[考试反思]1028csp-s模拟测试91:预估
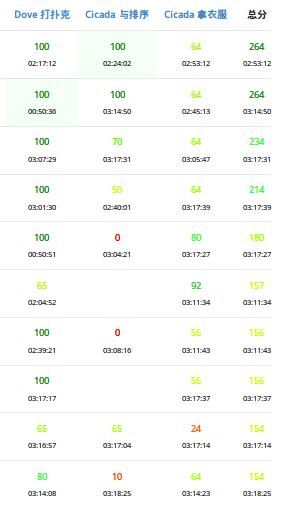

这一轮是要闹哪样啊???前十都死活进不去???
能不能不要到联赛前突然连续掉链子啊!!!
总算难得的切掉了T1。然后又一次把T2和T3的难度估反了
结果给T2剩下了30分钟,想到正解来不及打了。
然后T3没有乱搞丢了很多分。(循环不用跑满,上限能到80。。。考后还有AC的)
联赛题目的难度基本是升序。。。
学会乱搞,要有信仰。。。
T1必须占用更少的时间,想到并证明正确之后就快速打出来
T1:Dave打扑克
可以证明,数量本质不同的堆数至多为根号个。
所以并查集维护,用unordered_set迭代器遍历,用树状数组计数询问即可。
- #include<cstdio>
- #include<unordered_set>
- using namespace std;
- unordered_set<int>S;
- int n,m,t[],buc[],siz[],f[];
- void add(int p,int w){for(;p<=;p+=p&-p)t[p]+=w;}
- int ask(int p,int a=){for(;p;p^=p&-p)a+=t[p];return a;}
- int find(int p){return f[p]==p?p:f[p]=find(f[p]);}
- int main(){//freopen("cards105.in","r",stdin);freopen("my.out","w",stdout);
- scanf("%d%d",&n,&m);
- buc[]=n;S.insert();add(,n);
- for(int i=;i<=n;++i)f[i]=i,siz[i]=;
- for(int i=,opt,x,y;i<=m;++i){
- scanf("%d",&opt);
- if(opt==){
- scanf("%d%d",&x,&y);
- x=find(x);y=find(y);
- if(x==y)continue;
- add(siz[x],-);add(siz[y],-);add(siz[x]+siz[y],);
- buc[siz[x]]--;buc[siz[y]]--;buc[siz[x]+siz[y]]++;
- if(!buc[siz[x]])S.erase(siz[x]);
- if(!buc[siz[y]])S.erase(siz[y]);
- if(buc[siz[x]+siz[y]]==)S.insert(siz[x]+siz[y]);
- siz[y]+=siz[x];f[x]=y;n--;
- }else{
- scanf("%d",&x);long long ans=n*(n-1ll)>>;
- if(!x){printf("%lld\n",ans);continue;}
- unordered_set<int>::iterator it=S.begin();
- while(it!=S.end()){
- y=*it;
- ans-=1ll*buc[y]*(ask(y+x-)-ask(y));
- ans-=1ll*buc[y]*(buc[y]-)>>;
- it++;
- }printf("%lld\n",ans);
- }
- }
- }
T2:Cicada与排序
归并排序每个数也就会递归下去log层。
所以我们不断考虑每个数在参与一次归并后的相对排名就好了。
当然数字不一样的最后排名肯定好说,现在只考虑每个数在所有与它相同的数里的相对排名(以下简称“位置”)
设rk[i][j]表示最开始位置在i的数在归并后所在的位置。
然后我们考虑如何转移,我们需要的其实就是一个“两个数组归并,其中第一个数组的第p位在归并后的数组排第q位的概率”
这个可以dp求出。dp[i][j][0/1]表示归并排序时第一个数组弹掉了i个,第二个数组弹掉了j个,最后一次弹的来自于第一组还是第二组。
这样的话最后弹掉的元素就是排名第i+j的元素了,而在归并之前的排名就是i或j(取决于来源)
具体的转移其实就是考虑两个数组是不是已经被弹干净了,弹干净了一个那就只能弹另一个,否则就随机弹一个
转移比较简单,自己想比较好(这个已经比题解的那个简单很多了)实在不行再颓码
这个dp数组当然与两个原数组的长度有关,所以要放在merge_sort里面处理,而非全局预处理(这不是题解思路)
然后rk也就可以转移了,枚举归并前后的排名即可。
不要memset。跑的很快的。
复杂度的证明可能要等到学积分?极端数据是所有数都相同。
并不是积分,是主定理啦!
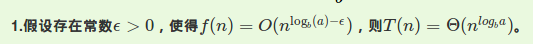
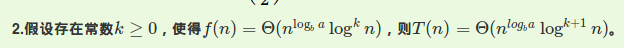
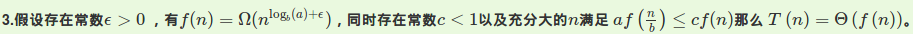
这道题满足第三条。$f(n)=\Omega (n^3)$,
这样的话$\epsilon =2>0$
此时c取$\frac{1}{4}$时满足后者条件即
$2f(\frac{n}{2})<=\frac{1}{4}f(n)$,其中$a=b=2$
所以总复杂度$O(n^3)$
- #include<bits/stdc++.h>
- using namespace std;
- #define mod 998244353
- #define inv 499122177
- #define int long long
- vector<int>lv[],rv[];
- int n,x[],rk[][],Rcnt[],Lcnt[],tem[],dp[][][];
- void merge_sort(int l,int r){
- if(l==r)return; int M=l+r>>;
- merge_sort(l,M); merge_sort(M+,r);
- for(int i=l;i<=M;++i)Lcnt[x[i]]++,lv[x[i]].push_back(i);
- for(int i=M+;i<=r;++i)Rcnt[x[i]]++,rv[x[i]].push_back(i);
- for(int i=;i<=;++i){
- for(int L=;L<=Lcnt[i];++L)for(int R=;R<=Rcnt[i];++R)dp[L][R][]=dp[L][R][]=;
- dp[][][]=;
- for(int L=;L<=Lcnt[i];++L)for(int R=;R<=Rcnt[i];++R)
- if(L!=Lcnt[i]&&R!=Rcnt[i])
- dp[L+][R][]=(dp[L+][R][]+(dp[L][R][]+dp[L][R][])*inv)%mod,
- dp[L][R+][]=(dp[L][R+][]+(dp[L][R][]+dp[L][R][])*inv)%mod;
- else if(L!=Lcnt[i])dp[L+][R][]=(dp[L+][R][]+dp[L][R][]+dp[L][R][])%mod;
- else if(R!=Rcnt[i])dp[L][R+][]=(dp[L][R+][]+dp[L][R][]+dp[L][R][])%mod;
- for(int j=;j<Lcnt[i];++j){
- for(int k=;k<=Lcnt[i];++k)for(int rp=;rp<=Rcnt[i];++rp)
- tem[k+rp]=(tem[k+rp]+rk[lv[i][j]][k]*dp[k][rp][])%mod;
- for(int nrk=;nrk<=Lcnt[i]+Rcnt[i];++nrk)rk[lv[i][j]][nrk]=tem[nrk],tem[nrk]=;
- }
- for(int j=;j<Rcnt[i];++j){
- for(int k=;k<=Rcnt[i];++k)for(int lp=;lp<=Lcnt[i];++lp)
- tem[k+lp]=(tem[k+lp]+rk[rv[i][j]][k]*dp[lp][k][])%mod;
- for(int nrk=;nrk<=Lcnt[i]+Rcnt[i];++nrk)rk[rv[i][j]][nrk]=tem[nrk],tem[nrk]=;
- }
- lv[i].clear();rv[i].clear();Lcnt[i]=Rcnt[i]=;
- }
- }
- main(){//freopen("sort103.in","r",stdin);
- scanf("%lld",&n);
- for(int i=;i<=n;++i)scanf("%lld",&x[i]);
- for(int i=;i<=n;++i)rk[i][]=;
- merge_sort(,n);
- for(int i=;i<=n;++i)Lcnt[x[i]]++;
- for(int i=;i<=;++i)Lcnt[i]+=Lcnt[i-];
- for(int i=;i<=n;++i){
- int ans=;
- for(int j=;j<=Lcnt[x[i]]-Lcnt[x[i]-];++j)ans=(ans+1ll*rk[i][j]*j)%mod;//,printf("%lld %lld\n",j,rk[i][j]);
- printf("%lld ",ans+Lcnt[x[i]-]);
- }puts("");
- }
T3:Cicada拿衣服
英文题目名为什么叫naive??拿(na)衣(i)服(ve)???
看到这个题目名我还以为这道题真的很naive
其实只是比较好打,但是思路不是很好想
首先你需要打一个暴力,需要一个ST表来O(1)查询区间的那四个函数。
发现Dybala的ST表还是O(log)的。。。奉劝各位好好学学ST表。。。
highbit操作是要预处理的!!!不要现算!!!
然后最粗暴的就是枚举左右端点,check它的excited值,如果合法就区间取max。我是用线段树维护的。
到这里为止如果你不乱搞你能有36分。
然后正解的80%就已经打完了。
首先我们固定右端点,不断左移左端点。
对于OR,最多只会变化log次,即每一位从0变成1。
对于AND,最多也只会变化log次,每一位从1到0。
所以其实OR-AND只会变化2log次。
那么问题就是MIN-MAX了。MIN越来越小MAX越来越大所以MIN-MAX会越来越小。
所以在由OR-AND分割出的2log段里,每一段内部的excited值都满足单调性。
所以我们只要考虑在每一段里找到最靠左的excited值的合法位置,然后就线段树区间赋取max就好了。
然后怎么找到这2log个段呢?
用链表记录下每个段的右端点就好了,然后跳链表就可以。
因为右端点右移的时候,链表内部只会合并段而不会新增段,所以是可以用链表的。
所以代码其实只是多了一个链表,然后爆扫改成跳链表而已。
复杂度是$O(nlogn)$
这题数据很难造,所以乱搞可过。然而打正解需要优化常数不然容易T92什么的。。。
记得及时跳出不然还是$nlog^2$。。。我就是hanpi
- #include<bits/stdc++.h>
- using namespace std;
- int mx[][],mn[][],Or[][],And[][];
- int ans[],n,x[],hi[],k,t[],cl[],cr[];
- int lst[],nxt[];
- void del(int p){lst[nxt[p]]=lst[p];nxt[lst[p]]=nxt[p];}
- const int N=1e6+;
- const int Ls=<<|;
- char buffer[Ls],*Ss,*Ts;
- #define getchar() ((Ss==Ts&&(Ts=(Ss=buffer)+fread(buffer,1,Ls,stdin),Ss==Ts))?EOF:*Ss++)
- int read(register int p=,register char ch=getchar()){
- while(ch<''||ch>'')ch=getchar();
- while(ch>=''&&ch<='')p=(p<<)+(p<<)+ch-'',ch=getchar();
- return p;
- }
- #define Max(a,b) ((a)>(b)?(a):(b))
- #define Min(a,b) ((a)<(b)?(a):(b))
- int _max(int l,int r){
- int x=hi[r-l+];
- return Max(mx[x][l],mx[x][r-(<<x)+]);
- }
- int _min(int l,int r){
- int x=hi[r-l+];
- return Min(mn[x][l],mn[x][r-(<<x)+]);
- }
- int _or(int l,int r){
- int x=hi[r-l+];
- return Or[x][l]|Or[x][r-(<<x)+];
- }
- int _and(int l,int r){
- int x=hi[r-l+];
- return And[x][l]&And[x][r-(<<x)+];
- }
- int excited(int l,int r){
- return _or(l,r)-_max(l,r)+_min(l,r)-_and(l,r);
- }
- void build(int p,int l,int r){
- cl[p]=l;cr[p]=r;t[p]=-;
- if(l==r)return;
- build(p<<,l,l+r>>);
- build(p<<|,(l+r>>)+,r);
- }
- void modify(int p,int l,int r,int w){
- if(l<=cl[p]&&cr[p]<=r)return t[p]=Max(t[p],w),(void);
- if(l<=cr[p<<]) modify(p<<,l,r,w);
- if(r>cr[p<<]) modify(p<<|,l,r,w);
- }
- void dfs(int p,int w){
- w=Max(w,t[p]);
- if(cl[p]==cr[p])return printf("%d ",w),(void);
- dfs(p<<,w); dfs(p<<|,w);
- }
- int chk(int l,int r,int R){
- while(l<r-)if(excited(l+r>>,R)>=k)r=l+r>>;else l=(l+r>>)+;
- if(excited(l,R)>=k)return l;return r;
- }
- int main(){//freopen("naive105.in","r",stdin);freopen("my.out","w",stdout);
- scanf("%d%d",&n,&k);build(,,n);
- for(int i=;i<=n;++i)x[i]=read(),lst[i]=i-,nxt[i]=i+;
- nxt[]=;
- for(int i=;i<=n;++i) mx[][i]=mn[][i]=Or[][i]=And[][i]=x[i];
- for(int j=;j<;++j)for(int i=;i+(<<j)-<=n;++i)
- mx[j][i]=Max(mx[j-][i],mx[j-][i+(<<j-)]),
- mn[j][i]=Min(mn[j-][i],mn[j-][i+(<<j-)]),
- Or[j][i]=Or[j-][i]|Or[j-][i+(<<j-)],
- And[j][i]=And[j-][i]&And[j-][i+(<<j-)];
- for(int j=;j<;++j)for(int i=<<j;i<<<j+&&i<=n;++i)hi[i]=j;
- for(int r=;r<=n;++r){
- for(int i=lst[r];i;i=lst[i])if(_or(nxt[i],r)==_or(i,r)&&_and(nxt[i],r)==_and(i,r))del(i);
- for(int i=nxt[],p;i<=r;i=nxt[i])if(excited(i,r)>=k){p=chk(lst[i]+,i,r),modify(,p,r,r-p+);break;}
- }
- dfs(,-);puts("");
- }
[考试反思]1028csp-s模拟测试91:预估的更多相关文章
- [考试反思]0718 NOIP模拟测试5
最后一个是我...rank#11 rank#1和rank#2被外校大佬包揽了. 啊...考的太烂说话底气不足... 我考场上在干些什么啊!!! 20分钟“切”掉T2,又27分钟“切”掉T1 切什么切, ...
- csp-s模拟测试91
csp-s模拟测试91 倒悬吃屎的一套题. $T1$认真(?)分析题意发现复杂度不能带$n$(?),计划直接维护答案,考虑操作对答案的影响,未果.突然发现可以动态开点权值线段树打部分分,后来$Tm$一 ...
- 2019.10.28 csp-s模拟测试91 反思总结
有一场没一场的233 T1: 胡乱分析一下题意,发现和为n的x个正整数,不同的数字种类不会超过√n个.假设这x个数字都不同,最多也就是(x+1)*x/2=n. 所以可以维护现有的size值以及对应的数 ...
- [考试反思]0814NOIP模拟测试21
前两名是外校的240.220.kx和skyh拿到了190的[暴力打满]的好成绩. 我第5是170分,然而160分就是第19了. 在前一晚上刚刚爆炸完毕后,心态格外平稳. 想想前一天晚上的挣扎: 啊啊啊 ...
- [考试反思]0714/0716,NOIP模拟测试3/4
这几天时间比较紧啊(其实只是我效率有点低我在考虑要不要坐到后面去吹空调) 但是不管怎么说,考试反思还是要写的吧. 第三次考试反思没写总感觉缺了点什么,但是题都刷不完... 一进图论看他们刷题好快啊为什 ...
- [考试反思]1109csp-s模拟测试106:撞词
(撞哈希了用了模拟测试28的词,所以这次就叫撞词吧) 蓝色的0... 蓝色的0... 都该联赛了还能CE呢... 考试结束前15分钟左右,期望得分300 然后对拍发现T2伪了写了一个能拿90分的垃圾随 ...
- [考试反思]0909csp-s模拟测试41:反典
说在前面:我是反面典型!!!不要学我!!! 说在前面:向rank1某脸学习,不管是什么题都在考试反思后面稍微写一下题解. 这次是真的真的运气好... 这次知识点上还可以,但是答题策略出了问题... 幸 ...
- [考试反思]0729NOIP模拟测试10
安度因:哇哦. 安度因:谢谢你. 第三个rank1不知为什么就来了.迷之二连?也不知道哪里来的rp 连续两次考试数学都占了比较大的比重,所以我非常幸运的得以发挥我的优势(也许是优势吧,反正数学里基本没 ...
- [考试反思]1003csp-s模拟测试58:沉淀
稳住阵脚. 还可以. 至少想拿到的分都拿到了,最后一题的确因为不会按秩合并和线段树分治而想不出来. 对拍了,暴力都拍了.挺稳的. 但是其实也有波折,险些被卡内存. 如果内存使用不连续或申请的内存全部使 ...
随机推荐
- 使用真机导致Androidstudio打印不出log
针对真机打印不出log这个问题,我具体的解决方案是这样: 1.你要确保你的Android studio中的菜单栏 ,Tools → Android → Enable ADB Integration这个 ...
- Redis info 说明
背景 前面几篇文章介绍完了Redis相关的一些说明,现在看看如何查看Redis的一些性能指标和统计信息,也可以看官网说明. INFO [section] INFO命令返回有关服务器的信息和统计信息,带 ...
- bugku细心地大象
解压得到图片,查看属性,发现一段编码. 用winhex打开图片,发现头文件是错的,正常jpg文件头文件为FF D8 FF E0 说明不是图片,是zip的文件头,更换格式. 丢到kali用binwalk ...
- 爬虫之beautifulsoup篇之一
一个网页的节点太多,一个个的用正则表达式去查找不方便且不灵活.BeautifulSoup将html文档转换成一个属性结构,每个节点都是python对象.这样我们就能针对每个结点进行操作.参考如下代码: ...
- ubuntu使用uwsgi+nginx部署django
ls -lha export WORKON_HOME=~/venv source /usr/local/bin/vitualenvwrapper.sh VIRTUALENVWRAPPER_PYTHON ...
- Vue-cli中axios传参的方式以及后端取的方式
0917自我总结 Vue-cli中axios传参的方式以及后端取的方式 一.传参 params是添加到url的请求字符串中的,用于get请求. data是添加到请求体(body)中的, 用于post请 ...
- Python_深拷贝和浅拷贝
深拷贝与浅拷贝 import copy v = 123 v1 = copy.copy(v) #浅拷贝 v2 = copy.deepcopy(v) #深拷贝 **拷贝只拷贝可变数据类型,浅拷贝只拷贝第一 ...
- 攻防世界(XCTF)WEB(进阶区)write up(四)
ics-07 Web_php_include Zhuanxv Web_python_template_injection ics-07 题前半部分是php弱类型 这段说当传入的id值浮点值不能为1 ...
- 实用---GUI的搭建,windowbuilder的使用
在进行GUI的搭建过程中,相信很多人对于一个图标的设置感觉写起来很麻烦,需要不断的添加,而在java中有一个windowbuilder窗口可以很好的帮助我们进行GUI的搭建 1.进入eclipse的页 ...
- gitlab 提交
gitlab 提交 Git global setup git config --global user.name "lial" git config --global user.e ...