Pandas常用基本功能
Series 和 DataFrame还未构建完成的朋友可以参考我的上一篇博文:https://www.cnblogs.com/zry-yt/p/11794941.html
当我们构建好了 Series 和 DataFrame 之后,我们会经常使用哪些功能呢?引用上一章节中的场景,我们有一些用户的的信息,并将它们存储到了 DataFrame 中。因为大多数情况下 DataFrame 比 Series 更为常用,所以这里以 DataFrame 举例说明,但实际上很多常用功能对于 Series 也适用。
此为上一章节完成的DataFrame
import pandas as pd
index = pd.Index(data=["Tom", "Bob", "Mary", "James"], name="name")
data = {
"age": [18, 30, 25, 40],
"city": ["BeiJing", "ShangHai", "GuangZhou", "ShenZhen"],
"sex": ["male", "male", "female", "male"]
}
user_info = pd.DataFrame(data=data, index=index)
user_info """
age city sex
name
Tom 18 BeiJing male
Bob 30 ShangHai male
Mary 25 GuangZhou female
James 40 ShenZhen male
"""
常用基本功能
了解数据的整体情况
user_info.info() """
<class 'pandas.core.frame.DataFrame'>
Index: 4 entries, Tom to James
Data columns (total 3 columns):
age 4 non-null int64
city 4 non-null object
sex 4 non-null object
dtypes: int64(1), object(2)
memory usage: 128.0+ bytes
"""
查看头部、尾部的n条数据
查看头部 --> .head(n)
# 查看前三条数据
user_info.head(3)
查看尾部 --> .tail(n)
# 查看最后两条数据
user_info.tail(2)
获取Pandas 中数据结构的方法和属性
通过 .shape 获取数据的形状
user_info.shape # (4, 3)
"""
age city sex
name
Tom 18 BeiJing male
Bob 30 ShangHai male
Mary 25 GuangZhou female
James 40 ShenZhen male
"""
通过 .T 获取数据的转置。
user_info.T
"""
name Tom Bob Mary James
age 18 30 25 40
city BeiJing ShangHai GuangZhou ShenZhen
sex male male female male
"""
通过 .values 获取原有数据
user_info.values
"""
array([[18, 'BeiJing', 'male'],
[30, 'ShangHai', 'male'],
[25, 'GuangZhou', 'female'],
[40, 'ShenZhen', 'male']], dtype=object)
"""
描述与统计
查看数据的简单统计指标
user_info.age.max() # 查看年龄的最大值
user_info.age.min() # 查看年龄的最小值
user_info.age.mean() # 查看年龄的平均值
user_info.age.quantile() # 查看年龄的中位数
user_info.age.sum() # 查看年龄的总和 user_info.age.cumsum() # 累加求和
"""
name
Tom 18
Bob 48
Mary 73
James 113
Name: age, dtype: int64
"""
一次性获取多个统计指标
查看数字类型列的一些统计指标:如 总数、平均数、标准差、最小值、最大值、25% / 50% / 75% 分位数
user_info.describe()
查看非数字类型的列的统计指标:如 总数,去重后的个数、最常见的值、最常见的值的频数
user_info.describe(include=["object"])
统计某列中每个值出现的次数
# 统计sex列值出现的次数
user_info.sex.value_counts()
"""
male 3
female 1
Name: sex, dtype: int64
"""
获取某列最大值或最小值对应的索引
# 获取年龄最大的索引
user_info.age.idxmax() # 'James'
# 获取年龄最小的索引
user_info.age.idxmin() # 'Tom'
离散化
数值区间为(a,b]
.cut
根据每个值的大小来进行离散化,自动生成等距的离散区间
# 将年龄分成3个区间
pd.cut(user_info.age,3)
"""
name
Tom (17.978, 25.333]
Bob (25.333, 32.667]
Mary (17.978, 25.333]
James (32.667, 40.0]
Name: age, dtype: category
Categories (3, interval[float64]): [(17.978, 25.333] < (25.333, 32.667] < (32.667, 40.0]]
"""
自定义区间与标签
pd.cut(user_info.age,[10,24,36,50],labels=["child",'youth',"middle"])
"""
user_index
Tom child
Scott child
Jass middle
Jame middle
Name: age, dtype: category
Categories (3, object): [child < youth < middle]
"""
.qcut
根据每个值出现的次数来进行离散化
pd.qcut(user_info.age,3)
"""
name
Tom (17.999, 25.0]
Bob (25.0, 30.0]
Mary (17.999, 25.0]
James (30.0, 40.0]
Name: age, dtype: category
Categories (3, interval[float64]): [(17.999, 25.0] < (25.0, 30.0] < (30.0, 40.0]]
"""
练习
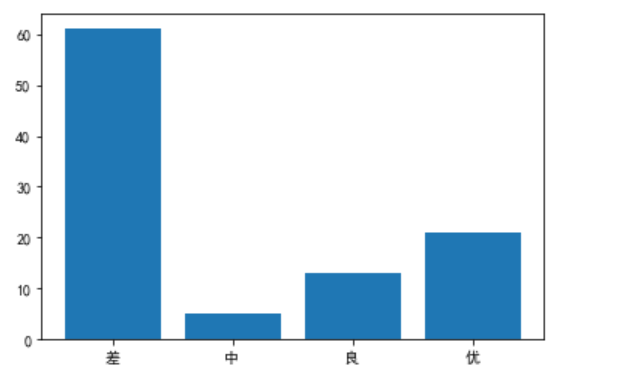
随机生成 100 个数作为考试成绩,给成绩设定优良中差,比如:0-59 分为差,60-70 分为中,71-80 分为良,81-100 为优秀,统计每个区间上的人数。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 种子
np.random.seed(10)
# 生成0-100的随机数字100个
data = np.random.randint(0,101,100)
# 准备区间名字
labels=["差","中","良","优"]
# 将区间显示为自定义区间名
count=pd.cut(data,[-1,59,70,80,100],labels=labels)
# 统计次数
count=count.value_counts()
# 画直方图,横轴为标签,纵轴为数量
plt.bar(labels,count)
# 防止中文编码错误
plt.rcParams['font.sans-serif']=['SimHei']
排序功能
Pandas 支持两种排序方式:
- 按轴(索引或列)排序
- 按实际值排序
按索引排序
.sort_index:默认是按照索引进行正序排的
user_info.sort_index()
按列名进行倒序排
设置参数 axis=1 和 ascending=False
user_info.sort_index(axis=1, ascending=False)
按照实际值来排序
.sort_values:后接需要排序的参数(默认升序)
# 按年龄排序
user_info.sort_values(by="age")
按照多个值来排序
# 先按年龄排序,再按城市排序
# list 中每个元素的顺序会影响排序优先级
user_info.sort_values(by=["age", "city"])
获取字段最大/小的 n 个值
# 获取年龄最大的两个值
user_info.age.nlargest(2)
# 获取年龄最小的两个值
user_info.age.nsmallest (2) """
注意:该方法比先排序再取head()或者tail()效率高
"""
函数应用
虽说 Pandas 为我们提供了非常丰富的函数,有时候我们可能需要自己定制一些函数,并将它应用到 DataFrame 或 Series。常用到的函数有: map 、 apply 、 applymap 。
map 方法
map 是 Series 中特有的方法,通过它可以对 Series 中的每个元素实现转换。
#通过年龄判断用户是否属于中年人(30岁以上为中年)
# 接收一个 lambda 函数
user_info.age.map(lambda x: "yes" if x >= 30 else "no")
"""
name
Tom no
Bob yes
Mary no
James yes
Name: age, dtype: object
""" # 通过城市来判断是南方还是北方
city_map = {
"BeiJing": "north",
"ShangHai": "south",
"GuangZhou": "south",
"ShenZhen": "south"
}
# 传入一个 map
user_info.city.map(city_map)
"""
name
Tom north
Bob south
Mary south
James south
Name: city, dtype: object
"""
apply方法
既支持 Series,也支持 DataFrame,在对 Series 操作时会作用到每个值上,在对DataFrame 操作时会作用到所有行或所有列(通过 axis 参数控制)
对 Series 来说,apply 方法 与 map 方法区别不大。
user_info.age.apply(lambda x: "yes" if x >= 30 else "no")
对 DataFrame 来说,apply 方法的作用对象是一行或一列数据(一个Series)
user_info.apply(lambda x: x.max(), axis=0)
"""
age 40
city ShenZhen
sex male
dtype: object
"""
applymap 方法
applymap 方法针对于 DataFrame,它作用于 DataFrame 中的每个元素,它对 DataFrame 的效果类似于 apply 对 Series 的效果
# .upper()将所有的英文字母大写
# .lower()将所有的英文字母小写
user_info.applymap(lambda x: str(x).upper())
"""
age city sex
name
Tom 23 BEIJING MALE
Bob 30 SHANGHAI MALE
Mary 25 GUANGZHOU FEMALE
James 40 SHENZHEN MALE
"""
修改列/ 索引名称
.rename ()
修改列
user_info.rename(columns={"age": "Age", "city": "City", "sex":
"Sex"})
修改索引
user_info.rename(index={"Tom": "tom", "Bob": "bob"})
类型操作
获取每种类型的列数
user_info.get_dtype_counts()
"""
int64 1
object 2
dtype: int64
"""
转换数据类型
user_info["age"].astype(float)
"""
name
Tom 23.0
Bob 30.0
Mary 25.0
James 40.0
Name: age, dtype: float64
"""
将 object 类型转为其他类型
object --> 数字 --> .to_numeric
object --> 日期 --> .to_datetime
object --> 时间差 --> .to_timedelta
#添加身高字段
user_info["height"] = ["", "", "", "180cm"]
"""
age city sex height
name
Tom 23 BeiJing male 178
Bob 30 ShangHai male 168
Mary 25 GuangZhou female 178
James 40 ShenZhen male 180cm
"""
"""
将身高这一列转为数字,很明显,180cm 并非数字,为了强制转换,我们可以传入 errors 参数,这个参数的作用是当强转失败时的处理方式。
默认情况下errors='raise':意味着强转失败后直接抛出异常
设置errors='coerce':可以在强转失败时将有问题的元素赋值为 pd.NaT(对于datetime或timedelta)或 np.nan(数字)
设置 errors='ignore':可以在强转失败时返回原有的数据。
""" pd.to_numeric(user_info.height, errors="coerce")
"""
name
Tom 178.0
Bob 168.0
Mary 178.0
James NaN
Name: height, dtype: float64
""" pd.to_numeric(user_info.height, errors="ignore")
"""
name
Tom 178
Bob 168
Mary 178
James 180cm
Name: height, dtype: object
"""
Pandas常用基本功能的更多相关文章
- NumPy和Pandas常用库
NumPy和Pandas常用库 1.NumPy NumPy是高性能科学计算和数据分析的基础包.部分功能如下: ndarray, 具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组. 用于对整组数 ...
- Pandas常用数据结构
Pandas 概述 Pandas(Python Data Analysis Library)是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数 ...
- (数据科学学习手札134)pyjanitor:为pandas补充更多功能
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 pandas发展了如此多年,所包含的功能已 ...
- RealView编译器常用特有功能(转)
源:RealView编译器常用特有功能 一. 关键字和运算符 1. __align(n):指示编译器在n 字节边界上对齐变量. 对于局部变量,n 值可为 1.2.4 或 8. 对于全局变量,n 可以具 ...
- pandas常用函数之shift
shift函数是对数据进行移动的操作,假如现在有一个DataFrame数据df,如下所示: index value1 A 0 B 1 C 2 D 3 那么如果执行以下代码: df.shift() 就会 ...
- pandas常用函数之diff
diff函数是用来将数据进行某种移动之后与原数据进行比较得出的差异数据,举个例子,现在有一个DataFrame类型的数据df,如下: index value1 A 0 B 1 C 2 D 3 如果执行 ...
- pandas的基本功能(一)
第16天pandas的基本功能(一) 灵活的二进制操作 体现在2个方面 支持一维和二维之间的广播 支持缺失值数据处理 四则运算支持广播 +add - sub *mul /div divmod()分区和 ...
- Impala系列: Impala常用的功能函数
--=======================查看内置的函数--=======================hive 不需要进入什么内置数据库, 即可使用 show functions 命令列出 ...
- pandas的筛选功能,跟excel的筛选功能类似,但是功能更强大。
Select rows from a DataFrame based on values in a column -pandas 筛选 https://stackoverflow.com/questi ...
随机推荐
- CSS动画,2D和3D模块
CSS3提供了丰富的动画类属性,使我们可以不通过flash甚至JavaScript,就能实现很多动态的效果.它们主要分为三大类:transform(变换),transition(过渡),animati ...
- php实现商城秒杀
这一次总结和分享用Redis实现分布式锁来完成电商的秒杀功能.先扯点个人观点,之前我看了一篇博文说博客园的文章大部分都是分享代码,博文里强调说分享思路比分享代码更重要(貌似大概是这个意思,若有误请谅解 ...
- [经验分享]C# 操作Windows系统计划任务
背景:我做了一个事情是要自己提前创建好很多要定时执行的任务,在我不在的时候自动执行这些程序,以保证我的工作能无人值守,那么我就需要建立系统计划任务来帮我完成这件事情,当然用脑子想想如何实现,很简单,每 ...
- Vue-懒加载(判断元素是否在可视区域内)
上公式: 元素距离顶部高度(elOffsetTop) >= dom滚动高度(docScrollTop) 并且元素距离顶部高度(elOffsetTop) < (dom滚动高度 + 视窗高度) ...
- Flex 布局——语法属性详解
前言 Flexbox 是 flexible box 的简称(注:意思是“灵活的盒子容器”),是 CSS3 引入的新的布局模式.它决定了元素如何在页面上排列,使它们能在不同的屏幕尺寸和设备下可预测地展现 ...
- zoj 3886 Nico Number
中文题面: 问题描述] 我们定义一个非负整数是“好数”,当且仅当它符合以下条件之一: 1. 这个数是0或1 2. 所有小于这个数且与它互质的正整数可以排成一个等差数列 例如,8就是一个好数,因为1,3 ...
- python selenium之Xpath定位
属性描述 XPath 语法支持节点描述,节点描述为一个逻辑真假表达式,任何真假判断表达式都可在节点后方括号里表示,这条件必须在XPath处理这个节点前先被满足.在某一步骤可有多少个描述并没有限制. 对 ...
- 2019年高级Java程序员面试题汇总
目录 JDK Dubbo Zookeeper Strut2 Spring系列 Redis系列 Mysql系列 Java多线程 消息中间件 线程池 事物 JVM 设计模式 其他 程序设计 基础知识 编程 ...
- [USACO10NOV]奶牛的图片Cow Photographs
题目描述 Farmer John希望给他的N(1<=N<=100,000)只奶牛拍照片,这样他就可以向他的朋友炫耀他的奶牛. 这N只奶牛被标号为1..N. 在照相的那一天,奶牛们排成了一排 ...
- std::multiset
Set.multiset都是集合类, 差别在与set中不允许有重复元素, multiset中允许有重复元素. sets和multiset内部以平衡二叉树实现. multiset 多重集合容器是一个 ...