linux2.6.24内核源代码分析(2)——扒一扒网络数据包在链路层的流向路径之一
在2.6.24内核中链路层接收网络数据包出现了两种方法,第一种是传统方法,利用中断来接收网络数据包,适用于低速设备;第二种是New Api(简称NAPI)方法,利用了中断+轮询的方法来接收网络数据包,是linux为了接收高速的网络数据包而加入的,适用于告诉设备,现在大多数NIC都兼容了这个方法。
今天我的任务是扒一扒网络数据包在传统方法也就是低速路径中如何传入链路层以及如何将其发送给上层网络层的。下面先来看看这条低速路径的简略示意图:
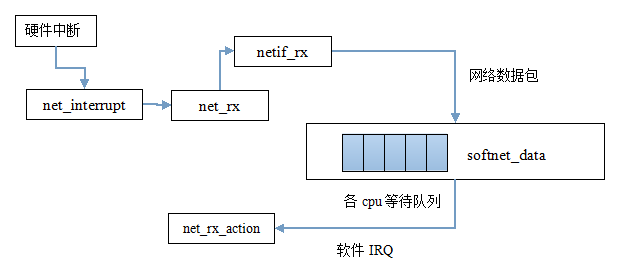
//当产生硬件中断时,此中断处理例程被调用.例程确定该中断是否是由接收到的分组引发的,如果是则调用net_rx
static irqreturn_t net_interrupt(int irq, void *dev_id)
{
struct net_device *dev = dev_id;
struct net_local *np;
int ioaddr, status;
int handled = ; ioaddr = dev->base_addr; np = netdev_priv(dev);
status = inw(ioaddr + ); if (status == )
goto out;
handled = ; if (status & RX_INTR) {
/* 调用此函数来获取数据包!!!!!! */
net_rx(dev);
}
#if TX_RING
if (status & TX_INTR) {
/* 此出代码为发送数据包的过程,我以后会扒它 */
net_tx(dev);
np->stats.tx_packets++;
netif_wake_queue(dev);
}
#endif
if (status & COUNTERS_INTR) { np->stats.tx_window_errors++;
}
out:
return IRQ_RETVAL(handled);
}
static void
net_rx(struct net_device *dev)
{
struct net_local *lp = netdev_priv(dev);
int ioaddr = dev->base_addr;
int boguscount = ; do {
int status = inw(ioaddr);
int pkt_len = inw(ioaddr); if (pkt_len == )
break; if (status & 0x40) {
lp->stats.rx_errors++;
if (status & 0x20) lp->stats.rx_frame_errors++;
if (status & 0x10) lp->stats.rx_over_errors++;
if (status & 0x08) lp->stats.rx_crc_errors++;
if (status & 0x04) lp->stats.rx_fifo_errors++;
} else { struct sk_buff *skb; lp->stats.rx_bytes+=pkt_len;
//调用dev_alloc_skb来分配一个sk_buff实例
//还记得我上一篇文章扒的这个结构体吗?
skb = dev_alloc_skb(pkt_len);
if (skb == NULL) {
printk(KERN_NOTICE "%s: Memory squeeze, dropping packet.\n",
dev->name);
lp->stats.rx_dropped++;
break;
}
//设置skb关联的网络设备
skb->dev = dev; /*将得到的数据拷贝到sk_buff的data处 */
memcpy(skb_put(skb,pkt_len), (void*)dev->rmem_start,
pkt_len); insw(ioaddr, skb->data, (pkt_len + ) >> );
//接着调用netif_rx!!!!!
netif_rx(skb);
dev->last_rx = jiffies;
lp->stats.rx_packets++;
lp->stats.rx_bytes += pkt_len;
}
} while (--boguscount); return;
}
int netif_rx(struct sk_buff *skb)
{
struct softnet_data *queue;
unsigned long flags; if (netpoll_rx(skb))
return NET_RX_DROP; if (!skb->tstamp.tv64)
net_timestamp(skb);//设置分组到达时间 /*
* The code is rearranged so that the path is the most
* short when CPU is congested, but is still operating.
*/
local_irq_save(flags);
//得到cpu的等待队列!!!!
queue = &__get_cpu_var(softnet_data);
__get_cpu_var(netdev_rx_stat).total++;
if (queue->input_pkt_queue.qlen <= netdev_max_backlog) {
if (queue->input_pkt_queue.qlen) {
enqueue:
dev_hold(skb->dev);
//将skb加到等待队列的输入队列队尾!!!!!
__skb_queue_tail(&queue->input_pkt_queue, skb);
local_irq_restore(flags);
return NET_RX_SUCCESS;
}
//NAPI调度函数,我以后将扒!
napi_schedule(&queue->backlog);
goto enqueue;
} __get_cpu_var(netdev_rx_stat).dropped++;
local_irq_restore(flags); kfree_skb(skb);
return NET_RX_DROP;
}
接下来就到了net_rx_action了

static void net_rx_action(struct softirq_action *h)
{
struct list_head *list = &__get_cpu_var(softnet_data).poll_list;
unsigned long start_time = jiffies;
int budget = netdev_budget;
void *have; local_irq_disable(); while (!list_empty(list)) {
struct napi_struct *n;
int work, weight; if (unlikely(budget <= || jiffies != start_time))
goto softnet_break; local_irq_enable(); n = list_entry(list->next, struct napi_struct, poll_list); have = netpoll_poll_lock(n); weight = n->weight; work = ;
if (test_bit(NAPI_STATE_SCHED, &n->state))
//此时poll函数指针指向默认的process_backlog!!!!重要!!!!!!!!!!!!!!!
work = n->poll(n, weight);
WARN_ON_ONCE(work > weight); budget -= work; local_irq_disable(); if (unlikely(work == weight)) {
if (unlikely(napi_disable_pending(n)))
__napi_complete(n);
else
list_move_tail(&n->poll_list, list);
} netpoll_poll_unlock(have);
}
out:
local_irq_enable(); #ifdef CONFIG_NET_DMA
/*
* There may not be any more sk_buffs coming right now, so push
* any pending DMA copies to hardware
*/
if (!cpus_empty(net_dma.channel_mask)) {
int chan_idx;
for_each_cpu_mask(chan_idx, net_dma.channel_mask) {
struct dma_chan *chan = net_dma.channels[chan_idx];
if (chan)
dma_async_memcpy_issue_pending(chan);
}
}
#endif return; softnet_break:
__get_cpu_var(netdev_rx_stat).time_squeeze++;
__raise_softirq_irqoff(NET_RX_SOFTIRQ);
goto out;
}
如果大家不明白上面的n->poll为什么指向了process_backlog,那我们来看一下n的定义:struct napi_struct *n。关键是搞懂napi_struct结构体

结构体中的poll函数指针指向轮询函数,在传统方法(就是我今天介绍的方法)下内核将poll填写为默认的process_backlog函数而在NAPI方法下内核则会填写相应的轮询函数
static int process_backlog(struct napi_struct *napi, int quota)
{
int work = ;
//得到cpu的等待队列
struct softnet_data *queue = &__get_cpu_var(softnet_data);
unsigned long start_time = jiffies; napi->weight = weight_p;
do {
struct sk_buff *skb;
struct net_device *dev; local_irq_disable();
//在等待队列的输入队列中移除一个sk_buff!!!!!
skb = __skb_dequeue(&queue->input_pkt_queue);
if (!skb) {
__napi_complete(napi);
local_irq_enable();
break;
} local_irq_enable(); dev = skb->dev;
//调用此函数处理分组!!!!
netif_receive_skb(skb);
dev_put(dev);
} while (++work < quota && jiffies == start_time); return work;
}
int netif_receive_skb(struct sk_buff *skb)
{
struct packet_type *ptype, *pt_prev;
struct net_device *orig_dev;
int ret = NET_RX_DROP;
__be16 type; ……
……
type = skb->protocol;
list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type)&], list) {
if (ptype->type == type &&
(!ptype->dev || ptype->dev == skb->dev)) {
if (pt_prev)
ret = deliver_skb(skb, pt_prev, orig_dev);
pt_prev = ptype;
}
} if (pt_prev) {
/*调用函数指针func将skb传送至网络层!!!
*pt_prev为packet_type指针,
*在分组传递过程中内核会根据protocol填写func,
*func被填写为向网络层传递skb的函数
*/
ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev);
} else {
kfree_skb(skb);
/* Jamal, now you will not able to escape explaining
* me how you were going to use this. :-)
*/
ret = NET_RX_DROP;
} out:
rcu_read_unlock();
return ret;
}
linux2.6.24内核源代码分析(2)——扒一扒网络数据包在链路层的流向路径之一的更多相关文章
- linux2.6.24内核源代码分析(1)——扒一扒sk_buff
最近研究了linux内核的网络子系统上的网络分组的接收与发送的流程,发现这个叫sk_buff的东西无处不在,内核利用了这个结构来管理分组,在各个层中传递这个结构,因此sk_buff可以说是linux内 ...
- Suse环境下编译linux-2.6.24内核
Suse环境下编译linux-2.6.24内核 1.下载linux-2.6.24内核源码: https://mirrors.edge.kernel.org/pub/linux/kernel/v2.6/ ...
- Linux内核源代码分析方法
Linux内核源代码分析方法 一.内核源代码之我见 Linux内核代码的庞大令不少人"望而生畏",也正由于如此,使得人们对Linux的了解仅处于泛泛的层次.假设想透析Linux ...
- 《LINUX3.0内核源代码分析》第二章:中断和异常 【转】
转自:http://blog.chinaunix.net/uid-25845340-id-2982887.html 摘要:第二章主要讲述linux如何处理ARM cortex A9多核处理器的中断.异 ...
- Linux内核--网络栈实现分析(六)--应用层获取数据包(上)
本文分析基于内核Linux 1.2.13 原创作品,转载请标明http://blog.csdn.net/yming0221/article/details/7541907 更多请看专栏,地址http: ...
- 捕获网络数据包并进行分析的开源库-WinPcap
什么是WinPcap WinPcap是一个基于Win32平台的,用于捕获网络数据包并进行分析的开源库. 大多数网络应用程序通过被广泛使用的操作系统元件来访问网络,比如sockets. 这是一种简单的 ...
- Linux内核中网络数据包的接收-第一部分 概念和框架
与网络数据包的发送不同,网络收包是异步的的.由于你不确定谁会在什么时候突然发一个网络包给你.因此这个网络收包逻辑事实上包括两件事:1.数据包到来后的通知2.收到通知并从数据包中获取数据这两件事发生在协 ...
- 网络数据包分析 网卡Offload
http://blog.nsfocus.net/network-packets-analysis-nic-offload/ 对于网络安全来说,网络传输数据包的捕获和分析是个基础工作,绿盟科技研 ...
- Linux内核网络数据包处理流程
Linux内核网络数据包处理流程 from kernel-4.9: 0. Linux内核网络数据包处理流程 - 网络硬件 网卡工作在物理层和数据链路层,主要由PHY/MAC芯片.Tx/Rx FIFO. ...
随机推荐
- Linux 常用命令小结
学习脚本几天了,总结下linux debian下脚本常用命令. Linux 1.添加删除账户 useradd / userdel 2.修改"张三"密码 passwd 张 ...
- 今日例子border
border这个属性在页面上的使用率还是很高,例如我们需要理解的盒模型就需要对border有个 比较深的理解,如果你会盒模型,但对border没有深的理解,那只能说你只是知道盒模型,而 不是懂得盒模型 ...
- 在jsp中重复定义了两个相同id的标签导致的错误
jQuery做前台开发的程序有一个页面在IE11和谷歌浏览器下都没有问题,但是在XP的IE8下运行就报错: 后来发现是定义了两个相同id的标签所致. 在icCard.jsp中定义的标签: 在carIn ...
- android: 从相册中选择照片
虽然调用摄像头拍照既方便又快捷,但并不是每一次我们都需要去当场拍一张照片的. 因为每个人的手机相册里应该都会存有许许多多张照片,直接从相册里选取一张现有的照 片会比打开相机拍一张照片更加常用.一个优秀 ...
- Docker实践(2)—虚拟网络
1 docker(container)的虚拟网络 docker的虚拟网络结构: host创建一个虚拟bridge,每个container对应一个虚拟网络设备(TAP设备),与bridge一起构成一个虚 ...
- 【原】MyEclipse8.5集成Tomcat7时启动错误:Exception in thread “main” java.lang.NoClassDefFoundError
解决方法: MyEclipse->Window->Preferences->MyEclipse->Servers->Tomcat->Tomcat 6.x->L ...
- Linux录屏软件
如何查找录屏软件 apt-cache search screen record libutempter-dev - privileged helper for utmp/wtmp updates (d ...
- Scala 深入浅出实战经典 第76讲:模式匹配下的赋值语句
王家林亲授<DT大数据梦工厂>大数据实战视频 Scala 深入浅出实战经典(1-87讲)完整视频.PPT.代码下载: 百度云盘:http://pan.baidu.com/s/1c0noOt ...
- python查找算法的实现-二分法
1.算法:(设查找的数组期间为array[low, high]) (1)确定该期间的中间位置K(2)将查找的值T与array[k]比较.若相等,查找成功返回此位置:否则确定新的查找区域,继续二分查找. ...
- Mac上编译libimobiledevice库
0.准备工作: 使用brew或Mac Ports安装:libgnutls or openssl. libplist .libusb.libusbmuxd 1.下载代码: 下载地址:https://gi ...