spark graphX作图计算
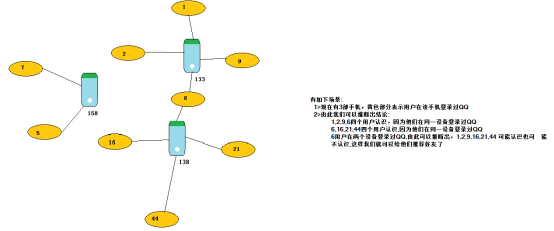
一、使用graph做好友推荐

import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
//求共同好友
object CommendFriend {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//点的集合
//点
val uv: RDD[(VertexId,(String,Int))] = sc.parallelize(Seq(
(133, ("毕东旭", 58)),
(1, ("贺咪咪", 18)),
(2, ("范闯", 19)),
(9, ("贾璐燕", 24)),
(6, ("马彪", 23)),
(138, ("刘国建", 40)),
(16, ("李亚茹", 18)),
(21, ("任伟", 25)),
(44, ("张冲霄", 22)),
(158, ("郭佳瑞", 22)),
(5, ("申志宇", 22)),
(7, ("卫国强", 22))
))
//边的集合
//边Edge
val ue: RDD[Edge[Int]] = sc.parallelize(Seq(
Edge(1, 133,0),
Edge(2, 133,0),
Edge(9, 133,0),
Edge(6, 133,0),
Edge(6, 138,0),
Edge(16, 138,0),
Edge(44, 138,0),
Edge(21, 138,0),
Edge(5, 158,0),
Edge(7, 158,0)
))
//构建图(连通图)
val graph: Graph[(String, Int), Int] = Graph(uv,ue)
//调用连通图算法
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(name,age)))=>(minid,(uid,name,age))
}.groupByKey()
.foreach(println(_))
//关闭
}
}
二、用户标签数据合并Demo
测试数据
|
陌上花开 旧事酒浓 多情汉子 APP爱奇艺:10 BS龙德广场:8 多情汉子 满心闯 K韩剧:20 满心闯 喜欢不是爱 不是唯一 APP爱奇艺:10 装逼卖萌无所不能 K欧莱雅面膜:5 |
计算结果数据
|
(-397860375,(List(喜欢不是爱, 不是唯一, 多情汉子, 多情汉子, 满心闯, 满心闯, 旧事酒浓, 陌上花开),List((APP爱奇艺,20), (K韩剧,20), (BS龙德广场,8)))) (553023549,(List(装逼卖萌无所不能),List((K欧莱雅面膜,5)))) |
import org.apache.spark.graphx.{Edge, Graph, VertexId}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object UserRelationDemo {
def main(args: Array[String]): Unit = {
//创建入口
val conf: SparkConf = new SparkConf().setAppName("CommendFriend").setMaster("local[*]")
val sc: SparkContext = new SparkContext(conf)
//读取数据
val rdd: RDD[String] = sc.textFile("F:\\dmp\\graph")
//点的集合
val uv: RDD[(VertexId, (String, List[(String, Int)]))] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val tags: List[(String, Int)] = arr.filter(_.contains(":")).map(tagstr => {
val arr: Array[String] = tagstr.split(":")
(arr(0), arr(1).toInt)
}).toList
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => {
if(nickname.equals(filterd(0))) {
(nickname.hashCode.toLong, (nickname, tags))
}else{
(nickname.hashCode.toLong, (nickname, List.empty))
}
})
})
//边的集合
val ue: RDD[Edge[Int]] = rdd.flatMap(line => {
val arr: Array[String] = line.split(" ")
val filterd: Array[String] = arr.filter(!_.contains(":"))
filterd.map(nickname => Edge(filterd(0).hashCode.toLong, nickname.hashCode.toLong, 0))
})
//构建图
val graph: Graph[(String, List[(String, Int)]), Int] = Graph(uv,ue)
//连通图算法找关系
graph
.connectedComponents()
.vertices
.join(uv)
.map{
case (uid,(minid,(nickname,list))) => (minid,(List(uid),List(nickname),list))
}
.reduceByKey{
case (t1,t2) =>
(
t1._1++t2._1 distinct ,
t1._2++t2._2 distinct,
t1._3++t2._3.groupBy(_._1).mapValues(_.map(_._2).reduce(_+_))
//.groupBy(_._1).mapValues(_.map(_._2).sum)
// list.groupBy(_._1).mapValues(_.map(_._2).foldLeft(0)(_+_))
)
}
.foreach(println(_))
//关闭
sc.stop()
}
}
三、用户标签数据合并
|
package cn.bw.mock.tags import cn.bw.mock.utils.TagsUtil |
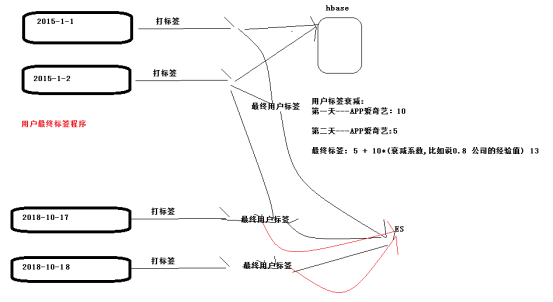
四、用户最终标签和衰减系数
spark graphX作图计算的更多相关文章
- Spark GraphX图计算核心源码分析【图构建器、顶点、边】
一.图构建器 GraphX提供了几种从RDD或磁盘上的顶点和边的集合构建图形的方法.默认情况下,没有图构建器会重新划分图的边:相反,边保留在默认分区中.Graph.groupEdges要求对图进行重新 ...
- Spark GraphX图计算核心算子实战【AggreagteMessage】
一.简介 参考博客:https://www.cnblogs.com/yszd/p/10186556.html 二.代码实现 package graphx import org.apache.log4j ...
- Spark GraphX图计算简单案例【代码实现,源码分析】
一.简介 参考:https://www.cnblogs.com/yszd/p/10186556.html 二.代码实现 package big.data.analyse.graphx import o ...
- Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈与熟练的掌握Scala语言【大数据Spark实战高手之路】
Spark GraphX宝刀出鞘,图文并茂研习图计算秘笈 大数据的概念与应用,正随着智能手机.平板电脑的快速流行而日渐普及,大数据中图的并行化处理一直是一个非常热门的话题.图计算正在被广泛地应用于社交 ...
- 明风:分布式图计算的平台Spark GraphX 在淘宝的实践
快刀初试:Spark GraphX在淘宝的实践 作者:明风 (本文由团队中梧苇和我一起撰写,并由团队中的林岳,岩岫,世仪等多人Review,发表于程序员的8月刊,由于篇幅原因,略作删减,本文为完整版) ...
- 大数据技术之_19_Spark学习_05_Spark GraphX 应用解析 + Spark GraphX 概述、解析 + 计算模式 + Pregel API + 图算法参考代码 + PageRank 实例
第1章 Spark GraphX 概述1.1 什么是 Spark GraphX1.2 弹性分布式属性图1.3 运行图计算程序第2章 Spark GraphX 解析2.1 存储模式2.1.1 图存储模式 ...
- 基于Spark GraphX计算二度关系
关系计算问题描述 二度关系是指用户与用户通过关注者为桥梁发现到的关注者之间的关系.目前微博通过二度关系实现了潜在用户的推荐.用户的一度关系包含了关注.好友两种类型,二度关系则得到关注的关注.关注的好友 ...
- 转载:四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍
四两拨千斤:借助Spark GraphX将QQ千亿关系链计算提速20倍 时间 2016-07-22 16:57:00 炼数成金 相似文章 (5) 原文 http://www.dataguru.cn/ ...
- Spark GraphX学习资料
<Spark GraphX 大规模图计算和图挖掘> http://book.51cto.com/art/201408/450049.htm http://www.csdn.net/arti ...
随机推荐
- ArangoDB简单实例介绍
数据介绍: 2008美国国内航班数据 airports.csv flights.csv 数据下载地址:https://www.arangodb.com/graphcourse_demodata_ara ...
- 学习笔记65_K均值_聚类算法
- LVS DR模式实践
client:192.168.4.10/24 proxy:192.168.4.5/24 VIP: 192.168.4.15/24 web1:192.168.4.100/24 VIP:192.168 ...
- MySQL8.0 redo日志系统优化
背景 现在主流的数据库系统的故障恢复逻辑都是基于经典的ARIES协议,也就是基于undo日志+redo日志的来进行故障恢复.redo日志是物理日志,一般采用WAL(Write-Ahead-Loggin ...
- 7.22 NOIP模拟7
又是炸掉的一次考试 T1.方程的解 本次考试最容易骗分的一道题,但是由于T2花的时间太多,我竟然连a+b=c都没判..暴力掉了40分. 首先a+b=c,只有一组解. 然后是a=1,b=1,答案是c-1 ...
- P3128 [USACO15DEC]最大流
秒切树上查分....(最近一次集训理解的东西) 但是,我敲了半小时才切掉这道题.... 我一直迷在了“边差分”和“点差分”的区别上. 所以,先说一下此题,再说一下区别. 首先,想到差分很容易. 然后, ...
- Docker从入门到掉坑(二):基于Docker构建SpringBoot微服务
本篇为Docker从入门到掉坑第二篇:基于Docker构建SpringBoot微服务,没有看过上一篇的最好读过 Docker 从入门到掉坑 之后,阅读本篇. 在之前的文章里面介绍了如何基于docker ...
- go中的数据结构切片-slice
1.部分基本类型 go中的类型与c的相似,常用类型有一个特例:byte类型,即字节类型,长度为,默认值是0: bytes = []btye{'h', 'e', 'l', 'l', 'o'} 变量byt ...
- IntelliJ IDEA 中设置左菜单字体, 编辑器字体和控制台的字体
IntelliJ IDEA 中设置左菜单字体大小 File-Settings,然后选择appearance,下图右侧红色边框中的内容即设置菜单的字体和大小 IntelliJ IDEA 中设置当前编 ...
- 使用.net core中的类DispatchProxy实现AOP
在软件业,AOP为Aspect Oriented Programming的缩写,意为:面向切面编程,通过预编译方式和运行期动态代理实现程序功能的统一维护的一种技术.AOP是软件开发中的一个热点,利用A ...