【原创】Kakfa message包源代码分析
public class Message implements Serializable {
private CRC32 crc;
private short magic;
private boolean codecEnabled;
private short codecClassOrdinal;
private String key;
private String body;
}
可以看出,实现的方式是非常朴素和简单的,基本上就是由一个CRC32校验码、一个magic域、2个表明压缩类的字段以及两个表明消息的键值和消息本身的字符串组成。当与源代码中的实现方式做了比较时才发现自己的实现方式实在是too simple, sometimes naive了。在Java的内存模型中,对象保存的开销其实相当大,通常都要花费至少2倍以上的空间来保存数据(甚至更糟)。另外,随着堆数据越来越大,GC的性能下降得很多,将会变得非常缓慢。
在上面的实现中JMM会为字段进行重排以减少内存使用:
public class Message implements Serializable {
private short magic;
private short codecKlassOrdinal;
private boolean codecEnabled;
private CRC32 crc;
private String key;
private String body;
}
即使是这样,上面朴素的实现仍然需要40字节,而其中有7个字节只是为了补齐(padding)。Kafka实现的方式是使用nio.ByteBuffer来保存消息,同时依赖文件系统提供的页缓存机制,而不是依靠堆缓存。毕竟通常情况下,堆上保存的对象很有可能在os的页缓存中还保存一份,造成了资源的浪费。ByteBuffer是二进制的紧凑字节结构,而不是独立的对象,因此我们至少能够访问多一倍的可用内存。按照Kafka官网的说法,在一台32GB内存的机器上,Kafka几乎能用到28~30GB的物理内存同时还不比担心GC的糟糕性能。如果使用ByteBuffer来保存同样的消息,只需要24个字节,比起纯Java堆的实现减少了40%的空间占用,好处不言而喻。这种设计的好处还有加入了扩展的可能性。下图就是Kafka中Message的实现方式:
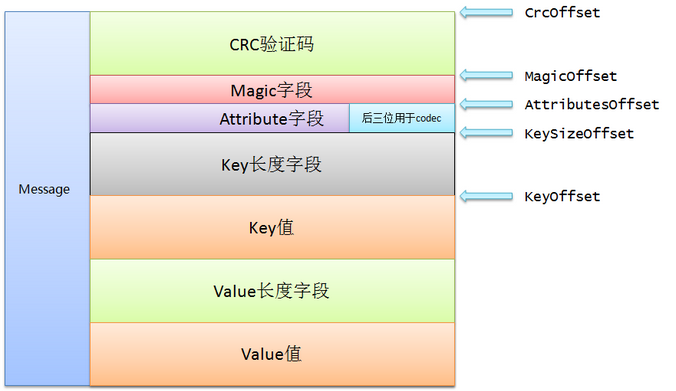
具体的域有: crc + magic + attribute + key + value,其中key + value 称为message overhead。虽然代码中起的名字都是offset,位移,但其实你可以理解为对应域在bytebuffer中的起始位移位置。由于个人是不太主张通篇把源代码贴上来的,毕竟大家都能下载到,所以这里就不全篇贴代码了。

【原创】Kakfa message包源代码分析的更多相关文章
- 【原创】Kakfa cluster包源代码分析
kafka.cluster包定义了Kafka的基本逻辑概念:broker.cluster.partition和replica——这些是最基本的概念.只有弄懂了这些概念,你才真正地使用kakfa来帮助完 ...
- 【原创】Kakfa log包源代码分析(二)
八.Log.scala 日志类,个人认为是这个包最重要的两个类之一(另一个是LogManager).以伴生对象的方式提供.先说Log object,既然是object,就定义了一些类级别的变量,比如定 ...
- 【原创】Kakfa log包源代码分析(一)
Kafka日志包是提供的是日志管理系统.主要的类是LogManager——该类负责处理所有的日志,并根据topic/partition分发日志.它还负责flush策略以及日志保存策略.Kafka日志本 ...
- 【原创】Kakfa network包源代码分析
kafka.network包主要为kafka提供网络服务,通常不包含具体的逻辑,都是一些最基本的网络服务组件.其中比较重要的是Receive.Send和Handler.Receive和Send封装了底 ...
- 【原创】Kakfa common包源代码分析
初一看common包的代码吓了一跳,这么多scala文件!后面仔细一看大部分都是Kafka自定义的Exception类,简直可以改称为kafka.exceptions包了.由于那些异常类的名称通常都定 ...
- 【原创】Kakfa api包源代码分析
既然包名是api,说明里面肯定都是一些常用的Kafka API了. 一.ApiUtils.scala 顾名思义,就是一些常见的api辅助类,定义的方法包括: 1. readShortString: 从 ...
- 【原创】Kakfa metrics包源代码分析
这个包主要是与Kafka度量相关的. 一.KafkaTimer.scala 对代码块的运行进行计时.仅提供一个方法: timer——在运行传入函数f的同时为期计时 二.KafkaMetricsConf ...
- 【原创】Kakfa serializer包源代码分析
这个包很简单,只有两个scala文件: decoder和encoder,就是提供序列化/反序列化的服务.我们一个一个说. 一.Decoder.scala 首先定义了一个trait: Decoder[T ...
- 【原创】kafka producer源代码分析
Kafka 0.8.2引入了一个用Java写的producer.下一个版本还会引入一个对等的Java版本的consumer.新的API旨在取代老的使用Scala编写的客户端API,但为了兼容性 ...
随机推荐
- WPF 窗口自适应
窗口自适应就是说,当主窗口缩放的时候,内部的控件位置自动的调整,而不是隐藏掉.这主要依赖于Grid布局. 1.比如这个groupbox 本身是在一个Grid的Row中的.缩放之后,左边的button不 ...
- Unity多单位战斗寻路问题的一种解决办法
Unity多单位战斗寻路问题的一种解决办法 Unity提供了NavMesh 导航组件 NavMesh是在实践中通用性最好的一种导航方式,但是Unity的实现并没有完全提供一个开放自由的API. 主 ...
- shell脚本常规技巧
邮件相关 发送邮件: #!/usr/bin/python import sys; import smtplib; from email.MIMEText import MIMEText mail_ho ...
- http学习笔记(二)—— 嘿!伙计,你在哪?(URL)
我们之所以希望浏览网页,其中一个重要的原因就是庞大的web世界中有很丰富的资源,他就像哆啦a梦的口袋,随时都能拿出我们想要的宝贝.这些资源通过http被传送到我们的浏览器,并展示到我们的屏幕上.而我们 ...
- .NET学习笔记 -- 那堆名词到底是啥(CLR、CLI、CTS、CLS、IL、JIT)
什么是CLR? CLR,公共语言运行时(Common Language Runtime)是一个由多种语言使用的“运行时”.他的核心功能包括(内存管理.程序集加载.安全性.异常处理和线程同步),可以被面 ...
- 腾讯Ubuntu云虚拟主机设置ftp服务器
刚申请了免费的腾讯云主机, 发现还要想办法自己的服务器代码传到云主机上 在网上搜了很多方法介绍, 照着设置完后都无法正常连接 最后半夜尿醒来睡不着找到一篇站内文章, 提到必须注释掉一行代码 这个是其他 ...
- NodeJS系列~第四个小例子,NodeJs处理Get请求和Post请求
返回目录 说在前 对于HTTP请求来说,我们通常使用的是Get和Post,除此之外还有put,delete等,而对于get来说,比较lightweight,只是对字符串的传输,它会被添加到URL地址里 ...
- 在Windows下安装Memcached
Windows下的Memcache安装: 需要运行命令行工具cmd 请以管理员权限运行 开始->附件->命令提示符,以管理员身份运行 假如当前C:\windows\system32,输入c ...
- ASP.net的文件扩展名
尽管ASP.NET中采用的是事件响应模式,使程序开发人员和最终用户感觉与WinForm程序非常接近,但是它毕竟还是Web应用程序.而Web应用程序的特点,就是基于浏览器与服务器的请求与响应的执行方式. ...
- Atitit USRqc62204 证书管理器标准化规范
Atitit USRqc62204 证书管理器标准化规范 /atiplat_cms/src/com/attilax/cert/CertSrv4mv.java /** * */ package com. ...