程序员的算法课(14)-Hash算法-对海量url判重
前面给大家讲了哈希表(散列)这种数据结构,那么使用哈希表来解决实际问题,那就是Hash算法了,我们一起来看看。
一、Hash算法的概念
Hash算法(Hash Algorithm),简称散列算法,也成哈希算法(英译),是将一个大文件映射成一个小串字符。与指纹一样,就是以较短的信息来保证文件的唯一性的标志,这种标志与文件的每一个字节都相关,而且难以找到逆向规律。
举个列子:
服务器存了10个文本文件,你现在想判断一个新的文本文件和那10个文件有没有一个是一样的。你不可能去比对每个文本里面的每个字节,很有可能,两个文本文件都是5000个字节,但是只有最后一位有所不同,但这样的,你前面4999位的比较就是毫无意义。那一个解决办法,就是在存储那10个文本文件的时候,都将每个文件映射成一个hash字符串。服务器只需要存储10个hash字符串,在判断的时候,只需要判断新的这个文本文件的hash值是否和那10个文件的hash值一致,那就可以解决这个问题了。
由于文件是无限的,而映射后的字符串能表示的位数是有限的。因此可能会存在不同的key对应相同的Hash值。这就存在碰撞的可能。
二、Hash算法的应用
java的数据结构中,很多类都有用到hash算法,比如String,HashMap。
1.String中的hashCode方法
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
可以看到,这里使用了31来作为乘级因子,这是为什么呢?
- 选择数字31是因为它是一个奇质数,如果选择一个偶数,因为乘二相当于左移一位,可能会产生溢出,导致数值信息溢出。
- 这一点的优势并不明显,但这是一个传统(选择质数)。
- 同时,数字31有一个很好的特性,乘法运算可以被移位和减法运算来取代,来获取更好的性能,而且这一点可以由jvm来自动完成。31*i=(i<<5)-i
2.HashMap中hash值
存在的目的是加速键值对的查找,key的作用是为了将元素适当的放在各个桶里,对于抗碰撞的要求没那么高。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
对key的hash计算,就是计算出key的hash值,并移动到低位,完成高低位的融合。
3.Hash在密码学中的应用
hash算法在密码学中主要是用于消息摘要和签名。换句话说,主要是对整个消息的完整性进行校验。
安全散列算法(英语:Secure Hash Algorithm,缩写为SHA),SHA家族的五个算法,分别是SHA-1、SHA-224、SHA-256、SHA-384,和SHA-512,由美国国家安全局(NSA)所设计,并由美国国家标准与技术研究院(NIST)发布;是美国的政府标准。后四者有时并称为SHA-2。
三、使用hash来解决字符串判重/字符串匹配问题
- 遇见不定长问题可通过二分+hash降低复杂度
- 遇见定长字符串问题可通过尺取+hash来降低复杂度
- 二维hash的时候尺取方法就是把之前不需要的都变为0再加上当前行,将匹配字符串整体下移,来验证hash值是否相等
PS:尺取法:顾名思义,像尺子一样取一段,尺取法通常是对数组保存一对下标,即所选取的区间的左右端点,然后根据实际情况不断地推进区间左右端点以得出答案。
例子1:
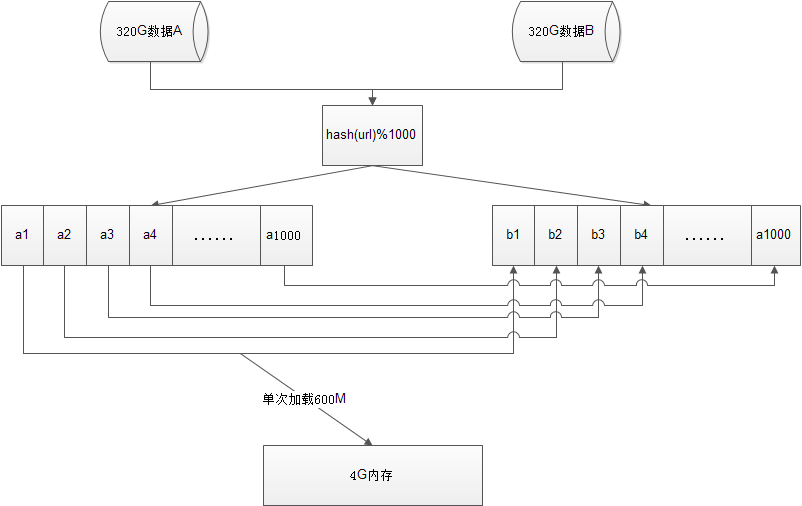
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,让你找出a、b文件共同的url?
腾讯面试题:A.txt和B.txt两个文件,A有1亿个qq号,B有100万个,用代码实现交、并、差...
1.思路
可以估计每个文件安的大小为5G×64=320G,远远大于内存限制的4G。所以不可能将其完全加载到内存中处理。考虑采取分而治之的方法。
- 遍历文件a,对每个url求取hash(url)%1000,然后根据所取得的值将url分别存储到1000个小文件(记为a0,a1,...,a999)中。这样每个小文件的大约为300M。
- 遍历文件b,采取和a相同的方式将url分别存储到1000小文件(记为b0,b1,...,b999)。这样处理后,所有可能相同的url都在对应的小文件(a0vsb0,a1vsb1,...,a999vsb999)中,不对应的小文件不可能有相同的url。然后我们只要求出1000对小文件中相同的url即可。
- 求每对小文件中相同的url时,可以把其中一个小文件的url存储到hash_set中。然后遍历另一个小文件的每个url,看其是否在刚才构建的hash_set中,如果是,那么就是共同的url,存到文件里面就可以了
2.代码实现
参考自两个上亿行的大文件取交集
TODO:Java实现版本还未写
PS:如果允许小误差,也可以采用如下的布隆算法实现
import java.util.ArrayList;
import java.util.BitSet;
import java.util.List; /**
* BloomFilter算法
*
* @author JYC506
*
*/
public class BloomFilter {
/*哈希函数*/
private List<IHashFunction> hashFuctionList;
/*构造方法*/
public BloomFilter() {
this.hashFuctionList = new ArrayList<IHashFunction>();
}
/*添加哈希函数类*/
public void addHashFunction(IHashFunction hashFunction) {
this.hashFuctionList.add(hashFunction);
}
/*删除hash函数*/
public void removeHashFunction(IHashFunction hashFunction) {
this.hashFuctionList.remove(hashFunction);
}
/*判断是否被包含*/
public boolean contain(BitSet bitSet, String str) {
for (IHashFunction hash : hashFuctionList) {
int hashCode = hash.toHashCode(str);
if(hashCode<0){
hashCode=-hashCode;
}
if (bitSet.get(hashCode) == false) {
return false;
}
}
return true;
}
/*添加到bitSet*/
public void toBitSet(BitSet bitSet, String str) {
for (IHashFunction hash : hashFuctionList) {
int hashCode = hash.toHashCode(str);
if(hashCode<0){
hashCode=-hashCode;
}
bitSet.set(hashCode, true);
}
} public static void main(String[] args) {
BloomFilter bloomFilter=new BloomFilter();
/*添加3个哈希函数*/
bloomFilter.addHashFunction(new JavaHash());
bloomFilter.addHashFunction(new RSHash());
bloomFilter.addHashFunction(new SDBMHash());
/*长度为2的24次方*/
BitSet bitSet=new BitSet(1<<25);
/*判断test1很test2重复的字符串*/
String[] test1=new String[]{"哈哈","我","大家","逗比","有钱人性","小米","Iphone","helloWorld"};
for (String str1 : test1) {
bloomFilter.toBitSet(bitSet, str1);
}
String[] test2=new String[]{"哈哈","我的","大家","逗比","有钱的人性","小米","Iphone6s","helloWorld"};
for (String str2 : test2) {
if(bloomFilter.contain(bitSet, str2)){
System.out.println("'"+str2+"'是重复的");
}
} }
}
/*哈希函数接口*/
interface IHashFunction {
int toHashCode(String str);
} class JavaHash implements IHashFunction { @Override
public int toHashCode(String str) {
return str.hashCode();
} } class RSHash implements IHashFunction { @Override
public int toHashCode(String str) {
int b = 378551;
int a = 63689;
int hash = 0;
for (int i = 0; i < str.length(); i++) {
hash = hash * a + str.charAt(i);
a = a * b;
}
return hash;
} } class SDBMHash implements IHashFunction { @Override
public int toHashCode(String str) {
int hash = 0;
for (int i = 0; i < str.length(); i++)
hash = str.charAt(i) + (hash << 6) + (hash << 16) - hash;
return hash;
} }
例子2:
现有海量日志数据保存在一个超级大的文件中,该文件无法直接读入内存,要求从中提取某天出访问百度次数最多的那个IP。
- 从这一天的日志数据中把访问百度的IP取出来,逐个写入到一个大文件中;
- 注意到IP是32位的,最多有2^32个IP。同样可以采用映射的方法,比如模1000,把整个大文件映射为1000个小文件;
- 找出每个小文中出现频率最大的IP(可以采用hash_map进行频率统计,然后再找出频率最大的几个)及相应的频率;
- 在这1000个最大的IP中,找出那个频率最大的IP,即为所求。
四、总结
- 简单点说,hash就是将任意长度的消息压缩成某一固定长度的消息摘要的函数。
- 可能会存在不同的key对应相同的Hash值,这就是存在碰撞的可能。
- Hash算法是不可逆的,即不同通过Hash值逆向推出key的值。
处理海量数据问题思路:
- 分而治之/hash映射 + hash统计 + 堆/快速/归并排序;
- 双层桶划分
- Bloom filter/Bitmap;
- Trie树/数据库/倒排索引;
- 外排序;
- 分布式处理之Hadoop/Mapreduce。
我的微信公众号:架构真经(id:gentoo666),分享Java干货,高并发编程,热门技术教程,微服务及分布式技术,架构设计,区块链技术,人工智能,大数据,Java面试题,以及前沿热门资讯等。每日更新哦!

参考资料:
- https://blog.csdn.net/u014209205/article/details/80820263
- https://blog.csdn.net/qq_38891827/article/details/80723483
- https://www.cnblogs.com/wkfvawl/p/9016281.html
- https://blog.csdn.net/consciousman/article/details/52348439
- https://bbs.csdn.net/topics/370253735
- https://www.cnblogs.com/aspirant/p/7154551.html
- https://www.bbsmax.com/A/n2d9OwP4JD
- https://www.2cto.com/kf/201701/586765.html
- https://blog.csdn.net/weixin_33737774/article/details/85891625
- https://blog.csdn.net/qingdujun/article/details/82343756
- https://blog.csdn.net/u012173884/article/details/47419163
- https://blog.csdn.net/samjustin1/article/details/52251180
程序员的算法课(14)-Hash算法-对海量url判重的更多相关文章
- murmurhash2算法 和 DJB Hash算法是目前最流行的hash算法
murmurhash2算法 和 DJB Hash算法是目前最流行的hash算法 1.DJB HASH算法 1 2 3 4 5 6 7 8 9 10 11 /* the famous DJB Hash ...
- 11.redis cluster的hash slot算法和一致性 hash 算法、普通hash算法的介绍
分布式寻址算法 hash 算法(大量缓存重建) 一致性 hash 算法(自动缓存迁移)+ 虚拟节点(自动负载均衡) redis cluster 的 hash slot 算法 一.hash 算法 来了一 ...
- 程序员代码面试指南 IT名企算法与数据结构题目最优解
原文链接 这是一本程序员面试宝典!书中对IT名企代码面试各类题目的最优解进行了总结,并提供了相关代码实现.针对当前程序员面试缺乏权威题目汇总这一痛点,本书选取将近200道真实出现过的经典代码面试题,帮 ...
- 【数据结构与算法】一致性Hash算法及Java实践
追求极致才能突破极限 一.案例背景 1.1 系统简介 首先看一下系统架构,方便解释: 页面给用户展示的功能就是,可以查看任何一台机器的某些属性(以下简称系统信息). 消息流程是,页面发起请求查看指定机 ...
- Hash算法和一致性Hash算法
Hash算法 我们对同一个图片名称做相同的哈希计算时,得出的结果应该是不变的,如果我们有3台服务器,使用哈希后的结果对3求余,那么余数一定是0.1或者2,正好与我们之前的服务器编号相同,如果求余的结果 ...
- 【算法】一致性Hash算法
一.分布式算法 在做服务器负载均衡时候可供选择的负载均衡的算法有很多,包括: 轮循算法(Round Robin).哈希算法(HASH).最少连接算法(Least Connection).响应速度算法( ...
- 程序员编程艺术:面试和算法心得-(转 July)
1.1 旋转字符串 题目描述 给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符'a'和'b'移动到字符串的尾部,使得原字符串变成字符串“cdef ...
- 程序员的进阶课-架构师之路(14)-B+树、B*树
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
- 程序员的进阶课-架构师之路(13)-B-树
版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https://blog.csdn.net/m0_37609579/article/de ...
随机推荐
- spring boot项目启动报错
在eclipse中运行没有任何问题,项目挪到idea之后就报错 Unable to start EmbeddedWebApplicationContext due to miss EmbeddedSe ...
- Flex 和 Bison 使用方法
背景知识 在学编译原理的时候,同时在做南京大学的编译原理课程实验,这里是链接,整个实验的效果是实现一个完整的 C-- 语法的编译器.C-- 语法是他们老师指定的一种类 C 语言. Flex 和 Bis ...
- Python开发【第十三篇】高阶函数、递归函数、闭包
函数式编程是指用一系列函数解决问题 好处:用每个函数完成每个细小的功能,一系列函数任意组合能够解决大问题 函数仅仅接收输入并产生输出,不包含任何能影响输出的内部状态 函数之间的可重入性 当一个函数的输 ...
- unittest加载测试用例名称必须以test开头,是否可以定制化
前几天,在一个群里,一个人问了,这样一个问题.说他面试遇到一个面试官,问他,为啥unittest的测试用例要用test 开头,能不能定制化.他不知道为啥. 看到这个题目,我回答当然可以了,可以用l ...
- dubbo监控安装
tar xf dubbo-monitor-simple-2.8.4-assembly.tar.gz cd dubbo-monitor-simple-2.8.4 vi conf/dubbo.proper ...
- linux No module named yum错误的解决办法
linux No module named yum错误的解决办法 肯定是yum的版本与当前python的版本不一致造成的 <pre>所以修改yum的配置,修改文件: vim /usr/bi ...
- 【algo&ds】2.线性表
1.线性表 线性表(英语:Linear List)是由n(n≥0)个数据元素(结点)a[0],a[1],a[2]-,a[n-1]组成的有限序列. 其中: 数据元素的个数n定义为表的长度 = " ...
- 插入排序的代码实现(C语言)
void insert_sort(int arr[], int len) { for (int i = 1; i < len; ++i) { if (arr[i] < arr[i - 1] ...
- Salesforce学习之路(十)Org的命名空间
1. 命名空间的适用场景 每个组件都是命名空间的一部分,如果Org中设置了命名空间前缀,那么需使用该命名空间访问组件.否则,使用默认命名空间访问组件,系统默认的命名空间为“c”. 如果Org没有创建命 ...
- flex一些属性
// 改变主轴的方向 flex-direction: column; // display:flex的子元素无法设置宽度 // 子元素有个flex-shrink属性,表示在父元素宽度不够的情况下是否自 ...