[Spark] 04 - HBase
BHase基本知识
基本概念
自我介绍
HBase是一个分布式的、面向列的开源数据库,该技术来源于 Fay Chang 所撰写的Google论文“Bigtable:一个结构化数据的分布式存储系统”。
HBase在Hadoop之上提供了类似于Bigtable的能力。
HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。
另一个不同的是HBase基于列的而不是基于行的模式。
作为独立的体系,有其所属的资源:HBase教程
必要性
Ref: How and When should you use HBase NoSQL DB
HBase is a NoSQL database and it works on top of HDFS.
Data volume: peta bytes of data (1024 TB) 级别的数据才有必要。
Application Types: 不适合分析,毕竟sql天生适合分析。
Hardware environment: 硬件得好。
No requirement of relational features: 适合不需要怎么分析的数据。
Quick access to data: 适合随机实时访问。
作为比对:HBase is to real-time querying and Hive is to analytical queries.
四维定位
每个单元格都有版本控制的属性,也就是“时间戳”。
列被分为了 “列族“ 和 ”列限定符“。
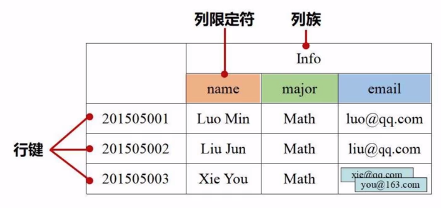
存储原理
逻辑视图可能是稀疏矩阵。
在物理视图中,会切割行分组保存。
演进过程
Ref: Hbase深入理解
Ref: 从mysql向HBase+Phoenix迁移数据的心得总结
通过这几个链接,了解HBase的一些“考点”。
第一阶段
谈谈MySQL应用的演化。
单实例
一旦MySQL挂了,服务全部停止;
一旦MySQL的磁盘坏了,公司的所有服务都没有了 (一般会定时备份数据文件)。
主从方案
垂直拆分
拆成多个库,已经无法join了,囧。
更多详情可参见:大众点评订单系统分库分表实践
第二阶段
HBase基于Zookeeper:HBase架构
Client会通过Zookeeper定位到 .META. 表;
根据 .META. 查找需要服务的RegionServer,连接RegionServer进行读写;
Client会缓存 .META. 表信息,下次可以直接连到RegionServer 。
MySQL成也B+,败也B+;HBase成也LSM,败也LSM。
优化思路
HBase优化点 (主要是读)
异步化
后台线程将memstore写入Hfile;
后台线程完成Hfile合并;
wal异步写入(数据有丢失的风险)。
数据就近
blockcache,缓存常用数据块:读请求先到memstore中查数据,查不到就到blockcache中查,再查不到就会到磁盘上读,把最近读的信息放入blockcache,基于LRU淘汰,可以减少磁盘读写,提高性能;
本地化,如果Region Server恰好是HDFS的data node,Hfile会将其中一个副本放在本地;
就近原则,如果数据没在本地,Region Server会取最近的data node中数据。
基于timestamp过滤
HFile存储结构
MySQL优化点(主要是写)
查询缓存
将SQL执行结果放入缓存。
缓存B+高层节点
一千万行的大表,一般只需要一棵3层的B+树,其中索引节点 (非叶子节点) 的大小约20MB。完全可以考虑将大部叶子节点缓存,基于主键查询只需要一次IO。
减少随机写——缓冲:延迟写/批量写
减少随机读——MRR
索引下推
进而就是一系列分布式方案,而HBase就是其中一种解决思路——只读主库保证一致,水平拆分、zk等机制保证自动运维、单行级ACID。
至于性能方面,由于存储思路不同,MySQL与HBase分别取舍了不同的读写性能。继而,就衍生出了如何针对性进行优化。
读写HBase数据
启动环境
先启动Hadoop。
再启动HBase,如下:
cd /usr/local/hbase
./bin/start-hbase.sh
./bin/hbase shell # 支持交互式操作
创建表
一,数据定义语言
这些是关于HBase在表中操作的命令。
- create: 创建一个表。
- list: 列出HBase的所有表。
- disable: 禁用表。
- is_disabled: 验证表是否被禁用。
- enable: 启用一个表。
- is_enabled: 验证表是否已启用。
- describe: 提供了一个表的描述。
- alter: 改变一个表。
- exists: 验证表是否存在。
- drop: 从HBase中删除表。
- drop_all: 丢弃在命令中给出匹配“regex”的表。
- Java Admin API: 在此之前所有的上述命令,Java提供了一个通过API编程来管理实现DDL功能。在这个org.apache.hadoop.hbase.client包中有HBaseAdmin和HTableDescriptor 这两个重要的类提供DDL功能。
首先,确保此表之前没有。
disable 'student'
drop 'student'
然后,创建如下表。

create 'student', 'info' # 意味着 'info'里包含:name, gender, age. put 'student', '', 'info: name', 'Xueqian'
put 'student', '', 'info: gender', 'F'
put 'student', '', 'info: age', ''
二,数据操纵语言
- put: 把指定列在指定的行中单元格的值在一个特定的表。
- get: 取行或单元格的内容。
- delete: 删除表中的单元格值。
- deleteall: 删除给定行的所有单元格。
- scan: 扫描并返回表数据。
- count: 计数并返回表中的行的数目。
- truncate: 禁用,删除和重新创建一个指定的表。
- Java client API: 在此之前所有上述命令,Java提供了一个客户端API来实现DML功能,CRUD(创建检索更新删除)操作更多的是通过编程,在org.apache.hadoop.hbase.client包下。 在此包HTable 的 Put和Get是重要的类。
配置Spark支持HBase


读取HBase数据
一、代码实例
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf) host = 'localhost'
table = 'student'
conf= {"hbase.zookeeper.quorum": host, "hbase.mapreduce.inputtable": table}
keyConv = "org.apache.spark.examples.pythonconverters.ImmutableBytesWritableToStringConverter"
valueConv= "org.apache.spark.examples.pythonconverters.HBaseResultToStringConverter"
hbase_rdd = sc.newAPIHadoopRDD("org.apache.hadoop.hbase.mapreduce.TableInputFormat", "org.apache.hadoop.hbase.io.ImmutableBytesWritable", "org.apache.hadoop.hbase.client.Result", \
keyConverter=keyConv, valueConverter=valueConv, conf=conf) count = hbase_rdd.count()
hbase_rdd.cache()
output = hbase_rdd.collect()
for (k, v) in output:
print (k, v)
二、执行代码

写入HBase数据
一、代码示例
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf) host = 'localhost'
table = 'student' keyConv = "org.apache.spark.examples.pythonconverters.StringToImmutableBytesWritableConverter"
valueConv = "org.apache.spark.examples.pythonconverters.StringListToPutConverter"
conf = {"hbase.zookeeper.quorum" :host,
"hbase.mapred.outputtable" :table,
"mapreduce.outputformat.class" :"org.apache.hadoop.hbase.mapreduce.TableOutputFormat",
"mapreduce.job.output.key.class" :"org.apache.hadoop.hbase.io.ImmutableBytesWritable",
"mapreduce.job.output.value.class":"org.apache.hadoop.io.Writable"} rawData = ['3,info,name,Rongcheng','3,info,gender,M','3,info,age,26','4,info,name,Guanhua','4,info,gender,M','4,info,age,27']
sc.parallelize(rawData).map(lambda x:(x[0],x.split(','))).saveAsNewAPIHadoopDataset(conf=conf, keyConverter=keyConv, valueConverter=valueConv)
二、运行结果

案例分析
以下其实是PySpark编程的例子,与HBase关系不大.
求Top值
对RDD中某一列排序。
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("ReadHBase")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/file")
# 内存中生成了一个rdd # 预处理,取出坏数据
result1 = lines.filter(lambda line: (len(line.strip()) > 0) and (len(line.split(","))== 4))
# 取出第三个元素,也就是第三列
result2 = result1.map(lambda x:x.split(",")[2])
# 转化为可以处理的数字形式
result3 = result2.map(lambda x:(int(x),""))
# 全局排序,所以只要一个分区
result4 = result3.repartition(1)
# 降序排列
result5 = result4.sortByKey(False)
result6 = result5.map(lambda x:x[0])
result7 = result6.take(5)
for a in result7:
print(a) lines = sc.textFile("file:///usr/local/spark/mycode/rdd/file")
若干文件内数字排序
原理类似上一个例子。
#!/usr/bin/env python3
from pyspark import SparkConf, SparkContext
index = 0
def getindex():
global index
index += 1
return index
def main():
conf = SparkConf().setMaster("local[1]").setAppName("FileSort")
sc = SparkContext(conf = conf)
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/filesort/file*.txt")
# 读取了若干文件,构成了一个RDD
index = 0
result1 = lines.filter(lambda line:(len(line.strip()) > 0))
result2 = result1.map(lambda x:(int(x.strip()),""))
result3 = result2.repartition(1)
result4 = result3.sortByKey(True)
result5 = result4.map(lambda x:x[0])
result6 = result5.map(lambda x:(getindex(),x))
result6.foreach(print)
result6.saveAsTextFile("file:///usr/local/spark/mycode/rdd/filesort/sortresult")
if __name__ == '__main__':
main()
lines = sc.textFile("file:///usr/local/spark/mycode/rdd/filesort/file*.txt")
result1 = lines.filter(lambda line:(len(line.strip()) > 0))
二次排序
根据多个属性去排序,比如总分一样的话就继续比较数学成绩。
重点是:构建一个可排序的,并且是可以二次排序的属性。
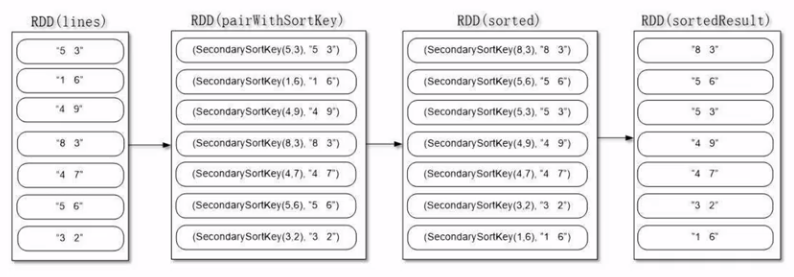
def main(
conf = SparkConf().setAppName('spark_sort').setMaster('local[1]')
sc = SparkContext(conf=conf)
file = "file:///usr/local/spark/mycode/rdd/secondarysort/file4.txt"
rdd1 = sc.textFile(file)
rdd2 = rdd1.filter(lambda x:(len(x.strip()) > 0))
rdd3 = rdd2.map(lambda x:((int(x.split(" ")[0]),int(x.split(" ")[1])),x)) # 写两个排序所需的key,生成”可排序“的rdd4
rdd4 = rdd3.map(lambda x: (SecondarySortKey(x[0]),x[1]))
rdd5 = rdd4.sortByKey(False)
rdd6 = rdd5.map(lambda x:x[1])
rdd6.foreach(print)
if __name__ == '__main__':
main()
rdd1 = sc.textFile(file)
rdd2 = rdd1.filter(lambda x:(len(x.strip()) > 0))
二次排序函数定义:
#!/usr/bin/env python3
from operator import gt
from pyspark import SparkContext, SparkConf
class SecondarySortKey():
def __init__(self, k):
self.column1 = k[0]
self.column2 = k[1]
def __gt__(self, other):
if other.column1 == self.column1:
return gt(self.column2,other.column2)
else:
return gt(self.column1, other.column1)
End.
[Spark] 04 - HBase的更多相关文章
- Spark整合HBase,Hive
背景: 场景需求1:使用spark直接读取HBASE表 场景需求2:使用spark直接读取HIVE表 场景需求3:使用spark读取HBASE在Hive的外表 摘要: 1.背景 2.提交脚本 内容 场 ...
- MapReduce和Spark写入Hbase多表总结
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 大家都知道用mapreduce或者spark写入已知的hbase中的表时,直接在mapreduc ...
- spark 操作hbase
HBase经过七年发展,终于在今年2月底,发布了 1.0.0 版本.这个版本提供了一些让人激动的功能,并且,在不牺牲稳定性的前提下,引入了新的API.虽然 1.0.0 兼容旧版本的 API,不过还是应 ...
- Spark操作hbase
于Spark它是一个计算框架,于Spark环境,不仅支持单个文件操作,HDFS档,同时也可以使用Spark对Hbase操作. 从企业的数据源HBase取出.这涉及阅读hbase数据,在本文中尽快为了尽 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- Spark读Hbase优化 --手动划分region提高并行数
一. Hbase的region 我们先简单介绍下Hbase的架构和Hbase的region: 从物理集群的角度看,Hbase集群中,由一个Hmaster管理多个HRegionServer,其中每个HR ...
- spark读写hbase性能对比
一.spark写入hbase hbase client以put方式封装数据,并支持逐条或批量插入.spark中内置saveAsHadoopDataset和saveAsNewAPIHadoopDatas ...
- Spark读写HBase
Spark读写HBase示例 1.HBase shell查看表结构 hbase(main)::> desc 'SDAS_Person' Table SDAS_Person is ENABLED ...
- Spark读HBase写MySQL
1 Spark读HBase Spark读HBase黑名单数据,过滤出当日新增userid,并与mysql黑名单表内userid去重后,写入mysql. def main(args: Array[Str ...
随机推荐
- 基于开源中文分词工具pkuseg-python,我用张小龙的3万字演讲做了测试
做过搜索的同学都知道,分词的好坏直接决定了搜索的质量,在英文中分词比中文要简单,因为英文是一个个单词通过空格来划分每个词的,而中文都一个个句子,单独一个汉字没有任何意义,必须联系前后文字才能正确表达它 ...
- 【雕爷学编程】Arduino动手做(16)---数字触摸传感器
37款传感器和模块的提法,在网络上广泛流传,其实Arduino能够兼容的传感器模块肯定是不止37种的.鉴于本人手头积累了一些传感器与模块,依照实践出真知(动手试试)的理念,以学习和交流为目的,这里准备 ...
- 深度学习环境搭建部署(DeepLearning 神经网络)
工作环境 系统:Ubuntu LTS 显卡:GPU NVIDIA驱动:410.93 CUDA:10.0 Python:.x CUDA以及NVIDIA驱动安装,详见https://www.cnblogs ...
- Http协议4个新的http状态码:428、429、431、511;
1.428 Precondition Required (要求先决条件) 先决条件是客户端发送 HTTP 请求时,必须要满足的一些预设条件.一个好的例子就是 If-None-Match 头,经常用在 ...
- Codeforces 337D
题意略. 思路: 本题着重考察树的直径.如果我们将这些标记点相连,将会得到大树中的一个子树.我之前只知道树内的点到直径上两端点的距离是最远的,其实,在 整个大树中,这个性质同样适用,也即大树上任意一点 ...
- Delphi - cxGrid字段类型设定为ComboBox 并实现动态加载Item
cxGrid设定字段类型为ComboBox 在cxGrid中选中需要设定的字段: 单击F11调出属性控制面板,在Properties下拉选项中选中ComboBox,完成字段类型的设定. cxGrid ...
- 使用ansible对思科交换机备份
先决条件 - 了解ansible基本操作 - 了解网络设备相关操作 - 了解linux相关操作 安装 安装EPEL yum install https://dl.fedoraproject.org/p ...
- Android定时锁屏功能实现(AlarmManager定时部分)
菜鸟入坑记——第一篇 关键字:AlarmManager 一.AlarmManager简介: 参考网址:https://www.jianshu.com/p/8a2ce9d02640 参考网 ...
- [Revit]开始:编写一个简单外部命令
1 创建项目 以Visual Stidio作为开发工具,测试平台为Revit 2017 打开VS,创建一个C# .NET Framwork类库项目,选择..net框架版本为.NET Framwork ...
- 模板汇总——AC自动机
AC自动机 模板题 HDU-2222 Keywords Search #include<bits/stdc++.h> using namespace std; #define LL lon ...