Paper | Deep Mutual Learning
【算法和公式很simple,甚至有点naive,但文章的写作不错】
为了让小网络具有大能力,我们通常使用蒸馏。这篇文章提出了一种新方法:深度相互学习(deep mutual learning, DML)。与蒸馏法不同,相互学习中存在多个学生共同学习,并且每个学生之间要互相学习。实验还发现了一个惊人的结果:我们不需要piror powerful的教师网络,而只需要一群简单的学生网络共同学习,性能就能超越蒸馏学习。
1. 动机详述和方法简介
模型精简化有很多手段:精简的网络设计,模型压缩,模型剪枝,二元化(binarisation)以及最有趣的模型蒸馏。
模型蒸馏的动机是:小网络的表达能力与大网络相似,但是训练起来却不如大网络简单。换句话说,小网络的训练问题不在于尺寸,而在于优化。
因此,模型蒸馏法中设置了一个教师模型。较小的学生模型试图去模仿教师模型的分类概率或特征表达,而不再通过传统的监督目标来学习。教师模型是提前训练好的,因此蒸馏学习是单向学习。
而本文的做法不同。本文设置了一系列学生网络,共同学习。每一个学生网络都在2个损失函数下进行训练:一个是传统的监督学习的损失;另一个是模仿损失(mimicry loss),将其他学生的分类概率作为该学生的先验概率。
..., and a mimicry loss that aligns each student’s class posterior with the class probabilities of other students.
意义有三方面:(1)每一个学生网络的性能,都要比单独学习更好,也要比蒸馏学习更好;(2)不再需要一个强大的教师;(3)让三个大型网络相互学习,也比一个大型网络单独学习效果更好。即哪怕我们不考虑模型规模,只考虑精度,深度相互学习也能派上用场。
有没有理论解释呢?恐怕没有。即:到底增量归功于何者?首先,相互学习和蒸馏学习一样,都是给学生网络提供了额外的信息指导,即让学生网络落入更加合理的、共同的局部最优解。【有点像dropout,但不是对网络结构的健壮性改造,而是对优化策略的健壮性改造】
作者在行人重识别和图像分类上都进行了实验,效果比蒸馏学习更好。此外还有几点发现:
这种方法对多种网络结构都有效,或者对于多种大小网络的组合有效;
随着合作网络数目的增加,性能也有所提升。
这对半监督学习有帮助,因为模仿损失既对有标签数据有效,也对无标签数据有效。
2. 相关工作
相比于蒸馏学习,本文直接扔掉了教师网络的概念,并且允许一堆学生网络共同、相互学习。
相比于协同学习,本文中每个网络的目标是一样的。而现有的协同学习旨在解决不同任务的协同。
3. 方法
3.1 Formulation
如图,看的很明白。
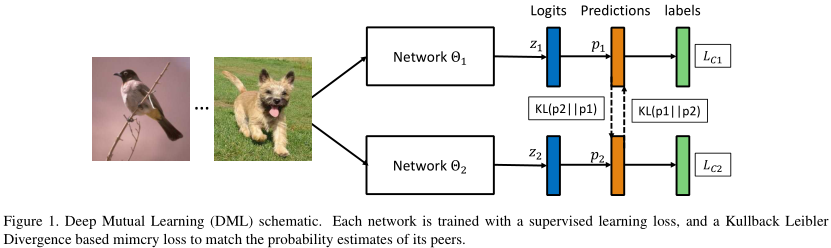
假设有\(M\)个分类\(N\)个样本\(\{ x_i \}_{i=1}^N\),对应标签为\(\{ y_i \}_{i=1}^N\)。
最后的监督学习损失\(L_C\)就是预测概率与真实标签之间的KL散度。网络的预测概率要通过softmax归一化。
\[
p^m (x_i) = \frac{\exp (z^m)}{\sum_{m=1}^M\ exp (z^m)}
\]
\[
L_C = - \sum_{i=1}^N \sum_{m=1}^M I(y_i, m) \log (p^m (x_i))
\]
\[
I \left( y_{i}, m \right) = \left\{
\begin{array}{ll}{1} & {y_{i}=m} \\
{0} & {y_{i} \neq m}
\end{array}
\right.
\]
此外,我们引入另一个随机初始化的网络,定义 网络1 参考 网络2 的模仿损失:
\[
D_{K L}\left(\boldsymbol{p}_{2} \| \boldsymbol{p}_{1}\right)=\sum_{i=1}^{N} \sum_{m=1}^{M} p_{2}^{m}\left(\boldsymbol{x}_{i}\right) \log \frac{p_{2}^{m}\left(\boldsymbol{x}_{i}\right)}{p_{1}^{m}\left(\boldsymbol{x}_{i}\right)}
\]
解释:如果二者概率相同,那么损失为零;否则,只要二者趋势不同(一个趋于0,一个趋于1),损失都是正值。
当然,我们也可以用对称KL损失,即\(\frac{1}{2}\left(D_{K L}\left(\boldsymbol{p}_{1} \| \boldsymbol{p}_{2}\right)+D_{K L}\left(\boldsymbol{p}_{2} \| \boldsymbol{p}_{1}\right)\right)\)。实验发现效果没区别。【博主怀疑公式7写错了】
最终的损失就是上述 模仿损失 和 监督学习损失 的直接求和。
3.2 实现
每一个网络可以在独立的GPU上计算。
当更多网络加入时,模仿损失要取均值。
还有一种优化方法:让其他所有学生网络的概率取均值(即统一作为一个教师),然后计算均值概率与该学生网络概率分布的KL散度。
\[
L_{\Theta_{k}}=L_{C_{k}}+D_{K L}\left(\boldsymbol{p}_{a v g} \| \boldsymbol{p}_{k}\right), \quad \boldsymbol{p}_{a v g}=\frac{1}{K-1} \sum_{l=1, l \neq k}^{K} \boldsymbol{p}_{l}
\]
实验发现这样做不好。可能的原因是:均值化操作降低了教师提供的先验熵【理解为随机性就行】。
3.3 弱监督学习
实现方法很简单:如果是有标签数据,那么就基于监督学习损失进行优化;如果是无标签数据,那么就基于模仿损失进行优化。
4. 实验
4.1 基本实验
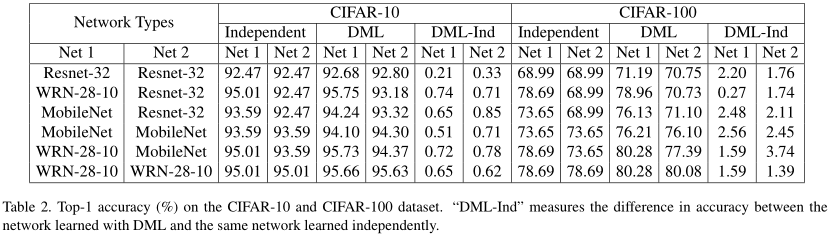
如表,作者尝试了很多网络结构。当交互学习时,准确率有所提升(DML-Ind是正值)。其中还包括各种网络的配对组合。作者还尝试了行人重识别任务,精度也得到了提升。
在训练过程中,DML也有助于更快、更好地收敛。
作者尝试了两种迭代策略:一种是序列化迭代,即第一个网络迭代完再迭代第二个;第二种是并行化策略,即同时迭代。作者发现第二种更好。并且第二种由于并行化,效率也更高。
作者还比较了蒸馏学习,效果要远比DML差。
作者还考察了学生网络数量对最终效果的影响。总体上呈现增长趋势,并且方差也更小。
4.2 深入实验
那么DML为什么有效呢?作者还实施了一些实验。
[4,10]指出:落入宽谷(wide valleys)的网络,通常比落入窄缝(narrow crevices)的网络泛化能力更好。为什么呢?因为当输入扰动时,处于宽谷的网络不会产生较大变化,但后者会。而DML就充当了一个协助者的角色,协助网络冲出窄缝。
作者无法证明这一点,但进行了一个实验:和[4,10]一样,作者在网络权重上加上了高斯噪声。结果,原网络的训练误差剧烈上升,而DML训练网络的训练误差只有较小提升。
此外,DML是一种均值化教师网络的操作。我们看看这种均值化是不是有好处。作者发现,DML的加入使得网络的预测没有这么肯定了。这是类似于熵正则化方法[4,17],能够帮助网络寻找更宽的局部极小值点。但与[4]相比,DML的效果更好。
实验发现,无论有没有DML,不同初始化网络学出来的特征都不尽相同。因此,差异性服务于随机性,也就服务于健壮性。进一步,如果我们强迫特征相似,那么最终结果不增反降。作者尝试加入了关于特征的L2损失,结果效果更差。
Paper | Deep Mutual Learning的更多相关文章
- 【论文阅读】Deep Mutual Learning
文章:Deep Mutual Learning 出自CVPR2017(18年最佳学生论文) 文章链接:https://arxiv.org/abs/1706.00384 代码链接:https://git ...
- Deep Mutual Learning
论文地址: https://arxiv.org/abs/1706.00384 论文简介 该论文探讨了一种与模型蒸馏(model distillation)相关却不同的模型---即相互学习(mutual ...
- Paper | Deep Residual Learning for Image Recognition
目录 1. 故事 2. 残差学习网络 2.1 残差块 2.2 ResNet 2.3 细节 3. 实验 3.1 短连接网络与plain网络 3.2 Projection解决短连接维度不匹配问题 3.3 ...
- 论文笔记: Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation
Mutual Learning to Adapt for Joint Human Parsing and Pose Estimation 2018-11-03 09:58:58 Paper: http ...
- Paper Read: Robust Deep Multi-modal Learning Based on Gated Information Fusion Network
Robust Deep Multi-modal Learning Based on Gated Information Fusion Network 2018-07-27 14:25:26 Paper ...
- Paper Reading 1 - Playing Atari with Deep Reinforcement Learning
来源:NIPS 2013 作者:DeepMind 理解基础: 增强学习基本知识 深度学习 特别是卷积神经网络的基本知识 创新点:第一个将深度学习模型与增强学习结合在一起从而成功地直接从高维的输入学习控 ...
- (转) Playing FPS games with deep reinforcement learning
Playing FPS games with deep reinforcement learning 博文转自:https://blog.acolyer.org/2016/11/23/playing- ...
- Learning Roadmap of Deep Reinforcement Learning
1. 知乎上关于DQN入门的系列文章 1.1 DQN 从入门到放弃 DQN 从入门到放弃1 DQN与增强学习 DQN 从入门到放弃2 增强学习与MDP DQN 从入门到放弃3 价值函数与Bellman ...
- (转) Deep Reinforcement Learning: Playing a Racing Game
Byte Tank Posts Archive Deep Reinforcement Learning: Playing a Racing Game OCT 6TH, 2016 Agent playi ...
随机推荐
- C# 程序一个cmd命令窗口执行多条dos命令
1,前几天的项目要用到程序执行dos命令去编译已生成的ice文件,后来去百度了好多都是只能执行一条命令 或者是分别执行几条命令,而我要的是一条dos命令在另一台命令的基础上执行.而不是分别执行. 后来 ...
- QGIS练手 - 数据
又熬夜了... 这篇博客可能会将QGIS数据管理部分和ArcGIS数据管理进行对比学习. 1. 本地数据文件与数据库(矢量) 1.1 文件 QGIS用的是shp文件.kml文件.geojson文件较多 ...
- 从0系统学Android--3.1编写UI界面
从0系统学Android--3.1编写UI界面 本系列文章目录:更多精品文章分类 本系列持续更新中.... 界面设计和功能开发同样重要,界面美观的应用程序不仅可以大大增加用户粘性,还能帮我们吸引到更多 ...
- 如何在linux上有2个python的情况下安装gensim
安装python的问题 https://blog.51cto.com/liqingbiao/2083869 安装gensim https://blog.csdn.net/zhujiyao/articl ...
- Nim 游戏
你和你的朋友,两个人一起玩 Nim 游戏:桌子上有一堆石头,每次你们轮流拿掉 1 - 3 块石头. 拿掉最后一块石头的人就是获胜者.你作为先手. 你们是聪明人,每一步都是最优解. 编写一个函数,来判断 ...
- Java之Map接口(双列集合)
Map集合概述 现实生活中,我们常会看到这样的一种集合:IP地址与主机名,身份证号与个人,系统用户名与系统用户对象等,这种一一对应的关系,就叫做映射.Java提供了专门的集合类用来存放这种对象关系的对 ...
- leetcode-二叉树
树以及常用的算法 树的概念 树(Tree)的基本概念树是由结点或顶点和边组成的(可能是非线性的)且不存在着任何环的一种数据结构.没有结点的树称为空(null或empty)树.一棵非空的树包括一个根结点 ...
- github仓库迁移到gitlab以及gitlab仓库迁移到另一个gitlab服务器
一. github仓库迁移到gitlab 先进入 new project: 选择 Import project, 选择下面的github: 进入后,这里需要github的 personal acces ...
- goroutine,channel
Go语言中有个概念叫做goroutine, 这类似我们熟知的线程,但是更轻. 以下的程序,我们串行地去执行两次loop函数: package main import "fmt" f ...
- ASP.NET Core 3.0 gRPC 配置使用HTTP
前言 gRPC是基于http/2,是同时支持https和http协议的,我们在gRPC实际使用中,在内网通讯场景下,更多的是走http协议,达到更高的效率,下面介绍如何在 .NET Core 3.0 ...