LDA-math-认识Beta/Dirichlet分布
http://cos.name/2013/01/lda-math-beta-dirichlet/#more-6953
2. 认识Beta/Dirichlet分布
2.1 魔鬼的游戏—认识Beta 分布
统计学就是猜测上帝的游戏,当然我们不总是有机会猜测上帝,运气不好的时候就得揣度魔鬼的心思。有一天你被魔鬼撒旦抓走了,撒旦说:“你们人类很聪明,而我是很仁慈的,和你玩一个游戏,赢了就可以走,否则把灵魂出卖给我。游戏的规则很简单,我有一个魔盒,上面有一个按钮,你每按一下按钮,就均匀的输出一个[0,1]之间的随机数,我现在按10下,我手上有10个数,你猜第7大的数是什么,偏离不超过0.01就算对。”你应该怎么猜呢?
从数学的角度抽象一下,上面这个游戏其实是在说随机变量X1,X2,⋯,Xn∼iidUniform(0,1),把这n 个随机变量排序后得到顺序统计量 X(1),X(2),⋯,X(n), 然后问 X(k) 的分布是什么。
对于不喜欢数学的同学而言,估计每个概率分布都是一个恶魔,那在概率统计学中,均匀分布应该算得上是潘多拉魔盒,几乎所有重要的概率分布都可以从均匀分布Uniform(0,1)中生成出来;尤其是在统计模拟中,所有统计分布的随机样本都是通过均匀分布产生的。
 潘多拉魔盒Uniform(0,1)
潘多拉魔盒Uniform(0,1)
对于上面的游戏而言 n=10,k=7, 如果我们能求出 X(7) 的分布的概率密度,那么用概率密度的极值点去做猜测就是最好的策略。对于一般的情形,X(k) 的分布是什么呢?那我们尝试计算一下X(k) 落在一个区间 [x,x+Δx] 的概率,也就是求如下概率值
把 [0,1] 区间分成三段 [0,x),[x,x+Δx],(x+Δx,1],我们先考虑简单的情形,假设n 个数中只有一个落在了区间 [x,x+Δx]内,则因为这个区间内的数X(k)是第k大的,则[0,x)中应该有 k−1 个数,(x,1] 这个区间中应该有n−k 个数。不失一般性,我们先考虑如下一个符合上述要求的事件E
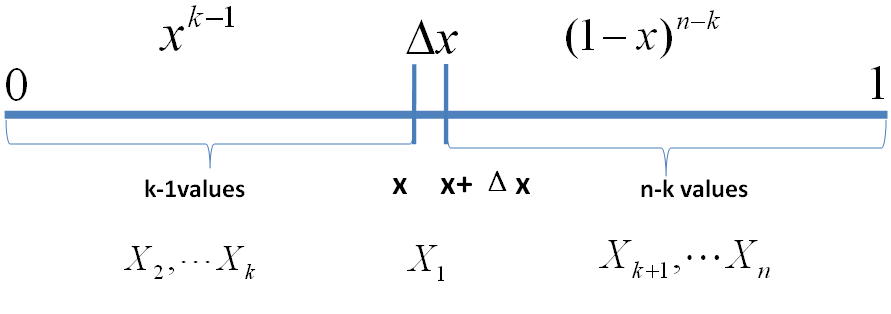
事件 E
则有
o(Δx)表示Δx的高阶无穷小。显然,由于不同的排列组合,即n个数中有一个落在 [x,x+Δx]区间的有n种取法,余下n−1个数中有k−1个落在[0,x)的有(n−1k−1)种组合,所以和事件E等价的事件一共有 n(n−1k−1)个。
继续考虑稍微复杂一点情形,假设n 个数中有两个数落在了区间 [x,x+Δx],
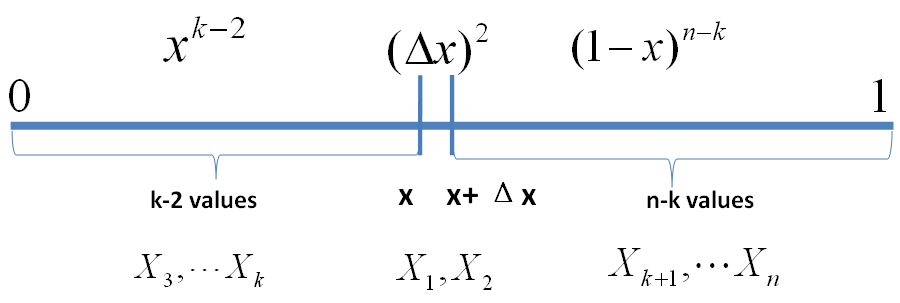
事件E’
则有
从以上分析我们很容易看出,只要落在[x,x+Δx]内的数字超过一个,则对应的事件的概率就是 o(Δx)。于是
所以,可以得到X(k)的概率密度函数为
利用Gamma 函数,我们可以把 f(x) 表达为
还记得神奇的 Gamma 函数可以把很多数学概念从整数集合延拓到实数集合吧。我们在上式中取α=k,β=n−k+1, 于是我们得到
这个就是一般意义上的 Beta 分布!可以证明,在α,β取非负实数的时候,这个概率密度函数也都是良定义的。
好,我们回到魔鬼的游戏,这n=10,k=7这个具体的实例中,我们按照如下密度分布的峰值去猜测才是最有把握的。
然而即便如此,我们能做到一次猜中的概率也不高,很不幸,你第一次没有猜中,魔鬼微笑着说:“我再仁慈一点,再给你一个机会,你按5下这个机器,你就得到了5个[0,1]之间的随机数,然后我可以告诉你这5个数中的每一个和我的第7大的数相比,谁大谁小,然后你继续猜我手头的第7大的数是多少。”这时候我们应该怎么猜测呢?
2.2 Beta-Binomial 共轭
魔鬼的第二个题目,数学上形式化一下,就是
- X1,X2,⋯,Xn∼iidUniform(0,1),对应的顺序统计量是 X(1),X(2),⋯,X(n), 我们要猜测 p=X(k);
- Y1,Y2,⋯,Ym∼iidUniform(0,1), Yi中有m1个比p小,m2个比p大;
- 问 P(p|Y1,Y2,⋯,Ym) 的分布是什么。
由于p=X(k)在 X1,X2,⋯,Xn中是第k大的,利用Yi的信息,我们容易推理得到 p=X(k) 在X1,X2,⋯,Xn,Y1,Y2,⋯,Ym∼iidUniform(0,1) 这(m+n)个独立随机变量中是第 k+m1大的,于是按照上一个小节的推理,此时p=X(k) 的概率密度函数是 Beta(p|k+m1,n−k+1+m2)。按照贝叶斯推理的逻辑,我们把以上过程整理如下:
- p=X(k)是我们要猜测的参数,我们推导出 p 的分布为 f(p)=Beta(p|k,n−k+1),称为 p 的先验分布;
- 数据Yi中有m1个比p小,m2个比p大,Yi相当于是做了m次贝努利实验,所以m1 服从二项分布 B(m,p);
- 在给定了来自数据提供的(m1,m2)的知识后,p 的后验分布变为 f(p|m1,m2)=Beta(p|k+m1,n−k+1+m2)
 贝努利实验
贝努利实验
我们知道贝叶斯参数估计的基本过程是
先验分布 + 数据的知识 = 后验分布
以上贝叶斯分析过程的简单直观的表述就是
其中 (m1,m2) 对应的是二项分布B(m1+m2,p)的计数。更一般的,对于非负实数α,β,我们有如下关系
这个式子实际上描述的就是 Beta-Binomial 共轭,此处共轭的意思就是,数据符合二项分布的时候,参数的先验分布和后验分布都能保持Beta 分布的形式,这种形式不变的好处是,我们能够在先验分布中赋予参数很明确的物理意义,这个物理意义可以延续到后验分布中进行解释,同时从先验变换到后验过程中从数据中补充的知识也容易有物理解释。
而我们从以上过程可以看到,Beta 分布中的参数α,β都可以理解为物理计数,这两个参数经常被称为伪计数(pseudo-count)。基于以上逻辑,我们也可以把Beta(p|α,β)写成下式来理解
其中 Beta(p|1,1) 恰好就是均匀分布Uniform(0,1)。
对于(***) 式,我们其实也可以纯粹从贝叶斯的角度来进行推导和理解。 假设有一个不均匀的硬币抛出正面的概率为p,抛m次后出现正面和反面的次数分别是m1,m2,那么按传统的频率学派观点,p的估计值应该为 p^=m1m。而从贝叶斯学派的观点来看,开始对硬币不均匀性一无所知,所以应该假设p∼Uniform(0,1), 于是有了二项分布的计数(m1,m2)之后,按照贝叶斯公式如下计算p 的后验分布
计算得到的后验分布正好是 Beta(p|m1+1,m2+1)。
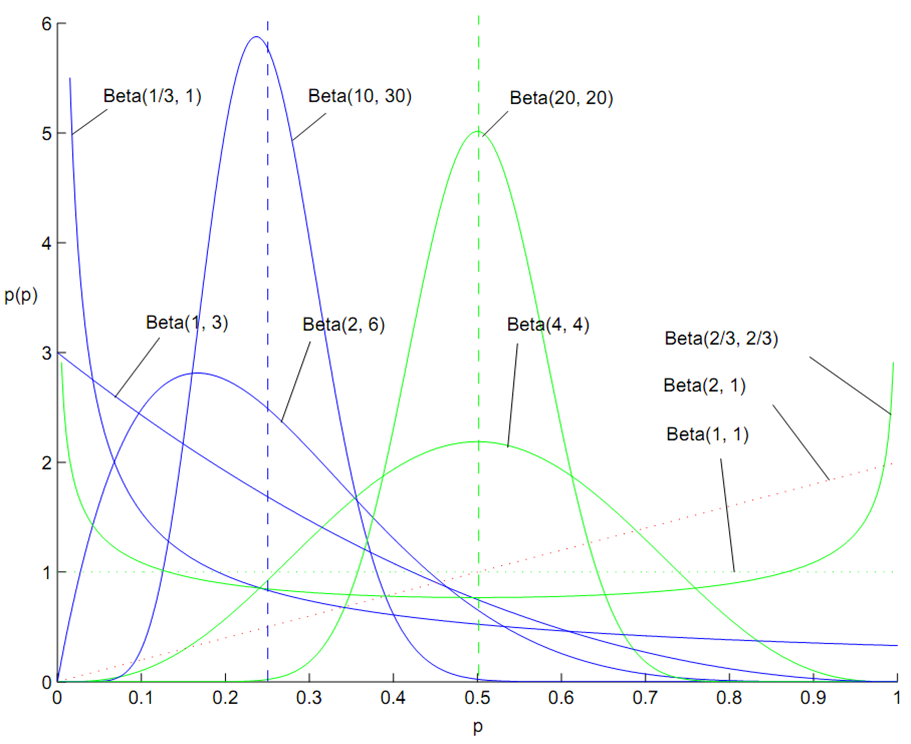
百变星君Beta分布
Beta 分布的概率密度我们把它画成图,会发现它是个百变星君,它可以是凹的、凸的、单调上升的、单调下降的;可以是曲线也可以是直线,而均匀分布也是特殊的Beta分布。由于Beta 分布能够拟合如此之多的形状,因此它在统计数据拟合中被广泛使用。
在上一个小节中,我们从二项分布推导Gamma 分布的时候,使用了如下的等式
现在大家可以看到,左边是二项分布的概率累积,右边实际上是Beta(t|k+1,n−k) 分布的概率积分。这个式子在上一小节中并没有给出证明,下面我们利用和魔鬼的游戏类似的概率物理过程进行证明。
我们可以如下构造二项分布,取随机变量 X1,X2,⋯,Xn∼iidUniform(0,1),一个成功的贝努利实验就是 Xi<p,否则表示失败,于是成功的概率为p。C用于计数成功的次数,于是C∼B(n,p)。
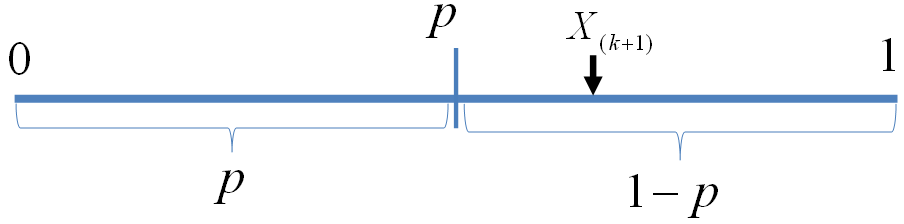
贝努利实验最多成功k次
显然我们有如下式子成立
此处X(k+1)是顺序统计量,为第k+1大的数。等式左边表示贝努利实验成功次数最多k次,右边表示第 k+1 大的数必然对应于失败的贝努利实验,从而失败次数最少是n−k次,所以左右两边是等价的。由于X(k+1)∼Beta(t|k+1,n−k), 于是
最后我们再回到魔鬼的游戏,如果你按出的5个随机数字中,魔鬼告诉你有2个小于它手中第7大的数,那么你应该
按照如下概率分布的峰值做猜测是最好的
很幸运的,你这次猜中了,魔鬼开始甩赖了:这个游戏对你来说太简单了,我要加大点难度,我们重新来一次,我按魔盒20下生成20个随机数,你同时给我猜第7大和第13大的数是什么,这时候应该如何猜测呢?
2.3 Dirichlet-Multinomial 共轭
对于魔鬼变本加厉的新的游戏规则,数学形式化如下:
- X1,X2,⋯,Xn∼iidUniform(0,1),
- 排序后对应的顺序统计量 X(1),X(2),⋯,X(n),
- 问 (X(k1),X(k1+k2))的联合分布是什么;
游戏3
完全类似于第一个游戏的推导过程,我们可以进行如下的概率计算(为了数学公式的简洁对称,我们取x3满足x1+x2+x3=1,但只有x1,x2是变量)

(X(k1),X(k1+k2))的联合分布推导
于是我们得到 (X(k1),X(k1+k2))的联合分布是
熟悉 Dirichlet的同学一眼就可以看出,上面这个分布其实就是3维形式的 Dirichlet 分布Dir(x1,x2,x3|k1,k2,n−k1−k2+1)。令 α1=k1,α2=k2,α3=n−k1−k2+1,于是分布密度可以写为
这个就是一般形式的3维 Dirichlet 分布,即便 α→=(α1,α2,α3) 延拓到非负实数集合,以上概率分布也是良定义的。
从形式上我们也能看出,Dirichlet 分布是Beta 分布在高维度上的推广,他和Beta 分布一样也是一个百变星君,密度函数可以展现出多种形态。
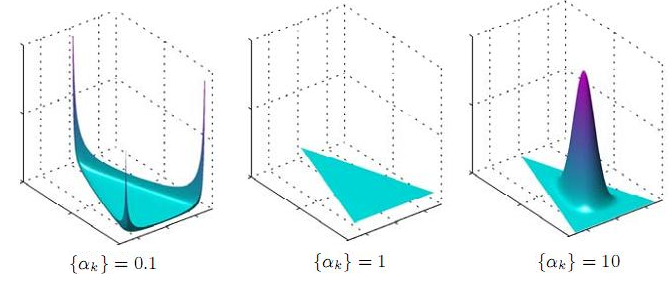 不同 α 下的Dirichlet 分布
不同 α 下的Dirichlet 分布
类似于魔鬼的游戏2,我们也可以调整一下游戏3,从魔盒中生成m个随机数Y1,Y2,⋯,Ym∼iidUniform(0,1) 并让魔鬼告诉我们Yi和(X(k1),X(k1+k2))相比谁大谁小。于是有如下游戏4
- X1,X2,⋯,Xn∼iidUniform(0,1),排序后对应的顺序统计量 X(1),X(2),⋯,X(n)
- 令p1=X(k1),p2=X(k1+k2),p3=1−p1−p2(加上p3是为了数学表达简洁对称),我们要猜测 p→=(p1,p2,p3);
- Y1,Y2,⋯,Ym∼iidUniform(0,1), Yi中落到[0,p1),[p1,p2),[p2,1] 三个区间的个数分别为 m1,m2,m3,m=m1+m2+m3;
- 问后验分布 P(p→|Y1,Y2,⋯,Ym) 的分布是什么。
游戏4
为了方便,我们记
由游戏中的信息,我们可以推理得到 p1,p2在X1,X2,⋯,Xn, Y1,Y2,⋯,Ym ∼iidUniform(0,1)这 m+n个数中分别成为了第 k1+m1,k2+m2大的数,于是后验分布 P(p→|Y1,Y2,⋯,Ym) 应该是 Dir(p→|k1+m1,k1+m2,n−k1−k2+1+m3),即Dir(p→|k→+m−→)。按照贝叶斯推理的逻辑,我们同样可以把以上过程整理如下:
- 我们要猜测参数 p→=(p1,p2,p3),其先验分布为Dir(p→|k→);
- 数据Yi落到[0,p1),[p1,p2),[p2,1]三个区间的个数分别为 m1,m2,m3,所以m−→=(m1,m2,m3) 服从多项分布Mult(m−→|p→)
- 在给定了来自数据提供的知识m−→后,p→ 的后验分布变为 Dir(p→|k→+m−→)
贝叶斯推理过程
以上贝叶斯分析过程的简单直观的表述就是
令 α→=k→,把α→从整数集合延拓到实数集合,更一般的可以证明有如下关系
以上式子实际上描述的就是 Dirichlet-Multinomial 共轭,而我们从以上过程可以看到,Dirichlet 分布中的参数α→都可以理解为物理计数。类似于 Beta 分布,我们也可以把 Dir(p→|α→)作如下分解
此处1→=(1,1,⋯,1)。自然,上式我们也可以类似地用纯粹贝叶斯的观点进行推导和解释。
以上的游戏我们还可以往更高的维度上继续推,譬如猜测 X(1),X(2),⋯,X(n)中的4、5、…等更多个数,于是就得到更高纬度的 Dirichlet 分布和 Dirichlet-Multinomial 共轭。一般形式的 Dirichlet 分布定义如下
对于给定的 p→和 N,多项分布定义为
而 Mult(n→|p→,N) 和 Dir(p→|α→)这两个分布是共轭关系。
Beta-Binomail 共轭和 Dirichlet-Multinomail 共轭都可以用纯粹数学的方式进行证明,我们在这两个小节中通过一个游戏来解释这两个共轭关系,主要是想说明这个共轭关系是可以对应到很具体的概率物理过程的。
2.4 Beta/Dirichlet 分布的一个性质
如果 p∼Beta(t|α,β), 则
上式右边的积分对应到概率分布 Beta(t|α+1,β),对于这个分布,我们有
把上式带入E(p)的计算式,得到
这说明,对于Beta 分布的随机变量,其均值可以用αα+β来估计。Dirichlet 分布也有类似的结论,如果p→∼Dir(t→|α→),同样可以证明
以上两个结论很重要,因为我们在后面的 LDA 数学推导中需要使用这个结论。
LDA-math-认识Beta/Dirichlet分布的更多相关文章
- 伯努利分布、二项分布、Beta分布、多项分布和Dirichlet分布与他们之间的关系,以及在LDA中的应用
在看LDA的时候,遇到的数学公式分布有些多,因此在这里总结一下思路. 一.伯努利试验.伯努利过程与伯努利分布 先说一下什么是伯努利试验: 维基百科伯努利试验中: 伯努利试验(Bernoulli tri ...
- LDA学习之beta分布和Dirichlet分布
---恢复内容开始--- 今天学习LDA主题模型,看到Beta分布和Dirichlet分布一脸的茫然,这俩玩意怎么来的,再网上查阅了很多资料,当做读书笔记记下来: 先来几个名词: 共轭先验: 在贝叶斯 ...
- 关于Beta分布、二项分布与Dirichlet分布、多项分布的关系
在机器学习领域中,概率模型是一个常用的利器.用它来对问题进行建模,有几点好处:1)当给定参数分布的假设空间后,可以通过很严格的数学推导,得到模型的似然分布,这样模型可以有很好的概率解释:2)可以利用现 ...
- Beta分布和Dirichlet分布
在<Gamma函数是如何被发现的?>里证明了\begin{align*} B(m, n) = \int_0^1 x^{m-1} (1-x)^{n-1} \text{d} x = \frac ...
- 机器学习的数学基础(1)--Dirichlet分布
机器学习的数学基础(1)--Dirichlet分布 这一系列(机器学习的数学基础)主要包括目前学习过程中回过头复习的基础数学知识的总结. 基础知识:conjugate priors共轭先验 共轭先验是 ...
- (转)机器学习的数学基础(1)--Dirichlet分布
转http://blog.csdn.net/jwh_bupt/article/details/8841644 这一系列(机器学习的数学基础)主要包括目前学习过程中回过头复习的基础数学知识的总结. 基础 ...
- mahout系列----Dirichlet 分布
Dirichlet分布可以看做是分布之上的分布.如何理解这句话,我们可以先举个例子:假设我们有一个骰子,其有六面,分别为{1,2,3,4,5,6}.现在我们做了10000次投掷的实验,得到的实验结果是 ...
- Dirichlet分布深入理解
Dirichlet分布 我们把Beta分布推广到高维的场景,就是Dirichlet分布.Dirichlet分布定义如下 Dirichlet分布与多项式分布共轭.多项式分布定义如下 共轭关系表示如下 D ...
- LDA处理文档主题分布代码
[python] LDA处理文档主题分布代码入门笔记 http://blog.csdn.net/eastmount/article/details/50824215
随机推荐
- 算法训练 Hankson的趣味题
算法训练 Hankson的趣味题 时间限制:1.0s 内存限制:64.0MB 问题描述 Hanks 博士是BT (Bio-Tech,生物技术) 领域的知名专家,他的儿子名叫Han ...
- .SQL Server中 image类型数据的比较
原文:.SQL Server中 image类型数据的比较 在SQL Server中如果你对text.ntext或者image数据类型的数据进行比较.将会提示:不能比较或排序 text.ntext 和 ...
- 网络拥塞控制(三) TCP拥塞控制算法
为了防止网络的拥塞现象,TCP提出了一系列的拥塞控制机制.最初由V. Jacobson在1988年的论文中提出的TCP的拥塞控制由“慢启动(Slow start)”和“拥塞避免(Congestion ...
- sqlserver 四舍五入(转)
select cast(round(12.5,2) as numeric(5,2)) 解释: round()函数,是四舍五入用,第一个参数是我们要被操作的数据,第二个参数是设置我们四舍五入 ...
- Swift-07-析构器deinit
析构器只适用于类类型,当一个类的实例被释放之前,析构器会被立即调用.析构器用关键字deinit来标识,类似于构造器用init来标识. 原理: Swift会自动释放不再需要的实例以释放资源.Swift通 ...
- LeetCode Majority Element I && II
原题链接在这里:Majority Element I,Majority Element II 对于Majority Element I 来说,有多重解法. Method 1:最容易想到的就是用Hash ...
- 团队冲刺the first day
2014年5月5号晚上我们团队小组一起做了团队项目.在此期间我们确定了项目的详细计划,,界面的安排,主界面,还有实现的具体功能,在这我就不做赘述了. 本次晚上我们做主界面,把界面和界面之间的调转实现了 ...
- you need to upgrade the working copy first
is too old (format 29) to work with client version '1.9.4 (r1740329)' (expects format 31) 2016年09月18 ...
- Apache kafka原理与特性(0.8V)
前言: kafka是一个轻量级的/分布式的/具备replication能力的日志采集组件,通常被集成到应用系统中,收集"用户行为日志"等,并可以使用各种消费终端(consumer) ...
- ubantu install chrome
ubantu apt-get installt -y openssh-server sudo apt-get -f install libappindicator1 libindicator7dpkg ...