7. SOFAJRaft源码分析—如何实现一个轻量级的对象池?
前言
我在看SOFAJRaft的源码的时候看到了使用了对象池的技术,看了一下感觉要吃透的话还是要新开一篇文章来讲,内容也比较充实,大家也可以学到之后运用到实际的项目中去。
这里我使用RecyclableByteBufferList来作为讲解的例子:
RecyclableByteBufferList
public final class RecyclableByteBufferList extends ArrayList<ByteBuffer> implements Recyclable {
private transient final Recyclers.Handle handle;
private static final Recyclers<RecyclableByteBufferList> recyclers = new Recyclers<RecyclableByteBufferList>(512) {
@Override
protected RecyclableByteBufferList newObject(final Handle handle) {
return new RecyclableByteBufferList(
handle);
}
};
//获取一个RecyclableByteBufferList实例
public static RecyclableByteBufferList newInstance(final int minCapacity) {
final RecyclableByteBufferList ret = recyclers.get();
//容量不够的话,进行扩容
ret.ensureCapacity(minCapacity);
return ret;
}
//回收RecyclableByteBufferList对象
@Override
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}
}
我在上面将RecyclableByteBufferList获取对象的方法和回收对象的方法给列举出来了,获取实例的时候会通过recyclers的get方法去获取,回收对象的时候会去调用list的clear方法清空list里面的内容之后再去调用recyclers的recycle方法进行回收。
如果recyclers里面没有对象可以获取,那么会调用newObject方法创建一个对象,然后将handle对象传入构造器中进行实例化。
对象池Recyclers
数据结构
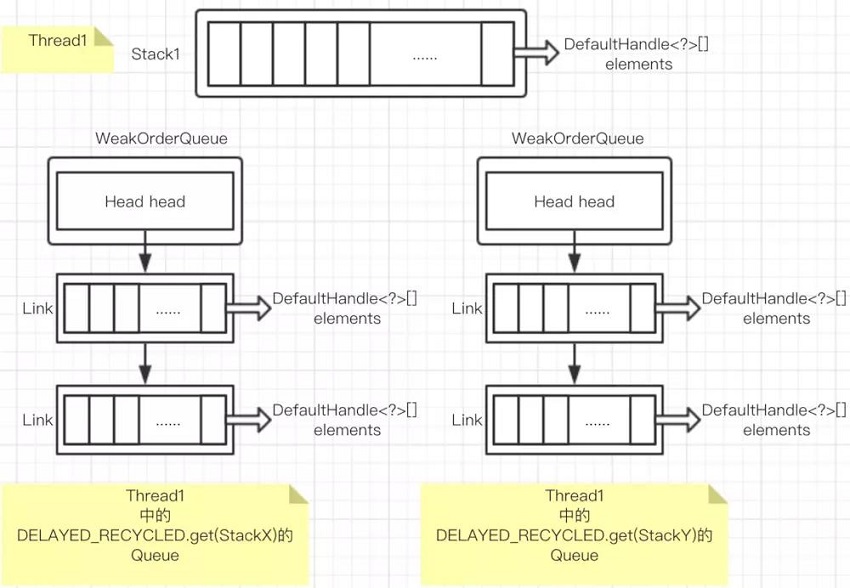
- 每一个 Recyclers 对象包含一个
ThreadLocal<Stack<T>> threadLocal实例;
每一个线程包含一个 Stack 对象,该 Stack 对象包含一个 DefaultHandle[],而 DefaultHandle 中有一个属性 T value,用于存储真实对象。也就是说,每一个被回收的对象都会被包装成一个 DefaultHandle 对象 - 每一个 Recyclers 对象包含一个
ThreadLocal<Map<Stack<?>, WeakOrderQueue>> delayedRecycled实例;
每一个线程对象包含一个 Map<Stack<?>, WeakOrderQueue>,存储着为其他线程创建的 WeakOrderQueue 对象,WeakOrderQueue 对象中存储一个以 Head 为首的 Link 数组,每个 Link 对象中存储一个 DefaultHandle[] 数组,用于存放回收对象。

假设线程A创建的对象
- 线程A回收RecyclableByteBufferList时,直接将RecyclableByteBufferList的DefaultHandle 对象压入 Stack 的 DefaultHandle[] 中;
- 线程B回收RecyclableByteBufferList时,会首先从其 Map<Stack<?>, WeakOrderQueue> 对象中获取 key=线程A的Stack 对象的 WeakOrderQueue,然后直接将RecyclableByteBufferList的DefaultHandle 对象(内部包含RecyclableByteBufferList对象)压入该 WeakOrderQueue 中的 Link 链表中的尾部 Link 的 DefaultHandle[]中,同时,这个 WeakOrderQueue 会与线程 A 的 Stack 中的 head 属性进行关联,用于后续对象的 pop 操作;
- 当线程 A 从对象池获取对象时,如果线程 A 的 Stack 中有对象,则直接弹出;如果没有对象,则先从其 head 属性所指向的 WeakorderQueue 开始遍历 queue 链表,将 RecyclableByteBufferList 对象从其他线程的 WeakOrderQueue 中转移到线程 A 的 Stack 中(一次 pop 操作只转移一个包含了元素的 Link),再弹出。
Recyclers静态代码块
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 4 * 1024; // Use 4k instances as default.
private static final int DEFAULT_MAX_CAPACITY_PER_THREAD;
private static final int INITIAL_CAPACITY;
static {
// 每个线程的最大对象池容量
int maxCapacityPerThread = SystemPropertyUtil.getInt("jraft.recyclers.maxCapacityPerThread", DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD);
if (maxCapacityPerThread < 0) {
maxCapacityPerThread = DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD;
}
DEFAULT_MAX_CAPACITY_PER_THREAD = maxCapacityPerThread;
if (LOG.isDebugEnabled()) {
if (DEFAULT_MAX_CAPACITY_PER_THREAD == 0) {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: disabled");
} else {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: {}", DEFAULT_MAX_CAPACITY_PER_THREAD);
}
}
// 设置初始化容量信息
INITIAL_CAPACITY = Math.min(DEFAULT_MAX_CAPACITY_PER_THREAD, 256);
}
public static final Handle NOOP_HANDLE = new Handle() {};
Recyclers会在静态代码块中做一些对象池容量初始化的工作,初始化了最大对象池容量和初始化容量信息。
从对象池中获取对象
Recyclers#get
// 线程变量,保存每个线程的对象池信息,通过 ThreadLocal 的使用,避免了不同线程之间的竞争情况
private final ThreadLocal<Stack<T>> threadLocal = new ThreadLocal<Stack<T>>() {
@Override
protected Stack<T> initialValue() {
return new Stack<>(Recyclers.this, Thread.currentThread(), maxCapacityPerThread);
}
};
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject(NOOP_HANDLE);
}
//从threadLocal中获取一个栈对象
Stack<T> stack = threadLocal.get();
//拿出栈顶元素
DefaultHandle handle = stack.pop();
//如果栈里面没有元素,那么就实例化一个
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}
Get方法会从threadLocal中去获取数据,如果获取不到,那么会初始化一个Stack,并传入当前Recyclers实例,当前线程,与最大容量。然后从stack中pop拿出栈顶元素,如果获取的元素为空,那么直接调用newHandle新建一个DefaultHandle实例,并调用Recyclers实现类的newObject获取实现类的实例。也就是说DefaultHandle是用来封装真正的对象的实例。
从stack中申请一个对象
Stack(Recyclers<T> parent, Thread thread, int maxCapacity) {
this.parent = parent;
this.thread = thread;
this.maxCapacity = maxCapacity;
elements = new DefaultHandle[Math.min(INITIAL_CAPACITY, maxCapacity)];
}
DefaultHandle pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
//size表示整个stack中的大小
size--;
//获取最后一个元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判断是否重复回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
获取对象的逻辑也比较简单,当 Stack 中的 DefaultHandle[] 的 size 为 0 时,需要从其他线程的 WeakOrderQueue 中转移数据到 Stack 中的 DefaultHandle[],即 scavenge方法,该方法下面再聊。当 Stack 中的 DefaultHandle[] 中最终有了数据时,直接获取最后一个元素
对象池回收对象
我们再来看看RecyclableByteBufferList是怎么回收对象的。
RecyclableByteBufferList#recycle
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}
RecyclableByteBufferList回收对象的时候首先会调用clear方法清空属性,然后调用recyclers的recycle方法进行对象回收。
Recyclers#recycle
public final boolean recycle(T o, Handle handle) {
if (handle == NOOP_HANDLE) {
return false;
}
DefaultHandle h = (DefaultHandle) handle;
//stack在实例化的时候会在构造器中传入一个Recyclers作为parent
//所以这里是校验一下,如果不是当前线程的, 直接不回收了
if (h.stack.parent != this) {
return false;
}
if (o != h.value) {
throw new IllegalArgumentException("o does not belong to handle");
}
h.recycle();
return true;
}
这里会接着调用DefaultHandle的recycle方法进行回收
DefaultHandle
static final class DefaultHandle implements Handle {
//在WeakOrderQueue的add方法中会设置成ID
//在push方法中设置成为OWN_THREAD_ID
//在pop方法中设置为0
private int lastRecycledId;
//只有在push方法中才会设置OWN_THREAD_ID
//在pop方法中设置为0
private int recycleId;
//当前的DefaultHandle对象所属的Stack
private Stack<?> stack;
private Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
public void recycle() {
Thread thread = Thread.currentThread();
//如果当前线程正好等于stack所对应的线程,那么直接push进去
if (thread == stack.thread) {
stack.push(this);
return;
}
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
// 如果不是当前线程,则需要延迟回收,获取当前线程存储的延迟回收WeakHashMap
Map<Stack<?>, WeakOrderQueue> delayedRecycled = Recyclers.delayedRecycled.get();
// 当前 handler 所在的 stack 是否已经在延迟回收的任务队列中
// 并且 WeakOrderQueue是一个多线程间可以共享的Queue
WeakOrderQueue queue = delayedRecycled.get(stack);
if (queue == null) {
delayedRecycled.put(stack, queue = new WeakOrderQueue(stack, thread));
}
queue.add(this);
}
}
DefaultHandle在实例化的时候会传入一个stack实例,代表当前实例是属于这个stack的。
所以在调用recycle方法的时候,会判断一下,当前的线程是不是stack所属的线程,如果是那么直接push到stack里面就好了,不是则调用延迟队列delayedRecycled;
从delayedRecycled队列中获取Map<Stack<?>, WeakOrderQueue> delayedRecycled ,根据stack作为key来获取WeakOrderQueue,然后将当前的DefaultHandle实例放入到WeakOrderQueue中。
同线程回收对象
Stack#push
void push(DefaultHandle item) {
// (item.recycleId | item.lastRecycleId) != 0 等价于 item.recycleId!=0 && item.lastRecycleId!=0
// 当item开始创建时item.recycleId==0 && item.lastRecycleId==0
// 当item被recycle时,item.recycleId==x,item.lastRecycleId==y 进行赋值
// 当item被pop之后, item.recycleId = item.lastRecycleId = 0
// 所以当item.recycleId 和 item.lastRecycleId 任何一个不为0,则表示回收过
if ((item.recycleId | item.lastRecycledId) != 0) {
throw new IllegalStateException("recycled already");
}
// 设置对象的回收id为线程id信息,标记自己的被回收的线程信息
item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
int size = this.size;
if (size >= maxCapacity) {
// Hit the maximum capacity - drop the possibly youngest object.
return;
}
// stack中的elements扩容两倍,复制元素,将新数组赋值给stack.elements
if (size == elements.length) {
elements = Arrays.copyOf(elements, Math.min(size << 1, maxCapacity));
}
elements[size] = item;
this.size = size + 1;
}
同线程回收对象 DefaultHandle#recycle 步骤:
- stack 先检测当前的线程是否是创建 stack 的线程,如果不是,则走异线程回收逻辑;如果是,则首先判断是否重复回收,然后判断 stack 的 DefaultHandle[] 中的元素个数是否已经超过最大容量(4k),如果是,直接返回;
- 判断当前的 DefaultHandle[] 是否还有空位,如果没有,以 maxCapacity 为最大边界扩容 2 倍,之后拷贝旧数组的元素到新数组,然后将当前的 DefaultHandle 对象放置到 DefaultHandle[] 中
- 最后重置 stack.size 属性
异线程回收对象
WeakOrderQueue
static final class Stack<T> {
//使用volatile可以立即读取到该queue
private volatile WeakOrderQueue head;
}
WeakOrderQueue(Stack<?> stack, Thread thread) {
head = tail = new Link();
//使用的是WeakReference ,作用是在poll的时候,如果owner不存在了
// 则需要将该线程所包含的WeakOrderQueue的元素释放,然后从链表中删除该Queue。
owner = new WeakReference<>(thread);
//假设线程B和线程C同时回收线程A的对象时,有可能会同时创建一个WeakOrderQueue,就坑同时设置head,所以这里需要加锁
synchronized (stackLock(stack)) {
next = stack.head;
stack.head = this;
}
}
创建WeakOrderQueue对象的时候会初始化一个WeakReference的owner,作用是在poll的时候,如果owner不存在了, 则需要将该线程所包含的WeakOrderQueue的元素释放,然后从链表中删除该Queue。
然后给stack加锁,假设线程B和线程C同时回收线程A的对象时,有可能会同时创建一个WeakOrderQueue,就坑同时设置head,所以这里需要加锁。
以head==null的时候为例
加锁:
线程B先执行,则head = 线程B的queue;之后线程C执行,此时将当前的head也就是线程B的queue作为线程C的queue的next,组成链表,之后设置head为线程C的queue
不加锁:
线程B先执行 next = stack.head此时线程B的queue.next=null->线程C执行next = stack.head;线程C的queue.next=null-> 线程B执行stack.head = this;设置head为线程B的queue -> 线程C执行stack.head = this;设置head为线程C的queue,此时线程B和线程C的queue没有连起来。
WeakOrderQueue#add
void add(DefaultHandle handle) {
// 设置handler的最近一次回收的id信息,标记此时暂存的handler是被谁回收的
handle.lastRecycledId = id;
Link tail = this.tail;
int writeIndex;
// 判断一个Link对象是否已经满了:
// 如果没满,直接添加;
// 如果已经满了,创建一个新的Link对象,之后重组Link链表,然后添加元素的末尾的Link(除了这个Link,前边的Link全部已经满了)
if ((writeIndex = tail.get()) == LINK_CAPACITY) {
this.tail = tail = tail.next = new Link();
writeIndex = tail.get();
}
tail.elements[writeIndex] = handle;
// 如果使用者在将DefaultHandle对象压入队列后,将Stack设置为null
// 但是此处的DefaultHandle是持有stack的强引用的,则Stack对象无法回收;
//而且由于此处DefaultHandle是持有stack的强引用,WeakHashMap中对应stack的WeakOrderQueue也无法被回收掉了,导致内存泄漏
handle.stack = null;
// we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread;
// this also means we guarantee visibility of an element in the queue if we see the index updated
// tail本身继承于AtomicInteger,所以此处直接对tail进行+1操作
tail.lazySet(writeIndex + 1);
}
Stack异线程push对象流程:
- 首先获取当前线程的 Map<Stack<?>, WeakOrderQueue> 对象,如果没有就创建一个空 map;
- 然后从 map 对象中获取 key 为当前的 Stack 对象的 WeakOrderQueue;
- 如果获取的WeakOrderQueue对象为null,那么创建一个WeakOrderQueue对象,并将对象放入到map中,最后调用WeakOrderQueue#add添加对象
WeakOrderQueue 的创建流程:
- 创建一个Link对象,将head和tail的引用都设置为此对象
- 创建一个WeakReference指向owner对象,设置当前的 WeakOrderQueue 所属的线程为当前线程。
- 先将原本的 stack.head 赋值给刚刚创建的 WeakOrderQueue 的 next 节点,之后将刚刚创建的 WeakOrderQueue 设置为 stack.head(这一步非常重要:假设线程 A 创建对象,此处是线程 C 回收对象,则线程 C 先获取其 Map<Stack<?>, WeakOrderQueue> 对象中 key=线程A的stack对象的 WeakOrderQueue,然后将该 Queue 赋值给线程 A 的 stack.head,后续的 pop 操作打基础),形成 WeakOrderQueue 的链表结构。
WeakOrderQueue#add添加对象流程
- 首先设置 item.lastRecycledId = 当前 WeakOrderQueue 的 id
- 然后看当前的 WeakOrderQueue 中的 Link 节点链表中的尾部 Link 节点的 DefaultHandle[] 中的元素个数是否已经达到 LINK_CAPACITY(16)
- 如果不是,则直接将当前的 DefaultHandle 元素插入尾部 Link 节点的 DefaultHandle[] 中,之后置空当前的 DefaultHandle 元素的 stack 属性,最后记录当前的 DefaultHandle[] 中的元素数量;
- 如果是,则新建一个 Link,并且放在当前的 Link 链表中的尾部节点处,与之前的 tail 节点连起来(链表),之后进行第三步的操作。
从异线程获取对象
我再把pop方法搬下来一次:
DefaultHandle pop() {
int size = this.size;
// size=0 则说明本线程的Stack没有可用的对象,先从其它线程中获取。
if (size == 0) {
// 当 Stack<T> 此时的容量为 0 时,去 WeakOrder 中转移部分对象到 Stack 中
if (!scavenge()) {
return null;
}
//由于在transfer(Stack<?> dst)的过程中,可能会将其他线程的WeakOrderQueue中的DefaultHandle对象传递到当前的Stack,
//所以size发生了变化,需要重新赋值
size = this.size;
}
//size表示整个stack中的大小
size--;
//获取最后一个元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判断是否重复回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}
- 首先获取当前的 Stack 中的 DefaultHandle 对象中的元素个数。
- 如果为 0,则从其他线程的与当前的 Stack 对象关联的 WeakOrderQueue 中获取元素,并转移到 Stack 的 DefaultHandle[] 中(每一次 pop 只转移一个有元素的 Link),如果转移不成功,说明没有元素可用,直接返回 null;
- 如果转移成功,则重置 size属性 = 转移后的 Stack 的 DefaultHandle[] 的 size,之后直接获取 Stack 对象中 DefaultHandle[] 的最后一位元素,之后做防护性检测,最后重置当前的 stack 对象的 size 属性以及获取到的 DefaultHandle 对象的 recycledId 和 lastRecycledId 回收标记,返回 DefaultHandle 对象。
scavenge转移
Stack#scavenge
boolean scavenge() {
// continue an existing scavenge, if any
// 扫描判断是否存在可转移的 Handler
if (scavengeSome()) {
return true;
}
// reset our scavenge cursor
prev = null;
cursor = head;
return false;
}
调用scavengeSome扫描判断是否存在可转移的 Handler,如果没有,那么就返回false,表示没有可用对象
Stack#scavengeSome
boolean scavengeSome() {
WeakOrderQueue cursor = this.cursor;
if (cursor == null) {
cursor = head;
// 如果head==null,表示当前的Stack对象没有WeakOrderQueue,直接返回
if (cursor == null) {
return false;
}
}
boolean success = false;
WeakOrderQueue prev = this.prev;
do {
// 从当前的WeakOrderQueue节点进行 handler 的转移
if (cursor.transfer(this)) {
success = true;
break;
}
// 遍历下一个WeakOrderQueue
WeakOrderQueue next = cursor.next;
// 如果 WeakOrderQueue 的实际持有线程因GC回收了
if (cursor.owner.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
// 如果当前的WeakOrderQueue的线程已经不可达了
//如果该WeakOrderQueue中有数据,则将其中的数据全部转移到当前Stack中
if (cursor.hasFinalData()) {
for (;;) {
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
//将当前的WeakOrderQueue的前一个节点prev指向当前的WeakOrderQueue的下一个节点,
// 即将当前的WeakOrderQueue从Queue链表中移除。方便后续GC
if (prev != null) {
prev.next = next;
}
} else {
prev = cursor;
}
cursor = next;
} while (cursor != null && !success);
this.prev = prev;
this.cursor = cursor;
return success;
}
- 首先设置当前操作的 WeakOrderQueue cursor,如果为 null,则赋值为 stack.head 节点,如果 stack.head 为 null,则表明外部线程没有回收过当前线程创建的 对象,外部线程在回收对象的时候会创建一个WeakOrderQueue,并将stack.head 指向新创建的WeakOrderQueue对象,则直接返回 false;如果不为 null,则继续向下执行;
- 首先对当前的 cursor 进行元素的转移,如果转移成功,则跳出循环,设置 prev 和 cursor 属性;
- 如果转移不成功,获取下一个线程 Y 中的与当前线程的 Stack 对象关联的 WeakOrderQueue,如果该 queue 所属的线程 Y 还可达,则直接设置 cursor 为该 queue,进行下一轮循环;如果该 queue 所属的线程 Y 不可达了,则判断其内是否还有元素,如果有,全部转移到当前线程的 Stack 中,之后将线程 Y 的 queue 从查询 queue 链表中移除。
transfer转移
boolean transfer(Stack<?> dst) {
//寻找第一个Link
Link head = this.head;
// head == null,没有存储数据的节点,直接返回
if (head == null) {
return false;
}
// 读指针的位置已经到达了每个 Node 的存储容量,如果还有下一个节点,进行节点转移
if (head.readIndex == LINK_CAPACITY) {
//判断当前的Link节点的下一个节点是否为null,如果为null,说明已经达到了Link链表尾部,直接返回,
if (head.next == null) {
return false;
}
// 否则,将当前的Link节点的下一个Link节点赋值给head和this.head.link,进而对下一个Link节点进行操作
this.head = head = head.next;
}
// 获取Link节点的readIndex,即当前的Link节点的第一个有效元素的位置
final int srcStart = head.readIndex;
// 获取Link节点的writeIndex,即当前的Link节点的最后一个有效元素的位置
int srcEnd = head.get();
// 本次可转移的对象数量(写指针减去读指针)
final int srcSize = srcEnd - srcStart;
if (srcSize == 0) {
return false;
}
// 获取转移元素的目的地Stack中当前的元素个数
final int dstSize = dst.size;
// 计算期盼的容量
final int expectedCapacity = dstSize + srcSize;
// 期望的容量大小与实际 Stack 所能承载的容量大小进行比对,取最小值
if (expectedCapacity > dst.elements.length) {
final int actualCapacity = dst.increaseCapacity(expectedCapacity);
srcEnd = Math.min(srcStart + actualCapacity - dstSize, srcEnd);
}
if (srcStart != srcEnd) {
// 获取Link节点的DefaultHandle[]
final DefaultHandle[] srcElems = head.elements;
// 获取目的地Stack的DefaultHandle[]
final DefaultHandle[] dstElems = dst.elements;
// dst数组的大小,会随着元素的迁入而增加,如果最后发现没有增加,那么表示没有迁移成功任何一个元素
int newDstSize = dstSize;
//// 进行对象转移
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle element = srcElems[i];
// 表明自己还没有被任何一个 Stack 所回收
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
// 避免对象重复回收
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
// 将可转移成功的DefaultHandle元素的stack属性设置为目的地Stack
element.stack = dst;
// 将DefaultHandle元素转移到目的地Stack的DefaultHandle[newDstSize ++]中
dstElems[newDstSize++] = element;
// 设置为null,清楚暂存的handler信息,同时帮助 GC
srcElems[i] = null;
}
// 将新的newDstSize赋值给目的地Stack的size
dst.size = newDstSize;
if (srcEnd == LINK_CAPACITY && head.next != null) {
// 将Head指向下一个Link,也就是将当前的Link给回收掉了
// 假设之前为Head -> Link1 -> Link2,回收之后为Head -> Link2
this.head = head.next;
}
// 设置读指针位置
head.readIndex = srcEnd;
return true;
} else {
// The destination stack is full already.
return false;
}
}
}
- 寻找 cursor 节点中的第一个 Link如果为 null,则表示没有数据,直接返回;
- 如果第一个 Link 节点的 readIndex 索引已经到达该 Link 对象的 DefaultHandle[] 的尾部,则判断当前的 Link 节点的下一个节点是否为 null,如果为 null,说明已经达到了 Link 链表尾部,直接返回,否则,将当前的 Link 节点的下一个 Link 节点赋值给 head ,进而对下一个 Link 节点进行操作;
- 获取 Link 节点的 readIndex,即当前的 Link 节点的第一个有效元素的位置
- 获取 Link 节点的 writeIndex,即当前的 Link 节点的最后一个有效元素的位置
- 计算 Link 节点中可以被转移的元素个数,如果为 0,表示没有可转移的元素,直接返回
- 获取转移元素的目标 Stack 中当前的元素个数(dstSize)并计算期盼的容量 expectedCapacity,如果 expectedCapacity 大于目标Stack 的长度(dst.elements.length),则先对目的地 Stack 进行扩容,计算 Link 中最终的可转移的最后一个元素的下标;
- 如果发现目的地 Stack 已经满了( srcStart != srcEnd为false),则直接返回 false
- 获取 Link 节点的 DefaultHandle[] (srcElems)和目标 Stack 的 DefaultHandle[](dstElems)
- 根据可转移的起始位置和结束位置对 Link 节点的 DefaultHandle[] 进行循环操作
- 将可转移成功的 DefaultHandle 元素的stack属性设置为目标 Stack(element.stack = dst),将 DefaultHandle 元素转移到目的地 Stack 的 DefaultHandle[newDstSize++] 中,最后置空 Link 节点的 DefaultHandle[i]
- 如果当前被遍历的 Link 节点的 DefaultHandle[] 已经被掏空了(srcEnd == LINK_CAPACITY),并且该 Link 节点还有下一个 Link 节点
- 重置当前 Link 的 readIndex
7. SOFAJRaft源码分析—如何实现一个轻量级的对象池?的更多相关文章
- 8. SOFAJRaft源码分析— 如何实现日志复制的pipeline机制?
前言 前几天和腾讯的大佬一起吃饭聊天,说起我对SOFAJRaft的理解,我自然以为我是很懂了的,但是大佬问起了我那SOFAJRaft集群之间的日志是怎么复制的? 我当时哑口无言,说不出是怎么实现的,所 ...
- 3. SOFAJRaft源码分析— 是如何进行选举的?
开篇 在上一篇文章当中,我们讲解了NodeImpl在init方法里面会初始化话的动作,选举也是在这个方法里面进行的,这篇文章来从这个方法里详细讲一下选举的过程. 由于我这里介绍的是如何实现的,所以请大 ...
- 4. SOFAJRaft源码分析— RheaKV初始化做了什么?
前言 由于RheaKV要讲起来篇幅比较长,所以这里分成几个章节来讲,这一章讲一讲RheaKV初始化做了什么? 我们先来给个例子,我们从例子来讲: public static void main(fin ...
- 6. SOFAJRaft源码分析— 透过RheaKV看线性一致性读
开篇 其实这篇文章我本来想在讲完选举的时候就开始讲线性一致性读的,但是感觉直接讲没头没尾的看起来比比较困难,所以就有了RheaKV的系列,这是RheaKV,终于可以讲一下SOFAJRaft的线性一致性 ...
- Spring IOC 容器源码分析 - 填充属性到 bean 原始对象
1. 简介 本篇文章,我们来一起了解一下 Spring 是如何将配置文件中的属性值填充到 bean 对象中的.我在前面几篇文章中介绍过 Spring 创建 bean 的流程,即 Spring 先通过反 ...
- 9. SOFAJRaft源码分析— Follower如何通过Snapshot快速追上Leader日志?
前言 引入快照机制主要是为了解决两个问题: JRaft新节点加入后,如何快速追上最新的数据 Raft 节点出现故障重新启动后如何高效恢复到最新的数据 Snapshot 源码分析 生成 Raft 节点的 ...
- jQuery-1.9.1源码分析系列(六) 延时对象续——辅助函数jQuery.when
$.when的说明 描述: 提供一种方法来执行一个或多个对象的回调函数,返回这些对象的延时(Deferred)对象. 说明(结合实例和源码): 如果你不传递任何参数, jQuery.when()将返 ...
- 2. SOFAJRaft源码分析—JRaft的定时任务调度器是怎么做的?
看完这个实现之后,感觉还是要多看源码,多研究.其实JRaft的定时任务调度器是基于Netty的时间轮来做的,如果没有看过Netty的源码,很可能并不知道时间轮算法,也就很难想到要去使用这么优秀的定时调 ...
- jQuery-1.9.1源码分析系列(五) 回调对象
jQuery.Callbacks()提供的回调函数队列管理本来是延时回调处理的一部分,但是后面将其独立出来作为一个模块.jQuery就是这样,各个模块间的代码耦合度是处理的比较好的,值得学习.虽然是从 ...
随机推荐
- MS09-012 PR提权
漏洞编号:MS09-012 披露日期: 2009/4/14 受影响的操作系统:Windows 2008 x64 x86;XP;Server 2003 sp1 sp2; 测试系统:windows 20 ...
- 第一个shell脚本(一)
第一个脚本 [root@ipha-dev71- exercise_shell]# ll total -rw-r--r-- root root Aug : test.sh [root@ipha-dev7 ...
- ESP8266开发之旅 网络篇⑭ web配网
1. 前言 目前,市面上流行多种配网方式: WIFI模块的智能配网(SmartConfig以及微信AirKiss配网) SmartConfig 配网方式 请参考博主之前的博文 ESP8266开 ...
- OptimalSolution(5)--数组和矩阵问题(2)2
一.找到无序数组中最小的k个数 二.在数组中找到出现次数大于N/K的数 三.最长的可整合子数组的长度 四.不重复打印排序数组中相加和为给定值的所有二元组和三元组 五.未排序正数数组中累加和为给定值的最 ...
- 设计模式(十四)Chain of Responsibility模式
Chain of Responsibility模式就是当外部请求程序进行某个处理,但程序暂时无法直接决定由哪个对象负责处理时,就需要推卸责任.也就是说,当一个人被要求做什么事时,如果他可以做就自己做, ...
- Flask解析(二):Flask-Sqlalchemy与多线程、多进程
Sqlalchemy flask-sqlalchemy的session是线程安全的,但在多进程环境下,要确保派生子进程时,父进程不存在任何的数据库连接,可以通过调用db.get_engine(app= ...
- 【从刷面试题到构建知识体系】Java底层-synchronized锁-2偏向锁篇
上一篇通过构建金字塔结构,来从不同的角度,由浅入深的对synchronized关键字做了介绍, 快速跳转:https://www.cnblogs.com/xyang/p/11631866.html 本 ...
- 怎么安装wordcloud
python第三方组件有很多都是whl文件,遇到这样的whl文件应该怎样安装呢,今天来介绍一下whl文件怎样安装. 更多内容访问omegaxyz.com 先推荐一个非正式第三方whl文件包的网站: h ...
- C语言存储类别和链接
目录 C语言存储类别和链接 存储类别 存储期 五种存储类别 C语言存储类别和链接 最近详细的复习C语言,看到存储类别的时候总感觉一些概念模糊不清,现在认真的梳理一下.C语言的优势之一能够让程序员恰 ...
- Java内存模型相关原则详解
在<Java内存模型(JMM)详解>一文中我们已经讲到了Java内存模型的基本结构以及相关操作和规则.而Java内存模型又是围绕着在并发过程中如何处理原子性.可见性以及有序性这三个特征来构 ...