SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句
原文出处:http://www.cnblogs.com/wy123/p/5933734.html
先看常用的一种表结构设计方式:
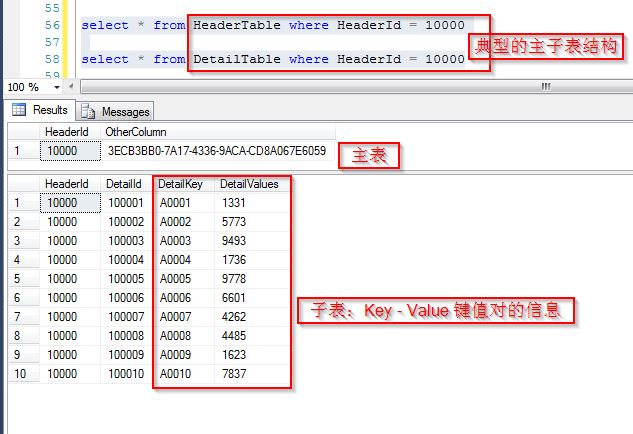
那么可能会遇到一种典型的查询方式,主子表关联,查询子表中的某些(或者全部)Key点对应的Value,横向显示(也即以行的方式显示)

这种查询方式很明显的一个却显示多次对字表查询(暂时抛开索引)
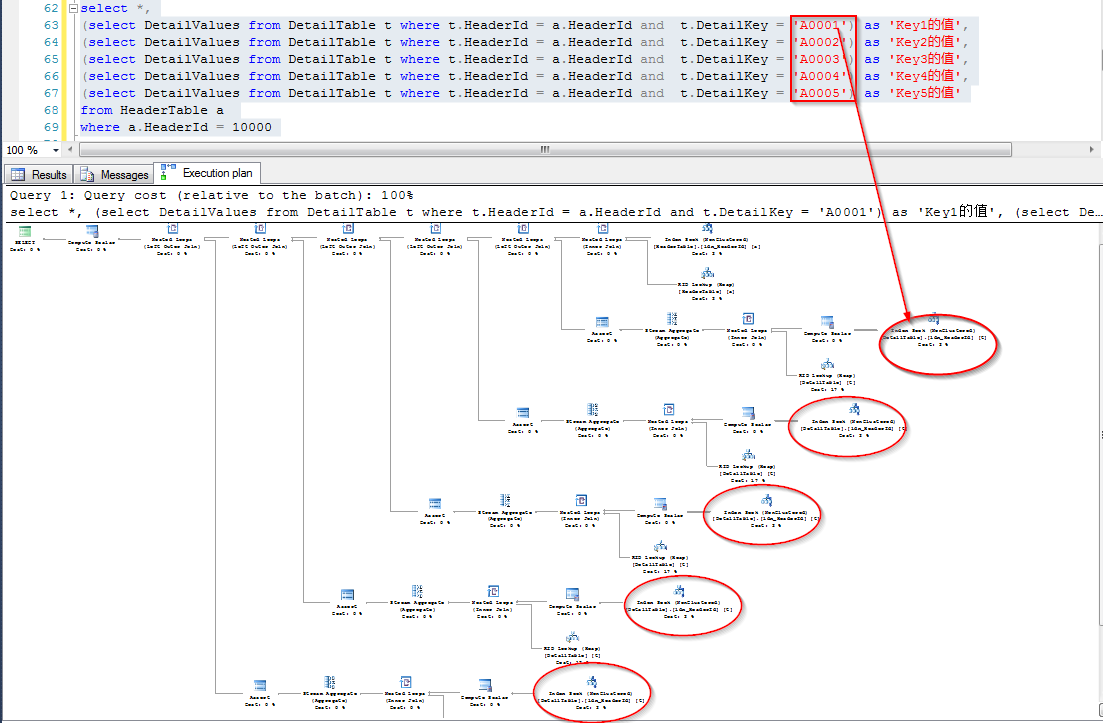
相比这种查询方式很多人都遇到过,如果子表是配置信息之类的小表的话,问题不大,如果字表数据量较大,可能就会有影响了。
这个查询目的是将”纵表”存储的结果“横向”显示,相当于横列转换的感觉了。
可以将子表的结果一次性将纵表的结果转换成横标,再跟主表连接,
然后得到一个最终一样的查询结果(格式),就能够减少子表的查询次数
这里将子表的结果“一次性将纵表的结果转换成横标”,是典型的行列转换操作
首先先看一下这里所说的一次转换成横标的这一步骤,需要借助pivot,一步一步来

然后看跟主表join之后,两种查询方式的整体查询结果
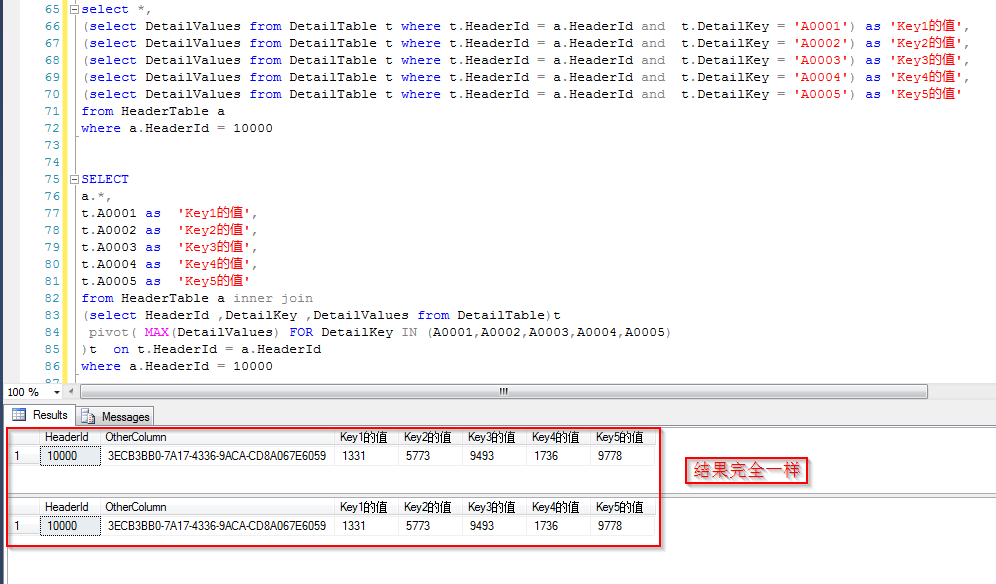
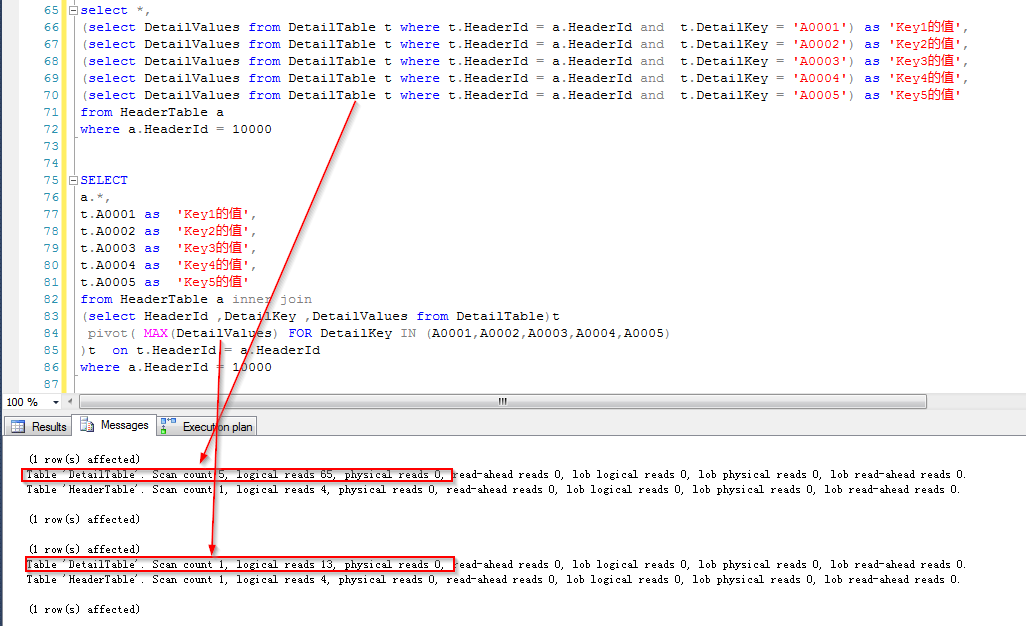
那么看一下后一种查询方式也即通过行业转换之后做join的执行计划,可以看到只对字表进行了一次查找(这里是index seek,但是暂抛开索引)
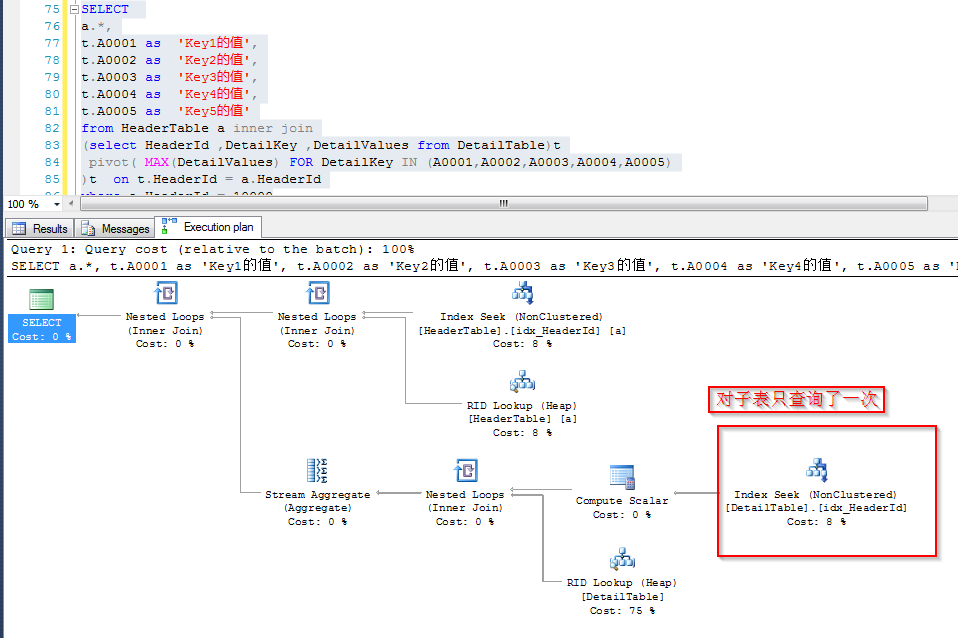
观察一下两条SQL的IO信息,可以发现,前者的Scan count是5,逻辑读是65,后者的Scan count是1,逻辑读是13,65=13*5。可见后者是一次性将表中的几个Key值读取出来的,而前者每个Key值读取一次表。
总结:
改写SQL是实现优化的思路之一,当然改写SQL技巧有很多种,本文仅对某一类典型查询提供一个改写思路,避免对一个表进行多次读取的方式来实现的查询。
通过改写一个常用的查询写法,从而实现一个等价的逻辑来减少对基表的读取次数来达到SQL优化的目的。
当然实际情况可能更加复杂,采用该思路改写的时候要注意针对SQL语句测试验证。
附上本文的测试脚本
create table HeaderTable
(
HeaderId int ,
OtherColumn varchar(50)
) create table DetailTable
(
HeaderId int,
DetailId int identity(1,1),
DetailKey varchar(50),
DetailValues int
) declare @i int = 0
while @i<1000000
begin
insert into HeaderTable values (@i,NEWID())
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0001',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0002',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0003',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0004',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0005',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0006',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0007',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0008',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0009',RAND()*10000)
insert into DetailTable (HeaderId,DetailKey,DetailValues)values(@i,'A0010',RAND()*10000)
set @i=@i+1
end create index idx_HeaderId on HeaderTable(HeaderId) create index idx_HeaderId on DetailTable(HeaderId) create index idx_DetailKey on DetailTable(DetailKey) select *,
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0001') as 'Key1的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0002') as 'Key2的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0003') as 'Key3的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0004') as 'Key4的值',
(select DetailValues from DetailTable t where t.HeaderId = a.HeaderId and t.DetailKey = 'A0005') as 'Key5的值'
from HeaderTable a
where a.HeaderId = 10000 SELECT
a.*,
t.A0001 as 'Key1的值',
t.A0002 as 'Key2的值',
t.A0003 as 'Key3的值',
t.A0004 as 'Key4的值',
t.A0005 as 'Key5的值'
from HeaderTable a inner join
(select HeaderId ,DetailKey ,DetailValues from DetailTable)t
pivot( MAX(DetailValues) FOR DetailKey IN (A0001,A0002,A0003,A0004,A0005)
)t on t.HeaderId = a.HeaderId
where a.HeaderId = 10000
SQL Server SQL性能优化之--pivot行列转换减少扫描计数优化查询语句的更多相关文章
- SQL Server数据库性能优化之SQL语句篇【转】
SQL Server数据库性能优化之SQL语句篇http://www.blogjava.net/allen-zhe/archive/2010/07/23/326927.html 近期项目需要, 做了一 ...
- 最有效地优化 Microsoft SQL Server 的性能
为了最有效地优化 Microsoft SQL Server 的性能,您必须明确当情况不断变化时,性能将在哪些方面得到最大程度的改进,并集中分析这些方面.否则,在这些问题上您可能花费大量的时间和精力 ...
- Sql Server CPU 性能排查及优化的相关 Sql
Sql Server CPU 性能排查及优化的相关 Sql 语句,非常好的SQL语句,记录于此: --Begin Cpu 分析优化的相关 Sql --使用DMV来分析SQL Server启动以来累计使 ...
- Sql Server数据库性能优化之索引
最近在做SQL Server数据库性能优化,因此复习下一索引.视图.存储过程等知识点.本篇为索引篇,知识整理来源于互联网. 索引加快检索表中数据的方法,它对数据表中一个或者多个列的值进行结构排序,是数 ...
- 对SQL Server SQL语句进行优化的10个原则
1.使用索引来更快地遍历表. 缺省情况下建立的索引是非群集索引,但有时它并不是最佳的.在非群集索引下,数据在物理上随机存放在数据页上.合理的索引设计要建立在对各种查询的分析和预测上.一般来说:①.有大 ...
- SQL Server 2008性能故障排查(四)——TempDB
原文:SQL Server 2008性能故障排查(四)--TempDB 接着上一章:I/O TempDB: TempDB是一个全局数据库,存储内部和用户对象还有零食表.对象.在SQLServer操作过 ...
- SQL Server 2008性能故障排查(三)——I/O
原文:SQL Server 2008性能故障排查(三)--I/O 接着上一章:CPU瓶颈 I/O瓶颈(I/O Bottlenecks): SQLServer的性能严重依赖I/O子系统.除非你的数据库完 ...
- SQL Server 2008性能故障排查(二)——CPU
原文:SQL Server 2008性能故障排查(二)--CPU 承接上一篇:SQL Server 2008性能故障排查(一)--概论 说明一下,CSDN的博客编辑非常不人性化,我在word里面都排好 ...
- SQL Server 2008性能故障排查(一)——概论
原文:SQL Server 2008性能故障排查(一)--概论 备注:本人花了大量下班时间翻译,绝无抄袭,允许转载,但请注明出处.由于篇幅长,无法一篇博文全部说完,同时也没那么快全部翻译完,所以按章节 ...
随机推荐
- 在SQLSERVER里,怎么让别人只能输入一个字母的约束该怎么写?就是26个字母中的任意一个?
alter table 表名 add constraint ck_char check(自段名 like '[a-z]' or 自段名 like '[A-Z]')
- final 140字评论
按照演讲顺序 1.约跑app 个人感觉约跑现在做的已经很不错了,要是能添加地图就更好了. 2.礼物挑选 给人感觉在一定的时间做到这个程度,很不错很好,讲的声音有点小. ...
- java的英文词频算法
java实现的英文词频算法,通常是采用单词树来实现的.使用java实现词频统计,为了统计词汇出现频率,最简单的做法是再建立一个map,其中,key是单词,value代表次数.将文章从头读到尾,读到一个 ...
- Ajax请求
<!doctype html><html lang="en"> <head> <meta charset="UTF-8" ...
- Visual Studio跨平台开发Xamarin
台湾微软的一系列Visual Studio跨平台开发Xamarin的资料,上面还有视频.具体参看 http://www.microsoft.com/taiwan/newsletter/library/ ...
- Android提权漏洞CVE-2014-7920&CVE-2014-7921分析
没羽@阿里移动安全,更多安全类技术干货,请访问阿里聚安全博客 这是Android mediaserver的提权漏洞,利用CVE-2014-7920和CVE-2014-7921实现提权,从0权限提到me ...
- [译]MVC网站教程(一):多语言网站框架
本文简介 本博文介绍了 Visual Studio 工具生成的 ASP.NET MVC3 站点的基本框架:怎样实现网站的语言的国际化与本地化功能,从零开始实现用户身份认证机制,从零开始实现用户注册机制 ...
- MySQL 变量和条件
概述 变量在存储过程中会经常被使用,变量的使用方法是一个重要的知识点,特别是在定义条件这块比较重要. mysql版本:5.6 变量定义和赋值 #创建数据库 DROP DATABASE IF EXIST ...
- MySQL 主主复制
200 ? "200px" : this.width)!important;} --> 介绍 环境 OS:CentOS 6.7,MySQL 5.6 Master:192.16 ...
- Step by step 活动目录中添加一个子域
原创地址:http://www.cnblogs.com/jfzhu/p/4006545.html 转载请注明出处 前面介绍过如何创建一个域,下面再介绍一下如何在该父域中添加一个子域. 活动目录中的森林 ...