Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计
要求编写的程序可爬取斗鱼直播网站上的直播信息,如:房间数,直播类别和人气等。熟悉掌握基本的网页和url分析,同时能灵活使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析。
一、项目分析
1. 网页分析
斗鱼直播网站按直播类型明显在网页上划分区域,同时在每一种类型区域中,视频标签框都将具有相同的class名称,如:直播房间的class名称为:ellipsis,直播类型class为:tag ellipsis,主播名称为:dy-name ellipsis fl,人气活跃度为:dy-num fr,这使得本实验的进行更为便捷。
这里使用xpath_helper_2_0_2工具,对网页中的class进行分析并转换成相应的xpath表达式,如下:
ellipsis为:
//div[@id='live-list-content']//h3[@class='ellipsis']/text()
dy-num fr为:
//div[@id='live-list-content']//span[@class='dy-num fr']/text()
dy-name ellipsis fl为:
//div[@id='live-list-content']//span[@class='dy-name ellipsis fl']/text()
tag ellipsis为:
//div[@id='live-list-content']//span[@class='tag ellipsis']/text()
2. url分析
这里的网页加载可由self.driver调用get()方法完成,同时在网页模块判断的时候,可由其调用find_element_by_class_name('shark-pager-next').click()方法串,自动完成下一页的模拟翻转。
同时可调用page_source.find('shark-pager-disable-next')方法进行判断是否为模块中的最后一页。
二、项目工具
Python 3.7.1 、 JetBrains PyCharm 2018.3.2
三、项目过程
(一)使用Xmind工具对Python爬虫程序(网络爬虫)流程图进行分析,绘制如图3-1所示的程序逻辑框架图
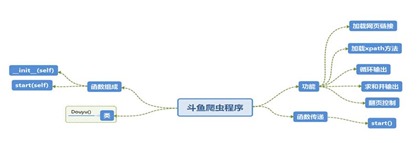
图3-1 程序逻辑框架图
(二)爬虫程序调试过程BUG描述(截图)

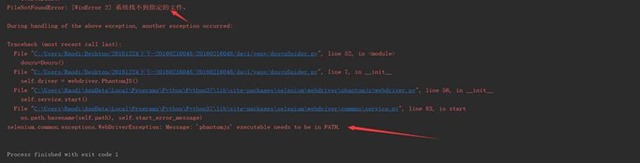
图3-2 爬虫程序BUG描述②
四、项目结果
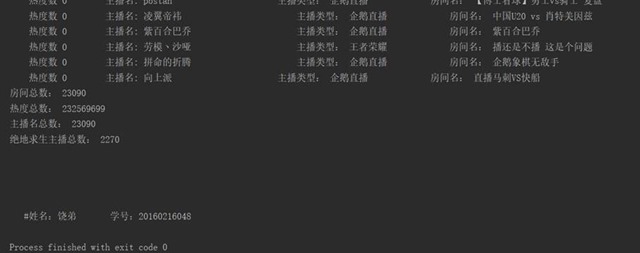
五、项目心得
关于本例实验心得可总结如下:
1、 当程序运行结果提示错误为:ModuleNotFoundError: No module named 'lxml',最好的解决方法是:首先排除是否lxml是否安装,再检查lxml是否被导入。本实验中,是由于工程项目为能成功导入lxml,解决方法如图5-1所示,在“Project Interperter”中选择python安装目录,即可。
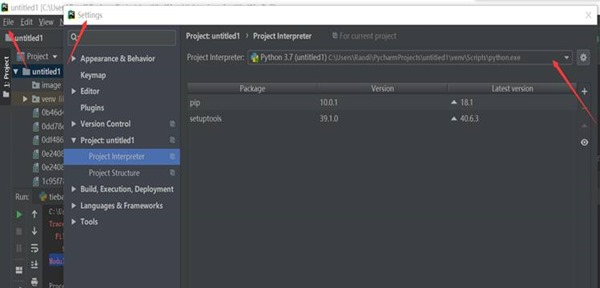
图5-1 错误解决过程
2、 当出现如图4-6的爬虫程序BUG描述时,可以确定为phantomjs没有设置环境变量,或者编程程序没有成功加载环境,后者的解决方法只需重新启动JetBrains PyCharm 2018.3.2即可,对于前者可在系统中设置环境即可
3、 新版selenium不支持phantomJS的解决方法:使用Chrome+headless或Firefox+headless,headless:无头参数,如图5-2所示:
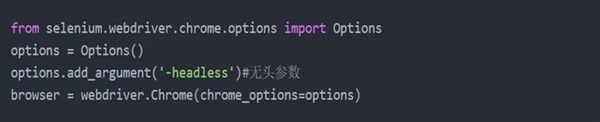
图5-2 解决方法
六、项目源码
doyu.py
from selenium import webdriver
from lxml import etree
import twisted
import scrapy
from openpyxl import Workbook
import time
class Douyu(object):
def __init__(self):
self.driver = webdriver.PhantomJS() def start(self):
self.driver.get('https://www.douyu.com/directory/all')
room_sum=0
host_sum=0
type_sum=0
while True:
time.sleep(2)
content=etree.HTML(self.driver.page_source)
roomnames=content.xpath("//div[@id='live-list-content']//h3[@class='ellipsis']/text()")
hots=content.xpath("//div[@id='live-list-content']//span[@class='dy-num fr']/text()")
names=content.xpath("//div[@id='live-list-content']//span[@class='dy-name ellipsis fl']/text()")
types=content.xpath("//div[@id='live-list-content']//span[@class='tag ellipsis']/text()")
for roomname,hot,name,type in zip(roomnames,hots,names,types):
roomname=roomname.strip()
print("\t热度数",hot," \t主播名:",name," \t主播类型:",type," \t房间名:",roomname)
room_sum+=1
if hot[-1]=='万':
hot=hot[:-1]
hot=int(float(hot)*10000)
host_sum+=hot
#host_sum=host_sum+hot else:
host_sum+=int(hot) if type=='绝地求生':
type_sum+=1
else:
a=0
a+=1
ret=self.driver.page_source.find('shark-pager-disable-next')
if ret>0:
break
else:
# 非最后一页,点击下一页
self.driver.find_element_by_class_name('shark-pager-next').click()
print('房间总数:',room_sum)
print('热度总数:', host_sum)
print('主播名总数:', room_sum)
print('绝地求生主播总数:',type_sum) class DoubanPipeline(object):
wb = Workbook()
ws = wb.active
# 设置表头
ws.append(['标题', '评分']) def process_item(self, item):
# 添加数据
line = [item['title'], item['star']]
self.ws.append(line) # 按行添加
self.wb.save('douban.xlsx')
return item if __name__=="__main__":
douyu=Douyu()
douyu.start() #//div[@id='live-list-content']//h3[@class='ellipsis']/text()
#//div[@id='live-list-content']//span[@class='dy-num fr']/text()
#ret= driver.page_source.find('shark-pager-disable-next')
#print(ret)
Scrapy项目 - 实现斗鱼直播网站信息爬取的爬虫设计的更多相关文章
- Scrapy项目 - 数据简析 - 实现斗鱼直播网站信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 2-3个图,作业文字描述) 本次将所爬取的数据信息,如:房间数,直播类别和人气,导入Weka 3.7工具进行数据分析.有关本次的数据分析详情详见下图所示: ...
- Scrapy项目 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
通过使Scrapy框架,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,进行数据挖掘和对web站点页面提取结构化数据,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 实现腾讯网站社会招聘信息爬取的爬虫设计
通过使Scrapy框架,进行数据挖掘和对web站点页面提取结构化数据,掌握如何使用Twisted异步网络框架来处理网络通讯的问题,可以加快我们的下载速度,也可深入接触各种中间件接口,灵活的完成各种需求 ...
- Scrapy项目 - 数据简析 - 实现腾讯网站社会招聘信息爬取的爬虫设计
一.数据分析截图 本例实验,使用Weka 3.7对腾讯招聘官网中网页上所罗列的招聘信息,如:其中的职位名称.链接.职位类别.人数.地点和发布时间等信息进行数据分析,详见如下图: 图1-1 Weka ...
- Scrapy项目 - 项目源码 - 实现腾讯网站社会招聘信息爬取的爬虫设计
1.tencentSpider.py # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentItem #创建爬虫 ...
- Scrapy项目 - 源码工程 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.项目目录结构 spiders文件夹内包含doubanSpider.py文件,对于项目的构建以及结构逻辑,详见环境搭建篇. 二.项目源码 1.doubanSpider.py # -*- coding ...
- Scrapy项目 - 数据简析 - 实现豆瓣 Top250 电影信息爬取的爬虫设计
一.数据分析截图(weka数据分析截图 ) 本例实验,使用Weka 3.7对豆瓣电影网页上所罗列的上映电影信息,如:标题.主要信息(年份.国家.类型)和评分等的信息进行数据分析,Weka 3.7数据分 ...
- Scrapy项目 - 实现百度贴吧帖子主题及图片爬取的爬虫设计
要求编写的程序可获取任一贴吧页面中的帖子链接,并爬取贴子中用户发表的图片,在此过程中使用user agent 伪装和轮换,解决爬虫ip被目标网站封禁的问题.熟悉掌握基本的网页和url分析,同时能灵活使 ...
- Scrapy实现腾讯招聘网信息爬取【Python】
一.腾讯招聘网 二.代码实现 1.spider爬虫 # -*- coding: utf-8 -*- import scrapy from Tencent.items import TencentIte ...
随机推荐
- Mysql系列 - 第3天:管理员必备技能(必须掌握)
这是mysql系列第3篇文章. 环境:mysql5.7.25,cmd命令中进行演示. 在玩mysql的过程中,经常遇到有很多朋友在云上面玩mysql的时候,说我创建了一个用户为什么不能登录?为什么没有 ...
- MyBatis 封装Map,返回不同实体的集合对象
现在有一个需求,就是从100个表中获得任意表中的数据,按照正常的思维模式和处理方式, 我们首先会创建100个实体类(累死!),然后通过resultType一一对应实体类,这种方式简直... 那么我们 ...
- JavaScript String 字符串方法
JavaScript String 字符串方法汇总 1.str.indexOf() 方法查找字符串中的字符串 返回 字符串中指定文本首次出现的索引(位置) JavaScript ...
- 学习笔记(一)-PyTorch在Windows环境搭建
一.安装Anaconda 3.5 Anaconda是一个用于科学计算的Python发行版,支持Linux.Mac和Window系统,提供了包管理与环境管理的功能,可以很方便地解决Python并存.切换 ...
- 计蒜客 ACM训练联盟周赛 第一场 Alice和Bob的Nim游戏 矩阵快速幂
题目描述 众所周知,Alice和Bob非常喜欢博弈,而且Alice永远是先手,Bob永远是后手. Alice和Bob面前有3堆石子,Alice和Bob每次轮流拿某堆石子中的若干个石子(不可以是0个), ...
- hdu 6435 CSGO
题意:现在有n个主武器, m个副武器, 你要选择1个主武器,1个副武器, 使得 题目给定的那个式子最大. 题解:这个题目困难的地方就在于有绝对值,| a - b | 我们将绝对值去掉之后 他的值就为 ...
- Cocos2d-x 学习笔记(24) ParticleSystem ParticleSystemQuad
1. ParticleSystem ParticleData是存储粒子数据的类,ParticleSystem会关联一个ParticleData对象. ParticleSystem直接继承了Node.T ...
- Allure-pytest功能特性介绍
前言 Allure框架是一个灵活的轻量级多语言测试报告工具,它不仅以web的方式展示了简介的测试结果,而且允许参与开发过程的每个人从日常执行的测试中最大限度的提取有用信息从dev/qa的角度来看,Al ...
- 在javascript中的浏览器兼容问题以及兼容浏览器汇总(默认事件,阻止冒泡,事件监听。。。)以及解决方式详解
在javascript中常见的浏览器兼容问题,以及解决方式. 在前端工作当中我们遵循这样的原则:渐进增强和优雅降级 渐进增强(progressive enhancement): 针对低版本浏览器进 ...
- Go操作kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者规模的网站中的所有动作流数据,具有高性能.持久化.多副本备份.横向扩展等特点.本文介绍了如何使用Go语言发送和接收kafka消息. s ...