spark集群搭建(三台虚拟机)——spark集群搭建(5)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下:
virtualBox5.2、Ubuntu14.04、securecrt7.3.6_x64英文版(连接虚拟机)
jdk1.7.0、hadoop2.6.5、zookeeper3.4.5、Scala2.12.6、kafka_2.9.2-0.8.1、spark1.3.1-bin-hadoop2.6
本文在前面基础上搭建spark
一、spark1
下面操作在spark1上:
1、spark(spark1.3.1-bin-hadoop2.6)下载解压重命名
2、配置环境变量
export SPARK_HOME=/usr/local/bigdata/spark
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
修改配置文件
1、spark-env.sh
$ cd ./spark/conf #进入spark的conf目录下
$ mv spark-env.sh.template spark-env.sh
$ vim spark-env.sh
添加如下配置
export JAVA_HOME=/usr/local/bigdata/jdk
export SCALA_HOME=/usr/local/bigdata/scala
export SPARK_MASTER_IP=192.168.43.XXX
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/usr/local/bigdata/hadoop/etc/hadoop
2、slaves
$ mv slaves.template slaves
$ vim slaves
添加三台主机名
spark1
spark2
spark3
二、spark2和spark3
1、拷贝spark到另外两台机器上
root@spark1:/usr/local/bigdata# scp -r spark root@spark2://usr/local/bigdata/
root@spark1:/usr/local/bigdata# scp -r spark root@spark3://usr/local/bigdata/
2、同理配置spark2和spark3的环境变量,或者直接把环境变量文件拷贝过去
三、启动spark
进入spark的sbin目录下,执行:
$ ./start-all.sh
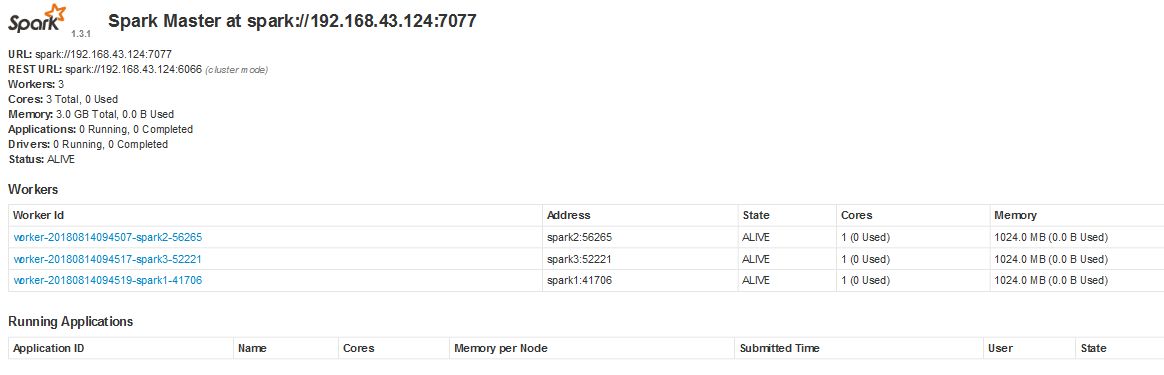
此时查看jps,spark1上有Master
root@spark1:/usr/local/bigdata/spark/sbin# jps
Worker
NodeManager
SecondaryNameNode
Jps
NameNode
Master
ResourceManager
DataNode
spark2
root@spark2:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
spark3
root@spark3:/usr/local/bigdata# jps
Jps
NodeManager
Worker
DataNode
浏览器输入http://spark1:8080/
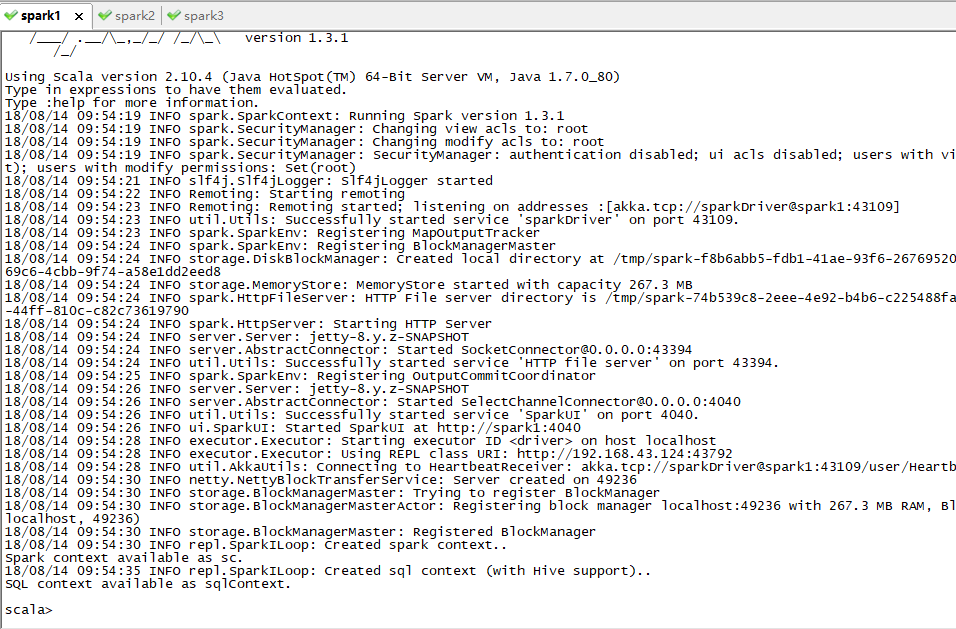
$ spark-shell #进入shell
spark集群搭建(三台虚拟机)——spark集群搭建(5)的更多相关文章
- Centos 7下VMware三台虚拟机Hadoop集群初体验
一.下载并安装Centos 7 传送门:https://www.centos.org/download/ 注:下载DVD ISO镜像 这里详解一下VMware安装中的两个过程 网卡配置 是Add ...
- spark集群搭建(三台虚拟机)——kafka集群搭建(4)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——zookeeper集群搭建(3)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——hadoop集群搭建(2)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- spark集群搭建(三台虚拟机)——系统环境搭建(1)
!!!该系列使用三台虚拟机搭建一个完整的spark集群,集群环境如下: virtualBox5.2.Ubuntu14.04.securecrt7.3.6_x64英文版(连接虚拟机) jdk1.7.0. ...
- AWS EC2 搭建 Hadoop 和 Spark 集群
前言 本篇演示如何使用 AWS EC2 云服务搭建集群.当然在只有一台计算机的情况下搭建完全分布式集群,还有另外几种方法:一种是本地搭建多台虚拟机,好处是免费易操控,坏处是虚拟机对宿主机配置要求较高, ...
- Spark学习之路(七)—— 基于ZooKeeper搭建Spark高可用集群
一.集群规划 这里搭建一个3节点的Spark集群,其中三台主机上均部署Worker服务.同时为了保证高可用,除了在hadoop001上部署主Master服务外,还在hadoop002和hadoop00 ...
- 用三台虚拟机搭建Hadoop全分布集群
用三台虚拟机搭建Hadoop全分布集群 所有的软件都装在/home/software下 虚拟机系统:centos6.5 jdk版本:1.8.0_181 zookeeper版本:3.4.7 hadoop ...
- 一台虚拟机,基于docker搭建大数据HDP集群
前言 好多人问我,这种基于大数据平台的xxxx的毕业设计要怎么做.这个可以参考之前写得关于我大数据毕业设计的文章.这篇文章是将对之前的毕设进行优化. 个人觉得可以分为两个部分.第一个部分就是基础的平台 ...
随机推荐
- MySQL生僻函数
0X01 字符串函数 STRCMP STRCMP(expr1,expr2) 若所有的字符串均相同,则返回STRCMP(),若根据当前分类次序,第一个参数小于第二个,则返回 -1,其它情况返回 1 . ...
- SQLMAP SSI注入错误解决
记一次SQL注入 目标地址:https://www.xxxx.com/ 之前补天提交过这个注入 后来貌似”修复了”(实际就是装了安全狗和过滤了一些关键字) 不过今天试了下 还是可以注入 可以看到已经 ...
- PHP pa和ma
<?php class Mouse { private $color; public $sex; public function __construct($role){ switch($role ...
- nginx::配置https/反向代理
vim /etc/nginx/nginx.conf user nginx; worker_processes ; error_log /var/log/nginx/error.log warn; pi ...
- php后端开发要学什么
PHP历史: 1994年创建,1995年对外发表第一个版本,名为:personal home page tools,之后发表PHP1.0.1995年中期,PHP2.0,从此建立了PHP在动态网站开发的 ...
- Docker卷
要解决的问题:在移除了现有容器或者添加了新容器时,之前容器的数据无法访问. 为避免上述问题,Docker提供了以下策略来持久化数据 tmpfs挂载 绑定挂载 卷 1.tmpfs挂载 2.绑定挂载 将D ...
- 高性能Web动画和渲染原理系列(3)——transform和opacity为什么高性能
示例代码托管在:http://www.github.com/dashnowords/blogs 博客园地址:<大史住在大前端>原创博文目录 华为云社区地址:[你要的前端打怪升级指南] [T ...
- springMVC初学简单例子
新建web项目,保留web.xml. 配置web.xml文件(/WEB-INF/下): <?xml version="1.0" encoding="UTF-8&qu ...
- Juc1024小半年总结-面试篇
大家好,我叫Juc 这大概是我时隔2年度多 第一次以分享的形式发的第一篇公众号 今天是2019年10月26 本想在10月24就分享一下 可惜前面两天时间太忙... 很凑巧,今天我出来工作刚好满4个月, ...
- java集合第一节,List简单介绍
Java中List集合的常用方法 List接口是继承Collection接口,所以Collection集合中有的方法,List集合也继承过来. package 集合; import java.ut ...