利用procedure批量插入数据
正文
要求在页面查询到5000条数据,为了方便插入,准备用shell脚本写curl命令调用自己写的代码接口,但是速度慢,而且写的时候遇到点儿小问题,故用sql语句写了这个功能
由于operationlog表中的ts字段为13位的时间戳,所以采用了截取的方式。
DROP TABLE IF EXISTS `operationlog`;
CREATE TABLE `operationlog` (
`sn` int(11) NOT NULL AUTO_INCREMENT,
`opl` varchar(8) NOT NULL,
`src` varchar(32) NOT NULL,
`pid` varchar(32) DEFAULT NULL,
`ts` varchar(13) NOT NULL,
PRIMARY KEY (`sn`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
drop procedure if exists batchAdd;
/*count1 循环次数 opl和src为operationlog的列*/
create procedure batchAdd(in count1 int,in opl varchar(32),in src varchar(32))
begin
declare a int;
set a=0;
while a<count1 do
begin
/*延时1s*/
select sleep(1);
/*获取时间戳1523285555.207000,后面3位是0,现在的需求是ts为13位,即带ms的*/
select @time1:=unix_timestamp(now(3));
/*将1523285555.207000的.去掉*/
select @time1:=replace(@time1, '.', '');
/*取1523285555207000左边13位*/
select @time1:=left(@time1, 13);
/*生成sql,进行insert*/
insert into operationlog(opl, src, pid, ts) values(opl, src, '1111', @time1);
/*a加1*/
set a = a + 1;
end;
end while;
end;
--查看procedure
show procedure status;
--调用该procedure
call batchAdd(10, 'INFO', 'AJG');
--删除procedure
drop procedure batchAdd;
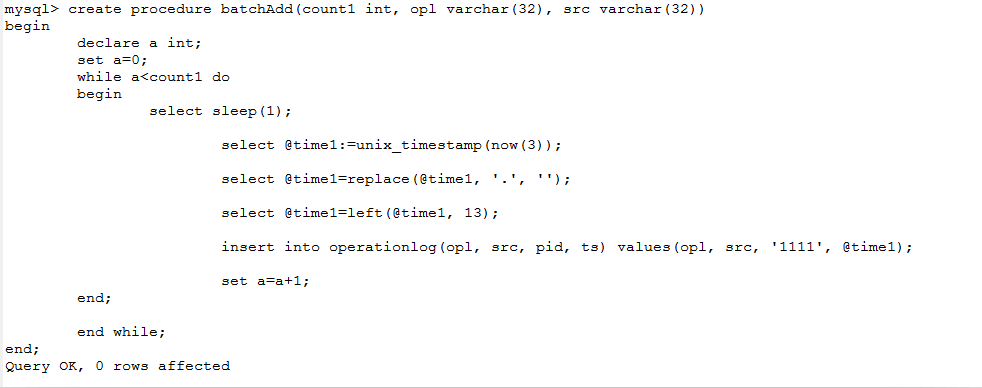
create procedure batchAdd如图所示:
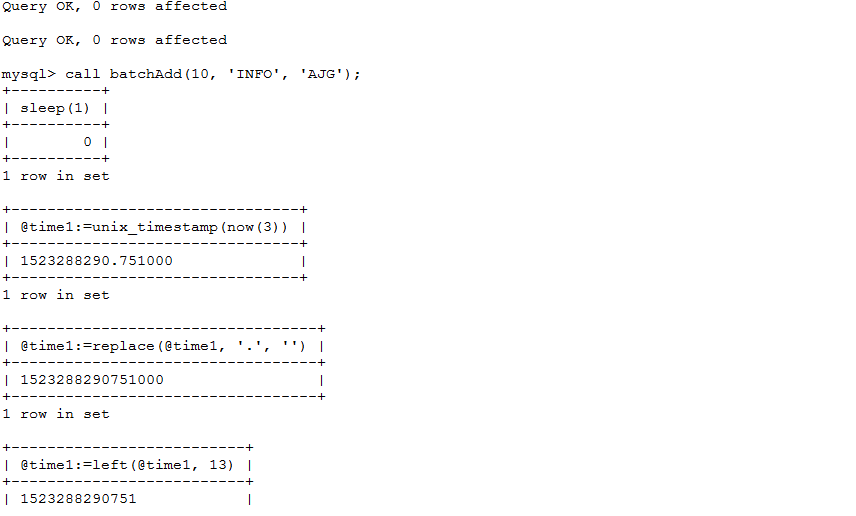
创建好procedure后,可以通过call batchAdd(10, 'INFO', 'AJG');来调用,如下图所示:
本公众号免费提供csdn下载服务,海量IT学习资源,如果你准备入IT坑,励志成为优秀的程序猿,那么这些资源很适合你,包括但不限于java、go、python、springcloud、elk、嵌入式 、大数据、面试资料、前端 等资源。同时我们组建了一个技术交流群,里面有很多大佬,会不定时分享技术文章,如果你想来一起学习提高,可以公众号后台回复【2】,免费邀请加技术交流群互相学习提高,会不定期分享编程IT相关资源。
扫码关注,精彩内容第一时间推给你

利用procedure批量插入数据的更多相关文章
- 利用pipeline批量插入数据到redis
在推荐系统中,推荐候选集格式一般是,itemid itemid_list.要把itemid作为key,推荐列表作为value批量插入到redis. 比如文件cf.data为: cf_763500210 ...
- mysql利用存储过程批量插入数据
最近需要测试一下mysql单表数据达到1000W条以上时增删改查的性能.由于没有现成的数据,因此自己构造,本文只是实例,以及简单的介绍. 首先当然是建表: [sql]view plaincopy CR ...
- sqlalchemy ORM进阶- 批量插入数据
参考: https://www.jb51.net/article/49789.htm https://blog.csdn.net/littlely_ll/article/details/8270687 ...
- django基础之day08,利用bulk_create 批量插入成千上万条数据
bulk_create批量插入数据 models.py文件 class Book(models.Model): title=models.CharField(max_length=32) urls.p ...
- SQLServer 批量插入数据的两种方法
SQLServer 批量插入数据的两种方法-发布:dxy 字体:[增加 减小] 类型:转载 在SQL Server 中插入一条数据使用Insert语句,但是如果想要批量插入一堆数据的话,循环使用Ins ...
- mysql应用存储过程批量插入数据
--批量插入数据的sql语句 delimiter $$ DROP PROCEDURE IF EXISTS `test.sp_insert_batch` $$ CREATE DEFINER =`root ...
- C# 批量插入表SQLSERVER SqlBulkCopy往数据库中批量插入数据
#region 帮助实例:SQL 批量插入数据 多种方法 /// <summary> /// SqlBulkCopy往数据库中批量插入数据 /// </summary> /// ...
- MySQL高级知识(十)——批量插入数据脚本
前言:使用脚本进行大数据量的批量插入,对特定情况下测试数据集的建立非常有用. 0.准备 #1.创建tb_dept_bigdata(部门表). create table tb_dept_bigdata( ...
- 练习六 向表A批量插入数据
create or replace procedure BATCH_INSERT_A (insertNo in integer) is n_id integer; /***************** ...
随机推荐
- 060 Python必备库-从数据处理到人工智能
目录 一.概述 1.1 从数据处理到人工智能 二.Python库之数据分析 2.1 numpy 2.2 pandas 2.3 scipy 三.Python库之数据可视化 3.1 matplotlib ...
- 小白学习VUE第一篇文章---如何看懂网上搜索到的VUE代码或文章---使用VUE的三种模式:
小白学习VUE第一篇文章---如何看懂网上搜索到的VUE代码或文章---使用VUE的三种模式: 直接引用VUE; 将vue.js下载到本地后本目录下使用; 安装Node环境下使用; ant-desig ...
- HTTPS加密协议
使用JDK自带的keytool工具生成一个证书(keystore文件),其中包含了密钥. a.在命令行输入以下命令:keytool -genkey -alias tbb -keyalg RSA -ke ...
- FreeSql (二十六)贪婪加载 Include、IncludeMany、Dto、ToList
贪婪加载顾名思议就是把所有要加载的东西一次性读取. 本节内容为了配合[延时加载]而诞生,贪婪加载和他本该在一起介绍,开发项目的过程中应该双管齐下,才能写出高质量的程序. Dto 映射查询 Select ...
- jstat虚拟机统计信息监视工具
jstsat(JVM Statistics Monitoring Tool) jstat用于监视虚拟机各种运行状态信息的命令工具.可以显示本地或者远程虚拟机进程中的类装载.内存.垃圾收集.JIT编译等 ...
- SpringBoot 2.0 + Nacos + Sentinel 流控规则集中存储
前言 Sentinel 原生版本的规则管理通过API 将规则推送至客户端并直接更新到内存中,并不能直接用于生产环境.不过官方也提供了一种 Push模式,扩展读数据源ReadableDataSource ...
- 疑难杂症----Windows10
现在大多数个人电脑所用的操作系统都是win10,而我们使用win10时总是会碰上各种各样的问题,所以专门写一篇博客来记录我碰上的各种问题,便于以后更快的解决问题. 一.小娜搜索不到应用问题解决方案 小 ...
- ES6中的迭代器、Generator函数以及Generator函数的异步操作
最近在写RN相关的东西,其中涉及到了redux-saga ,saga的实现原理就是ES6中的Generator函数,而Generator函数又和迭代器有着密不可分的关系.所以本篇博客先学习总结了ite ...
- new的执行过程
- VMbox 安装 LInux系统流程
STEP 1 文件--新建---(自定义高级)---(默认设置)---(稍后安装系统)---(Linux+选择版本)---(虚拟机名字+存放位置)---(处理器2+核数2)---(虚拟机内存)2G一般 ...