为了能早点买房,我用 Python 预测房价走势!
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
作者: Python高校
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef
项目描述
利用马萨诸塞州波士顿郊区的房屋信息数据训练和测试一个模型,并对模型的性能和预测能力进行测试;
项目分析
数据集字段解释:
RM: 住宅平均房间数量;
LSTAT: 区域中被认为是低收入阶层的比率;
PTRATIO: 镇上学生与教师数量比例;
MEDV: 房屋的中值价格(目标特征,即我们要预测的值);
其实现在回过头来看,前三个特征应该都是挖掘后的组合特征,比如RM,通常在原始数据中会分为多个特征:一楼房间、二楼房间、厨房、卧室个数、地下室房间等等,这里应该是为了教学简单化了;
MEDV为我们要预测的值,属于回归问题,另外数据集不大(不到500个数据点),小数据集上的回归问题,现在的我初步考虑会用SVM,稍后让我们看看当时的选择;
Step 1 导入数据
注意点:
1、如果数据在多个csv中(比如很多销售项目中,销售数据和店铺数据是分开两个csv的,类似数据库的两张表),这里一般要连接起来; 2、训练数据和测试数据连接起来,这是为了后续的数据处理的一致,否则训练模型时会有问题(比如用训练数据训练的模型,预测测试数据时报错维度不一致); 3、观察下数据量,数据量对于后续选择算法、可视化方法等有比较大的影响,所以一般会看一下; 4、pandas内存优化,这一点项目中目前没有,但是我最近的项目有用到,简单说一下,通过对特征字段的数据类型向下转换(比如int64转为int8)降低对内存的使用,这里很重要,数据量大时很容易撑爆个人电脑的内存存储;
上代码:
# 载入波士顿房屋的数据集
data = pd.read_csv('housing.csv')
prices = data['MEDV']
features = data.drop('MEDV', axis = 1)
# 完成
print"Boston housing dataset has {} data points with {} variables each.".format(*data.shape)
tep 2 分析数据
加载数据后,不要直接就急匆匆的上各种处理手段,加各种模型,先慢一点,对数据进行一个初步的了解,了解其各个特征的统计值、分布情况、与目标特征的关系,最好进行可视化,这样会看到很多意料之外的东西;
基础统计运算
统计运算用于了解某个特征的整体取值情况,它的最大最小值,平均值中位数,百分位数等等,这些都是最简单的对一个字段进行了解的手段;
上代码:

特征观察
这里主要考虑各个特征与目标之间的关系,比如是正相关还是负相关,通常都是通过对业务的了解而来的,这里就延伸出一个点,机器学习项目通常来说,对业务越了解,越容易得到好的效果,因为所谓的特征工程其实就是理解业务、深挖业务的过程;
比如这个问题中的三个特征:
RM:房间个数明显应该是与房价正相关的;
LSTAT:低收入比例一定程度上表示着这个社区的级别,因此应该是负相关;
PTRATIO:学生/教师比例越高,说明教育资源越紧缺,也应该是负相关;
上述这三个点,同样可以通过可视化的方式来验证,事实上也应该去验证而不是只靠主观猜想,有些情况下,主观感觉与客观事实是完全相反的,这里要注意;
Step 3 数据划分
为了验证模型的好坏,通常的做法是进行cv,即交叉验证,基本思路是将数据平均划分N块,取其中N-1块训练,并对另外1块做预测,并比对预测结果与实际结果,这个过程反复N次直到每一块都作为验证数据使用过;
上代码:
# 提示:导入train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features, prices, test_size=0.2, random_state=RANDOM_STATE)
print X_train.shape
print X_test.shape
print y_train.shape
print y_test.shape
Step 4 定义评价函数
这里主要是根据问题来定义,比如分类问题用的最多的是准确率(精确率、召回率也有使用,具体看业务场景中更重视什么),回归问题用RMSE(均方误差)等等,实际项目中根据业务特点经常会有需要去自定义评价函数的时候,这里就比较灵活;
Step 5 模型调优
通过GridSearch对模型参数进行网格组合搜索最优,注意这里要考虑数据量以及组合后的可能个数,避免运行时间过长哈。
上代码:
from sklearn.model_selection importKFold,GridSearchCV
from sklearn.tree importDecisionTreeRegressor
from sklearn.metrics import make_scorer
def fit_model(X, y):
""" 基于输入数据 [X,y],利于网格搜索找到最优的决策树模型"""
cross_validator = KFold()
regressor = DecisionTreeRegressor()
params = {'max_depth':[1,2,3,4,5,6,7,8,9,10]}
scoring_fnc = make_scorer(performance_metric)
grid = GridSearchCV(estimator=regressor, param_grid=params, scoring=scoring_fnc,cv=cross_validator)
# 基于输入数据 [X,y],进行网格搜索
grid = grid.fit(X, y)
# 返回网格搜索后的最优模型
return grid.best_estimator_
可以看到当时项目中选择的是决策树模型,现在看,树模型在这种小数据集上其实是比较容易过拟合的,因此可以考虑用SVM代替,你也可以试试哈,我估计是SVM效果最好;
学习曲线
通过绘制分析学习曲线,可以对模型当前状态有一个基本了解,如下图:
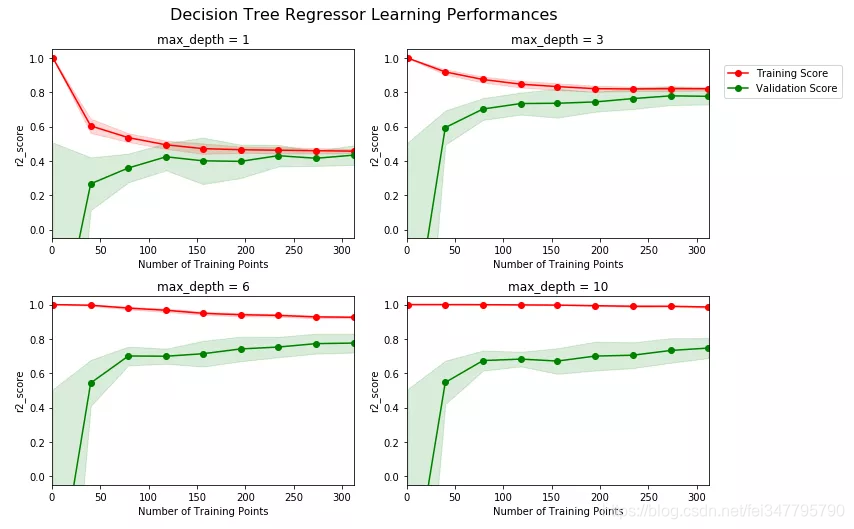
可以看到,超参数max_depth为1和3时,明显训练分数过低,这说明此时模型有欠拟合的情况,而当max_depth为6和10时,明显训练分数和验证分析差距过大,说明出现了过拟合,因此我们初步可以猜测,最佳参数在3和6之间,即4,5中的一个,其他参数一样可以通过学习曲线来进行可视化分析,判断是欠拟合还是过拟合,再分别进行针对处理;
为了能早点买房,我用 Python 预测房价走势!的更多相关文章
- 基于Python预测股价
▌实现预测的Stocker工具 Stocker是一款用于探索股票情况的Python工具.一旦我们安装了所需的库(查看文档),我们可以在脚本的同一文件夹中启动一个Jupyter Notebook,并导入 ...
- 用Python预测双色球福利彩票中奖号码(请不要当真)
前言 双色球是中国福利彩票的一种玩法. 红球一共6组,每组从1-33中抽取一个,六个互相不重复.然后蓝球是从1-16中抽取一个数字,这整个组成的双色球 python从零基础入门到实战 今天,我们就用P ...
- Python预测2020高考分数和录取情况可能是这样
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:打磨虾 “迟到”了一个月的高考终于要来了. 正好我得到了一份山东新高 ...
- Python预测2020高考分数和录取情况
“迟到”了一个月的高考终于要来了. 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识. ...
- 我的Python书被台湾的出版社引进版权了,书的名字也更吸引人了
我去年出了一本Python书,基于股票大数据分析的Python入门实战,在这本书里,我是用股票范例讲述Pythorn的爬虫,数据分析和机器学习知识点,如下是京东的连接. https://item.jd ...
- 80个Python练手项目列表
80个Python练手项目列表 我若将死,给孩子留遗言,只留一句话:Repetition is the mother of all learning重复是学习之母.他们将来长大,学知识,技巧.爱情 ...
- daal4py 随机森林模型训练mnist并保存模型给C++ daal predict使用
# daal4py Decision Forest Classification Training example Serialization import daal4py as d4p import ...
- Machine Learning in Action(1) K-近邻
机器学习分两大类,有监督学习(supervised learning)和无监督学习(unsupervised learning).有监督学习又可分两类:分类(classification.)和回归(r ...
- R Seurat 单细胞处理pipline 代码
options(stringsAsFactors = F ) rm(list = ls()) library(Seurat) library(dplyr) library(ggplot2) libra ...
随机推荐
- 3种不走寻常路的黑客攻击泄露&如何保护自己?
数据泄露和黑客攻击现在已经成为我们日常生活中的常见部分,除非您是网络安全专业人员或您的个人数据受到威胁,否则您实际上并不关心是否存在新的漏洞. 正如美国联邦贸易委员会指出的那样,万豪酒店连锁店的超过5 ...
- 通过jgit一次性升级fastjson版本
背景:笔者所在公司经历了三次fastjson的升级,由于集群,工程数量众多,每次升级都很麻烦.因此开发了一个java的升级工具. 功能介绍: 功能介绍:一个jar文件,通过java -jar命令,输入 ...
- kafka速度快的原因
我们都知道Kafka非常快,比绝大多数的市场上其他消息中间件都要快.这里来研究下那么为什么Kafka那么快(当然不会是因为它用了Scala). Kafka的消息是保存或缓存在磁盘上的,一般认为在磁盘上 ...
- Selenium(六):frame切换、窗口切换
1. 切换到frame index.html: <!DOCTYPE html> <html> <head> <meta charset="UTF-8 ...
- 【C++常用函数】头文件<algorithm>中的常用函数(绝对值,交换,比较)
swap(a,b) 用于交换a,b两个变量的值: max(a,b) 返回a,b中的最大值: min(a,b) 返回a,b中的最小值: abs(x) 返回x的绝对值,x必须是整数:
- docker redis使用
启动方式一:docker默认启动redis 1.拉取镜像 docker pull redis:lastest (若不使用版本号,如docker pull redis,默认拉取最新镜像) 2.启动red ...
- PostgreSQL 修改表字段常用命令
--数据库.模式.表名 "identities"."Test"."tab_test" --修改字段名 ALTER TABLE "i ...
- Taro自定义Modal对话框组件|taro仿微信、android弹窗
基于Taro多端实践TaroPop:自定义模态框|dialog对话框|msg消息框|Toast提示 taro自定义弹出框支持编译到多端H5/小程序/ReactNative,还可以自定义弹窗类型/弹窗样 ...
- linux中OTG识别到一个U盘后产生一个sg节点的全过程
注:本篇文章暂时不做流程图,如果有需求后续补做. 1. 需要准备的源码文件列表: base部分: kernel\base\core.c kernel\base\bus.c kernel\base\dd ...
- 25个JavaScript数组方法代码示例
摘要: 通过代码掌握数组方法. 原文:通过实现25个数组方法来理解及高效使用数组方法(长文,建议收藏) 译者:前端小智 Fundebug经授权转载,版权归原作者所有. 要在给定数组上使用方法,只需要通 ...