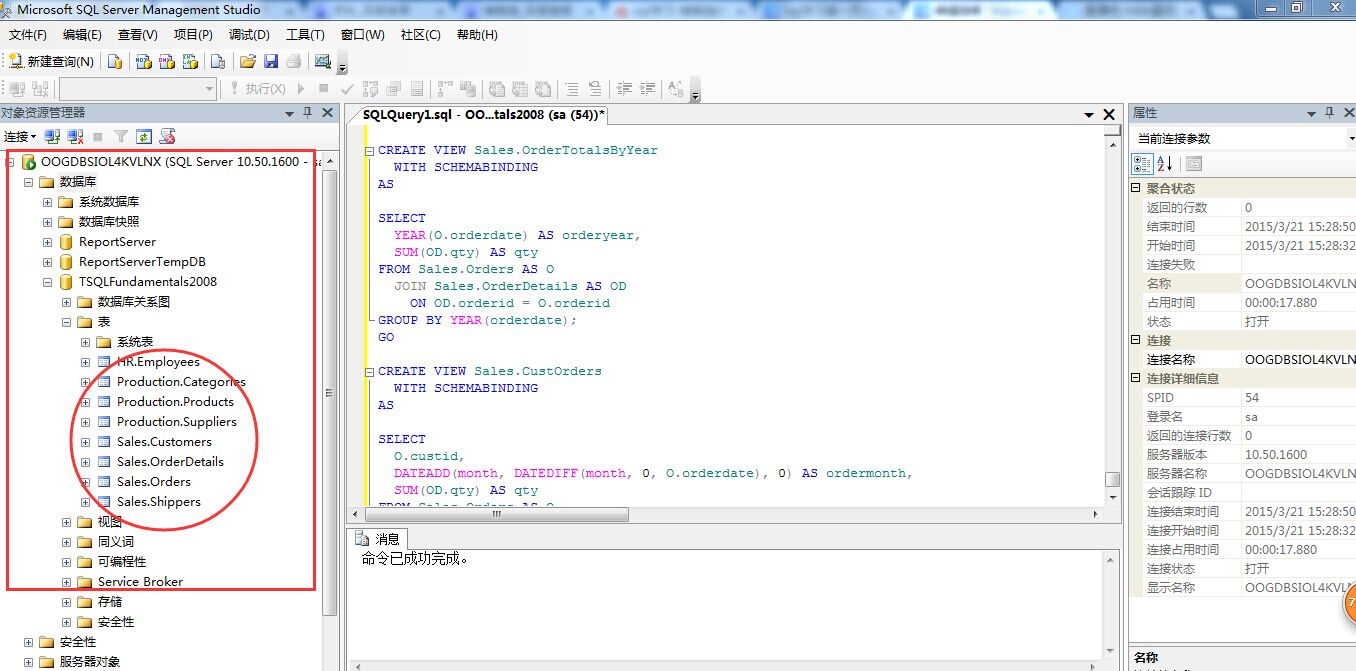
|
HR.Employees |
雇员表,存放员工的一些基本信息。 |
|
Production.Products |
产品信息表 |
|
Production.Suppliers |
供应商表 |
|
Production.Customers |
顾客信息表 |
|
Production.Categories |
产品类别表 |
|
Sales.OrderDetails |
订单详情表 |
|
Sales.Orders |
订单表 |
|
Sales.Shippers |
货运公司表 |
Sqlserver一些基本命令:
查询数据库是否存在:
if DB_ID("testDB")is not null;
检查表是否存在:
if OBJECT_ID(“textDB”,“U”) is not null ;其中U代表用户表
创建数据库:
create database+数据名
删除数据库:
drop database 数据库名 --删除数据库的
drop table 表名--删除表的
delete from 表名 where 条件 --删除数据的
查询语句:
use 数据库名称 --修改的数据库
select*from +表名称 --要查询的表
select某某,某某,某某 from 表名称 where 条件 --带条件查询的数据
插入数据:
insert into 表名称 (条件)values (相对应的值)
单表查询
(1)分组--对于分组查询,select字句会有限制,需要查询字段要出现在group by 子句中,同时分组以后,可以对分组情况进行统计。
查询雇员表,根据雇员所在国家分组,统计每组的人数情况:
1 select country,count(*) as N'人数'
2 from hr.Employees
3 group by country
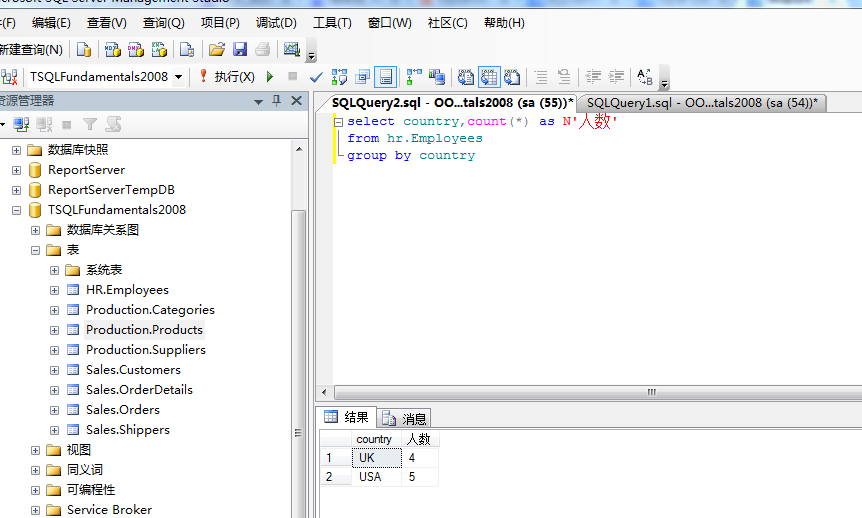
当要查询的字段不包含在group by子句中,则会报相应的错误,所以此时要注意出现在select 后面的查询字段进行分组后,也同时需要出现在group by后面。

(2)在这里提示一下:查询条件不要使用计算列,下面谈谈具体原因:
例如:查询雇员表里面雇员出生为1973年的所有雇员信息,可以这样编写sql语句:
1 select YEAR(birthdate),firstname,lastname from HR.Employees
2 where YEAR(birthdate)='1973'

可以看到查询结果将1973年的雇员信息查出来了,但是大家可以思考一下,上面的sql语句在查询的时候,首先是要讲birthdate进行取出年度的计算,
Year(birthdate),其中Year为sql的内置函数,可以用于对字符串日期进行取出年份的计算。同时我们还可以采用下面的sql语句进行查询:

通过sql执行计划可以看出来,查询条件带计算列走的是索引扫描,而where子句后面采用查找范围限制,则走的是索查找。对比两个查询显然绝大部分情况下
走索引查找的查询性能要高于走索引扫描,特别是查询的数据库不是非常大的情况下,索引查找的消耗时间要远远少于索引扫描的时间。所以在查询条件中尽
量避免计算条件。
(3)说说sqlserver中的null,null在数据库中表示不存在,与C#中的null不同,不表示空引用,没有对象,NULL的运算规则:有null的任何运算都是null。
is [not] null: 只能用做条件判断表达式,是否是null?是 条件为true,不是 条件为false。
isnull():函数,如果第一个参数是null,则用第二个参数的值替换第一个参数的值作为函数的返回值。记住:第二个参数的类型必须和第一个兼容。
nullif():函数,如果两个参数值相等、有一个参数是null、或两个参数是null,函数返回值是null;否则返回第一个参数的值。
(4)top用法:意在取出表中满足条件的前多少位。top 10---前10位
说到top,突然想到了面试题中经常出现的查询某表中的前30—40条记录,注意id可能不连续。利用top可以这样写:
1 select top 10 * from A where ID
2 not in(select top 30 ID from A order by ID asc)
3 order by ID asc
同时也可以采用如下写法,只不过可读性比较差:
1 select top 10 * fron A where ID>
2 (select Max(ID) from (select top 30 ID from A order by ID)as t)
3 order by ID asc
当然既然有范围in存在,就可以用exist实现:
1 select top 10 * from A a1
2 WHERE NOT EXISTS
3 (SELECT * from
4 (SELECT TOP 30 * FROM A ORDER BY id asc) a2
5 WHERE a2.id =a1.id
6 )
但是目前需要考虑到----相关子查询:主查询每遍历一条记录时,都要针对主查询的值执行子查询,所以效率比较低。
下面介绍一下top与percent联合使用,percent表示所占的百分比:例如查询雇员表里面,前面百分之二十的雇员的信息,可以写sql,查询结果为两人。
1 select top(20) percent * from hr.employees

我们在查询一下hr.employees(雇员表),同时查询一下雇员表里面总共有多少人,查出结果显示有9人。
1 select count(*) as N'总人数' from hr.employees
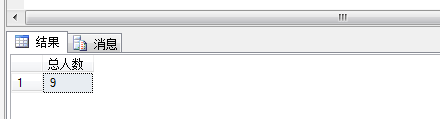
可以看出,9个人按百分之二十取整数了,所以查出来的显示有两个人。
(5)with ties附加属性:
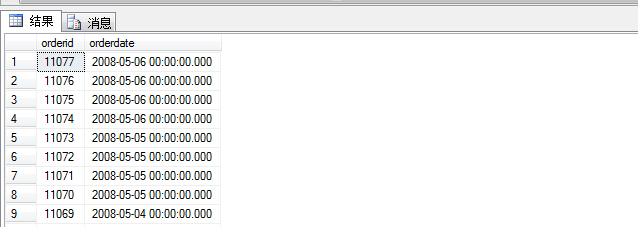
当我们查询订单表时,查询sql:
1 select orderid,orderdate
2 from sales.orders order by orderdate desc
加入我们查询前五个订单信息时候,加入top 5
1 select top 5 orderid,orderdate
2 from sales.orders order by orderdate desc
查询结果如图:
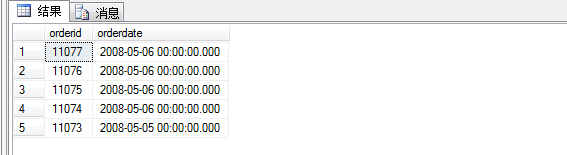
对比没有加top 5,查询结果截取了前五条订单信息,但是有时候我们需要将与最后一条订单日期相同的一起取出来,此时就需要采用附加属性with ties。

(6)over开窗函数:
上面讲到要用count聚合函数,在需要分组求和。但采用over 则可以同样实现基于什么的求和。省去group by。
1 select firstname,lastname ,count(*) over() as N'总人数'
2 from hr.employees
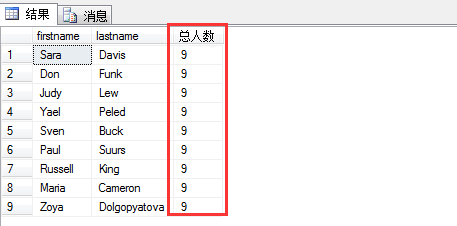
其中over(),括号里面可以附加条件,基于什么进行汇总。不添加,则表示对所有的记录进行汇总。例如求每位顾客所消费的订单总额,可以这样写:
1 select orderid,custid,sum(val) over (partition by custid) as N'顾客消费总额',
2 sum(val) over() as N'订单总额' from sales.ordervalues

五.排名函数
(1)row_number,行号,一般与over联合使用。over基于什么排名。
1 select row_number() over(order by lastname) as N'行号', lastname,firstname
2 from hr.employees
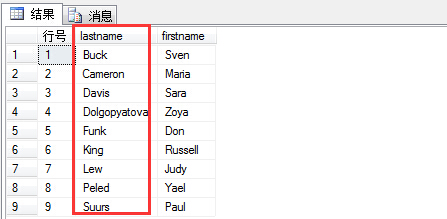
(2)rank ,排名,真正意义上的排名,例如:
1 select country,row_number() over(order by country) as N'rank排名', lastname,firstname
2 from hr.employees
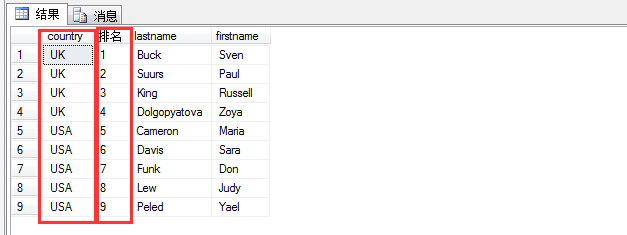
可以看出,根据country排名,确实排出来啦,但是发现前四位同为UK,按理来说使部分先后顺序的,所以在此可以用rank来操作。
1 select country,rank() over(order by country) as N'rank排名', lastname,firstname
2 from hr.employees

可以看出来,使用rank以后,country同为UK的并列第一,类似于学生考试成绩排名并列第一的情况。
(3)dense_rank,密集排名
通过上面rank排名以后,存在并列第一的情况,但是country为USA的应该为第二,所以就出现了使用密集排名dense_rank进行排名。
1 select country,dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname
2 from hr.employees
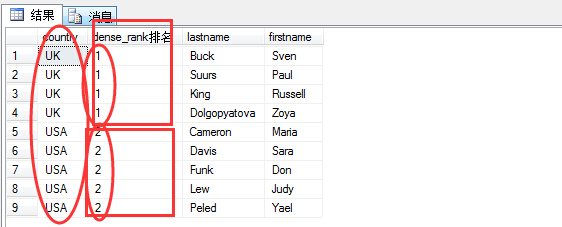
可以看出采用dense_rank以后,就满足了某一条件下,同属一个名次的需求。
(4)分组ntile。按某一条件进行分组。
1 select country,ntile(3) over (order by country) as N'ntile分组',dense_rank() over(order by country) as N'dense_rank排名', lastname,firstname
2 from hr.employees
3 order by country

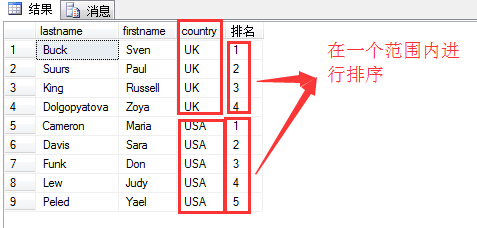
有时候为了在某一个范围内进行排序,比如:
1 select lastname,firstname,country,row_number() over( order by country) as N'排名'
2 from hr.employees

为了实现根据在country范围内排序,即country为Uk的为一组进行排序,country为USA的为一组进行排序。可以这样写:
1 select lastname,firstname,country,row_number() over( partition by country order by country) as N'排名'
2 from hr.employees
SQLServer学习笔记<>.基础知识,一些基本命令,单表查询(null top用法,with ties附加属性,over开窗函数),排名函数的更多相关文章
- jQuery学习笔记 - 基础知识扫盲入门篇
jQuery学习笔记 - 基础知识扫盲入门篇 2013-06-16 18:42 by 全新时代, 11 阅读, 0 评论, 收藏, 编辑 1.为什么要使用jQuery? 提供了强大的功能函数解决浏览器 ...
- python实现简易数据库之二——单表查询和top N实现
上一篇中,介绍了我们的存储和索引建立过程,这篇将介绍SQL查询.单表查询和TOPN实现. 一.SQL解析 正规的sql解析是用语法分析器,但是我找了好久,只知道可以用YACC.BISON等,sqlit ...
- Django学习——Django测试环境搭建、单表查询关键字、神奇的双下划线查询(范围查询)、图书管理系统表设计、外键字段操作、跨表查询理论、基于对象的跨表查询、基于双下划线的跨表查询
Django测试环境搭建 ps: 1.pycharm连接数据库都需要提前下载对应的驱动 2.自带的sqlite3对日期格式数据不敏感 如果后续业务需要使用日期辅助筛选数据那么不推荐使用sqlite3 ...
- three.js学习笔记--基础知识
基础知识 从去年开始就在计划中的three.js终于开始了 历史介绍 (摘自ijunfan1994的转载,感谢作者) OpenGL大概许多人都有所耳闻,它是最常用的跨平台图形库. WebGL是基于Op ...
- Java Script 学习笔记 -- 基础知识
Java script 概述 java Script 的简介 JavaScript一种直译式脚本语言,是一种动态类型.弱类型.基于原型的语言,内置支持类型.它的解释器被称为JavaScript引擎,为 ...
- Django学习笔记(10)——Book单表的增删改查页面
一,项目题目:Book单表的增删改查页面 该项目主要练习使用Django开发一个Book单表的增删改查页面,通过这个项目巩固自己这段时间学习Django知识. 二,项目需求: 开发一个简单的Book增 ...
- php学习笔记——基础知识(2)
9.PHP语句 if 语句 - 如果指定条件为真,则执行代码 if...else 语句 - 如果条件为 true,则执行代码:如果条件为 false,则执行另一端代码 if...else if.... ...
- node基础学习——http基础知识-01-客户单请求
<一> HTTP基础createServer()相关事件介绍 1. 创建HTTP服务器 server = http.createServer([requestListener]) // 下 ...
- Validform 学习笔记---基础知识整理
面对表单的验证,自己写大量的js毕竟不是一个明智的做法.不仅仅是代码很长而且不便于梳理.Validform就是一款开源的第三方验证js的控件,通过添加相应的js以及css能够有效的验证表单,维护起来也 ...
随机推荐
- 6、JavaScript进阶篇③——浏览器对象、Dom对象
一.浏览器对象 1. window对象 window对象是BOM的核心,window对象指当前的浏览器窗口. window对象方法: 注意:在JavaScript基础篇中,已讲解了部分属性,windo ...
- stack note
参考 http://www.cnblogs.com/java06/archive/2012/10/16/3122428.html 1,顺序栈 定义栈: #define stacksize 1000; ...
- MyCat:在.NET Core中使用MyCat
http://www.cnblogs.com/yuangang/p/5830716.html
- .NET业务实体类验证组件Fluent Validation
认识Fluent Vaidation. 看到NopCommerce项目中用到这个组建是如此的简单,将数据验证从业务实体类中分离出来,真是一个天才的想法,后来才知道这个东西是一个开源的轻量级验证组建. ...
- j2ee servlet listener
JSP/Servlet 中的事件处理写过AWT或Swing程序的人一定对桌面程序的事件处理机制印象深刻:通过实现Listener接口的类可以在特定事件(Event)发生时,呼叫特定的方法来对事件进行响 ...
- M面经Prepare: Find integer Average of 2 integers.
The definition of integer average is the highest smaller integer if average is floating point number ...
- SQL 数据库基础
SQL:Structured Quety Language SQL SERVER是一个以客户/服务器(c/s)模式访问.使用Transact-SQL语言的关系型数据库管理子系统(RDBMS) DBMS ...
- C++之路进阶——codevs2460(树的统计)
2460 树的统计 2008年省队选拔赛浙江 时间限制: 2 s 空间限制: 128000 KB 题目等级 : 大师 Master 题目描述 Description 一棵树上有n个节 ...
- c++之路起航——指针
c++一阶指针 定义 存储类型名 数据类型 * 指针变量名: Eg:int *a://定义了一个指向整型的指针 a: 指针使用方法 int a,*b; b=&a;//表明将a的地址赋值给b: ...
- php js表单登陆验证
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...