Deep learning:四十三(用Hessian Free方法训练Deep Network)
目前,深度网络(Deep Nets)权值训练的主流方法还是梯度下降法(结合BP算法),当然在此之前可以用无监督的方法(比如说RBM,Autoencoder)来预训练参数的权值,而梯度下降法应用在深度网络中的一个缺点是权值的迭代变化值会很小,很容易收敛到的局部最优点;另一个缺点是梯度下降法不能很好的处理有病态的曲率(比如Rosenbrock函数)的误差函数。而本文中所介绍的Hessian Free方法(以下简称HF)可以不用预训练网络的权值,效果也还不错,且其适用范围更广(可以用于RNN等网络的学习),同时克服了上面梯度下降法的那2个缺点。HF的主要思想类似于牛顿迭代法,只是并没有显示的去计算误差曲面函数某点的Hessian矩阵H,而是通过某种技巧直接算出H和任意向量v的乘积Hv(该矩阵-向量的乘积形式在后面的优化过程中需要用到),因此叫做”Hessian Free”。本文主要是读完Martens的论文Deep learning via Hessian-free optimization记下的一些笔记(具体内容请参考论文部分)。
Hessian Free方法其实在多年前就已经被使用,但为什么Martens论文又重提这个方法呢?其实它们的不同在于H矩阵”free”的方式不同,因为隐式计算H的方法可以有很多种,而算法的名字都可以叫做HF,因此不能简单的认为Martens文章中在Deep Learning中的HF方法就是很久以前存在的方法了(如果真是如此,Deep Learning在N年前就火了!),只能说明它们的思想类似。将HF思想应用于DL网络时,需要用到各种技巧,而数学优化本身就是各种技巧、近似的组合。Matrens主要使用2个大思想+5个小技巧(论文给出的大概是5个,但是其code里面还有不少技巧论文中没有提到)来完成DL网络的训练。
idea 1:利用某种方法计算Hv的值(v任意),比如说常见的对误差导函数用有限差分法来高精度近似计算Hv(见下面公式),这比以前只是用一个对角矩阵近似Hessian矩阵保留下来的信息要多很多。通过计算隐式计算Hv,可以避免直接求H的逆,一是因为H太大,二是H的逆有可能根本不存在。
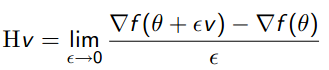
idea 2:用下面二次项公式来近似得到θ值附近的函数值。且最佳搜索方向p由CG迭代法(该算法简单介绍见前面博文:机器学习&数据挖掘笔记_12(对Conjugate Gradient 优化的简单理解))求得。
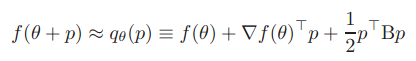
技巧1:计算Hv时并不是直接用有限差分法,而是利用Pearlmutter的R-operator方法(没看懂,但是该方法优点有很多)。
技巧2:用Gauss-Newton矩阵G来代替Hessian矩阵H,所以最终隐式计算的是Gv.
技巧3:作者给出了用CG算法(有预条件的CG,即先对参数θ进行了一次线性坐标变换)求解θ搜索方向p时的迭代终止条件,即:
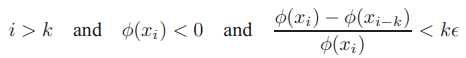
技巧4:在进行处理大数据学习时,用CG算法进行线性搜索时并没有用到所有样本,而是采用的mini-batch,因为从一些mini-batch样本已经可以获得关于曲面的一些有效曲率信息。
技巧5:用启发式的方法(Levenburg-Marquardt)求得系统的阻尼系数λ,该系数在预条件的CG算法中有用到,预条件矩阵M的计算公式为:
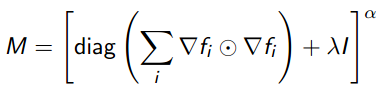
上面的7点需要详细阅读Martens的paper,且结合其paper对应的code来读(code见他的个人主页http://www.cs.toronto.edu/~jmartens/research.html).
下面来简单看看HF的流程图:
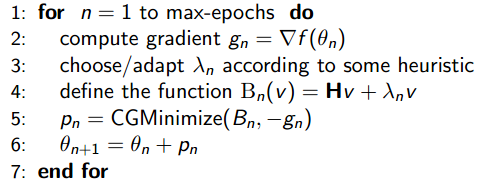
流程图说明的是:定义好系统的目标函数,见本博客中的第2个公式,接着定义一个最大权值更新次数max-epochs,每次循环时首先用BP算法求出目标函数的梯度值,接着用启发式的方法取得λ值,然后预条件CG方法来优化参数搜索方向p(此过程需要用到Hv形式的求解函数),最后更新参数进入下一轮。
关于code部分,简单说以下几点:
运行该程序,迭代到170次,共用了差不多20个小时,程序的输出如下:
maxiters = ; miniters =
CG steps used: , total is:
ch magnitude : 7.7864
Chose iters :
rho = 0.50606
Number of reductions : , chosen rate:
New lambda: 0.0001043
epoch: , Log likelihood: -54.7121, error rate: 0.25552
TEST Log likelihood: -87.9114, error rate: 3.5457
Error rate difference (test - train): 3.2901
code完成的是CURVES数据库的分类,用的是Autoencoder网络,网络的层次结构为:[784 400 200 100 50 25 6 25 50 100 200 400 784]。
conjgrad_1(): 完成的是预条件的CG优化算法,函数求出了CG所迭代的步数以及优化的结果(搜索方向)。
computeGV(): 完成的是矩阵Gv的计算,结合了R操作和Gauss-Newton方法。
computeLL(): 计算样本输出值的log似然以及误差(不同激发函数的输出节点其误差公式各异)。
nnet_train_2():该函数当然是核心函数了,直接用来训练一个DL网络,里面当少不了要调用conjgrad_1(),computeGV(),computeLL(),另外关于误差曲面函数导数的求法也是用的经典BP算法。
参考资料:
Martens, J. (2010). Deep learning via Hessian-free optimization. Proceedings of the 27th International Conference on Machine Learning (ICML-10).
机器学习&数据挖掘笔记_12(对Conjugate Gradient 优化的简单理解)
http://www.cs.toronto.edu/~jmartens/research.html
http://pillowlab.wordpress.com/2013/06/11/lab-meeting-6102013-hessian-free-optimization/
Deep learning:四十三(用Hessian Free方法训练Deep Network)的更多相关文章
- 深度学习FPGA实现基础知识10(Deep Learning(深度学习)卷积神经网络(Convolutional Neural Network,CNN))
需求说明:深度学习FPGA实现知识储备 来自:http://blog.csdn.net/stdcoutzyx/article/details/41596663 说明:图文并茂,言简意赅. 自今年七月份 ...
- Neural Networks and Deep Learning(week2)Logistic Regression with a Neural Network mindset(实现一个图像识别算法)
Logistic Regression with a Neural Network mindset You will learn to: Build the general architecture ...
- Deep Learning 学习笔记(6):神经网络( Neural Network )
神经元: 在神经网络的模型中,神经元可以表示如下 神经元的左边是其输入,包括变量x1.x2.x3与常数项1, 右边是神经元的输出 神经元的输出函数被称为激活函数(activation function ...
- Deep Learning(深度学习)学习笔记整理系列之(四)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- deep learning 以及deep learning 常用模型和方法
首先为什么会有Deep learning,我们得到一个结论就是Deep learning需要多层来获得更抽象的特征表达. 1.Deep learning与Neural Network 深度学习是机器学 ...
- 【转】Deep Learning(深度学习)学习笔记整理系列之(四)
九.Deep Learning的常用模型或者方法 9.1.AutoEncoder自动编码器 Deep Learning最简单的一种方法是利用人工神经网络的特点,人工神经网络(ANN)本身就是具有层次结 ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- Deep Learning 10_深度学习UFLDL教程:Convolution and Pooling_exercise(斯坦福大学深度学习教程)
前言 理论知识:UFLDL教程和http://www.cnblogs.com/tornadomeet/archive/2013/04/09/3009830.html 实验环境:win7, matlab ...
- Deep Learning 6_深度学习UFLDL教程:Softmax Regression_Exercise(斯坦福大学深度学习教程)
前言 练习内容:Exercise:Softmax Regression.完成MNIST手写数字数据库中手写数字的识别,即:用6万个已标注数据(即:6万张28*28的图像块(patches)),作训练数 ...
随机推荐
- 读bootstrap2.3.2有感2
排版: Bootstrap定义的全局 font-size 是 14px,line-height 是 20px.这些样式应用到了 <body> 和所有的段落上.另外,对 <p> ...
- Python小爬虫练习
# coding: utf-8 __author__ = 'zhangcx' from urllib3 import PoolManager import codecs import json cla ...
- 分享工作中遇到的问题积累经验 事务日志太大导致insert不进数据
分享工作中遇到的问题积累经验 事务日志太大导致insert不进数据 今天开发找我,说数据库insert不进数据,叫我看一下 他发了一个截图给我 然后我登录上服务器,发现了可疑的地方,而且这个数据库之前 ...
- Android性能优化典范第二季
Google前几天刚发布了Android性能优化典范第2季的课程,一共20个短视频,包括的内容大致有:电量优化,网络优化,Wear上如何做优化,使用对象池来提高效率,LRU Cache,Bitma ...
- Linux 学习笔记(一) 入门
Shell 显示Shell类型 $ps 切换Shell $[Shell 名称] ex. $tcsh 快捷键 Ctrl + Z:挂起,可用jobs查看到,fg恢复运行 Ctrl + W:删除单词 Ct ...
- EntityFunctions.AsNonUnicode
http://blog.csdn.net/zzx3q/article/details/7863797 使用工具VS2010 凡是调用FindAll的地方,如果传入参数是String类型的变量(数字类型 ...
- 如何用MediaCapture解决二维码扫描问题
二维码扫描的实现,简单的来说可以分三步走:“成像”.“截图”与“识别”. UWP开发中,最常用的媒体工具非MediaCapture莫属了,下面就来简单介绍一下如何利用MediaCapture来实现扫描 ...
- JDBC学习2:为什么要写Class.forName("XXX")?
Class.forName(String name) 接上一篇JDBC.本来这个内容是放在前面的一篇里面的一起的,后来发现越写越多,想想看就算了,还是单独开一篇文章好了,这样也能写得更加详细点. 上一 ...
- 与webview打交道中踩过的那些坑
随着HTML5被越来越多的用到web APP的开发当中,webview这一个神器便日渐凸显出重要地位.简要的说,webview能够在移动应用中开辟出一个窗口,在里面显示html页面,css以及js代码 ...
- TCP Server—Linux
#include <stdio.h> #include <netinet/ip.h> #define BUFF_SIZE 1024 int main(int argc,char ...