Zookeeper集群的"脑裂"问题处理 - 运维总结
关于集群中的"脑裂"问题,之前已经在这里详细介绍过,下面重点说下Zookeeper脑裂问题的处理办法。ooKeeper是用来协调(同步)分布式进程的服务,提供了一个简单高性能的协调内核,用户可以在此之上构建更多复杂的分布式协调功能。脑裂通常会出现在集群环境中,比如ElasticSearch、Zookeeper集群,而这些集群环境有一个统一的特点,就是它们有一个大脑,比如ElasticSearch集群中有Master节点,Zookeeper集群中有Leader节点。
一、 Zookeeper 集群节点为什么要部署成奇数
zookeeper容错指的是:当宕掉几个zookeeper节点服务器之后,剩下的个数必须大于宕掉的个数,也就是剩下的节点服务数必须大于n/2,这样zookeeper集群才可以继续使用,无论奇偶数都可以选举leader。例如5台zookeeper节点机器最多宕掉2台,还可以继续使用,因为剩下3台大于5/2。那么为什么最好为奇数个节点呢?是在以最大容错服务器个数的条件下,会节省资源。比如,最大容错为2的情况下,对应的zookeeper服务数,奇数为5,而偶数为6,也就是6个zookeeper服务的情况下最多能宕掉2个服务,所以从节约资源的角度看,没必要部署6(偶数)个zookeeper服务节点。
zookeeper集群有这样一个特性:集群中只要有过半的机器是正常工作的,那么整个集群对外就是可用的。也就是说如果有2个zookeeper节点,那么只要有1个zookeeper节点死了,那么zookeeper服务就不能用了,因为1没有过半,所以2个zookeeper的死亡容忍度为0;同理,要是有3个zookeeper,一个死了,还剩下2个正常的,过半了,所以3个zookeeper的容忍度为1;同理也可以多列举几个:2->0; 3->1; 4->1; 5->2; 6->2 就会发现一个规律,2n和2n-1的容忍度是一样的,都是n-1,所以为了更加高效,何必增加那一个不必要的zookeeper呢。
根据以上可以得出结论:从资源节省的角度来考虑,zookeeper集群的节点最好要部署成奇数个!!
二、 Zookeeper 集群中的"脑裂"场景说明
对于一个集群,想要提高这个集群的可用性,通常会采用多机房部署,比如现在有一个由6台zkServer所组成的一个集群,部署在了两个机房:
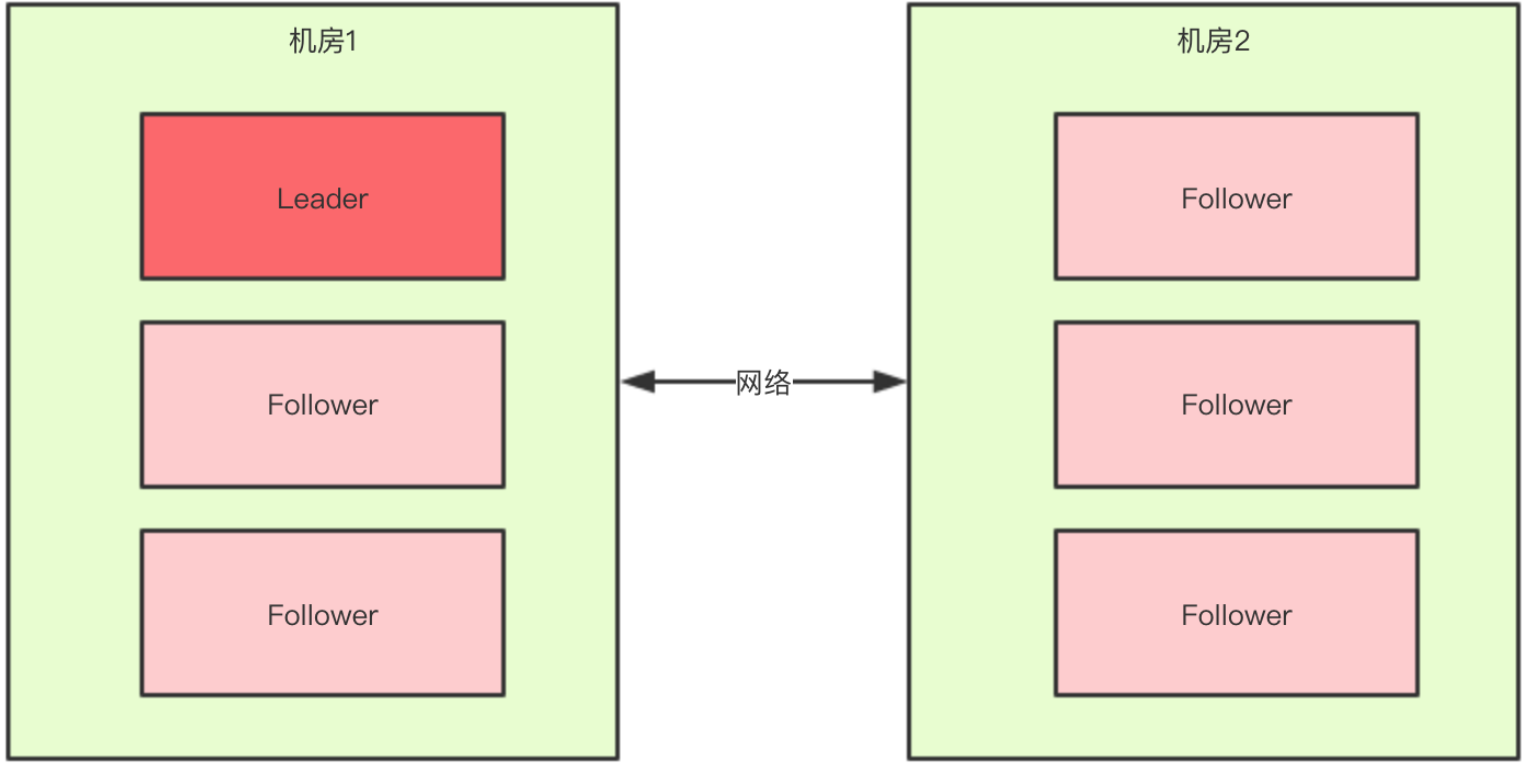
正常情况下,此集群只会有一个Leader,那么如果机房之间的网络断了之后,两个机房内的zkServer还是可以相互通信的,如果不考虑过半机制,那么就会出现每个机房内部都将选出一个Leader。
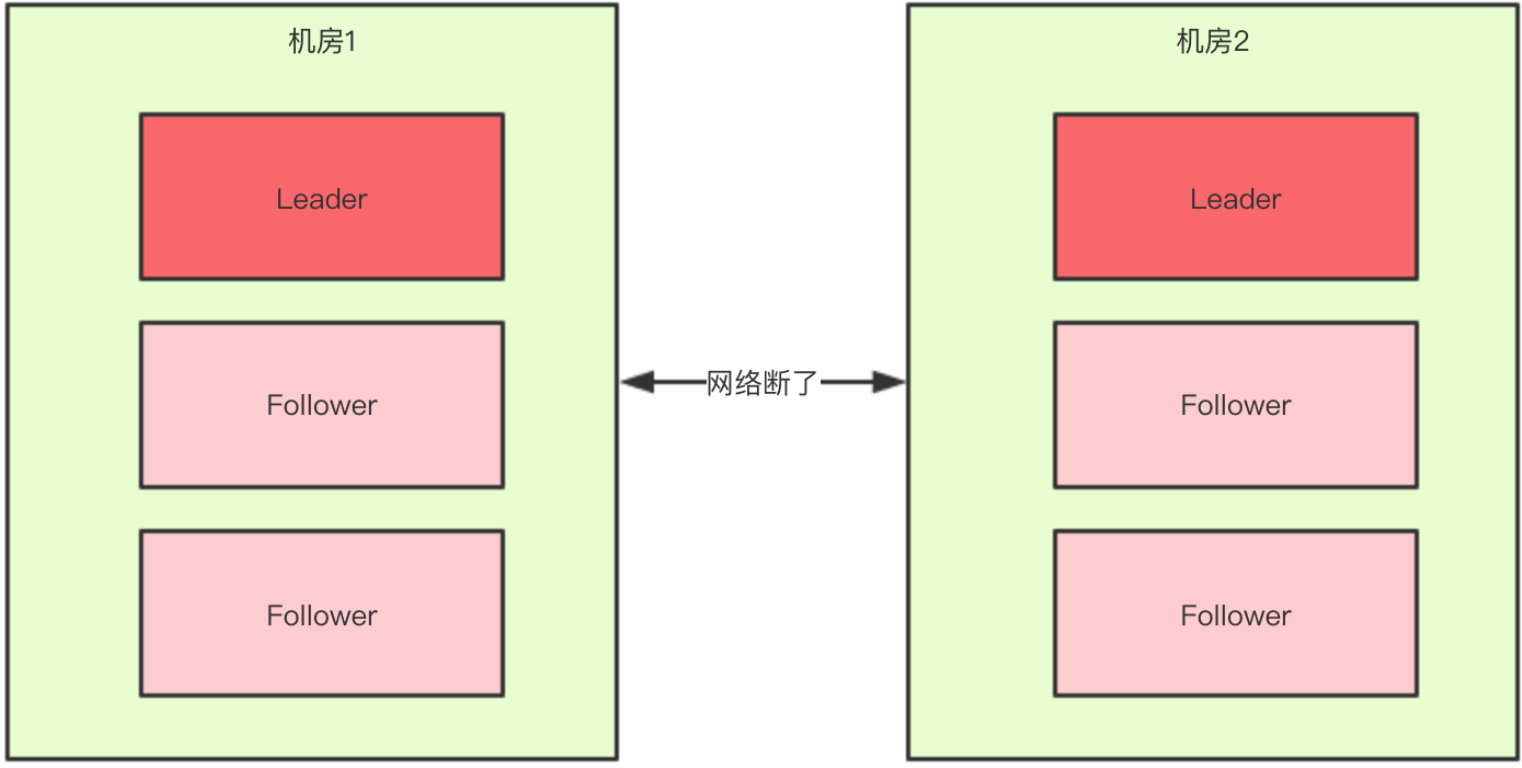
这就相当于原本一个集群,被分成了两个集群,出现了两个"大脑",这就是所谓的"脑裂"现象。对于这种情况,其实也可以看出来,原本应该是统一的一个集群对外提供服务的,现在变成了两个集群同时对外提供服务,如果过了一会,断了的网络突然联通了,那么此时就会出现问题了,两个集群刚刚都对外提供服务了,数据该怎么合并,数据冲突怎么解决等等问题。刚刚在说明脑裂场景时有一个前提条件就是没有考虑过半机制,所以实际上Zookeeper集群中是不会轻易出现脑裂问题的,原因在于过半机制。
zookeeper的过半机制:在领导者选举的过程中,如果某台zkServer获得了超过半数的选票,则此zkServer就可以成为Leader了。
举个简单的例子:如果现在集群中有5台zkServer,那么half=5/2=2,那么也就是说,领导者选举的过程中至少要有三台zkServer投了同一个zkServer,才会符合过半机制,才能选出来一个Leader。
有个疑问:zookeeper选举的过程中为什么一定要有一个过半机制验证?
因为这样不需要等待所有zkServer都投了同一个zkServer就可以选举出来一个Leader了,这样比较快,所以叫快速领导者选举算法。
再来想一个问题,过半机制中为什么是大于,而不是大于等于呢?这就是更脑裂问题有关系了,比如回到上文出现脑裂问题的场景 [如上图1]:
当机房中间的网络断掉之后,机房1内的三台服务器会进行领导者选举,但是此时过半机制的条件是 "节点数 > 3",也就是说至少要4台zkServer才能选出来一个Leader,所以对于机房1来说它不能选出一个Leader,同样机房2也不能选出一个Leader,这种情况下整个集群当机房间的网络断掉后,整个集群将没有Leader。
而如果过半机制的条件是 "节点数 >= 3",那么机房1和机房2都会选出一个Leader,这样就出现了脑裂。这就可以解释为什么过半机制中是大于而不是大于等于,目的就是为了防止脑裂。
如果假设我们现在只有5台机器,也部署在两个机房:
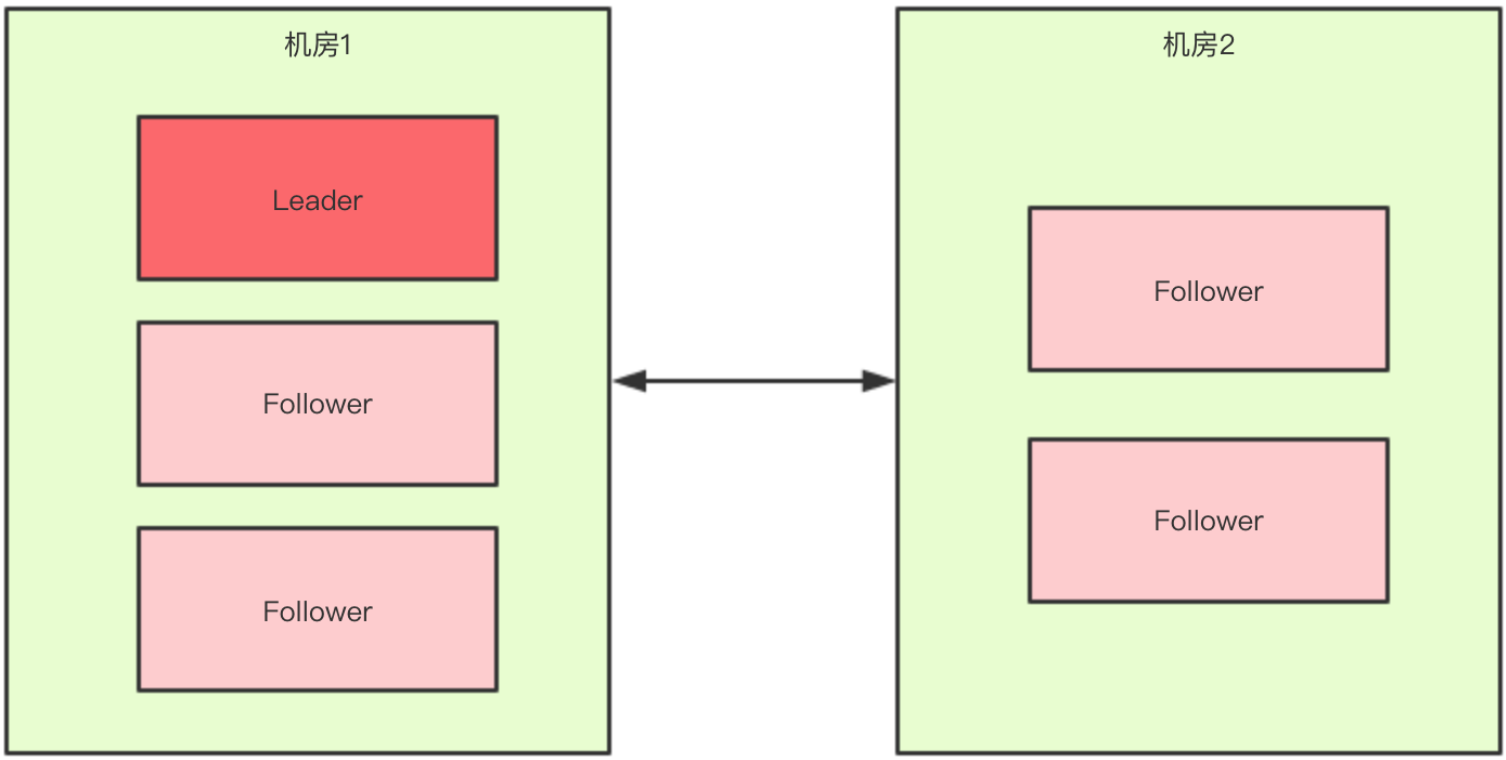
此时过半机制的条件是 "节点数 > 2",也就是至少要3台服务器才能选出一个Leader,此时机房件的网络断开了,对于机房1来说是没有影响的,Leader依然还是Leader,对于机房2来说是选不出来Leader的,此时整个集群中只有一个Leader。所以可以简单总结得出,有了过半机制,对于一个Zookeeper集群来说,要么没有Leader,要么只有1个Leader,这样zookeeper也就能避免了脑裂问题。
三、 Zookeeper 集群"脑裂"问题处理
1. 什么是脑裂?
简单点来说,脑裂(Split-Brain) 就是比如当你的 cluster 里面有两个节点,它们都知道在这个 cluster 里需要选举出一个 master。那么当它们两个之间的通信完全没有问题的时候,就会达成共识,选出其中一个作为 master。但是如果它们之间的通信出了问题,那么两个结点都会觉得现在没有 master,所以每个都把自己选举成 master,于是 cluster 里面就会有两个 master。
对于Zookeeper来说有一个很重要的问题,就是到底是根据一个什么样的情况来判断一个节点死亡down掉了。 在分布式系统中这些都是有监控者来判断的,但是监控者也很难判定其他的节点的状态,唯一一个可靠的途径就是心跳,Zookeeper也是使用心跳来判断客户端是否仍然活着。
使用ZooKeeper来做Leader HA基本都是同样的方式:每个节点都尝试注册一个象征leader的临时节点,其他没有注册成功的则成为follower,并且通过watch机制 (这里有介绍) 监控着leader所创建的临时节点,Zookeeper通过内部心跳机制来确定leader的状态,一旦leader出现意外Zookeeper能很快获悉并且通知其他的follower,其他flower在之后作出相关反应,这样就完成了一个切换,这种模式也是比较通用的模式,基本大部分都是这样实现的。但是这里面有个很严重的问题,如果注意不到会导致短暂的时间内系统出现脑裂,因为心跳出现超时可能是leader挂了,但是也可能是zookeeper节点之间网络出现了问题,导致leader假死的情况,leader其实并未死掉,但是与ZooKeeper之间的网络出现问题导致Zookeeper认为其挂掉了然后通知其他节点进行切换,这样follower中就有一个成为了leader,但是原本的leader并未死掉,这时候client也获得leader切换的消息,但是仍然会有一些延时,zookeeper需要通讯需要一个一个通知,这时候整个系统就很混乱可能有一部分client已经通知到了连接到新的leader上去了,有的client仍然连接在老的leader上,如果同时有两个client需要对leader的同一个数据更新,并且刚好这两个client此刻分别连接在新老的leader上,就会出现很严重问题。
这里做下小总结:
假死:由于心跳超时(网络原因导致的)认为leader死了,但其实leader还存活着。
脑裂:由于假死会发起新的leader选举,选举出一个新的leader,但旧的leader网络又通了,导致出现了两个leader ,有的客户端连接到老的leader,而有的客户端则连接到新的leader。
2. zookeeper脑裂是什么原因导致的?
主要原因是Zookeeper集群和Zookeeper client判断超时并不能做到完全同步,也就是说可能一前一后,如果是集群先于client发现,那就会出现上面的情况。同时,在发现并切换后通知各个客户端也有先后快慢。一般出现这种情况的几率很小,需要leader节点与Zookeeper集群网络断开,但是与其他集群角色之间的网络没有问题,还要满足上面那些情况,但是一旦出现就会引起很严重的后果,数据不一致。
3. zookeeper是如何解决"脑裂"问题的?
要解决Split-Brain脑裂的问题,一般有下面几种种方法:
- Quorums (法定人数) 方式: 比如3个节点的集群,Quorums = 2, 也就是说集群可以容忍1个节点失效,这时候还能选举出1个lead,集群还可用。比如4个节点的集群,它的Quorums = 3,Quorums要超过3,相当于集群的容忍度还是1,如果2个节点失效,那么整个集群还是无效的。这是zookeeper防止"脑裂"默认采用的方法。
- 采用Redundant communications (冗余通信)方式:集群中采用多种通信方式,防止一种通信方式失效导致集群中的节点无法通信。
- Fencing (共享资源) 方式:比如能看到共享资源就表示在集群中,能够获得共享资源的锁的就是Leader,看不到共享资源的,就不在集群中。
- 仲裁机制方式。
- 启动磁盘锁定方式。
要想避免zookeeper"脑裂"情况其实也很简单,在follower节点切换的时候不在检查到老的leader节点出现问题后马上切换,而是在休眠一段足够的时间,确保老的leader已经获知变更并且做了相关的shutdown清理工作了然后再注册成为master就能避免这类问题了,这个休眠时间一般定义为与zookeeper定义的超时时间就够了,但是这段时间内系统可能是不可用的,但是相对于数据不一致的后果来说还是值得的。
1) zooKeeper默认采用了Quorums这种方式来防止"脑裂"现象,即只有集群中超过半数节点投票才能选举出Leader。这样的方式可以确保leader的唯一性,要么选出唯一的一个leader,要么选举失败。在zookeeper中Quorums有3个作用:
1) 集群中最少的节点数用来选举leader保证集群可用。
2) 通知客户端数据已经安全保存前集群中最少数量的节点数已经保存了该数据。一旦这些节点保存了该数据,客户端将被通知已经安全保存了,可以继续其他任务。而集群中剩余的节点将会最终也保存了该数据。
假设某个leader假死,其余的followers选举出了一个新的leader。这时,旧的leader复活并且仍然认为自己是leader,这个时候它向其他followers发出写请求也是会被拒绝的。因为每当新leader产生时,会生成一个epoch标号(标识当前属于那个leader的统治时期),这个epoch是递增的,followers如果确认了新的leader存在,知道其epoch,就会拒绝epoch小于现任leader epoch的所有请求。那有没有follower不知道新的leader存在呢,有可能,但肯定不是大多数,否则新leader无法产生。Zookeeper的写也遵循quorum机制,因此,得不到大多数支持的写是无效的,旧leader即使各种认为自己是leader,依然没有什么作用。
zookeeper除了可以采用上面默认的Quorums方式来避免出现"脑裂",还可以可采用下面的预防措施:
2) 添加冗余的心跳线,例如双线条线,尽量减少“裂脑”发生机会。
3) 启用磁盘锁。正在服务一方锁住共享磁盘,"裂脑"发生时,让对方完全"抢不走"共享磁盘资源。但使用锁磁盘也会有一个不小的问题,如果占用共享盘的一方不主动"解锁",另一方就永远得不到共享磁盘。现实中假如服务节点突然死机或崩溃,就不可能执行解锁命令。后备节点也就接管不了共享资源和应用服务。于是有人在HA中设计了"智能"锁。即正在服务的一方只在发现心跳线全部断开(察觉不到对端)时才启用磁盘锁。平时就不上锁了。
4) 设置仲裁机制。例如设置参考IP(如网关IP),当心跳线完全断开时,2个节点都各自ping一下 参考IP,不通则表明断点就出在本端,不仅"心跳"、还兼对外"服务"的本端网络链路断了,即使启动(或继续)应用服务也没有用了,那就主动放弃竞争,让能够ping通参考IP的一端去起服务。更保险一些,ping不通参考IP的一方干脆就自我重启,以彻底释放有可能还占用着的那些共享资源。
Zookeeper集群的"脑裂"问题处理 - 运维总结的更多相关文章
- ZooKeeper 03 - ZooKeeper集群的脑裂问题 (Split Brain问题)
目录 1 ZooKeeper的主从机制 2 什么是ZooKeeper的脑裂 2.1 脑裂现象的表现 2.2 为什么会出现脑裂 3 ZooKeeper如何解决"脑裂" 3.1 3种可 ...
- 如何防止ElasticSearch集群出现脑裂现象(转)
原文:http://xingxiudong.com/2015/01/05/resolve-elasticsearch-split-brain/ 什么是“脑裂”现象? 由于某些节点的失效,部分节点的网络 ...
- 如何防止ElasticSearch集群出现脑裂现象
什么是“脑裂”现象? 由于某些节点的失效,部分节点的网络连接会断开,并形成一个与原集群一样名字的集群,这种情况称为集群脑裂(split-brain)现象.这个问题非常危险,因为两个新形成的集群会同时索 ...
- Docker集群管理工具 - Kubernetes 部署记录 (运维小结)
一. Kubernetes 介绍 Kubernetes是一个全新的基于容器技术的分布式架构领先方案, 它是Google在2014年6月开源的一个容器集群管理系统,使用Go语言开发,Kubernete ...
- Nginx+PHP负载均衡集群环境中Session共享方案 - 运维笔记
在网站使用nginx+php做负载均衡情况下,同一个IP访问同一个页面会被分配到不同的服务器上,如果session不同步的话,就会出现很多问题,比如说最常见的登录状态. 下面罗列几种nginx负载均衡 ...
- ZooKeeper 02 - ZooKeeper集群的节点为什么是奇数个
目录 1 关于节点个数的说明 2 ZooKeeper集群的容错数 3 ZooKeeper集群可用的标准 4 为什么不能是偶数个节点 4.1 防止由脑裂造成的集群不可用 4.2 奇数个节点更省资源 4. ...
- ZooKeeper 04 - ZooKeeper 集群的节点为什么必须是奇数个
目录 1 - 关于节点个数的说明 2 - ZooKeeper 集群的容错数 3 - ZooKeeper 集群可用的标准 4 - 为什么不能是偶数个节点 4.1 防止由脑裂造成的集群不可用 4.2 奇数 ...
- Zookeeper集群节点数量为什么要是奇数个?
无论是公司的生产环境,还是自己搭建的测试环境,Zookeeper集群的节点个数都是奇数个.至于为什么要是奇数个,以前只是模糊的知道是为了满足选举需要,并不知道详细的原因.最近重点学习zookeeper ...
- Zookeeper集群搭建(单机多节点,伪集群,docker-compose集群)
Zookeeper介绍 原理简介 ZooKeeper是一个分布式的.开源的分布式应用程序协调服务.它公开了一组简单的原语,分布式应用程序可以在此基础上实现更高级别的同步.配置维护.组和命名服务.它的设 ...
随机推荐
- postgres centos 创建数据库 创建用户
一个小的流程关于如何创建数据库和用户,用以加强印象,以及留档备份 一.创建账户 1.登录postgres账户 su postgres 2.进入psql 指令 psql 3.创建用户 create US ...
- 多个线程运行MR程序时hadoop出现的问题
夜间多个任务同时并行,总有几个随机性有任务失败,查看日志: cat -n ads_channel.log |grep "Caused by" Caused by: java.uti ...
- vue获取后端数据放在created还是mounted方法里面?
问题提出: 我们知道一般vue使用ajax或者axios来获取后端数据,并且好像放在created里面和mounted里面都可以获取数据并正确渲染.那么放在created里面和mounted里面有什么 ...
- ASP.NET MVC教程四:ASP.NET MVC中页面传值的几种方式
准备 在Models文件夹里面新添加Student实体类,用来模拟从Controller向View传递数据,Student类定义如下: using System; using System.Colle ...
- PlayJava Day013
今日所学: /* 2019.08.19开始学习,此为补档. */ 1.BufferedImage:是Image的一个子类,两者的主要作用就是将一副图片加载到内存中,即图像缓冲区. 对于本地图片: Fi ...
- C#中获取多个对象list中对象共有的属性项
场景 有一组数据list<TestDataList> 每一个TestDataList是一个对象,此对象可能有温度数据,也可能没有温度数据. 有温度数据的情况下,温度数据属性又是一个list ...
- RCA:收单设备调用云端接口频繁超时排查总结
研发中心/王鹏 2019年7月 关键词:OKHTTP,安卓,连接复用,开源软件BUG 一.背景知识: OKHTTP已是安卓项目中被广泛使用的网络请求开源库,它有如下特性: 1.支持HTTP/2,允许所 ...
- ABP入门教程5 - 界面调整
点这里进入ABP入门教程目录 调整前 调整后 调整项 页面标题 把favicon.ico替换为指定Logo JD.CRS.Web.Mvc\wwwroot\favicon.ico 顶部工具栏 把logo ...
- css权重问题
权重决定了你css规则怎样被浏览器解析直到生效.“css权重关系到你的css规则是怎样显示的 权重记忆口诀.从0开始,一个行内样式+1000,一个id+100,一个属性选择器/class或者伪类+10 ...
- android 对于asset和raw下文件的操作
Android 中资源分为两种,一种是res下可编译的资源文件, 这种资源文件系统会在R.Java里面自动生成该资源文件的ID,访问也很简单,只需要调用R.XXX.id即可;第二种就是放在assets ...