GPU CUDA 经典入门指南
转自:http://luofl1992.is-programmer.com/posts/38830.html
CUDA编程中,习惯称CPU为Host,GPU为Device。编程中最开始接触的东西恐怕是并行架构,诸如Grid、Block的区别会让人一头雾水,我所看的书上所讲述的内容比较抽象,对这些概念的内容没有细讲,于是在这里作一个整理。
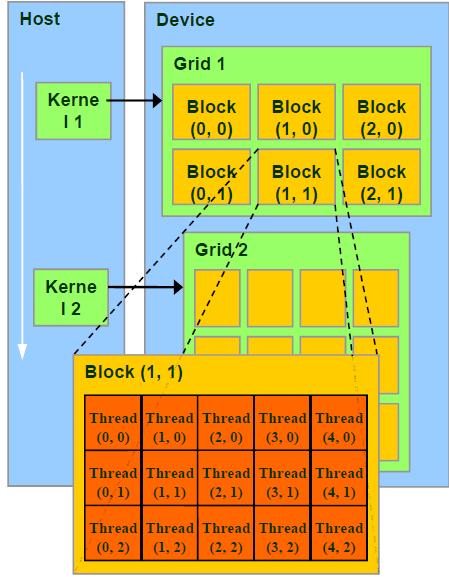
Grid、Block和Thread的关系
Thread :并行运算的基本单位(轻量级的线程)
Block :由相互合作的一组线程组成。一个block中的thread可以彼此同步,快速交换数据,最多可以同时512个线程。
Grid :一组Block,有共享全局内存
Kernel :在GPU上执行的程序,一个Kernel对应一个Grid。
其结构如下图所示:
/*
另外:Block和Thread都有各自的ID,记作blockIdx(1D,2D),threadIdx(1D,2D,3D)
Block和Thread还有Dim,即blockDim与threadDim. 他们都有三个分量x,y,z
线程同步:void __syncthreads(); 可以同步一个Block内的所有线程
总结来说,每个 thread 都有自己的一份 register 和 local memory 的空间。
一组thread构成一个 block,这些 thread 则共享有一份shared memory。
此外,所有的 thread(包括不同 block 的 thread)都共享一份
global memory、constant memory、和 texture memory。
不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
*/
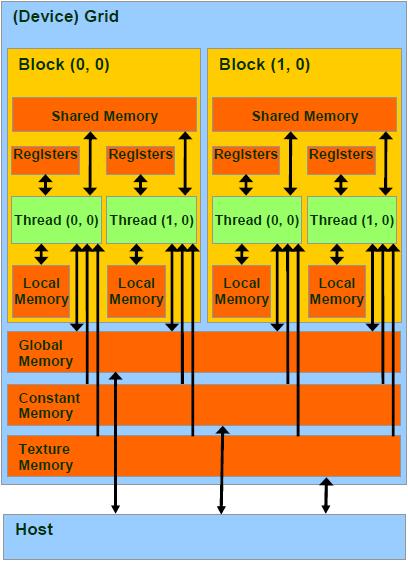
存储层次
1 per-thread register cycle
per-thread local memory slow
per-block shared memory cycle
per-grid global memory cycle,not cached!!
constant and texture memories cycle, but cached and read-only
分配内存:cudaMalloc,cudaFree,它们分配的是global memory
Hose-Device数据交换:cudaMemcpy
变量类型
1 __device__ // GPU的global memory空间,grid中所有线程可访问
__constant__ // GPU的constant memory空间,grid中所有线程可访问
__shared__ // GPU上的thread block空间,block中所有线程可访问
local // 位于SM内,仅本thread可访问
// 在编程中,可以在变量名前面加上这些前缀以区分。
数据类型
1 // 内建矢量类型:
int1,int2,int3,int4,float1,float2, float3,float4 ...
// 纹理类型:
texture<Type, Dim, ReadMode>texRef;
// 内建dim3类型:定义grid和block的组织方法。例如:
dim3 dimGrid(, );
dim3 dimBlock(, , );
// CUDA函数CPU端调用方法
kernelFoo<<<dimGrid, dimBlock>>>(argument);
函数定义
1 __device__ // 执行于Device,仅能从Device调用。限制,不能用&取地址;不支持递归;不支持static variable;不支持可变长度参数
__global__ // void: 执行于Device,仅能从Host调用。此类函数必须返回void
__host__ // 执行于Host,仅能从Host调用,是函数的默认类型
// 在执行kernel函数时,必须提供execution configuration,即<<<....>>>的部分。
// 例如:
__global__ void KernelFunc(...);
dim3 DimGrid(, ); // 5000 thread blocks
dim3 DimBlock(, , ); // 256 threads per block
size_t SharedMemBytes = ; // 64 bytes of shared memory
KernelFunc<<< DimGrid, DimBlock, SharedMemBytes >>>(...);
数学函数
1 CUDA包含一些数学函数,如sin,pow等。每一个函数包含有两个版本,
例如正弦函数sin,一个普通版本sin,另一个不精确但速度极快的__sin版本。
内置变量
1 /*
gridDim, blockIdx, blockDim,
threadIdx, wrapsize.
这些内置变量不允许赋值的
*/
编写程序
1 /*
目前CUDA仅能良好的支持C,在编写含有CUDA代码的程序时,
首先要导入头文件cuda_runtime_api.h。文件名后缀为.cu,使用nvcc编译器编译。
目前最新的CUDA版本为5.0,可以在官方网站下载最新的工具包,网址为:
https://developer.nvidia.com/cuda-downloads
该工具包内包含了ToolKit、样例等,安装起来比原先的版本也方便了很多。
*/
相关扩展
1 GPU硬件
// i GPU一个最小单元称为Streaming Processor(SP),全流水线单事件无序微处理器,
包含两个ALU和一个FPU,多组寄存器文件(register file,很多寄存器的组合),
这个SP没有cache。事实上,现代GPU就是一组SP的array,即SPA。
每一个SP执行一个thread // ii 多个SP组成Streaming Multiprocessor(SM)。
每一个SM执行一个block。每个SM包含8个SP;
2个special function unit(SFU):
这里面有4个FPU可以进行超越函数和插值计算
MultiThreading Issue Unit:分发线程指令
具有指令和常量缓存。
包含shared memory // iii Texture Processor Cluster(TPC) :包含某些其他单元的一组SM Single-Program Multiple-Data (SPMD)模型 // i CPU以顺序结构执行代码,
GPU以threads blocks组织并发执行的代码,即无数个threads同时执行 // ii 回顾一下CUDA的概念:
一个kernel程序执行在一个grid of threads blocks之中
一个threads block是一批相互合作的threads:
可以用过__syncthreads同步;
通过shared memory共享变量,不同block的不能同步。 // iii Threads block声明:
可以包含有1到512个并发线程,具有唯一的blockID,可以是1,,3D
同一个block中的线程执行同一个程序,不同的操作数,可以同步,每个线程具有唯一的ID 线程硬件原理 // i GPU通过Global block scheduler来调度block,
根据硬件架构分配block到某一个SM。
每个SM最多分配8个block,每个SM最多可接受768个thread
(可以是一个block包含512个thread,
也可以是3个block每个包含256个thread(*=!))。
同一个SM上面的block的尺寸必须相同。每个线程的调度与ID由该SM管理。 // ii SM满负载工作效率最高!考虑某个Block,其尺寸可以为8*8,16*16,32*32
*:每个block有64个线程,
由于每个SM最多处理768个线程,因此需要768/=12个block。
但是由于SM最多8个block,因此一个SM实际执行的线程为8*=512个线程。
*:每个block有256个线程,SM可以同时接受三个block,*=,满负载
*:每个block有1024个线程,SM无法处理! // iii Block是独立执行的,每个Block内的threads是可协同的。 // iv 每个线程由SM中的一个SP执行。
当然,由于SM中仅有8个SP,768个线程是以warp为单位执行的,
每个warp包含32个线程,这是基于线程指令的流水线特性完成的。
Warp是SM基本调度单位,实际上,一个Warp是一个32路SIMD指令
。基本单位是half-warp。
如,SM满负载工作有768个线程,则共有768/=24个warp
,每一瞬时,只有一组warp在SM中执行。
Warp全部线程是执行同一个指令,
每个指令需要4个clock cycle,通过复杂的机制执行。 // v 一个thread的一生:
Grid在GPU上启动;
block被分配到SM上;
SM把线程组织为warp;
SM调度执行warp;
执行结束后释放资源;
block继续被分配.... 线程存储模型 // i Register and local memory:线程私有,对程序员透明。
每个SM中有8192个register,分配给某些block,
block内部的thread只能使用分配的寄存器。
线程数多,每个线程使用的寄存器就少了。 // ii shared memory:block内共享,动态分配。
如__shared__ float region[N]。
shared memory 存储器是被划分为16个小单元,
与half-warp长度相同,称为bank,每个bank可以提供自己的地址服务。
连续的32位word映射到连续的bank。
对同一bank的同时访问称为bank conflict。
尽量减少这种情形。 // iii Global memory:没有缓存!容易称为性能瓶颈,是优化的关键!
一个half-warp里面的16个线程对global memory的访问可以被coalesce成整块内存的访问,如果:
数据长度为4,8或16bytes;地址连续;起始地址对齐;第N个线程访问第N个数据。
Coalesce可以大大提升性能。 // uncoalesced
Coalesced方法:如果所有线程读取同一地址,
不妨使用constant memory;
如果为不规则读取可以使用texture内存
如果使用了某种结构体,其大小不是4 16的倍数,
可以通过__align(X)强制对齐,X=
example://想象为二维数组
int row = blockIdx.y * blockDim.y + threadIdx.y; //thread 所在的行
int col = blockIdx.x * blockDim.x + threadIdx.x; //thread 所在的列
blockDim是指每个block的size,blockDim.y 相当于block的height,blockDim.x相当于block的width。
blockIdx.y是指block在grid中竖排的位置,同理,blockIdx.x是指block在grid中横排的位置。
GPU CUDA 经典入门指南的更多相关文章
- 算法竞赛入门经典训练指南——UVA 11300 preading the Wealth
A Communist regime is trying to redistribute wealth in a village. They have have decided to sit ever ...
- CUDA从入门到精通
http://blog.csdn.net/augusdi/article/details/12833235 CUDA从入门到精通(零):写在前面 在老板的要求下.本博主从2012年上高性能计算课程開始 ...
- CUDA从入门到精通 - Augusdi的专栏 - 博客频道 - CSDN.NET
http://blog.csdn.net/augusdi/article/details/12833235 CUDA从入门到精通 - Augusdi的专栏 - 博客频道 - CSDN.NET CUDA ...
- 【CUDA开发】CUDA从入门到精通
CUDA从入门到精通(零):写在前面 在老板的要求下,本博主从2012年上高性能计算课程开始接触CUDA编程,随后将该技术应用到了实际项目中,使处理程序加速超过1K,可见基于图形显示器的并行计算对于追 ...
- pytorch 入门指南
两类深度学习框架的优缺点 动态图(PyTorch) 计算图的进行与代码的运行时同时进行的. 静态图(Tensorflow <2.0) 自建命名体系 自建时序控制 难以介入 使用深度学习框架的优点 ...
- NLP新手入门指南|北大-TANGENT
开源的学习资源:<NLP 新手入门指南>,项目作者为北京大学 TANGENT 实验室成员. 该指南主要提供了 NLP 学习入门引导.常见任务的开发实现.各大技术教程与文献的相关推荐等内容, ...
- Microsoft Orleans 之 入门指南
Microsoft Orleans 在.net用简单方法构建高并发.分布式的大型应用程序框架. 原文:http://dotnet.github.io/orleans/ 在线文档:http://dotn ...
- 转 猫都能学会的Unity3D Shader入门指南(二)
猫都能学会的Unity3D Shader入门指南(二) 关于本系列 这是Unity3D Shader入门指南系列的第二篇,本系列面向的对象是新接触Shader开发的Unity3D使用者,因为我本身自己 ...
- Unity3D Shader入门指南(二)
关于本系列 这是Unity3D Shader入门指南系列的第二篇,本系列面向的对象是新接触Shader开发的Unity3D使用者,因为我本身自己也是Shader初学者,因此可能会存在错误或者疏漏,如果 ...
随机推荐
- 友盟iOS推送配置(从真机调试到推送)
下面我来讲解一下友盟iOS的推送配置,其实友盟只是一个示例,换做其余的第三方推送服务也会适用,只是第三方的后面服务变了而已. iOS推送(包括真机调试)所需要的步骤和文件如下: 备注:这里我将省略掉一 ...
- [NOIP2009] 普及组
多项式输出 模拟 /*by SilverN*/ #include<algorithm> #include<iostream> #include<cstring> # ...
- HDU 2896 病毒侵袭
Problem Description 当太阳的光辉逐渐被月亮遮蔽,世界失去了光明,大地迎来最黑暗的时刻....在这样的时刻,人们却异常兴奋——我们能在有生之年看到500年一遇的世界奇观,那是多么幸福 ...
- [LeetCode] Binary Tree Preorder/Inorder/Postorder Traversal
前中后遍历 递归版 /* Recursive solution */ class Solution { public: vector<int> preorderTraversal(Tree ...
- python之BIF函数在列表中的应用
1 Python 3.3.4 (v3.3.4:7ff62415e426, Feb 10 2014, 18:13:51) [MSC v.1600 64 bit (AMD64)] on win32 2 T ...
- mysql 外键(FOREIGN KEY)
最近有开始做一个实验室管理系统,因为分了几个表进行存储·所以要维护表间的关联··研究了一下MySQL的外键. (1)只有InnoDB类型的表才可以使用外键,mysql默认是MyISAM,这种类型不支持 ...
- Nonove js timer 计时器
<html> <head> <title> Nonove js timer 计时器 </title> </head> <body> ...
- 移动前端调式页面--weinre
一:远程调式工具---weinre 阅读目录 一:远程调式工具---weinre 二: 安装weinre 三: 访问weinre及在页面上调用 四:多用户 回到顶部 一:远程调式工具---weinre ...
- SpringMvc 相关,bean map转换,百度天气,base64.js,jsBase64.java;
1. Map<String, Object>与JavaBean[POJO, Model]转换; //model public class model{ private int id; pr ...
- POJ 1191 棋盘分割
棋盘分割 Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 11213 Accepted: 3951 Description 将一个 ...