05 (OC) 二叉树 深度优先遍历和广度优先遍历
总结深度优先与广度优先的区别
1、区别
1) 二叉树的深度优先遍历的非递归的通用做法是采用栈,广度优先遍历的非递归的通用做法是采用队列。
2) 深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历。具体说明如下:
- 先序遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
- 中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
- 后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止。
3)深度优先搜素算法:不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。
通常 深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些
4)深度优先遍历:用时间换空间。
广度优先遍历:用空间换时间。
2.二叉树的遍历
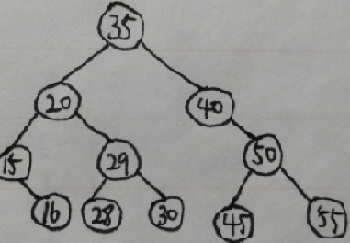
先序遍历(递归):35 20 15 16 29 28 30 40 50 45 55
中序遍历(递归):15 16 20 28 29 30 35 40 45 50 55
后序遍历(递归):16 15 28 30 29 20 45 55 50 40 35
先序遍历(非递归):35 20 15 16 29 28 30 40 50 45 55
中序遍历(非递归):15 16 20 28 29 30 35 40 45 50 55
后序遍历(非递归):16 15 28 30 29 20 45 55 50 40 35
广度优先遍历:35 20 40 15 29 50 16 28 30 45 55
05 (OC) 二叉树 深度优先遍历和广度优先遍历的更多相关文章
- js实现深度优先遍历和广度优先遍历
深度优先遍历和广度优先遍历 什么是深度优先和广度优先 其实简单来说 深度优先就是自上而下的遍历搜索 广度优先则是逐层遍历, 如下图所示 1.深度优先 2.广度优先 两者的区别 对于算法来说 无非就是时 ...
- 深度优先遍历 and 广度优先遍历
深度优先遍历 and 广度优先遍历 遍历在前端的应用场景不多,多数是处理DOM节点数或者 深拷贝.下面笔者以深拷贝为例,简单说明一些这两种遍历.
- C++ 二叉树深度优先遍历和广度优先遍历
二叉树的创建代码==>C++ 创建和遍历二叉树 深度优先遍历:是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. //深度优先遍历二叉树void depthFirstSearch(Tree r ...
- python、java实现二叉树,细说二叉树添加节点、深度优先(先序、中序、后续)遍历 、广度优先 遍历算法
数据结构可以说是编程的内功心法,掌握好数据结构真的非常重要.目前基本上流行的数据结构都是c和c++版本的,我最近在学习python,尝试着用python实现了二叉树的基本操作.写下一篇博文,总结一下, ...
- 二叉树的深度优先遍历与广度优先遍历 [ C++ 实现 ]
深度优先搜索算法(Depth First Search),是搜索算法的一种.是沿着树的深度遍历树的节点,尽可能深的搜索树的分支. 当节点v的所有边都己被探寻过,搜索将回溯到发现节点v的那条边的起始节点 ...
- 树的深度优先遍历和广度优先遍历的原理和java实现代码
import java.util.ArrayDeque; public class BinaryTree { static class TreeNode{ int value; TreeNode le ...
- 邻接矩阵c源码(构造邻接矩阵,深度优先遍历,广度优先遍历,最小生成树prim,kruskal算法)
matrix.c #include <stdio.h> #include <stdlib.h> #include <stdbool.h> #include < ...
- C++编程练习(9)----“图的存储结构以及图的遍历“(邻接矩阵、深度优先遍历、广度优先遍历)
图的存储结构 1)邻接矩阵 用两个数组来表示图,一个一维数组存储图中顶点信息,一个二维数组(邻接矩阵)存储图中边或弧的信息. 2)邻接表 3)十字链表 4)邻接多重表 5)边集数组 本文只用代码实现用 ...
- js实现对树深度优先遍历与广度优先遍历
深度优先与广度优先的定义 首先我们先要知道什么是深度优先什么是广度优先. 深度优先遍历是指从某个顶点出发,首先访问这个顶点,然后找出刚访问这个结点的第一个未被访问的邻结点,然后再以此邻结点为顶点,继续 ...
随机推荐
- v语言怎么玩
直接上github: https://github.com/vlang/v 前戏 大概是在6月份的时候,在github上看到了这个玩意,我以为是??? 我下意识的去查了一下有没有人在讨论这个语言,但是 ...
- Top11 构建和测试API的工具
立刻像专业人士一样构建API 组织正在改变他们已经在软件应用项目中成功的微服务架构模型,这就是大多数微服务项目使用API(应用程序接口)的原因. 我们要为微服务喝彩,因为它相对于其他的模型有各种先进的 ...
- 【翻译】无需安装Python,就可以在.NET里调用Python库
原文地址:https://henon.wordpress.com/2019/06/05/using-python-libraries-in-net-without-a-python-installat ...
- d3.js V5版本在vue里使用 自定义节点图片
var width = this.$refs.topInfo.offsetWidth; var height = this.$refs.topInfo.offsetHeight; var img_w ...
- Jmeter发送post请求报错Content type 'application/x-www-form-urlencoded;charset=UTF-8' not supported
常识普及: Content-type,在Request Headers里面,告诉服务器,我们发送的请求信息格式,在JMeter中,信息头存储在信息头管理器中,所以在做接口测试的时候,我们维护Conte ...
- Unity之SDK接入(Unity与Android通信)
首先介绍一点关于Android与unity通信的知识: 完成通信主要靠unity中的class.jar包(在unity的安装目录下). 在unity中调用android的方法: jo.call(&qu ...
- Java连载23-for循环练习、while\dowhile详解
一.for循环练习 1.例子:输入九九乘法表 public class d23_{ public static void main(String[] args) { for(int i = 1;i&l ...
- Java多线程之线程的状态迁移
Java多线程之线程的状态迁移 下图整理了线程的状态迁移.图中的线程状态(Thread.Stat 中定义的Enum 名)NEW.RUNNABLE .TERMINATED.WAITING.TIMED_W ...
- C++ 并发编程之互斥锁和条件变量的性能比较
介绍 本文以最简单生产者消费者模型,通过运行程序,观察该进程的cpu使用率,来对比使用互斥锁 和 互斥锁+条件变量的性能比较. 本例子的生产者消费者模型,1个生产者,5个消费者. 生产者线程往队列里放 ...
- docker运行原理与使用总结
docker运行原理概述 Client-Server架构 docker守护进程运行在宿主机上systemctl start docker daemon进程通过socket从客户端(docker命令)接 ...