python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书
- 1、初衷:想在网上批量下载点听书、脱口秀之类,资源匮乏,大家可以一试
- 2、技术:wireshark scrapy jsonMonogoDB
- 3、思路:wireshark分析移动APP返回的各种连接分类、列表、下载地址等(json格式)
- 4、思路:scrapy解析json,并生成下载连接
- 5、思路:存储到MongoDB
- 6、难点:wireshark分析各类地址,都是简单的scrapy的基础使用,官网的说明文档都有
- 7、按照:tree /F生成的文件目录进行说明吧
1 items.py 字段设置,根据需要改变
'''
from scrapy import Item,Field
class QtscrapyItem(Item):
id = Field()
parent_info = Field()
title = Field()
update_time = Field()
file_path = Field()
source = Field()
'''
2 pipelines.py 字段设置及相关处理,根据需要改变
'''
import pymongo as pymongo
from scrapy import signals
import json
import codecs
from scrapy.conf import settings
class QtscrapyPipeline(object):
def init(self):
self.file = codecs.open('qingting_209.json', 'wb', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
# print(line)
self.file.write(line)
return item
class QtscrapyMongoPipeline(object):
def init(self):
host = settings['MONGODB_HOST']
port = settings['MONGODB_PORT']
dbName = settings['MONGODB_DBNAME']
client = pymongo.MongoClient(host=host, port=port)
tdb = client[dbName]
self.post = tdb[settings['MONGODB_DOCNAME']]
def process_item(self, item, spider):
qtfm = dict(item)
self.post.insert(qtfm)
return item
'''
3 settings.py 基础配置 配置数据库存储相关 QtscrapyPipeline 来自pipelines.py中定义的类
'''
ITEM_PIPELINES = {
# 'qtscrapy.pipelines.QtscrapyPipeline': 300,
'qtscrapy.pipelines.QtscrapyMongoPipeline': 300,
}
MONGODB_HOST = '127.0.0.1'
MONGODB_PORT = 12345
MONGODB_DBNAME = 'qingtingDB'
MONGODB_DOCNAME = 'qingting'
'''
└─spiders
4 qingting.py 爬虫,各显神通
'''
from scrapy.spiders import BaseSpider
from scrapy.http import Request
import sys, json
from qtscrapy.items import QtscrapyItem
from scrapy_redis.spiders import RedisSpider
reload(sys)
sys.setdefaultencoding("utf-8")
1 酷我听书地址分析
http://ts.kuwo.cn/service/gethome.php?act=new_home
http://ts.kuwo.cn/service/getlist.v31.php?act=catlist&id=97
http://ts.kuwo.cn/service/getlist.v31.php?act=cat&id=21&type=hot
http://ts.kuwo.cn/service/getlist.v31.php?act=detail&id=100102396
2 配合Redis使用class qtscrapy(RedisSpider):
class qtscrapy(BaseSpider):
name = "qingting"
# redis_key = 'qingting:start_urls'
base_url = "http://api2.qingting.fm/v6/media/recommends/guides/section/"
start_urls = ["http://api2.qingting.fm/v6/media/recommends/guides/section/0",
"http://ts.kuwo.cn/service/gethome.php?act=new_home",
"http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=0&pageNum=0&pageSize=500&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&q=0&imei=ODY1MTY2MDIxNzMzNjI0"]
allowed_domains = ["api2.qingting.fm", "ts.kuwo.cn", "api.mting.info"]
def parse(self, response):
3 根据返回的url判断,在思考是scrapy执行多爬虫还是这种混杂
if "qingting" in response.url:
qt_json = json.loads(response.body, encoding="utf-8")
if qt_json["data"] is not None:
for data in qt_json["data"]:
if data is not None:
for de in data["recommends"]:
if de["parent_info"] is None:
pass
else:
jm_url = "http://api2.qingting.fm/v6/media/channelondemands/%(parent_id)s/programs/curpage/1/pagesize/1000" % \
de["parent_info"]
yield Request(jm_url, callback=self.get_qt_jmlist, meta={"de": de})
for i in range(0, 250):
url = self.base_url + str(i)
yield Request(url, callback=self.parse)
if "kuwo" in response.url:
kw_json = json.loads(response.body, encoding="utf-8")
if kw_json["cats"] is not None:
for data in kw_json["cats"]:
pp_id = data["Id"]
kw_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=catlist&id=%s" % pp_id
yield Request(kw_url, callback=self.get_kw_catlist)
if "mting" in response.url:
# print(response)
lr_json = json.loads(response.body, encoding="utf-8")
if len(lr_json["list"]) > 0:
for l in lr_json["list"]:
try:
lr_url = "http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=%(id)s&pageNum=0&pageSize=1000&sort=2&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&imei=ODY1MTY2MDIxNzMzNjI0" % l
yield Request(lr_url, callback=self.get_lr_booklist)
except:
pass
for r in range(-10, 1000):
lr_url = "http://api.mting.info/yyting/bookclient/ClientTypeResource.action?type=%s&pageNum=0&pageSize=1000&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&q=0&imei=ODY1MTY2MDIxNzMzNjI0" % t
yield Request(lr_url, callback=self.parse)
4 需递归几次是由App结构决定的
def get_qt_jmlist(self, response):
jm_json = json.loads(response.body, encoding="utf-8")
de = response.meta["de"]
for jm_data in jm_json["data"]:
if jm_data is None:
pass
else:
try:
file_path = "http://upod.qingting.fm/%(file_path)s?deviceid=ffffffff-ebbe-fdec-ffff-ffffb1c8b222" % \
jm_data["mediainfo"]["bitrates_url"][0]
item = QtscrapyItem()
# print(item)
# print(jm_data["id"])
item["id"] = str(jm_data["id"])
parent_info = "%(parent_id)s_%(parent_name)s" % de["parent_info"]
item["parent_info"] = parent_info
item["title"] = jm_data["title"]
item["update_time"] = str(jm_data["update_time"])[:str(jm_data["update_time"]).index(' ')]
item["file_path"] = file_path
item["source"] = "qingting"
yield item
except:
pass
pass
def get_kw_catlist(self, response):
try:
kw_json = json.loads(response.body, encoding="utf-8")
if kw_json["sign"] is not None:
if kw_json["list"] is not None:
for data in kw_json["list"]:
p_id = data["Id"]
kw_p_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=cat&id=%s&type=hot" % p_id
yield Request(kw_p_url, callback=self.get_kw_cat)
except:
print("*" * 300)
print(self.name, kw_json)
pass
def get_kw_cat(self, response):
try:
kw_json = json.loads(response.body, encoding="utf-8")
p_info = {}
if kw_json["sign"] is not None:
if kw_json["list"] is not None:
for data in kw_json["list"]:
id = data["Id"]
p_info["p_id"] = data["Id"]
p_info["p_name"] = data["Name"]
kw_pp_url = "http://ts.kuwo.cn/service/getlist.v31.php?act=detail&id=%s" % id
yield Request(kw_pp_url, callback=self.get_kw_jmlist, meta={"p_info": p_info})
except:
print("*" * 300)
print(self.name, kw_json)
pass
def get_kw_jmlist(self, response):
jm_json = json.loads(response.body, encoding="utf-8")
p_info = response.meta["p_info"]
for jm_data in jm_json["Chapters"]:
if jm_data is None:
pass
else:
try:
file_path = "http://cxcnd.kuwo.cn/tingshu/res/WkdEWF5XS1BB/%s" % jm_data["Path"]
item = QtscrapyItem()
item["id"] = str(jm_data["Id"])
parent_info = "%(p_id)s_%(p_name)s" % p_info
item["parent_info"] = parent_info
item["title"] = jm_data["Name"]
item["update_time"] = ""
item["file_path"] = file_path
item["source"] = "kuwo"
yield item
except:
pass
pass
def get_lr_booklist(self, response):
s_lr_json = json.loads(response.body, encoding="utf-8")
if len(s_lr_json["list"]) > 0:
for s_lr in s_lr_json["list"]:
s_lr_url = "http://api.mting.info/yyting/bookclient/ClientGetBookResource.action?bookId=%(id)s&pageNum=1&pageSize=2000&sortType=0&token=_4WfzpCah8ujgJZZzboaUGkJQvWGfEEL-zdukwv7lbY*&imei=ODY1MTY2MDIxNzMzNjI0" % s_lr
meta = {}
meta["id"] = s_lr["id"]
meta["name"] = s_lr["name"]
yield Request(s_lr_url, callback=self.get_lr_kmlist, meta={"meta": meta})
def get_lr_kmlist(self, response):
ss_lr_json = json.loads(response.body, encoding="utf-8")
parent = response.meta["meta"]
if len(ss_lr_json["list"]) > 0:
for ss_lr in ss_lr_json["list"]:
try:
item = QtscrapyItem()
item["id"] = str(ss_lr["id"])
parent_info = "%(id)s_%(name)s" % parent
item["parent_info"] = parent_info
item["title"] = ss_lr["name"]
item["update_time"] = ""
item["file_path"] = ss_lr["path"]
item["source"] = "lr"
yield item
except:
pass
'''
5 结果展示,爬取了大概40万记录
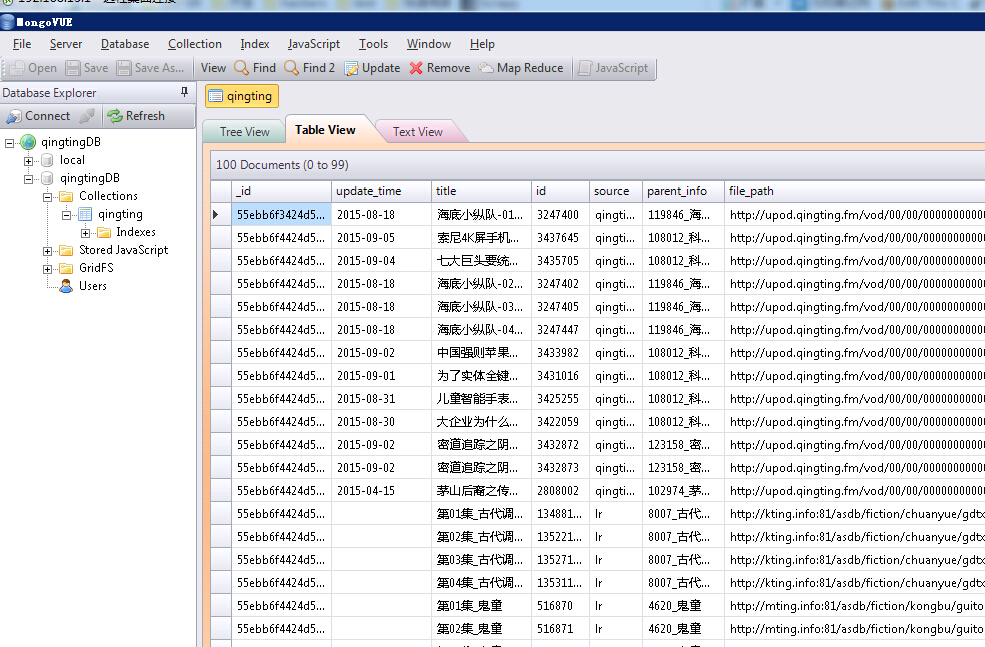
python scrapy+Mongodb爬取蜻蜓FM,酷我及懒人听书的更多相关文章
- 教程+资源,python scrapy实战爬取知乎最性感妹子的爆照合集(12G)!
一.出发点: 之前在知乎看到一位大牛(二胖)写的一篇文章:python爬取知乎最受欢迎的妹子(大概题目是这个,具体记不清了),但是这位二胖哥没有给出源码,而我也没用过python,正好顺便学一学,所以 ...
- Python scrapy框架爬取瓜子二手车信息数据
项目实施依赖: python,scrapy ,fiddler scrapy安装依赖的包: 可以到https://www.lfd.uci.edu/~gohlke/pythonlibs/ 下载 pywi ...
- python scrapy框架爬取豆瓣
刚刚学了一下,还不是很明白.随手记录. 在piplines.py文件中 将爬到的数据 放到json中 class DoubanmoviePipelin2json(object):#打开文件 open_ ...
- Python+Scrapy+Crawlspider 爬取数据且存入MySQL数据库
1.Scrapy使用流程 1-1.使用Terminal终端创建工程,输入指令:scrapy startproject ProName 1-2.进入工程目录:cd ProName 1-3.创建爬虫文件( ...
- 如何利用Python网络爬虫爬取微信朋友圈动态--附代码(下)
前天给大家分享了如何利用Python网络爬虫爬取微信朋友圈数据的上篇(理论篇),今天给大家分享一下代码实现(实战篇),接着上篇往下继续深入. 一.代码实现 1.修改Scrapy项目中的items.py ...
- python+selenium+PhantomJS爬取网页动态加载内容
一般我们使用python的第三方库requests及框架scrapy来爬取网上的资源,但是设计javascript渲染的页面却不能抓取,此时,我们使用web自动化测试化工具Selenium+无界面浏览 ...
- 使用scrapy框架爬取自己的博文(2)
之前写了一篇用scrapy框架爬取自己博文的博客,后来发现对于中文的处理一直有问题- - 显示的时候 [u'python\u4e0b\u722c\u67d0\u4e2a\u7f51\u9875\u76 ...
- Scrapy+selenium爬取简书全站
Scrapy+selenium爬取简书全站 环境 Ubuntu 18.04 Python 3.8 Scrapy 2.1 爬取内容 文字标题 作者 作者头像 发布日期 内容 文章连接 文章ID 思路 分 ...
- [python] 常用正则表达式爬取网页信息及分析HTML标签总结【转】
[python] 常用正则表达式爬取网页信息及分析HTML标签总结 转http://blog.csdn.net/Eastmount/article/details/51082253 标签: pytho ...
随机推荐
- marquee标签滚动效果
<marquee></marquee>标签,默认从最右侧往左滚动: direction:设置滚动的方向: height:设置标签高度, width:设置标签宽度: behavi ...
- web工程依赖的问题
http://blog.csdn.net/testcs_dn/article/details/43764497 做个记录
- Redis配置集群二(window)
第一篇那redis的基础命令都差不多讲了一遍了,这篇就将怎么配置集群了,最后要达到的效果是一台主redis,还有几台从的redis,每次数据都是同步的,当主redis挂掉了,那么就会从几台从redis ...
- 第 17 章 CSS 边框与背景[上]
学习要点: 1.声明边框 2.边框样式 3.圆角边框 主讲教师:李炎恢 本章主要探讨 HTML5 中 CSS 边框和背景,通过边框和背景的样式设置,给元素增加更丰富的外观. 一.声明边框 边框的声明有 ...
- 第 1 章 HTML5 概述
学习要点: 1.HTML5 的历史 2.HTML5 的功能 3.HTML5 的特点 4.课程学习问题 主讲教师:李炎恢 HTML5 是继 HTML4.01 和 XHTML1.0 之后的超文本标记语言的 ...
- [python拾遗]enumerate()函数
在python中处理各类序列时,如果我们想显示出这个序列的元素以及它们的下标,可以使用enumerate()函数. enumerate()函数用于遍历用于遍历序列中的元素以及它们的下标,用法如下: 1 ...
- Fiddler (四) 实现手机的抓包
Fiddler是我最喜爱的工具,几乎每天都用, 我已经用了8年了. 至今我也只学会其中大概50%的功能. Fiddler绝对称得上是"神器", 任何一个搞IT的人都得着的. 小 ...
- web桌面程序之图标拖动排序的分析
在web桌面程序里,图标拖动并重新排序是个比较常见的功能.这个功能我之前反复修改了好几遍,现在终于整理出了比较理想的解决思路,决定拿出来分享下. 这一功能主要有哪些难点呢?我总结了一下一共有2处难点: ...
- 让你忘记 Flash 的15款精彩 HTML5 游戏
HTML5 游戏开发是一个热门的话题,开发人员和设计人员最近经常谈论到.虽然不能迅速取代 Flash 的地位,但是 HTML5 凭借它的开放性和强大的编程能力,取代 Flash 是必然的趋势.你会看到 ...
- HTML <base> 标签 为页面上的所有链接规定默认地址或默认目标
定义和用法 <base> 标签为页面上的所有链接规定默认地址或默认目标. 通常情况下,浏览器会从当前文档的 URL 中提取相应的元素来填写相对 URL 中的空白. 使用 <base& ...