Trie树(c++实现)
转:http://www.cnblogs.com/kaituorensheng/p/3602155.html
http://blog.csdn.net/insistgogo/article/details/7828851
一、定义:
Trie,又称字典树,是一种用于快速检索的二十六叉树结构。典型的空间换时间
二、结构图:

三、原理:
Trie把要查找的关键词看作一个字符序列,并根据构成关键词字符的先后顺序检索树结构;
特别地:和二叉查找树不同,在Trie树中,每个结点上并非存储一个元素。
四、性质:
0、利用串的公共前缀,节约内存
2、根节点不包含字符,除根节点外的每一个节点都只代表一个字母,这里不是包含。
3、从根节点到某一节点,路径上经过的字符连接起来,为该节点对应的字符串。
4、每个节点的所有子节点包含的字符都不相同。
五、效率分析
0、当存储大量字符串时,Trie耗费的空间较少。因为键值并非显式存储的,而是与其他键值共享子串。
1、查询快。在trie树中查找一个关键字的时间和树中包含的结点数无关,而取决于组成关键字的字符数。对于长度为m的键值,最坏情况下只需花费O(m)的时间(对比:二叉查找树的查找时间和树中的结点数有关O(log2n)。)
2、如果要查找的关键字可以分解成字符序列且不是很长,利用trie树查找速度优于二叉查找树。
3、若关键字长度最大是5,则利用trie树,利用5次比较可以从265=11881376个可能的关键字中检索出指定的关键字。而利用二叉查找树至少要进行log2265=23.5次比较。
六、应用:用于字符串的统计与排序,经常被搜索引擎系统用于文本词频统计。
1、字典树在串的快速检索中的应用。
给出N个单词组成的熟词表,以及一篇全用小写英文书写的文章,请你按最早出现的顺序写出所有不在熟词表中的生词。在这道题中,我们可以用字典树,先把熟词建一棵树,然后读入文章进行比较,这种方法效率是比较高的。
2、字典树在“串”排序方面的应用
给定N个互不相同的仅由一个单词构成的英文名,让你将他们按字典序从小到大输出用字典树进行排序,采用数组的方式创建字典树,这棵树的每个结点的所有儿子很显然地按照其字母大小排序。对这棵树进行先序遍历即可。
3.、字典树在最长公共前缀问题的应用
对所有串建立字典树,对于两个串的最长公共前缀的长度即他们所在的结点的公共祖先个数,于是,问题就转化为最近公共祖先问题。
代码
原理
先看个例子,存储字符串abc、ab、abm、abcde、pm可以利用以下方式存储
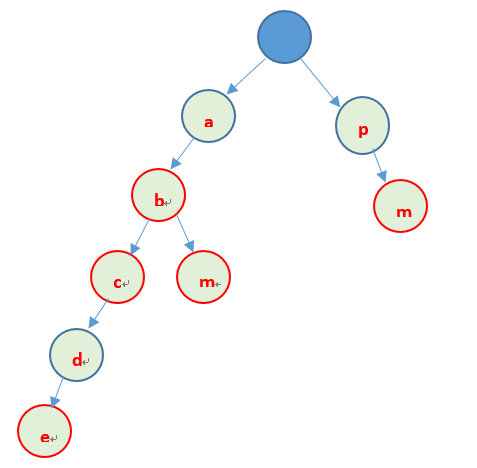
上边就是Trie树的基本原理:利用字串的公共前缀来节省存储空间,最大限度的减少无谓的字串比较。
应用
Trie树又称单词查找树,典型的应用是用于统计,排序和保存大量的字符串(不仅用于字符串),所以经常被搜索引擎系统用于文本词频的统计。
设计
trie,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
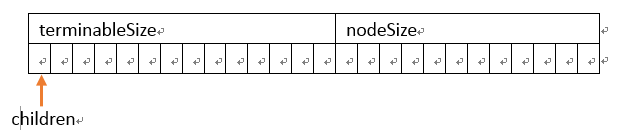
结点可以设计成这样:

class trieNode
{
public:
trieNode() : terminableSize(0), nodeSize(0) { for(int i = 0; i < Size; ++i) children[i] = NULL; }
~trieNode()
{
for(int i = 0; i < Size; ++i)
{
delete children[i];
children[i] = NULL;
}
}
public:
int terminableSize; //存储以此结点为结尾的字串的个数
int nodeSize; //记录此结点孩子的个数
trieNode* children[Size]; //该数组记录指向孩子的指针
};
图示
树设计成这样:
template<int Size, class Type>
class trie
{
public:
typedef trieNode<Size> Node;
typedef trieNode<Size>* pNode;
trie() : root(new Node) {} template<class Iterator>
void insert(Iterator beg, Iterator end);
void insert(const char *str); template<class Iterator>
bool find(Iterator beg, Iterator end);
bool find(const char *str); template<class Iterator>
bool downNodeAlone(Iterator beg); template<class Iterator>
bool erase(Iterator beg, Iterator end);
bool erase(const char *str); int sizeAll(pNode);
int sizeNoneRedundant(pNode);
public:
pNode root;
private:
Type index;
};
index字串索引利用(char % 26) 得到,这样'a' % 26 = 19, 'b' % 26 = 20
实现
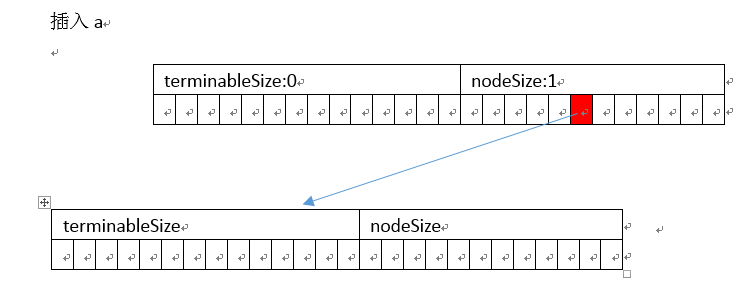
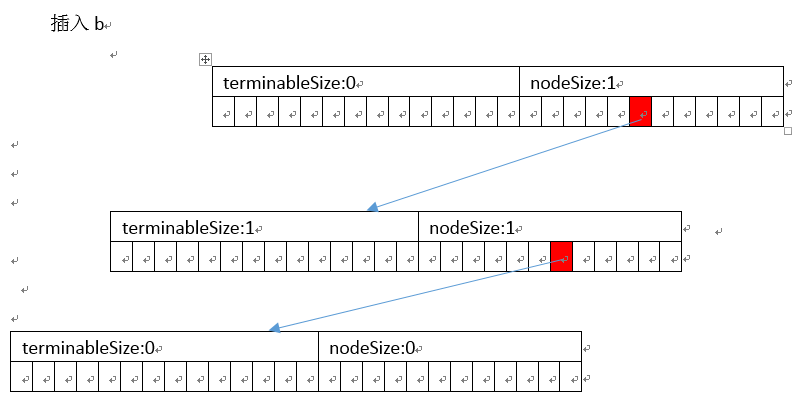
插入
以插入abc、ab为例
 ]
]
删除
删除结点,首先查找此字串是否在树中,如果在树中,再查找此结点以下的部分是不是都是只有一个孩子,并且每个结点只有叶子结点是结束结点,如果不是继续往下重复上边过程。
统计字串个数
分两种情况
- 计算重复的字串的个数:是结束结点,此时加的是terminabel的个数
- 计算不重复的字串的个数:是结束结点,此时加的是1(当terminabel>0)的个数
参考代码
#include <iostream>
#include <cstring>
using namespace std; template<int Size>
class trieNode
{
public:
trieNode() : terminableSize(0), nodeSize(0) { for(int i = 0; i < Size; ++i) children[i] = NULL; }
~trieNode()
{
for(int i = 0; i < Size; ++i)
{
delete children[i];
children[i] = NULL;
}
}
public:
int terminableSize;
int nodeSize;
trieNode* children[Size];
}; template<int Size, class Type>
class trie
{
public:
typedef trieNode<Size> Node;
typedef trieNode<Size>* pNode;
trie() : root(new Node) {} template<class Iterator>
void insert(Iterator beg, Iterator end);
void insert(const char *str); template<class Iterator>
bool find(Iterator beg, Iterator end);
bool find(const char *str); template<class Iterator>
bool downNodeAlone(Iterator beg); template<class Iterator>
bool erase(Iterator beg, Iterator end);
bool erase(const char *str); int sizeAll(pNode);
int sizeNoneRedundant(pNode);
public:
pNode root;
private:
Type index;
}; template<int Size, class Type>
template<class Iterator>
void trie<Size, Type>::insert(Iterator beg, Iterator end)
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(!cur->children[index[*beg]])
{
cur->children[index[*beg]] = new(Node);
++cur->nodeSize;
}
pre = cur;
cur = cur->children[index[*beg]];
}
++pre->terminableSize;
}
template<int Size, class Type>
void trie<Size, Type>::insert(const char *str)
{
return insert(str, str + strlen(str));
} template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::find(Iterator beg, Iterator end)
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(!cur->children[index[*beg]])
{
return false;
break;
}
pre = cur;
cur = cur->children[index[*beg]];
}
if(pre->terminableSize > 0)
return true;
return false;
} template<int Size, class Type>
bool trie<Size, Type>::find(const char *str)
{
return find(str, str + strlen(str));
} template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::downNodeAlone(Iterator beg)
{
pNode cur = root;
int terminableSum = 0;
while(cur->nodeSize != 0)
{
terminableSum += cur->terminableSize;
if(cur->nodeSize > 1)
return false;
else //cur->nodeSize = 1
{
for(int i = 0; i < Size; ++i)
{
if(cur->children[i])
cur = cur->children[i];
}
}
}
if(terminableSum == 1)
return true;
return false;
}
template<int Size, class Type>
template<class Iterator>
bool trie<Size, Type>::erase(Iterator beg, Iterator end)
{
if(find(beg, end))
{
pNode cur = root;
pNode pre;
for(; beg != end; ++beg)
{
if(downNodeAlone(cur))
{
delete cur;
return true;
}
pre = cur;
cur = cur->children[index[*beg]];
}
if(pre->terminableSize > 0)
--pre->terminableSize;
return true;
}
return false;
} template<int Size, class Type>
bool trie<Size, Type>::erase(const char *str)
{
if(find(str))
{
erase(str, str + strlen(str));
return true;
}
return false;
} template<int Size, class Type>
int trie<Size, Type>::sizeAll(pNode ptr)
{
if(ptr == NULL)
return 0;
int rev = ptr->terminableSize;
for(int i = 0; i < Size; ++i)
rev += sizeAll(ptr->children[i]);
return rev;
} template<int Size, class Type>
int trie<Size, Type>::sizeNoneRedundant(pNode ptr)
{
if(ptr == NULL)
return 0;
int rev = 0;
if(ptr->terminableSize > 0)
rev = 1;
if(ptr->nodeSize != 0)
{
for(int i = 0; i < Size; ++i)
rev += sizeNoneRedundant(ptr->children[i]);
}
return rev;
} template<int Size>
class Index
{
public:
int operator[](char vchar)
{ return vchar % Size; }
}; int main()
{
trie<26, Index<26> > t;
t.insert("hello");
t.insert("hello");
t.insert("h");
t.insert("h");
t.insert("he");
t.insert("hel");
cout << "SizeALL:" << t.sizeAll(t.root) << endl;
cout << "SizeALL:" << t.sizeNoneRedundant(t.root) << endl;
t.erase("h");
cout << "SizeALL:" << t.sizeAll(t.root) << endl;
cout << "SizeALL:" << t.sizeNoneRedundant(t.root) << endl;
}
结果

技术实现细节
1. 对树的删除,并不是树销毁结点,而是通过结点自身的析构函数实现
2. 模版类、模版函数、非类型模版可以参考:http://www.cnblogs.com/kaituorensheng/p/3601495.html
3. 字母的存储并不是存储的字母,而是存储的位置,如果该位置的指针为空,则说明此处没有字母;反之有字母。
4. terminableNum存储以此结点为结束结点的个数,这样可以避免删除时,不知道是否有多个相同字符串的情况。
Trie树(c++实现)的更多相关文章
- 基于trie树做一个ac自动机
基于trie树做一个ac自动机 #!/usr/bin/python # -*- coding: utf-8 -*- class Node: def __init__(self): self.value ...
- 基于trie树的具有联想功能的文本编辑器
之前的软件设计与开发实践课程中,自己构思的大作业题目.做的具有核心功能,但是还欠缺边边角角的小功能和持久化数据结构,先放出来,有机会一点点改.github:https://github.com/chu ...
- hihocoder-1014 Trie树
hihocoder 1014 : Trie树 link: https://hihocoder.com/problemset/problem/1014 题意: 实现Trie树,实现对单词的快速统计. # ...
- 洛谷P2412 查单词 [trie树 RMQ]
题目背景 滚粗了的HansBug在收拾旧英语书,然而他发现了什么奇妙的东西. 题目描述 udp2.T3如果遇到相同的字符串,输出后面的 蒟蒻HansBug在一本英语书里面找到了一个单词表,包含N个单词 ...
- 通过trie树实现单词自动补全
/** * 实现单词补全功能 */ #include <stdio.h> #include <stdlib.h> #include <string.h> #incl ...
- #1014 Trie树
本题主要是求构造一棵Trie树,即词典树用于统计单词. C#代码如下: using System; using System.Collections.Generic; using System.Lin ...
- Trie树-字典查找
描述 小Hi和小Ho是一对好朋友,出生在信息化社会的他们对编程产生了莫大的兴趣,他们约定好互相帮助,在编程的学习道路上一同前进. 这一天,他们遇到了一本词典,于是小Hi就向小Ho提出了那个经典的问题: ...
- Trie树的创建、插入、查询的实现
原文:http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=28977986&id=3807947 1.什么是Trie树 Tr ...
- [转]双数组TRIE树原理
原文名称: An Efficient Digital Search Algorithm by Using a Double-Array Structure 作者: JUN-ICHI AOE 译文: 使 ...
随机推荐
- information_schema系列十二
1: INNODB_SYS_VIRTUAL 表存储的是INNODB表的虚拟列的信息,当然这个还是比较简单的,我们直接通过SHOW CREATE TABLE 或者DESC TABLE就能看得到. Col ...
- mobx源码解读1
mobx是redux的代替品,其本身就是一个很好的MVVM框架.因此花点力气研究一下它. 网上下最新的2.75 function Todo() { this.id = Math.random() mo ...
- Node.js 中MongoDB的基本接口操作
Node.js 中MongoDB的基本接口操作 连接数据库 安装mongodb模块 导入mongodb模块 调用connect方法 文档的增删改查操作 插入文档 方法: db.collection(& ...
- c#委托和事件的介绍
委托是一个类,它定义了方法的类型,使得可以将方法当作另一个方法的参数来进行传递.事件是一种特殊的委托. (1). delegate delegate我们常用到的一种声明 Delegate至少0个参 ...
- DSP下的#program
2014年7月22日 最近调试使用TMS320C6713的片子调试SDRAM,中间经过很多波折,这里就不吐槽了. 想将数据或者代码放到SDRAM上一定要用到#pragma .查阅资料后,感觉百度文库的 ...
- oracle、mysql新增字段,字段存在则不处理
oracle: 表名:CHANNEL_TRADE_DETAIL列名:exchange_code declare v_rowcount integer; begin select count(*) in ...
- eclipse maven spring mvc el表达式无效
http://www.myexception.cn/javascript/2031310.html
- WeakHashMap回收时机
import java.util.ArrayList; import java.util.List; import java.util.WeakHashMap; public class TestWe ...
- modelsim仿真vivado自动化脚本
quit -sim set PATH1 C:/modeltech64_10.2c/xilinx144_lib set PATH2 C:/xilinx1/Vivado/2014.4/data/veril ...
- 2013 acm 长沙网络赛 G题 素数+枚举 Goldbach
题目 http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3856 先预处理求出两个素数的和与积,然后枚举n-prime和n/pr ...