简单的scrapy实例
前天实验室的学长要求写一个简单的scrapy工程出来,之前也多少看了点scrapy的知识,但始终没有太明白,刚好趁着这个机会,加深一下对scrapy工作流程的理解。由于临近期末,很多作业要做(其实。。。。。。。。。。。。。。主要还是自己太菜了,嘻嘻),所以决定去搜一个简单的实例模仿一下。
显示搜了一个爬取腾讯招聘网了例子(https://www.cnblogs.com/xinyangsdut/p/7628770.html),动手敲完之后无法运行,试着调式,也无法解决。就又去找了一个爬取博客园的(https://www.jianshu.com/p/78f0bc64feb8),这个例子只能爬取第一页,稍微改了下,可以爬取任意多个页面。再改的时候,也遇到了一下麻烦。还是对scrapy理解不够(其实。。。。。。。还是自己太菜,流下了无知的眼泪),不过最好总算是顺利完成了。下面,简单的解剖一下这个例子。
- 首先是编写item文件,根据爬取的内容,定义爬取字段。代码如下:
import scrapy class CnblogItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() #定义爬取的标题
link = scrapy.Field() #定义爬取的连接 - 编写spider文件(这是关键),这里命名为cnblog_spider,代码如下:
# -*- coding: utf-8 -*-
import scrapy
from cnblog.items import CnblogItem class CnblogSpiderSpider(scrapy.Spider):
name = "cnblog_spider"
allowed_domains = ["cnblogs.com"]
url = 'https://www.cnblogs.com/sitehome/p/'
offset = 1
start_urls = [url+str(offset)] def parse(self, response): item = CnblogItem() item['title'] = response.xpath('//a[@class="titlelnk"]/text()').extract() #使用xpath搜索
item['link'] = response.xpath('//a[@class="titlelnk"]/@href').extract() yield item print("第{0}页爬取完成".format(self.offset))
if self.offset < 10: #爬取到第几页
self.offset += 1
url2 = self.url+str(self.offset) #拼接url
print(url2)
yield scrapy.Request(url=url2, callback=self.parse)就这部分代码内容来说,没什么难于理解的,但如果搞明白整个运行流程的话,对理解scrapy有很大的帮助。
- 编写pipelines文件,用于把我们爬取到的数据写入TXT文件。
class FilePipeline(object):
def process_item(self, item, spider): data = '' with open('cnblog.txt', 'a', encoding='utf-8') as f:
titles = item['title']
links = item['link']
for i, j in zip(titles, links):
data += i+' '+j+'\n' f.write(data)
f.close()
return item - 更改setting文件
ROBOTSTXT_OBEY = False #一定要把这个参数的值更改为Fals
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
#user-agent新添加
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
#新修改
ITEM_PIPELINES = {
'cnblog.pipelines.FilePipeline': 300, #实现保存到txt文件 } - 编写一个main文件,scrapy是不能在编译器里面调试的,但我们可以自己写一个主文件,运行这个主文件就可以像普通的工程一样在编译器里调式了。代码如下
from scrapy import cmdline cmdline.execute("scrapy crawl cnblog_spider --nolog".split()) #--nolog是以不显示日志的形式运行,如果需要看详细信息,可以去掉现在,我们这个例子就算是写完了,运行main.py,就会生成一个cnblog.Ttxt的文件,里面就是我们爬取下来的内容了。如下图
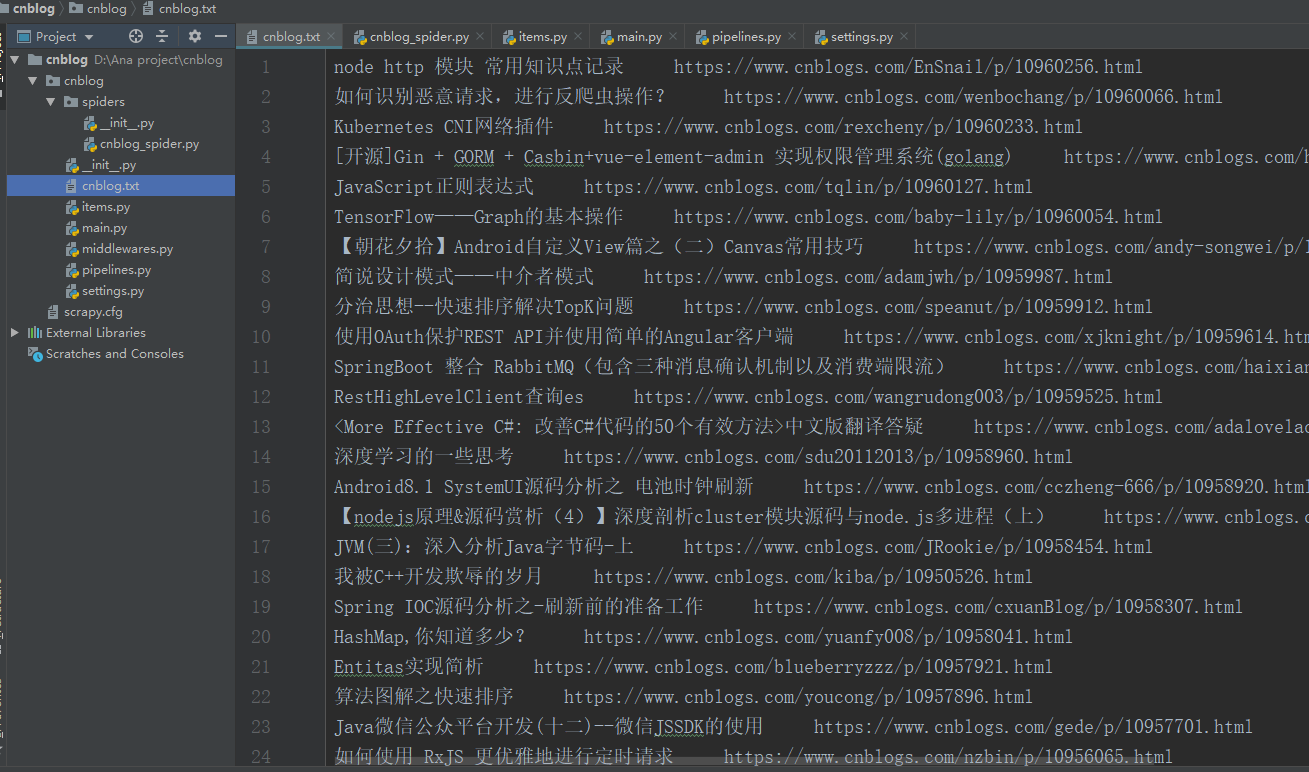
最后说一下写这个例子的收获与感想:在敲代码的过程中,发现自己对python一些知识点掌握的还是不够牢固,甚至是while循环一下子都写不出来,以后还是写多点py(别想歪哦)!另外还有一点,有时候真是没压力就没动力,之前学习scrapy时,一直没写出来一个能成功运行的例子,这次在学长的要求下,总算成功写出来了一个。虽然学习之路如此艰难,但绝不应该逃避。加油呀!!!!!
(ps:本人太菜,若有错误的地方欢迎大佬随时责骂。。。。xixixii)
简单的scrapy实例的更多相关文章
- [转]Scrapy简单入门及实例讲解
Scrapy简单入门及实例讲解 中文文档: http://scrapy-chs.readthedocs.io/zh_CN/0.24/ Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用 ...
- 审核流(3)低调奢华,简单不凡,实例演示-SNF.WorkFlow--SNF快速开发平台3.1
下面我们就从什么都没有,结合审核流进行演示实例.从无到有如何快速完美的实现,然而如此简单.低调而奢华,简单而不凡. 从只有数据表通过SNF.CodeGenerator代码生成器快速生成单据并与审核流进 ...
- 初学redux笔记,及一个最简单的redux实例
categories: 笔记 tags: react redux 前端框架 把初学redux的一些笔记写了下来 分享一个入学redux很合适的demo, 用redux实现计数器 这是从阮一峰老师git ...
- HTML与CSS简单页面效果实例
本篇博客实现一个HTML与CSS简单页面效果实例 index.html <!DOCTYPE html> <html> <head> <meta charset ...
- 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息
简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 简单的scrapy实战:爬取腾讯招聘北京地区的相关招聘信息 系统环境:Fedora22(昨天已安装scrapy环境) 爬取的开始URL:ht ...
- Java Tread多线程(0)一个简单的多线程实例
作者 : 卿笃军 原文地址:http://blog.csdn.net/qingdujun/article/details/39341887 本文演示,一个简单的多线程实例,并简单分析一下线程. 编程多 ...
- 使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(三)(错误整理篇)
使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(一) 使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(二) 以上两篇已经把流 ...
- 使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(二)(代码篇)
这篇是上一篇的延续: 用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(一) 源代码在github上可以下载,地址:https://github.com/guoxia ...
- 使用ssm(spring+springMVC+mybatis)创建一个简单的查询实例(一)
梳理下使用spring+springMVC+mybatis 整合后的一个简单实例:输入用户的 ID,之后显示用户的信息(此次由于篇幅问题,会分几次进行说明,此次是工程的创建,逆向生成文件以及这个简单查 ...
随机推荐
- WPF窗体隐藏鼠标光标的方法
原文:WPF窗体隐藏鼠标光标的方法 要引用 System.Windows.Input; Mouse.OverrideCursor = Cursors.None; 去掉 Override 则使用: ...
- getResources()方法
今天做一个Android文件管理器.它使用了很多当地的用途getResources. Drawable currentIcon = null; ------ current ...
- google 搜索结果在新标签中打开
google->setting->search setting->Where results open->检查
- Nucleus PLUS系统架构和组件
(一个)方法论和软件组件 1.软件组件(Software Component)定义 从一般意义上来说.组件(Component)是系统中能够明白辨识的组成部分,一个不透明的功能实现体.软件开发中,组件 ...
- WPF UpdateSourceTrigger的使用
<Window x:Class="XamlTest.Window8" xmlns="http://schemas.microsoft.com/winf ...
- 图片处理拓展篇 : 图片转字符画(ascii)
首先要明确思路, 图片是由像素组成的, 不同的像素有不同的颜色(rgb), 那么既然我们要转化为字符画, 最直接的办法就是利用字符串来替代像素, 也就是用不同的字符串来代表不同的像素. 另外图片一般来 ...
- Spring Web Flow 的优缺点
# 前言 Spring Web Flow = SWF 最近学习了<Spring实战>的第八章,Spring Web Flow.感觉是个不错的东西.无奈发现网上的资料少之又少.后来发现根本没 ...
- 展讯通信:文章"紫光收购后展讯困难重重”失实(展讯的成就确实很高)
6月22日上午消息,展讯通信官方微信对自媒体文章<五大危机缠身,紫光收购后展讯困难重重>作出声明,称,其中内容严重失实,对公司造成了不良影响,并表示,将坚决采取法律手段维护自身的合法权益. ...
- C#图片旋转
这里以Bitmap为例说明问题. 可以看到,旋转方法需要传入一个参数,而这个参数是一个枚举类型,RotateFlipType. 系统提供了两大类型的旋转, 1.旋转后不翻转. 2.旋转后接着翻转.翻转 ...
- Unity开发概览(HoloLens开发系列)
本文翻译自:Unity development overview 要开始使用Unity创建全息应用,点此安装包含Unity HoloLens技术预览的开发工具.Unity HoloLens技术预览基于 ...