Python爬虫的起点
第一章主要讲解爬虫相关的知识如:http、网页、爬虫法律等,让大家对爬虫有了一个比较完善的了解和一些题外的知识点。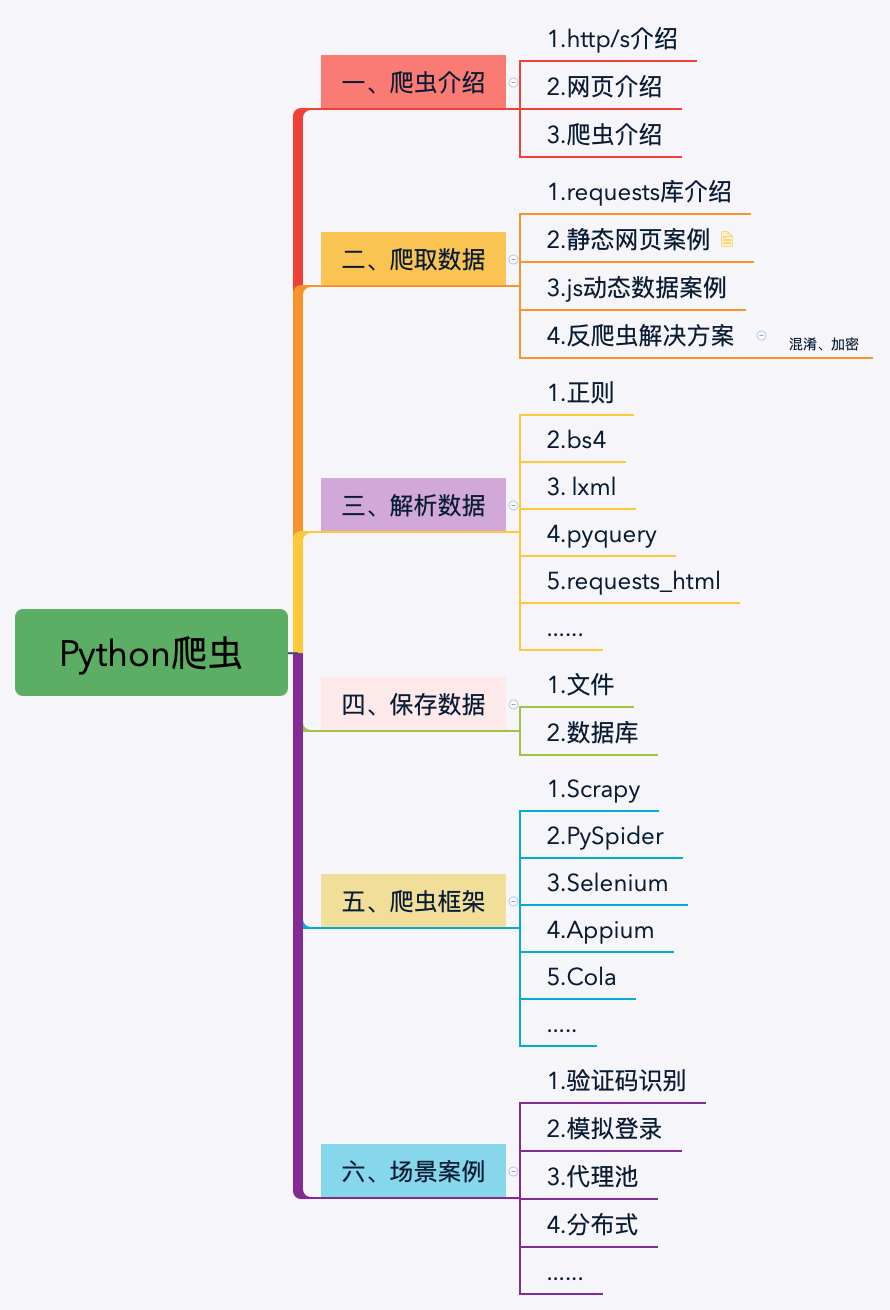
今天这篇文章将是我们第二章的第一篇,我们从今天开始就正式进入实战阶段,后面将会有更多的实际案例。
爬虫系列文章的第一篇,猪哥便为大家讲解了HTTP原理,很多人好奇:好好的讲爬虫和HTTP有什么关系?其实我们常说的爬虫(也叫网络爬虫)就是使用一些网络协议发起的网络请求,而目前使用最多的网络协议便是HTTP/S网络协议簇。
一、Python有哪些网络库
在真实浏览网页我们是通过鼠标点击网页然后由浏览器帮我们发起网络请求,那在Python中我们又如何发起网络请求的呢?答案当然是库,具体哪些库?猪哥给大家列一下:
- Python2: httplib、httplib2、urllib、urllib2、urllib3、requests
- Python3: httplib2、urllib、urllib3、requests
Python网络请求库有点多,而且还看见网上还都有用过的,那他们之间有何关系?又该如何选择?
- httplib/2:这是一个Python内置http库,但是它是偏于底层的库,一般不直接用。而httplib2是一个基于httplib的第三方库,比httplib实现更完整,支持缓存、压缩等功能。一般这两个库都用不到,如果需要自己 封装网络请求可能会需要用到。
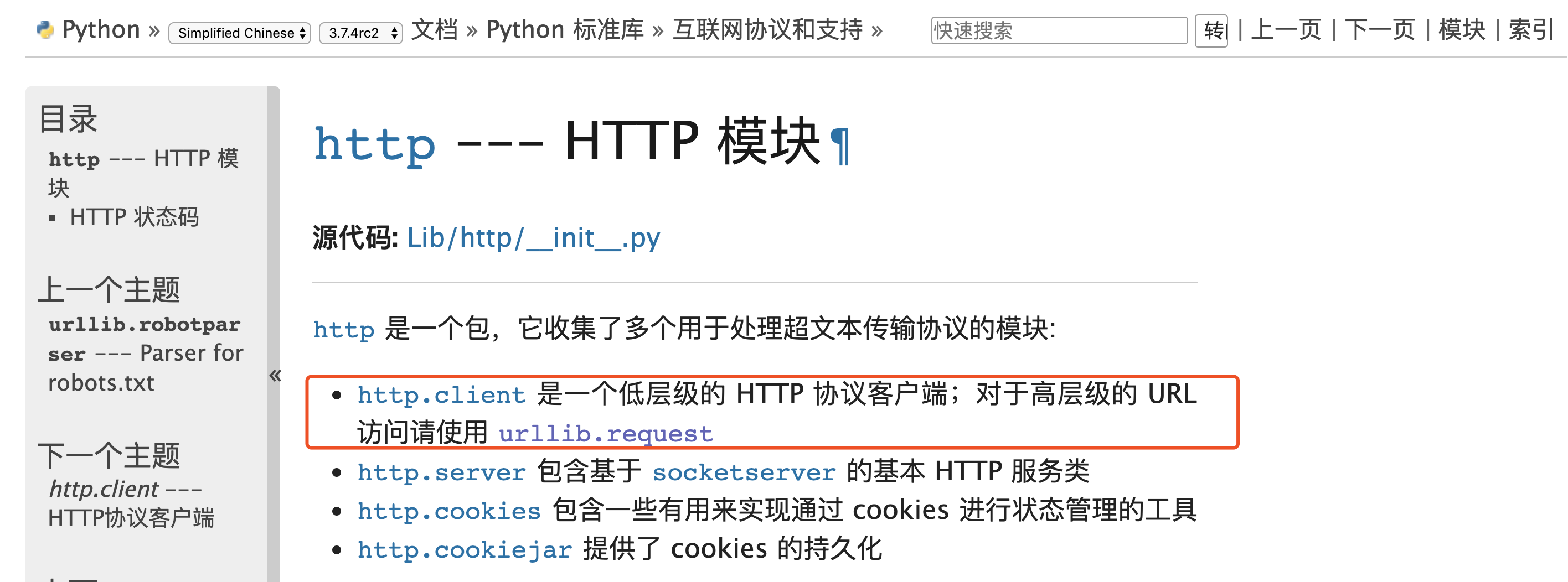
- urllib/urllib2/urllib3:urlliib是一个基于httplib的上层库,而urllib2和urllib3都是第三方库,urllib2相对于urllib增加一些高级功能,如:HTTP身份验证或Cookie等,在Python3中将urllib2合并到了urllib中。urllib3提供线程安全连接池和文件post等支持,与urllib及urllib2的关系不大。
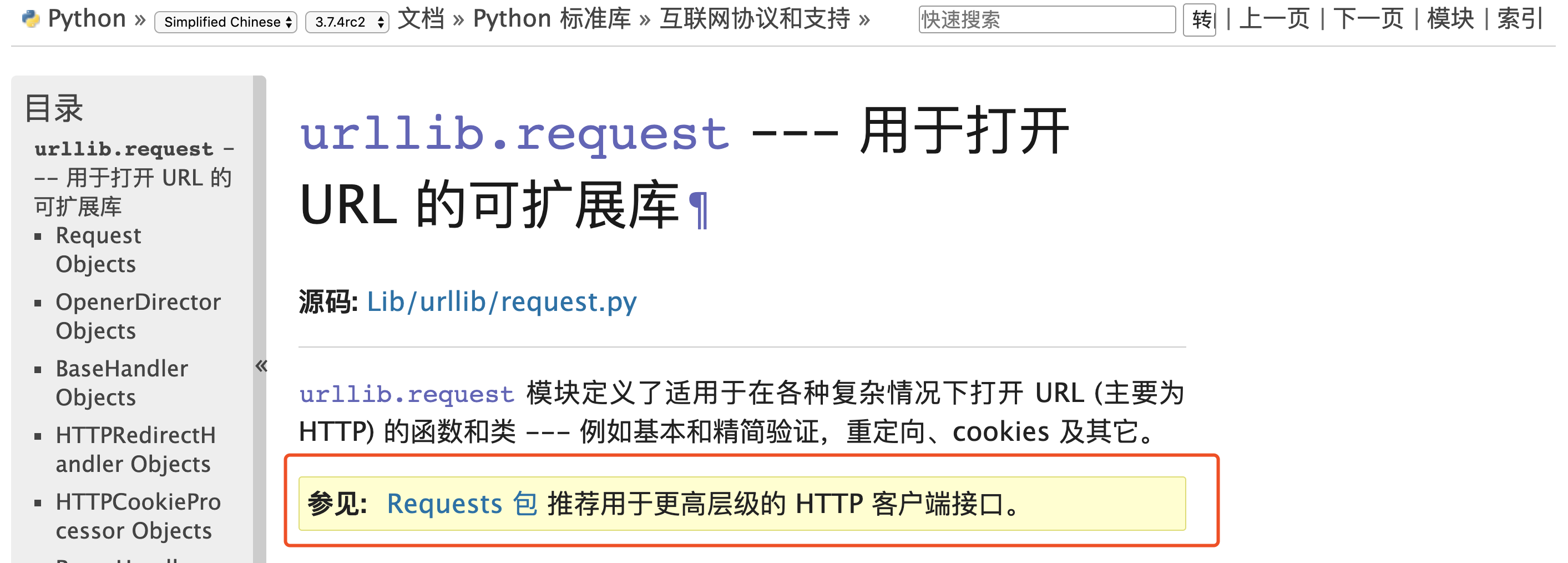
- requests:requests库是一个基于urllib/3的第三方网络库,它的特点是功能强大,API优雅。由上图我们可以看到,对于http客户端python官方文档也推荐我们使用requests库,实际工作中requests库也是使用的比较多的库。
综上所述,我们选择选择requests库作为我们爬虫入门的起点。另外以上的这些库都是同步网络库,如果需要高并发请求的话可以使用异步网络库:aiohttp,这个后面猪哥也会为大家讲解。
二、requests介绍
希望大家永远记住:学任何一门语言,都不要忘记去看看官方文档。也许官方文档不是最好的入门教程,但绝对是最新、最全的教学文档!
1.首页
requests的官方文档(目前已支持中文)链接:http://cn.python-requests.org
源代码地址:https://github.com/kennethreitz/requests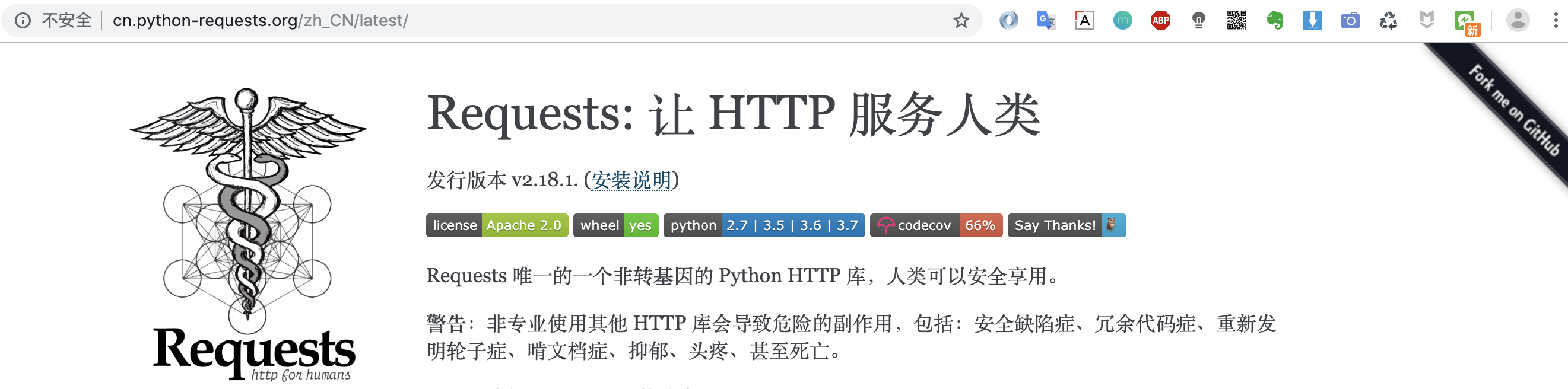
从首页中让HTTP服务人类这几个字中我们便能看出,requests核心宗旨便是让用户使用方便,间接表达了他们设计优雅的理念。
注:PEP 20便是鼎鼎大名的Python之禅。
警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症、冗余代码症、重新发明轮子症、啃文档症、抑郁、头疼、甚至死亡。
2.功能特性
都说requests功能强大,那我们来看看requests到底有哪些功能特性吧:
- Keep-Alive & 连接池
- 国际化域名和 URL
- 带持久 Cookie 的会话
- 浏览器式的 SSL 认证
- 自动内容解码
- 基本/摘要式的身份认证
- 优雅的 key/value Cookie
- 自动解压
- Unicode 响应体
- HTTP(S) 代理支持
- 文件分块上传
- 流下载
- 连接超时
- 分块请求
- 支持 .netrc
requests 完全满足今日 web 的需求。Requests 支持 Python 2.6—2.7以及3.3—3.7,而且能在 PyPy 下完美运行
三、安装requests
pip install requests
如果是pip3则使用
pip3 install requests
如果你使用anaconda则可以
conda install requests
如果你不想用命令行,可在pycharm中这样下载库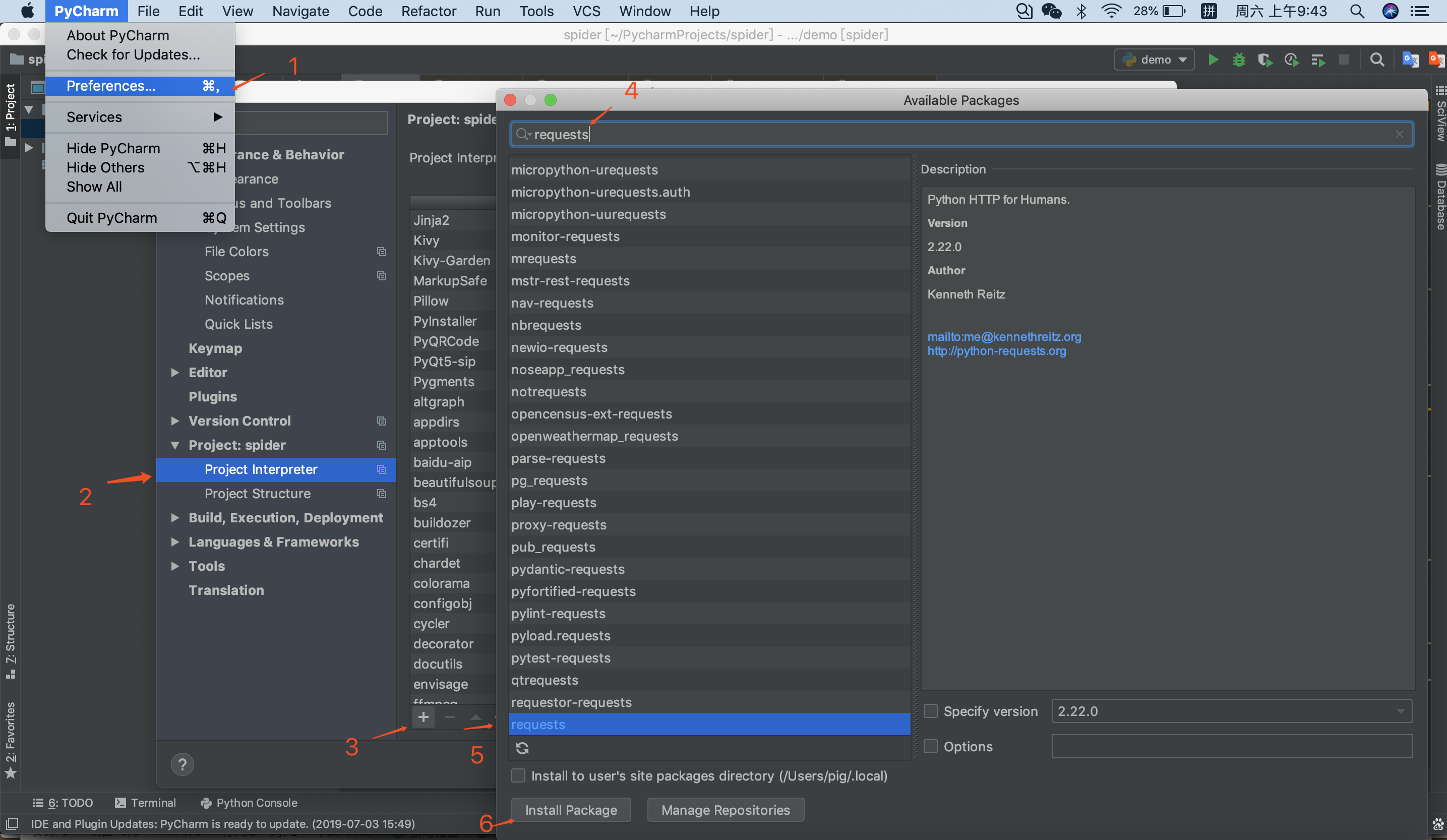
四、爬虫流程
下图是猪哥之前工作总结的一个项目开发流程,算是比较详细,在开发一个大型的项目真的需要这么详细,不然项目上线出故障或者修改需求都无法做项目复盘,到时候程序员就有可能背锅祭天。。。
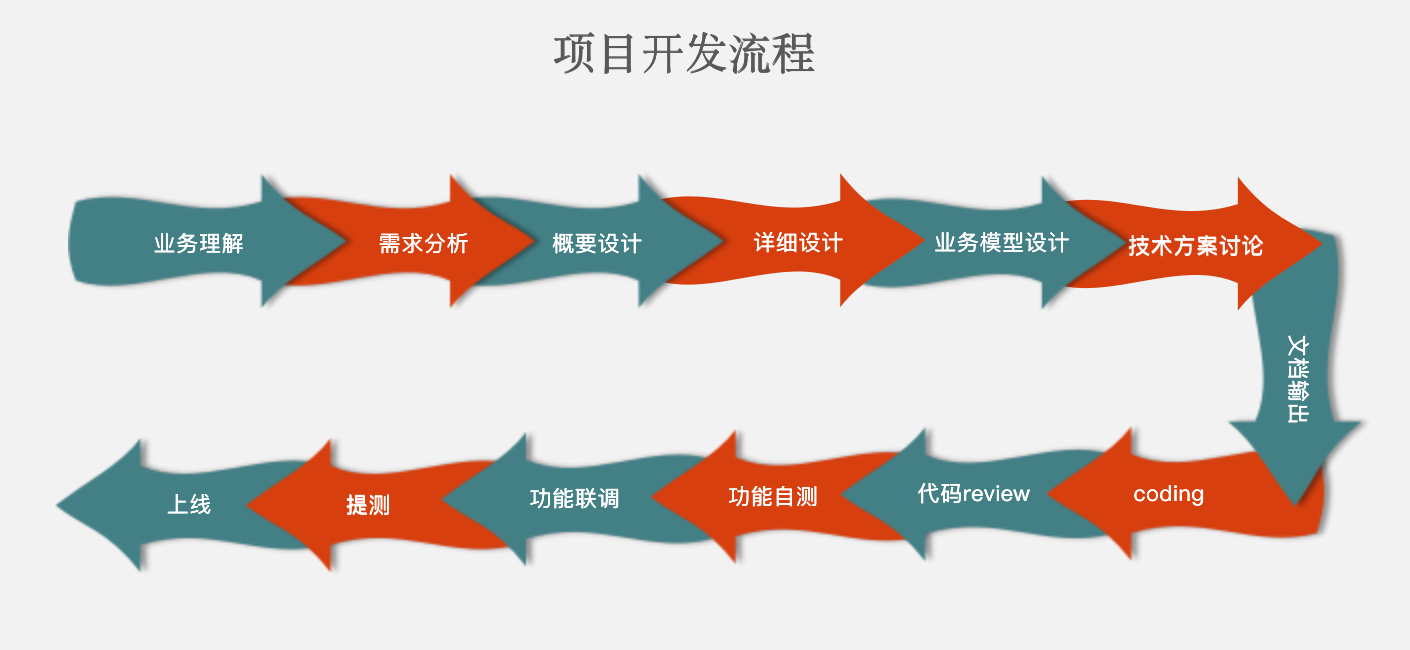
言归正传,给大家看项目的开发流程是想引出爬虫爬取数据的流程:
- 确定需要爬取的网页
- 浏览器检查数据来源(静态网页or动态加载)
- 寻找加载数据url的参数规律(如分页)
- 代码模拟请求爬取数据
五、爬取某东商品页
猪哥就以某东商品页为例子带大家学习爬虫的简单流程,为什么以某东下手而不是某宝?因为某东浏览商品页不需要登录,简单便于大家快速入门!
1.第一步:浏览器中找到你想爬取的商品
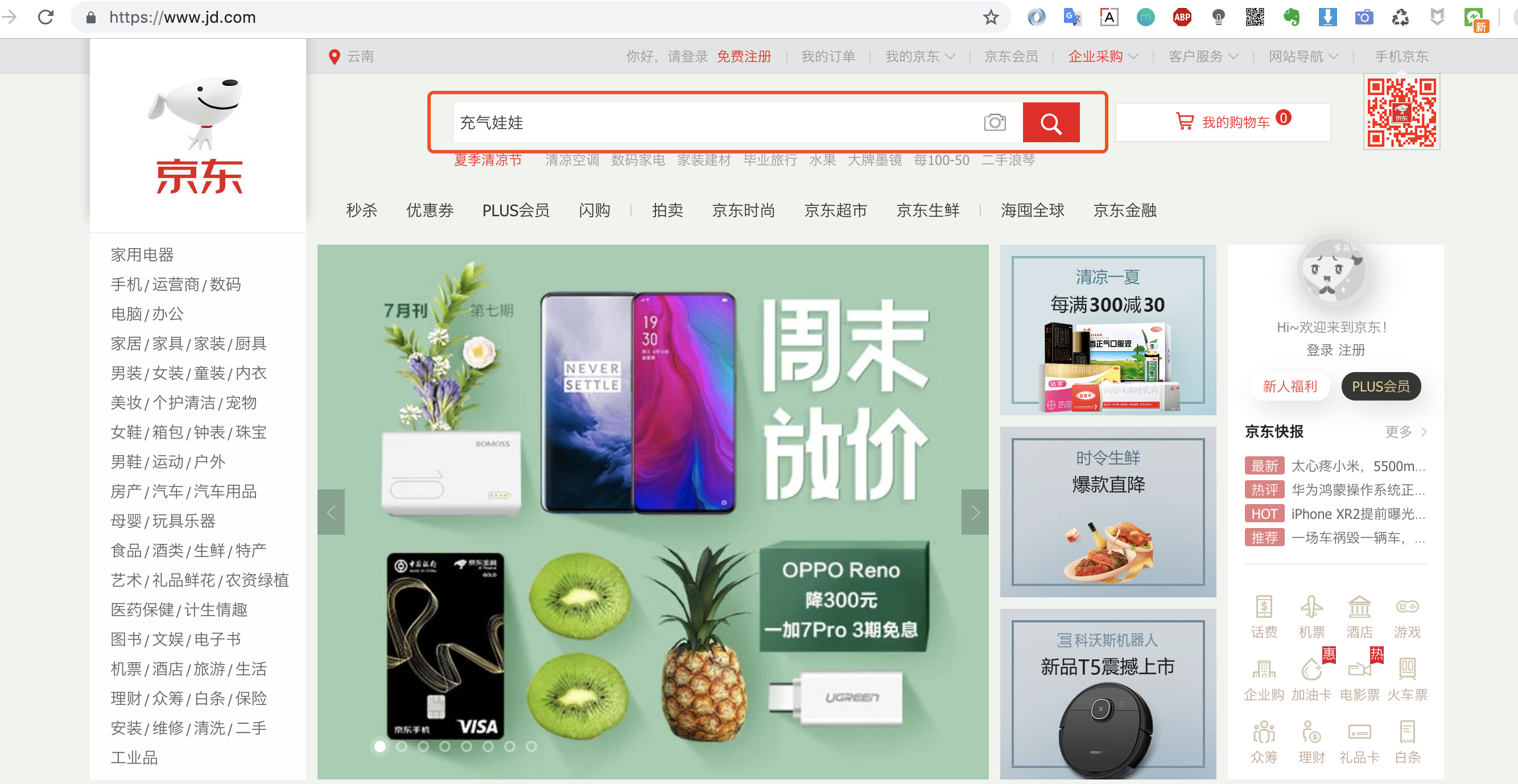
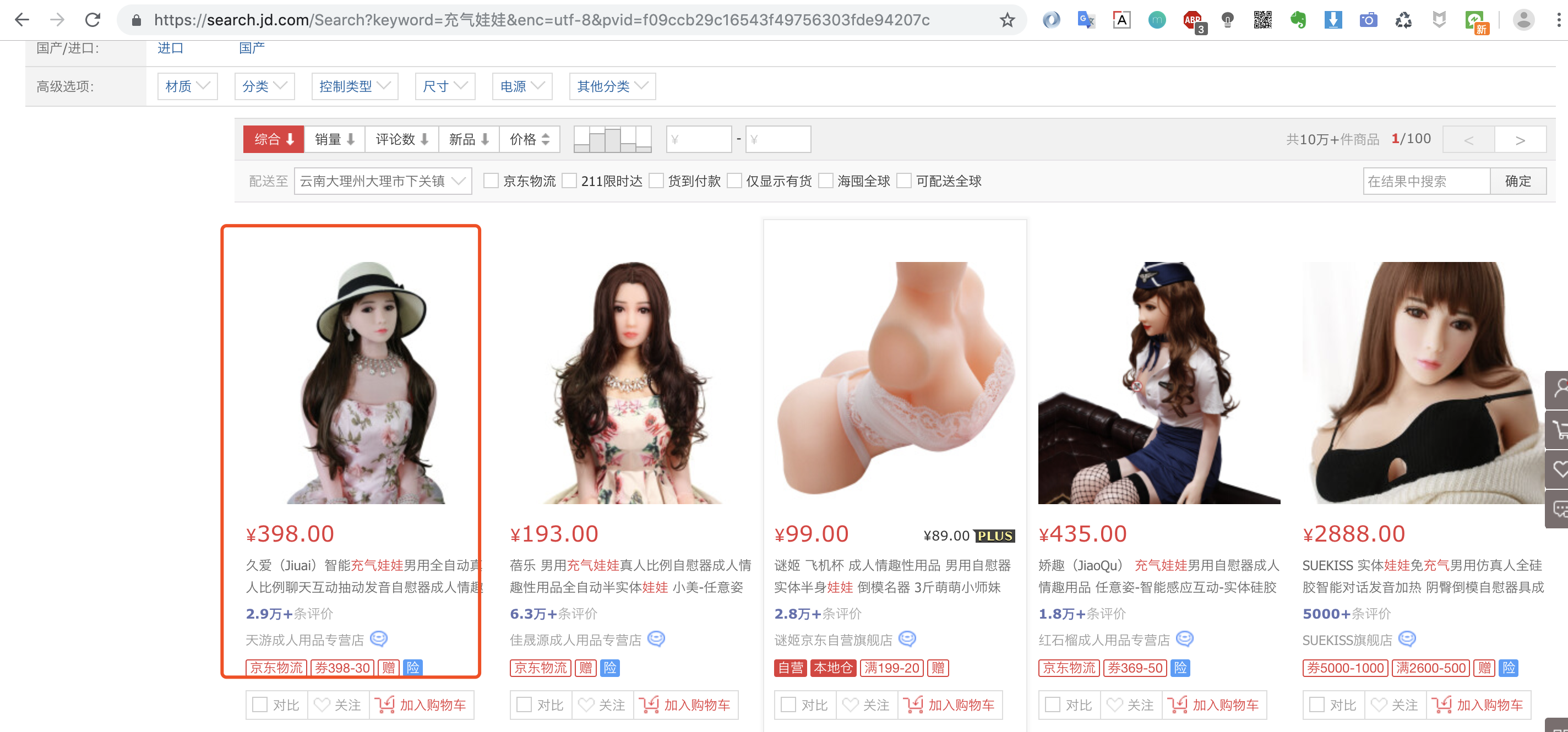

ps:猪哥并不是在开车哦,为什么选这款商品?因为后面会爬取这款商品的评价做数据分析,是不是很刺激!
2.第二步:浏览器检查数据来源
打开浏览器调试窗口是为了查看网络请求,看看数据是怎么加载的?是直接返回静态页面呢,还是js动态加载呢?
鼠标右键然后点检查或者直接F12即可打开调试窗口,这里猪哥推荐大家使用Chrome浏览器,为什么?因为好用,程序员都在用!具体的Chrome如何调试,大家自行网上看教程!
打开调试窗口之后,我们就可以重新请求数据,然后查看返回的数据,确定数据来源。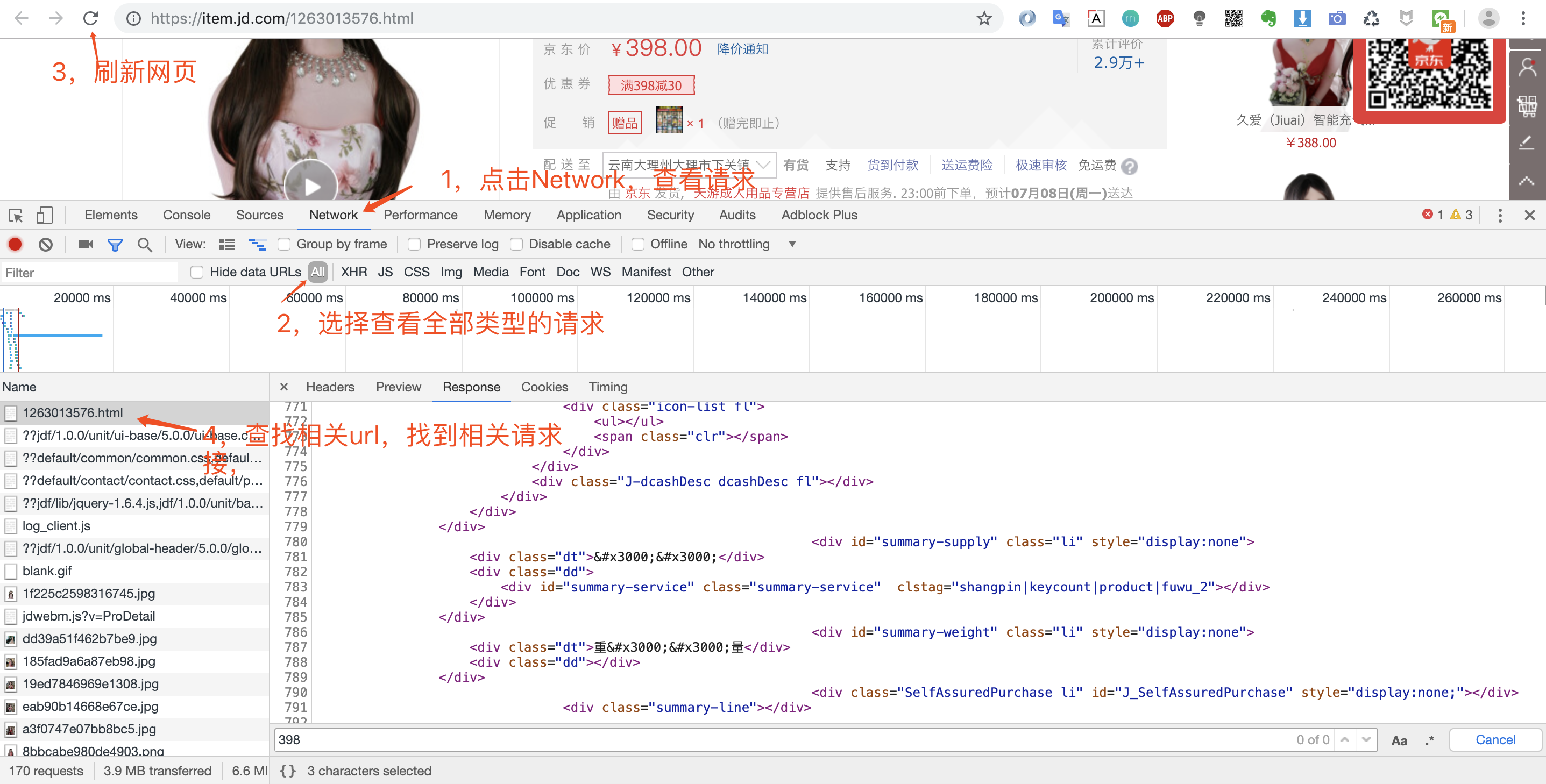
3.第三步:寻找加载数据url的参数规律
我们可以看到第一个请求链接:https://item.jd.com/1263013576.html 返回的数据便是我们要的网页数据。因为我们是爬取商品页,所以不存在分页之说。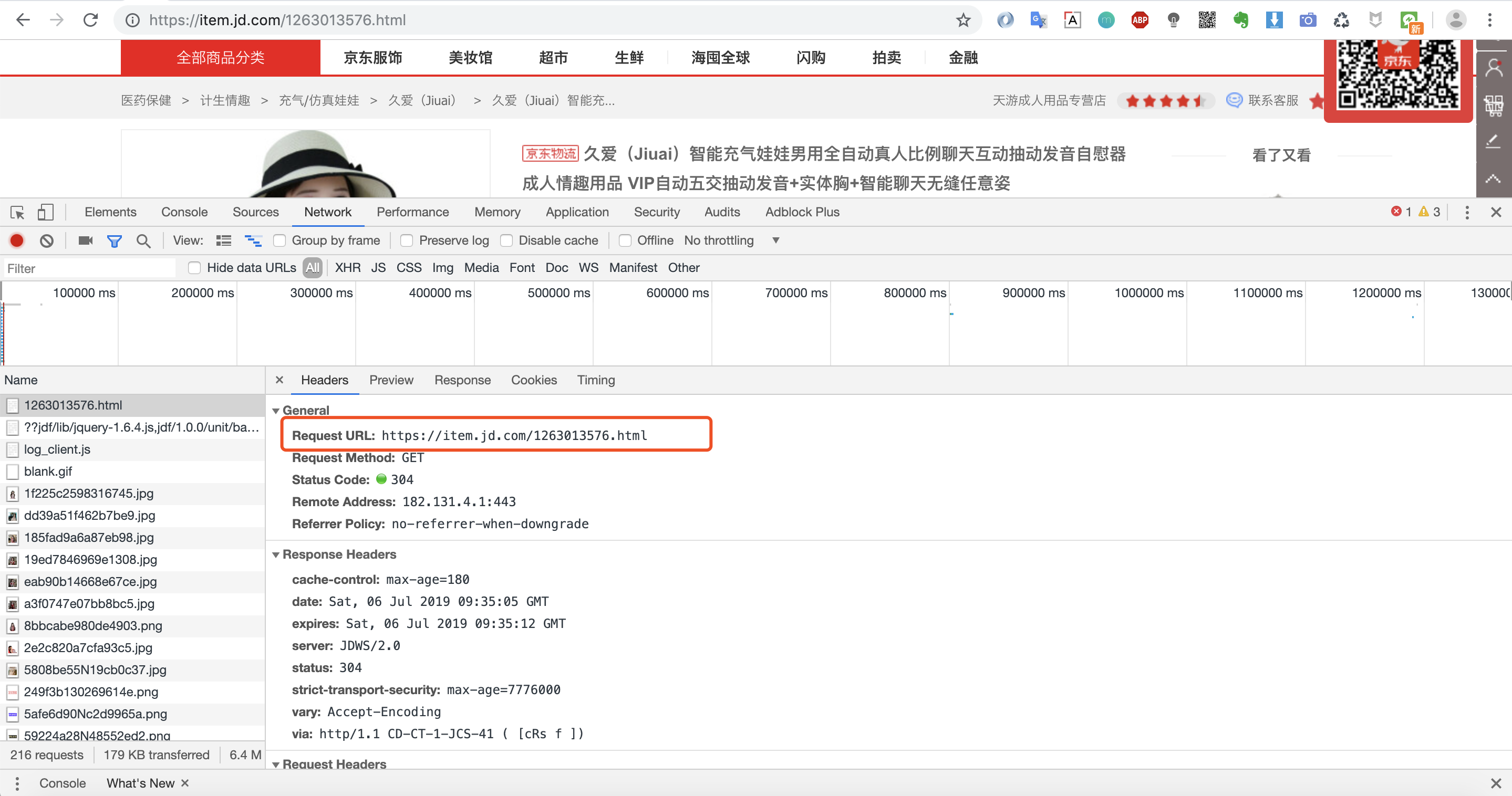
当然价格和一些优惠券等核心信息是通过另外的请求加载,这里我们暂时不讨论,先完成我们的第一个小例子!
4.第四步:代码模拟请求爬取数据
获取url链接之后我们来开始写代码吧
import requests
def spider_jd():
"""爬取京东商品页"""
url = 'https://item.jd.com/1263013576.html'
try:
r = requests.get(url)
# 有时候请求错误也会有返回数据
# raise_for_status会判断返回状态码,如果4XX或5XX则会抛出异常
r.raise_for_status()
print(r.text[:500])
except:
print('爬取失败')
if __name__ == '__main__':
spider_jd()
检查返回结果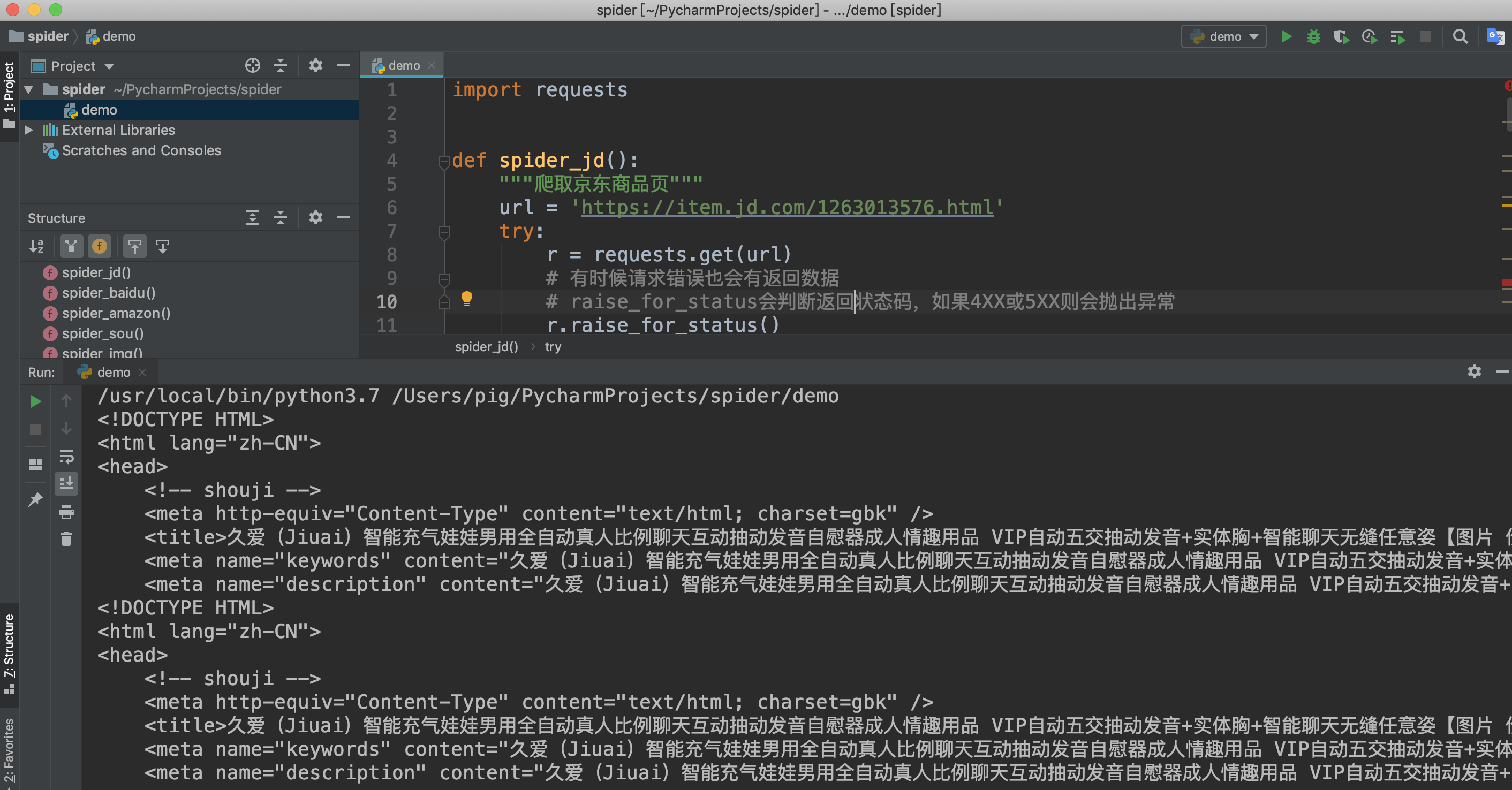
至此我们就完成了某东商品页的爬取,虽然案例简单,代码很少,但是爬虫的流程基本差不多,希望想学爬虫的同学自己动动手实践一把,选择自己喜欢的商品抓取一下,只有自己动手才能真的学到知识!
六、requests库介绍
上面我们使用了requests的get方法,我们可以查看源码发现还有其他几个方法:post、put、patch、delete、options、head,他们就是对应HTTP的请求方法。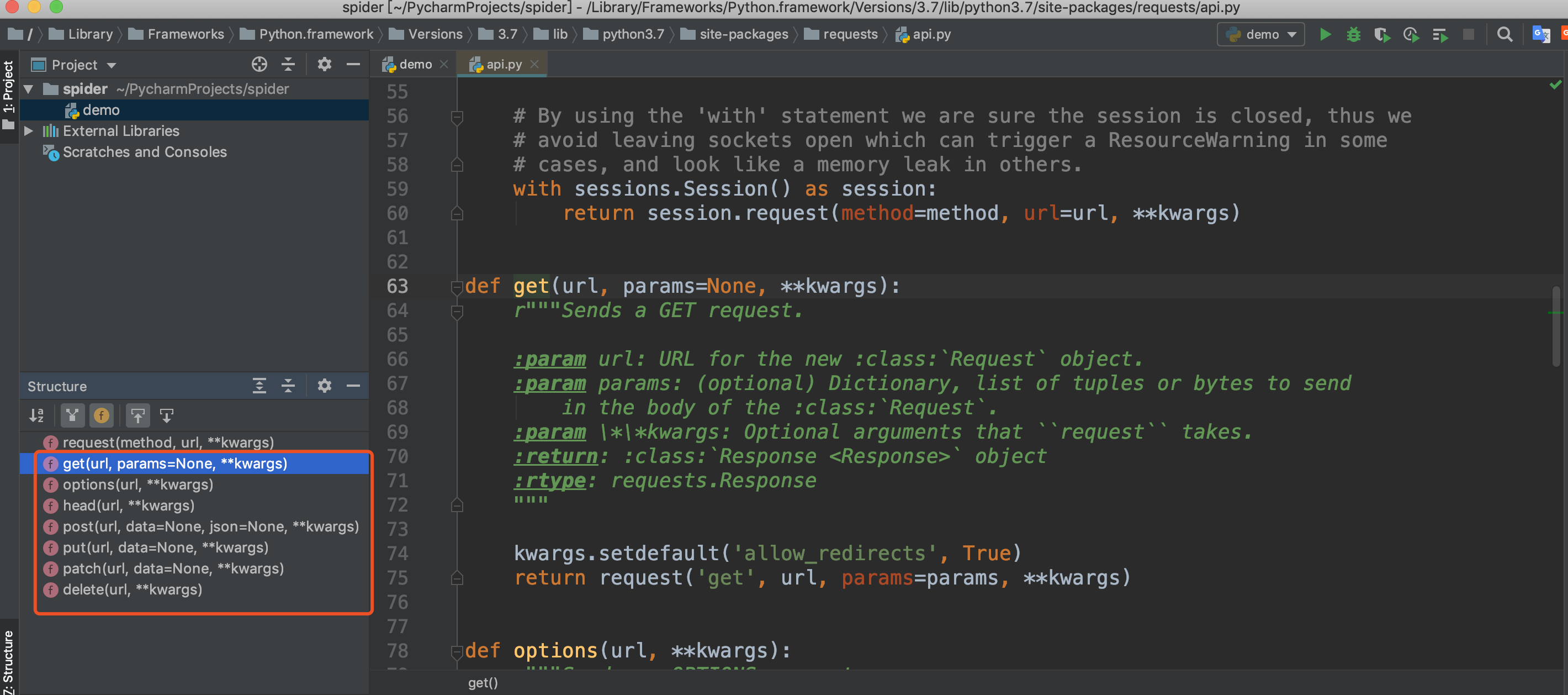
这里简单给大家列一下,后面会用大量的案例来用而后学,毕竟枯燥的讲解没人愿意看。
requests.post('http://httpbin.org/post', data = {'key':'value'})
requests.patch('http://httpbin.org/post', data = {'key':'value'})
requests.put('http://httpbin.org/put', data = {'key':'value'})
requests.delete('http://httpbin.org/delete')
requests.head('http://httpbin.org/get')
requests.options('http://httpbin.org/get')
注:httpbin.org是一个测试http请求的网站,能正常回应请求
对于HTTP的几种请求方法,没做过RestFul API的同学并不是很清楚每个请求方式表达的含义,这里给大家列一下:
- GET:获取用户列表:http://project.company.com/api/v1/users
- GET:获取单个用户:http://project.company.com/api/v1/users/{uid}
- POST:创建单个用户:http://project.company.com/api/v1/users/{uid}
- PUT:完全替换用户:http://project.company.com/api/v1/users/{uid}
- PATCH:局部更新用户:http://project.company.com/api/v1/users/{uid}
- DELETE:删除单个用户:http://project.company.com/api/v1/users/{uid}
想了解requests更多使用方法请参考:http://cn.python-requests.org
后面猪哥也会用大量案例来一点一点学习requests库的一些使用技巧。
七、总结
今天为大家简单介绍了一下这个非常重要的库:requests,requests可以胜任很多简单的爬虫需求,它强大的功能以及优美的api得到一致的认同。
有人多同学会问:爬虫到什么境界才算是入门?你会熟练使用requests库去实现一些简单的爬虫功能就算入门,并不是说需要会各种框架才算是入门,相反能使用低级工具实现功能的才更具潜力!
如果你有 有趣的爬虫案例或者想法,务必在下方留言,让我看看你们的骚操作。
Python爬虫的起点的更多相关文章
- Python爬虫与数据分析之爬虫技能:urlib库、xpath选择器、正则表达式
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python爬虫与数据分析之模块:内置模块、开源模块、自定义模块
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- Python爬虫与数据分析之进阶教程:文件操作、lambda表达式、递归、yield生成器
专栏目录: Python爬虫与数据分析之python教学视频.python源码分享,python Python爬虫与数据分析之基础教程:Python的语法.字典.元组.列表 Python爬虫与数据分析 ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用(转)
阅读目录 一.Selenium介绍 二.爬虫为什么要用selenium? 三.PhantomJS介绍 四.PhantomJS安装 五.操作实战 六.在此推荐虫师博客的学习资料 selenium + p ...
- python爬虫积累(一)--------selenium+python+PhantomJS的使用
最近按公司要求,爬取相关网站时,发现没有找到js包的地址,我就采用selenium来爬取信息,相关实战链接:python爬虫实战(一)--------中国作物种质信息网 一.Selenium介绍 Se ...
- 零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻 ...
- Python爬虫突破封禁的6种常见方法
转 Python爬虫突破封禁的6种常见方法 2016年08月17日 22:36:59 阅读数:37936 在互联网上进行自动数据采集(抓取)这件事和互联网存在的时间差不多一样长.今天大众好像更倾向于用 ...
- Python 爬虫模拟登陆知乎
在之前写过一篇使用python爬虫爬取电影天堂资源的博客,重点是如何解析页面和提高爬虫的效率.由于电影天堂上的资源获取权限是所有人都一样的,所以不需要进行登录验证操作,写完那篇文章后又花了些时间研究了 ...
- python爬虫成长之路(一):抓取证券之星的股票数据
获取数据是数据分析中必不可少的一部分,而网络爬虫是是获取数据的一个重要渠道之一.鉴于此,我拾起了Python这把利器,开启了网络爬虫之路. 本篇使用的版本为python3.5,意在抓取证券之星上当天所 ...
随机推荐
- Android自注-15-Activity生命周期
很长一段时间没有写博客,懒,感慨一下. Activity的生命周期是一块以下附图: 通过代码下面简单的介绍一下.一些内容看代码的凝视: package com.mxy; import android. ...
- springboot 集成swagger ui
springboot 配置swagger ui 1. 添加依赖 <!-- swagger ui --> <dependency> <groupId>io.sprin ...
- IIS运行WCF服务报错
试图加载格式不正确的程序 image 解决方法 image HTTP 错误 500.19 image 解决方法在控制面板————>程序————>启用或关闭windows功能—— ...
- WPF 4 DataGrid 控件(自定义样式篇)
原文:WPF 4 DataGrid 控件(自定义样式篇) 在<WPF 4 DataGrid 控件(基本功能篇)>中我们已经学习了DataGrid 的基本功能及使用方法.本篇将继续 ...
- Java Policy
# What The policy for a Java™ programming language application environment (specifying which permiss ...
- SQLSTATE[HY000]: General error: 1205 Lock wait timeout exceeded; try restarting transaction 解决方法
SHOW FULL PROCESSLIST; KILL 263071
- 零元学Expression Blend 4 - Chapter 17 用实例了解互动控制项「CheckBox」I
原文:零元学Expression Blend 4 - Chapter 17 用实例了解互动控制项「CheckBox」I 本章将教大家如何运用CheckBox做实作上的变化:教你如何把CheckBox变 ...
- SQL Server 将某一列的值拼接成字符串
名称 海鲜水产 水果蔬菜 海参 肉禽蛋 牛排 腊味 生鲜食品 将以上一列变成: 生鲜食品,海鲜水产,水果蔬菜,海参,牛排,肉禽蛋,腊味 sql for xml path('')
- mencache的使用二
在这里说的是在C#中的使用,在C#中使用是需要引入驱动的, 可以在网上找,这里推荐一个链接http://sourceforge.net/projects/memcacheddotnet/ 将Memca ...
- 从Java和JavaScript来学习Haskell和Groovy
直击现场 记得刚接触计算机的时候,我就受到了两个非常巨大的错误观念的影响,这个观念最初是来自于老师的传授还是学长的教诲已经记不清了,但是直到我工作几年以后,才慢慢有了实际的体会: 学习和使用什么编程语 ...