java2集合框架的一些个人分析和理解
Java2中的集合框架是广为人知的,本文打算从几个方面来说说自己对这个框架的理解。
下图是java.util.Collection的类图(基本完整,有些接口如集合类均实现的Cloneable、Serializable没有包含进去)
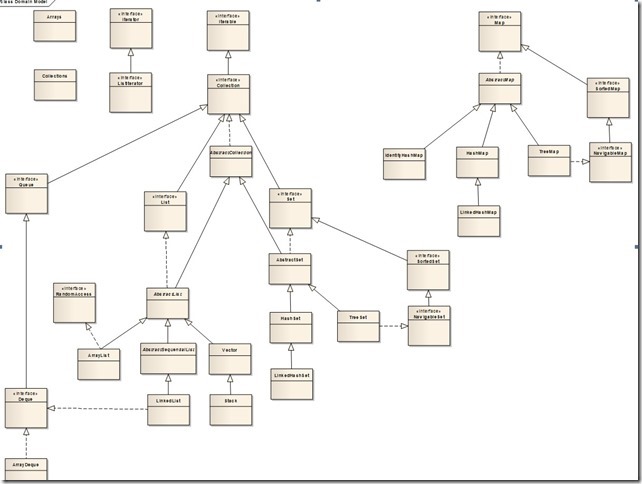
我们常说要继承的话,到底是写个抽象类还是接口,它们区别在于:如果子类确实是父类的一种,应该使用抽象类,描述是“is-a”的关系,而接口则表示一种行为,描述的是“like-a”的关系。但在Java类库里,其实许多原则由于各种原因被打破了,比如在Collection框架里,List/Set都是Collection的一种,为什么不把Collection定义为抽象类呢?而ArrayList/LinkedList也都是List的一种,为什么不把List定义为抽象类呢?这就是原则和实际的折衷。作为Java类库而言,不仅要考虑面向对象的一些原则,也要考虑扩展性和语言本身的限制。能不能把Collection接口去掉,用AbstractCollection作为顶层?作为类库而言是不可以的,因为Java是单继承的,如果把AbstractCollection作为顶层,那么当用户自定义的类既要继承自己的父类,又要具备集合的属性,那么就做不到了(可以自定义集合接口,但就无法与Collection相互转化)。因此,Java集合框架采取的是类库广泛使用的接口+抽象类的形式,以同时获得接口和抽象类的好处,所以我们看到ArrayList extends AbstractList implements List(AbstractList本身就是实现List的,这里再写出implements List是为了使ArrayList的类结构更为清晰)。
另外我们再看Set接口,它的方法基本和Collection方法一模一样,为什么要再写一遍?一方面是作为类库而言要增加详细注释,虽然是同名的方法但实现的约束不同,比如Set的add方法是不会保存重复值的,另一方面是为了从Set接口本身能很清楚地看到它所提供的功能(比如size()方法,和Collection是完全一个含义,也重新定义了一遍),这是从类库易读性来考虑,对于我们自己编写的类,基本就不需要这样。
说多了,回到集合框架本身。
Iterable基本是个标识接口,同时约定了所有线性集合(数组、队列、栈这种一维的都属于线性集合,Map就属于二维,不要求遍历)必须是可以遍历的(集合要给出遍历结构),同时提供了配套的Iterator顶级接口,实现hasNext()、next()和remove()方法来完成遍历功能。为什么这里要定义remove接口方法却不定义add/set方法?个人觉得这可能是考虑在类库的使用过程中remove的频率更高,而add的方法频率要低,set的使用场景就更少了。
ListIterator相比Iterator就多提供了很多功能,包括上面提到的add/set,还有获得索引的nextIndex、previousIndex、以及往回迭代的hasPrevious()/previous()。给针对线性表的操作者更多的便利,事实上在AbstractList里就提供了iterator()和listIterator()两种方法来提供给开发者更多选择。相应的,在HashMap里头,也提供了实现Iterator接口的HashIterator内部抽象类,而在Apache Commons Collections下甚至单独写出MapIterator extends Iterator,由此可见,作为类库的设计者,在Iterator和ListIterator/HashMapIterator上是做了便捷性/易用性以及使用场景上的权衡的。
ArrayList内部结构是个数组,默认是10,在创建ArrayList对象时此数组是空的(Object[] EMPTY_ELEMENTDATA = {})只有当add的时候才扩容(如果扩容容量小于DEFAULT_CAPACITY,也就是10,就一次性扩容到10)。其扩容的机制是:当前数组容量已经无法放入更多元素的时候,增加原有数组的一半,
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
elementData = Arrays.copyOf(elementData, newCapacity);
此数组的最大值是Integer.MAX_VALUE,也就是2^31-1。数组扩容的时候要考虑到当容量再度扩容一半的时候会越界,所以单独做了判断处理。数组扩容是在调用了本地方法去分配新的空间区域(下面是Arrays.CopyOf的代码)
public static int[] copyOf(int[] original, int newLength) {
int[] copy = new int[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
System.arraycopy的代码如下
public static native void arraycopy(Object src, int srcPos,
Object dest, int destPos,
int length);
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
按照理论上来说,对于能预先知道数组大小的,应该在定义ArrayList的时候指定其容量以减少扩容次数,但是经过以下代码试验(虚拟机64位Client模式,JDK1.7.0_45)
int times=1000000;
long startTime=new Date().getTime();
List<Integer> arrayList=new ArrayList<Integer>(times);
for(int i=0;i<times;i++) {
arrayList.add(i);
}
long endTime=new Date().getTime();
System.out.println("ArrayList增加"+times+"次,耗费时间="+(endTime-startTime));
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
对于1百万次增加,使用new ArrayList<Integer>(times)时耗费时间是90ms,而使用new ArrayList<Integer>()的耗费时间竟然要短一些,只要81ms;把times扩大到1千万的时候,差距更明显,指定容量的要5秒多,而不指定容量的只要3秒多。具体是哪慢了不好下结论,推测应该是当实际元素较少的时候,大数组在寻址、计算等方面要慢一些,反过来说System.arraycopy的效率并没有传说中的那么低,这也是为什么用的本地方法的原因。
LinkedList我们知道内部结构是个线性链表,首先看它继承的不是AbstractList,而是继承自AbstractSequentialList,这是AbstractList的子类,实现了线性链表的骨架方法,如get/set,均是通过ListIterator迭代器来遍历实现。为什么要创造出AbstractSequentialList这个类?因为线性的不只有链表,但线性的都只有通过迭代器才能找到元素,与之对应的是随机读取——也就是数组,因此在AbstractSequentialList的类注释里明确说明:如果是随机读取的,则使用AbstractList更合适(AbstractList并没有提供随机读取的实现,类注释的意思只是说如要随机读取,则AbstractSequentialList没有任何帮助,不如实现AbstractList更准确)。事实上,为了表明集合是否可以根据索引随机读取,Collection框架专门定义了一个空接口RandomAccess,以标识该类是否可随机读,ArrayList、Vector都实现了这个接口,而没有实现这个接口的,则是不可以通过下标索引来寻址的。
LinkedList有比ArrayList在接口上有更丰富的功能,比如addFirst()、addLast()、push()、pop(),、indexOf(),同时它的listIterator()也要比iterator()更常用一些。我们以前常说对于经常删除、增加的集合,使用LinkedList比ArrayList效率要高,这是容易被误解的,LinkedList的寻址相比数组来说非常地慢,如果在频繁增/删之前需要寻址定位,那么仍然比ArrayList要慢很多,数十倍地慢,所以使用它的时候要谨慎,不能耍小聪明。LinkedList根据索引寻址的get(int index)方法,使用的是简单的“二分法”,即如果index小于size的一半,则从前往后迭代;大于size一半则从后往前迭代。这也是没有办法的事情,LinkedList是需要保证插入顺序的,所以不能做任何排序,也就不能使用任何如冒泡、快速排序之类的算法。有没有不需要保证插入顺序从而能够快速寻址的集合呢?TreeSet/HashSet可以快速寻址,但不能有重复值;TreeMap/HashMap同样是不能有重复值;Collection框架并没有给出能有重复值同时又能允许排序的List,应该是他们认为ArrayList就可以满足这种场景了,但类库中有个类IdentityHashMap,它的hash()方法用的是System.identityHashCode()而不是HashMap所用的key.hashCode。System.identityHashCode()意思是不管对象是否实现了hashCode,都取Object的hashCode也就是对象的内存地址来作为key,这样即使两个对象hashCode相等,也会被重复插入(在该类的注释中说到了它的一些使用场景,有兴趣的可以仔细看下)。
我们知道通常的集合都是非线程安全的,表现在多个线程同时增/删时,集合大小会不可预测,同时Iterator尽量保证在迭代过程中操作是安全的(不保证准确,但尽量保证不会有越界问题),即当某线程迭代读取集合时,如有其他线程修改此集合的结构(扩大/缩小),则会抛出ConcurrentModificationException。那么它是如何实现的呢?在集合中都会维护一个内部计数器modCount,如果有影响集合结构的操作(增加、删除、合并等,而修改不是),modCount都会自增1。在对集合迭代时,都会检查当前迭代时的操作计数器副本expectedModCount(迭代前初始化为和modCount相等)和modCount是否相等
int expectedModCount = modCount;
final void checkForComodification() {
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
Entry(int h, K k, V v, Entry<K,V> n) {
value = v;
next = n;
key = k;
hash = h;
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
初始扩容的容量是16
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
,在扩容的过程中同时会计算下次扩容的阈值threshold,它=数组大小*负载因子。为什么在达到threshold的时候扩容而不是在达到数组最大长度的时候?这是为了减少每个数组元素上的Entry数,因为根据hash()方法,在把table数组占满之前,很可能在其他元素上已经有多个了(从概率角度),但负载因子又不能太小,否则会造成很多空间浪费,所以作者权衡(这里可能也是根据hash()或某些数学原理)取0.75作为负载因子,即达到table数组3/4时就扩容,并且是扩容2倍,不是ArrayList那样扩容一半
void addEntry(int hash, K key, V value, int bucketIndex) {
if ((size >= threshold) && (null != table[bucketIndex])) {
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
bucketIndex = indexFor(hash, table.length);
}
createEntry(hash, key, value, bucketIndex);
}
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
至于为什么这么做,比较复杂,我也没搞太清,尤其是其中为什么选择20、12、7、4这样的来右移。还有hashSeed的选择也不太清楚。
这里必须要提下HashMap扩容的效率问题。前面提到ArrayList的扩容性能并不差,而HashMap就完全不一样了,经实验,扩容至少带来性能下降1半以上,但有临界点,元素超过10万数量级差距就不明显了。下面是代码和测试结果
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
public class ResizePerformanceTest {
public static void main(String[] args) {
run(1000);
run(10000);
run(100000);
run(1000000);
run(10000000);
}
public static void run(int times) {
System.out.println("增加"+times+"次");
long startTime=new Date().getTime();
Map<Integer,Integer> map=new HashMap<Integer,Integer>();
for(int i=0;i<times;i++) {
map.put(i, i);
}
long endTime=new Date().getTime();
System.out.println("HashMap自动扩容的方式,增加"+times+"次,耗费时间="+(endTime-startTime));
long startTime1=new Date().getTime();
Map<Integer,Integer> map1=new HashMap<Integer,Integer>(times);
for(int i=0;i<times;i++) {
map1.put(i, i);
}
long endTime1=new Date().getTime();
System.out.println("HashMap预先指定空间的方式,增加"+times+"次,耗费时间="+(endTime1-startTime1));
}
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
增加1000次
HashMap自动扩容的方式,增加1000次,耗费时间=2
HashMap预先指定空间的方式,增加1000次,耗费时间=1
增加10000次
HashMap自动扩容的方式,增加10000次,耗费时间=15
HashMap预先指定空间的方式,增加10000次,耗费时间=6
增加100000次
HashMap自动扩容的方式,增加100000次,耗费时间=25
HashMap预先指定空间的方式,增加100000次,耗费时间=21
增加1000000次
HashMap自动扩容的方式,增加1000000次,耗费时间=1707
HashMap预先指定空间的方式,增加1000000次,耗费时间=1611
增加10000000次
HashMap自动扩容的方式,增加10000000次,耗费时间=21054
HashMap预先指定空间的方式,增加10000000次,耗费时间=17820
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
HashMap大约就说这么多,再说说TreeMap。TreeMap是种红黑树的结构,能够对元素排序(红黑树、数据库的B树、B+树,还有冒泡算法、快速排序算法这些算法领域的,现在还真是不那么掌握牢固)。为了保证排序,提供了两种方式:一种是Key对象实现Comparable接口,另外一种方式是单独提供Comparator实现类
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
如果本身Key对象的排序是确定的,比如Integer按大小排序,String按照字典排序,这些是无疑义的,所以它们都实现了Comparable接口,但假如说Person对象,有时需要按年龄排序,有时需要按身高排序,有时需要按薪酬排序,所以就没办法使用Comparable接口了,此时可以根据不同排序方式创建相应的Comparator类。
既然是按照顺序排列的树,那自然就需要提供一些数据结构方面的方法,所以TreeMap有了firstKey()、lastKey()、pollFirstEntry()、lowerEntry(K)、floorEntry(K)、headMap(K)、tailMap(K)、desendintMap()这样的方便方法。
相比HashMap,TreeMap还有个很大的不同,就是它不仅是继承AbstractMap,还实现了NavigableMap,NavigableMap继承自SortedMap,SortedMap继承自Map。SortedMap定义了什么?firstkey()、lastKey()、headMap(K)、tailMap(K)、subMap(K,K),NavigableMap定义了pollFirstEntry()、lowerEntry(K)、floorEntry(K)等方法。为什么这么设计?SortedMap是好理解的,针对可以排序的Map单独设一个接口,但为什么要NavigableMap呢?它的lowerEntry(K)之类的方法为什么不能合并到SortedMap里去?个人觉得这应该是两个版本时期导致的,NavigableMap是JDK1.6时加入的,此时已经有了不少SortedMap的子类,不是很有必要让子类也去实现这些方法,所以新加了个NavigableMap类,在需要lower的时候实现它即可,不需要时就直接实现SortedMap。也就是设计这种类库接口时的粒度问题,基本的方法在上一级接口定义,虽然另外一些方法也是正常使用,但根据它的频率、约束性有所不同可以下放,同时又要考虑不能使接口数量太多加大复杂性。
理解了Map,再来看Set就很简单了。HashSet内部完全是以Set元素为key,new Object()为value的HashMap
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
它的一些如size()、contain()方法都是直接调用map的方法。
public int size() {
return map.size();
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
TreeSet也是一样,且也有相配套的NavigableSet、SortedSet。
从整体来说,感觉Set设计地不是太好,其大多数功能和List很像,仅非重复这个频率并不高的场景不足以单独列这一套接口,而其实现上又基本上完全依托于Map。如果开发者真有这种场景,完全可以自行用HashMap来代替。
集合框架中还有两个很有用的辅助类,分别是Collections和Arrays,这两个就不多介绍了。Collections提供了一系列synchronized集合、unmodified集合以及很少用的Checked集合(类型检查的),以及toArray(toArray(T[] a)更好用,因为能指定返回数组的元素类型)、binarySearch(快速查找算法,需要参数列表元素能排序,否则结果就不准确)。而Arrays提供了一些如sort、merge、binarySearch、copyOf、asList这样有效的方法,注意这里的asList返回的Arrays内部实现的一个ArrayList,有些方法不支持,比如add、remove,除了set之外基本上就是一个只读列表,如果需要可add/remove,还是需要使用集合的相应构造函数或者Collections的copy方法)。
最后两个需要说的是虽然是在java.util根目录下,但基本是为java.util.concurrent准备的,就是Queue(队列)和Deque(双向队列)。Queue的一系列子类如DelayQueue、LinkedBlockQueue更多地是和并发有关,这放到将来的JUC框架时再讲吧。
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
.csharpcode, .csharpcode pre
{
font-size: small;
color: black;
font-family: consolas, "Courier New", courier, monospace;
background-color: #ffffff;
/*white-space: pre;*/
}
.csharpcode pre { margin: 0em; }
.csharpcode .rem { color: #008000; }
.csharpcode .kwrd { color: #0000ff; }
.csharpcode .str { color: #006080; }
.csharpcode .op { color: #0000c0; }
.csharpcode .preproc { color: #cc6633; }
.csharpcode .asp { background-color: #ffff00; }
.csharpcode .html { color: #800000; }
.csharpcode .attr { color: #ff0000; }
.csharpcode .alt
{
background-color: #f4f4f4;
width: 100%;
margin: 0em;
}
.csharpcode .lnum { color: #606060; }
java2集合框架的一些个人分析和理解的更多相关文章
- Java8集合框架——LinkedList源码分析
java.util.LinkedList 本文的主要目录结构: 一.LinkedList的特点及与ArrayList的比较 二.LinkedList的内部实现 三.LinkedList添加元素 四.L ...
- java的集合框架set 和map的深入理解
Java的集合框架之Map的用法详解 Map有两种比较常用的实现:HashMap 和 TreeMap. HashMap: HashMap 也是无序的,也是按照哈希编码来排序的,允许使用null 值和n ...
- Java基础-集合框架-ArrayList源码分析
一.JDK中ArrayList是如何实现的 1.先看下ArrayList从上而下的层次图: 说明: 从图中可以看出,ArrayList只是最下层的实现类,集合的规则和扩展都是AbstractList. ...
- Java8集合框架——LinkedHashMap源码分析
本文的结构如下: 一.LinkedHashMap 的 Javadoc 文档注释和简要说明 二.LinkedHashMap 的内部实现:一些扩展属性和构造函数 三.LinkedHashMap 的 put ...
- Java8集合框架——ArrayList源码分析
java.util.ArrayList 以下为主要介绍要点,从 Java 8 出发: 一.ArrayList的特点概述 二.ArrayList的内部实现:从内部属性和构造函数说起 三.ArrayLis ...
- Java8集合框架——LinkedHashSet源码分析
本文的目录结构如下: 一.LinkedHashSet 的 Javadoc 文档注释和简要说明 二.LinkedHashSet 的内部实现:构造函数 三.LinkedHashSet 的 add 操作和 ...
- Java8集合框架——HashSet源码分析
本文的目录结构: 一.HashSet 的 Javadoc 文档注释和简要说明 二.HashSet 的内部实现:内部属性和构造函数 三.HashSet 的 add 操作和扩容 四.HashSet 的 r ...
- Java8集合框架——HashMap源码分析
java.util.HashMap 本文目录: 一.HashMap 的特点概述和说明 二.HashMap 的内部实现:从内部属性和构造函数说起 三.HashMap 的 put 操作 四.HashMap ...
- 《深入理解Java集合框架》系列文章
Introduction 关于C++标准模板库(Standard Template Library, STL)的书籍和资料有很多,关于Java集合框架(Java Collections Framewo ...
随机推荐
- UESTC 288 青蛙的约会 扩展GCD
设两只青蛙跳了t步,则此时A的坐标:x+mt,B的坐标:y+nt.要使的他们在同一点,则要满足: x+mt - (y+nt) = kL (p是整数) 化成: (n-m)t + kL = x-y (L ...
- 第2章 面向对象的设计原则(SOLID):6_开闭原则
6. 开闭原则(Open Closed Principle,OCP) 6.1 定义 (1)一个类应该对扩展开放,对修改关闭.要求通过扩展来实现变化,而且是在不修改己有的代码情况下进行扩展,也不必改动己 ...
- android studio 使用入门 (快捷键等收集)
1. 解决 android studio cannot resolve symbol 1) file->import proj->create proj from exit proj .. ...
- 分布式监控系统Zabbix-3.0.3-完整安装记录(6)-微信报警部署
Zabbix可以通过多种方式把告警信息发送到指定人,常用的有邮件,短信报警方式. 现在由于微信使用的广泛度,越来越多的企业开始使用zabbix结合微信作为主要的告警方式,这样可以及时有效的把告警信息推 ...
- Window.open()方法参数详解
Window.open()方法参数详解 1, 最基本的弹出窗口代码 window.open('page.html'); 2, 经过设置后的弹出窗口 window.open('page.html ...
- [转]服务器自动化操作 RunDeck
From : http://www.oschina.net/p/rundeck/similar_projects?sort=view&lang=25 RunDeck 是用 Java/Grail ...
- mousedos网络批量部署xp
小时候对这个东西很好奇,不知道什么原理.一直觉得很好玩.现在研究了下,总结如下 软件的操作步骤很讲究,稍微不慎,则就需要重新来过 知识点: 1,掌握诺顿ghost分区为gh文件 2,学会清理至一个干净 ...
- C语言 百炼成钢18
//题目52:用递归打印以下图形 //* //*.*. //*..*..*.. //*...*...*...*... //*....*....*....*....*.... #include<s ...
- Oracle PL/SQL中如何使用%TYPE和%ROWTYPE
1. 使用%TYPE 在许多情况下,PL/SQL变量可以用来存储在数据库表中的数据.在这种情况下,变量应该拥有与表列相同的类型.例如,students表的first_name列的类型为VARCHAR2 ...
- opencv2学习:计算协方差矩阵
图像的高级处理中,协方差矩阵计算是必不可少的,但opencv关于这方面的资料却相当少. 首先,利用matlab计算一下,便于比较: >> data=[1,2,3;10,20,30] dat ...