深度学习笔记(六)finetune
一般来说我们自己需要做的方向,比如在一些特定的领域的识别分类中,我们很难拿到大量的数据。因为像在ImageNet上毕竟是一个千万级的图像数据库,通常我们可能只能拿到几千张或者几万张某一特定领域的图像,比如识别衣服啊、标志啊、生物种类等等。在这种情况下重新训练一个新的网络是比较复杂的,而且参数不好调整,数据量也不够,因此fine-tuning微调就是一个比较理想的选择。
所谓fine tune就是用别人训练好的模型,加上我们自己的数据,来训练新的模型。fine tune相当于使用别人的模型的前几层,来提取浅层特征,然后在最后再落入我们自己的分类中。
fine tune的好处在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是fine tune能够让我们在比较少的迭代次数之后得到一个比较好的效果。在数据量不是很大的情况下,fine tune会是一个比较好的选择。但是如果你希望定义自己的网络结构的话,就需要从头开始了。
我们可以在ImageNet上1000类分类训练好的参数的基础上,根据我们的分类识别任务进行特定的微调。
这里我以一个车型的识别为例,假设我们有431种车型需要识别,我的任务对象是车,现在有ImageNet的模型参数文件,在这里使用的网络模型是CaffeNet,是一个小型的网络,其实别的网络如GoogleNet也是一样的原理。那么这个任务的变化可以表示为:
任务:分类
类别数目:(ImageNet上1000类的分类任务)------> (自己的特定数据集的分类任务431车型) 利用已有网络及模型:
./models/bvlc_reference_caffenet/
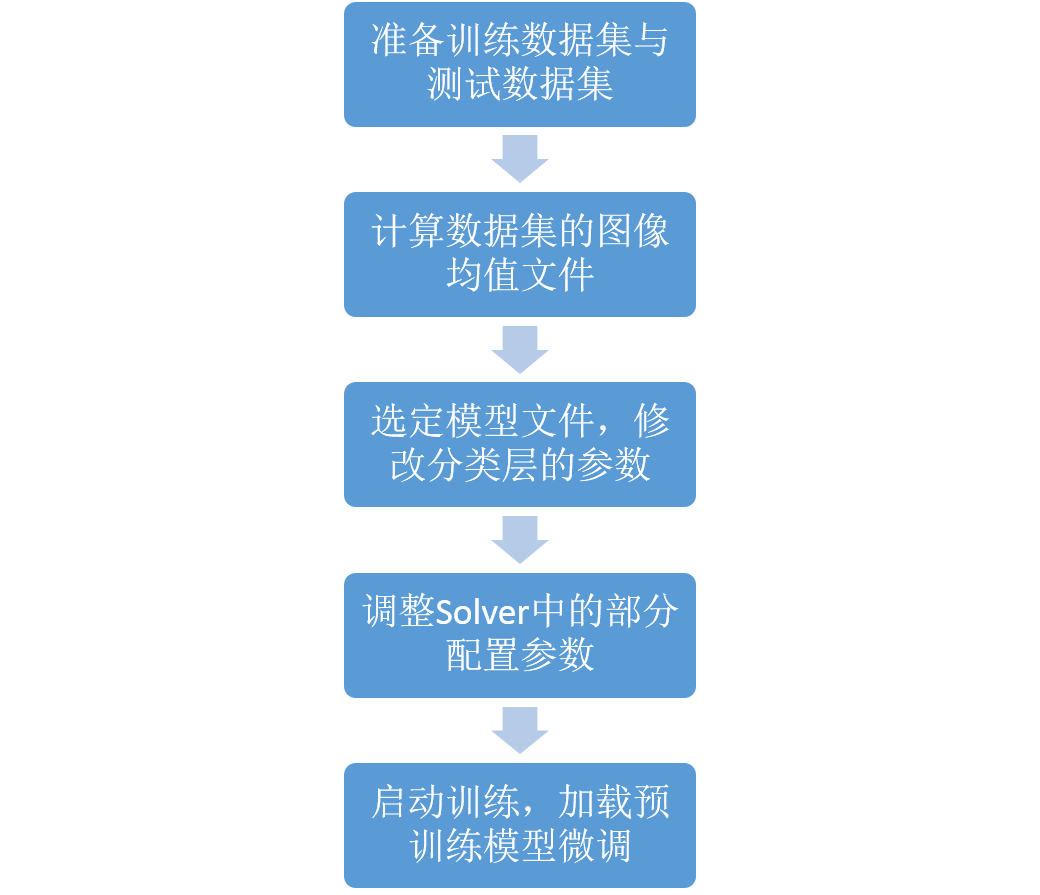
那么在网络的微调中,我们的整个流程分为以下几步:
- 依然是准备好我们的训练数据和测试数据
- 计算数据集的均值文件,因为集中特定领域的图像均值文件会跟ImageNet上比较General的数据的均值不太一样
- 修改网络最后一层的输出类别,并且需要加快最后一层的参数学习速率
- 调整Solver的配置参数,通常学习速率和步长,迭代次数都要适当减少
- 启动训练,并且需要加载pretrained模型的参数
简单的用流程图示意一下:
1.准备数据集
这一点就不用说了,准备两个txt文件,放成list的形式,可以参考caffe下的example,图像路径之后一个空格之后跟着类别的ID,如下,这里记住ID必须从0开始,要连续,否则会出错,loss不下降,按照要求写就OK。
这个是训练的图像label,测试的也同理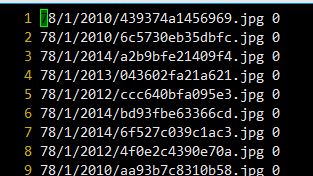
2.计算数据集的均值文件
使用caffe下的convert_imageset工具
具体命令是
/home/chenjie/louyihang/caffe/build/tools/convert_imageset /home/chenjie/DataSet/CompCars/data/cropped_image/ ../train_test_split/classification/train_model431_label_start0.txt ../intermediate_data/train_model431_lmdb -resize_width=227 -resize_height=227 -check_size -shuffle true
其中第一个参数是基地址路径用来拼接的,第二个是label的文件,第三个是生成的数据库文件支持leveldb或者lmdb,接着是resize的大小,最后是否随机图片顺序
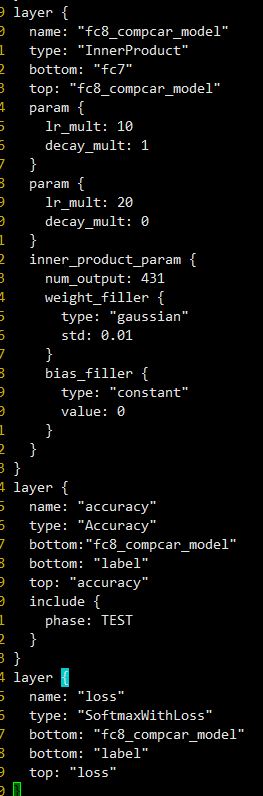
3.调整网络层参数
参照Caffe上的例程,我用的是CaffeNet,首先在输入层data层,修改我们的source 和 meanfile, 根据之前生成的lmdb 和mean.binaryproto修改即可
最后输出层是fc8,
1.首先修改名字,这样预训练模型赋值的时候这里就会因为名字不匹配从而重新训练,也就达成了我们适应新任务的目的。
1.调整学习速率,因为最后一层是重新学习,因此需要有更快的学习速率相比较其他层,因此我们将,weight和bias的学习速率加快10倍。
原来是fc8,记得把跟fc8连接的名字都要修改掉,修改后如下
4.修改Solver参数
原来的参数是用来training from scratch,从原始数据进行训练的,因此一般来说学习速率、步长、迭代次数都比较大,在fine-tuning 微调呢,也正如它的名字,只需要微微调整,以下是两个对比图
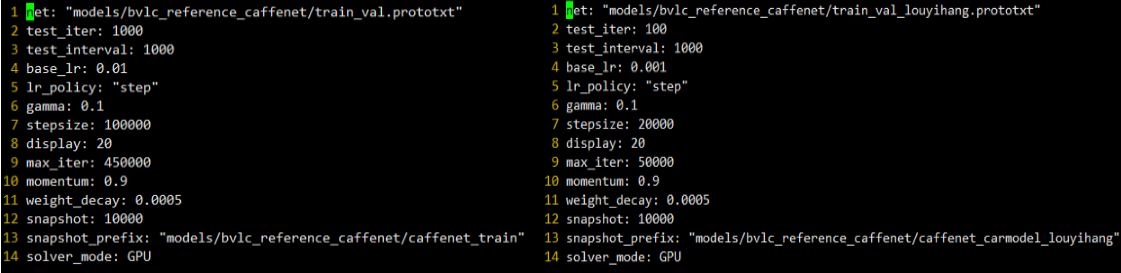
主要的调整有:test_iter从1000改为了100,因为数据量减少了,base_lr从0.01变成了0.001,这个很重要,微调时的基本学习速率不能太大,学习策略没有改变,步长从原来的100000变成了20000,最大的迭代次数也从450000变成了50000,动量和权重衰减项都没有修改,依然是GPU模型,网络模型文件和快照的路径根据自己修改
5.开始训练!
首先你要从caffe zoo里面下载一下CaffeNet网络用语ImageNet1000类分类训练好的模型文件,名字是bvlc_reference_caffenet.caffemodel
训练的命令如下:

OK,最后达到的性能还不错accuray 是0.9,loss降的很低,这是我的caffe初次体验,希望能帮到大家!
而如果是由于某些原因,训练中断了,需要继续训练,则将 --weights 替换成 --snapshot .caffemodel 替换成 .solverstate
深度学习笔记(六)finetune的更多相关文章
- 深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam)
深度学习笔记:优化方法总结(BGD,SGD,Momentum,AdaGrad,RMSProp,Adam) 深度学习笔记(一):logistic分类 深度学习笔记(二):简单神经网络,后向传播算法及实现 ...
- UFLDL深度学习笔记 (六)卷积神经网络
UFLDL深度学习笔记 (六)卷积神经网络 1. 主要思路 "UFLDL 卷积神经网络"主要讲解了对大尺寸图像应用前面所讨论神经网络学习的方法,其中的变化有两条,第一,对大尺寸图像 ...
- Learning ROS for Robotics Programming Second Edition学习笔记(六) indigo xtion pro live
中文译著已经出版,详情请参考:http://blog.csdn.net/ZhangRelay/article/category/6506865 Learning ROS for Robotics Pr ...
- UFLDL深度学习笔记 (四)用于分类的深度网络
UFLDL深度学习笔记 (四)用于分类的深度网络 1. 主要思路 本文要讨论的"UFLDL 建立分类用深度网络"基本原理基于前2节的softmax回归和 无监督特征学习,区别在于使 ...
- Google TensorFlow深度学习笔记
Google Deep Learning Notes Google 深度学习笔记 由于谷歌机器学习教程更新太慢,所以一边学习Deep Learning教程,经常总结是个好习惯,笔记目录奉上. Gith ...
- java之jvm学习笔记六-十二(实践写自己的安全管理器)(jar包的代码认证和签名) (实践对jar包的代码签名) (策略文件)(策略和保护域) (访问控制器) (访问控制器的栈校验机制) (jvm基本结构)
java之jvm学习笔记六(实践写自己的安全管理器) 安全管理器SecurityManager里设计的内容实在是非常的庞大,它的核心方法就是checkPerssiom这个方法里又调用 AccessCo ...
- Typescript 学习笔记六:接口
中文网:https://www.tslang.cn/ 官网:http://www.typescriptlang.org/ 目录: Typescript 学习笔记一:介绍.安装.编译 Typescrip ...
- python3.4学习笔记(六) 常用快捷键使用技巧,持续更新
python3.4学习笔记(六) 常用快捷键使用技巧,持续更新 安装IDLE后鼠标右键点击*.py 文件,可以看到Edit with IDLE 选择这个可以直接打开编辑器.IDLE默认不能显示行号,使 ...
- Go语言学习笔记六: 循环语句
Go语言学习笔记六: 循环语句 今天学了一个格式化代码的命令:gofmt -w chapter6.go for循环 for循环有3种形式: for init; condition; increment ...
- UFLDL深度学习笔记 (二)SoftMax 回归(矩阵化推导)
UFLDL深度学习笔记 (二)Softmax 回归 本文为学习"UFLDL Softmax回归"的笔记与代码实现,文中略过了对代价函数求偏导的过程,本篇笔记主要补充求偏导步骤的详细 ...
随机推荐
- 关于网络-get/post
关于网络: //英译 connection:连接 append:添加 resign:放弃 // 加载网页数据 步骤 [self.webView loadRequest:request]; NSURL ...
- Python requests模拟登录
Python requests模拟登录 #!/usr/bin/env python # encoding: UTF-8 import json import requests # 跟urllib,ur ...
- hdu4135 容斥定理
Co-prime Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Su ...
- Leetcode jump Game II
Given an array of non-negative integers, you are initially positioned at the first index of the arra ...
- Java_动态重新加载Class机制
Java动态重新加载Class 项目中使用到了动态重新加载Class的机制,作用是让一些代码上线之前可以在线上环境测试一下,当然,这是非常不好的测试机制,我刚来的时候也为这种机制感到惊讶—怎么可以在线 ...
- Self-introduction (自我介绍)
* 姓名,本名不想这样就暴露,Rachel我英文名,不愿意叫算了,直接叫我米蟲就好了. * 性格, 偏执一些,表里不一,表面和善,骨子倔强,我这一生都在追求高逼格,从未间断过 偶尔像个小疯子,有 ...
- BZOJ3687 计算子集和的异或和
题不知道怎么不见了,bzoj上已经没了3687这题了 题意:给你一个n 然后输入n个数 求这n个数的所有子集的和的异或和 思路:用bitset记录某个数是否在子集和中出现,利用bitset对二进制位的 ...
- easyUI下拉列表三级联动
首先是先想好数据库的搭建,通过地区id,地区名称,上级地区id就可以实现,所有省市区的数据 例如: DAO层 service层 Servlet 页面 <!DOCTYPE html> < ...
- Android课程---如何用网格视图做出手机桌面APP
activity_test.xml <?xml version="1.0" encoding="utf-8"?> <GridView xmln ...
- 获取程序的SHA1值
android获取程序的SHA1值 public static String getSHA1(Context context) { try { PackageInfo info = context.g ...