爬虫(四):requests模块
1. requests模块
1.1 requests简介
requests 是一个功能强大、简单易用的 HTTP 请求库,比起之前用到的urllib模块,requests模块的api更加便捷。(本质就是封装了urllib3)
可以使用pip install requests命令进行安装,但是很容易出网络问题,所以我找了下国内的镜像源来加速。
然后就找到了豆瓣的镜像源:
pip install 包名 -i http://pypi.douban.com/simple/ --trusted-host pypi.douban.com
只要将包名修改一下,就能快速下载模块了。
1.2 requests请求
请求方法有很多种,但是我们只讲最常用的两种:GET请求和POST请求。
1.2.1 GET请求
GET方法用于向目标网址发送请求,方法返回一个Response响应对象,Response下一小节详细讲解。
GET方法的参数:
url:必填,指定请求的URL
params:字典类型,指定请求参数,常用于发送GET请求时使用
例子:
import requests
url = 'http://www.httpbin.org/get'
params = {
'key1':'value1',
'key2':'value2'
}
response = requests.get(url=url,params=params)
print(response.text)
结果:

headers:字典类型,指定请求头部
例子:
import requests
url = 'http://www.httpbin.org/headers'
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
print(response.text)
结果:

proxies:字典类型,指定使用的代理
例子:
import requests
url = 'http://www.httpbin.org/ip'
proxies = {
'http':'113.116.127.164:8123',
'http':'113.116.127.164:80'
}
response = requests.get(url=url,proxies=proxies)
print(response.text)
结果:
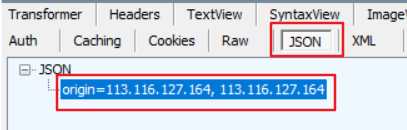
cookies:字典类型,指定Cookie
例子:
import requests
url = 'http://www.httpbin.org/cookies'
cookies = {
'name1':'value1',
'name2':'value2'
}
response = requests.get(url=url,cookies=cookies)
print(response.text)
结果:

auth:元组类型,指定登陆时的账号和密码
例子:
import requests
url = 'http://www.httpbin.org/basic-auth/user/password'
auth = ('user','password')
response = requests.get(url=url,auth=auth)
print(response.text)
结果:

verify:布尔类型,指定请求网站时是否需要进行证书验证,默认为 True,表示需要证书验证,假如不希望进行证书验证,则需要设置为False
import requests
response = requests.get(url='https://www.httpbin.org/',verify=False)
结果:

但是在这种情况下,一般会出现 Warning 提示,因为 Python 希望我们能够使用证书验证。
如果不希望看到 Warning 信息,可以使用以下命令消除:
import urllib3
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
timeout:指定超时时间,若超过指定时间没有获得响应,则抛出异常
1.2.2 POST请求
POST请求和GET请求的区别就是POST数据不会出现在地址栏,并且数据的大小没有上限。
所以GET的参数,POST差不多都可以使用, 除了params参数,POST使用data参数即可。
data:字典类型,指定表单信息,常用于发送 POST 请求时使用
例子:
import requests
url = 'http://www.httpbin.org/post'
data = {
'key1':'value1',
'key2':'value2'
}
response = requests.post(url=url,data=data)
print(response.text)
结果:

1.3 requests响应
1.3.1 response属性
使用GET或POST请求后,就会接收到response响应对象,其常用的属性和方法列举如下:
response.url:返回请求网站的 URL
response.status_code:返回响应的状态码
response.encoding:返回响应的编码方式
response.cookies:返回响应的 Cookie 信息
response.headers:返回响应头
response.content:返回 bytes 类型的响应体
response.text:返回 str 类型的响应体,相当于response.content.decode('utf-8')
response.json():返回 dict 类型的响应体,相当于json.loads(response.text)
import requests
response = requests.get('http://www.httpbin.org/get')
print(type(response))
# <class 'requests.models.Response'>
print(response.url) # 返回请求网站的 URL
# http://www.httpbin.org/get
print(response.status_code) # 返回响应的状态码
#
print(response.encoding) # 返回响应的编码方式
# None
print(response.cookies) # 返回响应的 Cookie 信息
# <RequestsCookieJar[]>
print(response.headers) # 返回响应头
# {'Access-Control-Allow-Credentials': 'true', 'Access-Control-Allow-Origin': '*', 'Content-Encoding': 'gzip', 'Content-Type': 'application/json', 'Date': 'Mon, 16 Dec 2019 03:16:22 GMT', 'Referrer-Policy': 'no-referrer-when-downgrade', 'Server': 'nginx', 'X-Content-Type-Options': 'nosniff', 'X-Frame-Options': 'DENY', 'X-XSS-Protection': '1; mode=block', 'Content-Length': '189', 'Connection': 'keep-alive'}
print(type(response.content))# 返回 bytes 类型的响应体
# <class 'bytes'>
print(type(response.text)) # 返回 str 类型的响应体
# <class 'str'>
print(type(response.json())) # 返回 dict 类型的响应体
# <class 'dict'>
1.3.2 编码问题
#编码问题
import requests
response=requests.get('http://www.autohome.com/news/')
# response.encoding='gbk' #汽车之家网站返回的页面内容为gb2312编码的,而requests的默认编码为ISO-8859-1,如果不设置成gbk则中文乱码
print(response.text)
爬虫(四):requests模块的更多相关文章
- 孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块
孤荷凌寒自学python第六十七天初步了解Python爬虫初识requests模块 (完整学习过程屏幕记录视频地址在文末) 从今天起开始正式学习Python的爬虫. 今天已经初步了解了两个主要的模块: ...
- Python爬虫练习(requests模块)
Python爬虫练习(requests模块) 关注公众号"轻松学编程"了解更多. 一.使用正则表达式解析页面和提取数据 1.爬取动态数据(js格式) 爬取http://fund.e ...
- 网络爬虫之requests模块的使用+Github自动登入认证
本篇博客将带领大家梳理爬虫中的requests模块,并结合Github的自动登入验证具体讲解requests模块的参数. 一.引入: 我们先来看如下的例子,初步体验下requests模块的使用: ...
- 爬虫之requests模块
requests模块 什么是requests模块 requests模块是python中原生的基于网络请求的模块,其主要作用是用来模拟浏览器发起请求.功能强大,用法简洁高效.在爬虫领域中占据着半壁江山的 ...
- 04.Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- 06.Python网络爬虫之requests模块(2)
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
- Python 爬虫二 requests模块
requests模块 Requests模块 get方法请求 整体演示一下: import requests response = requests.get("https://www.baid ...
- Python网络爬虫之requests模块(2)
session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 有些时候,我们在使用爬 ...
- Python网络爬虫之requests模块(1)
引入 Requests 唯一的一个非转基因的 Python HTTP 库,人类可以安全享用. 警告:非专业使用其他 HTTP 库会导致危险的副作用,包括:安全缺陷症.冗余代码症.重新发明轮子症.啃文档 ...
- Python网络爬虫之requests模块
今日内容 session处理cookie proxies参数设置请求代理ip 基于线程池的数据爬取 知识点回顾 xpath的解析流程 bs4的解析流程 常用xpath表达式 常用bs4解析方法 引入 ...
随机推荐
- 第四章 开始Unity Shader学习之旅(2)
目录 1. 强大的援手:Unity提供的内置文件和变量 1.1 内置的包含文件 1.2 内置的变量 2. Unity提供的Cg/HLSL语义 2.1 什么是语义 2.2 Unity支持的语义 2.3 ...
- obs命令行工具obsutil的使用测试
test1 批量复制,目标文件夹ggggg-zyx0809/data/tmp/a0文件夹已存在,不使用flat命令,目标路径包含a0文件夹 操作 从ggggg-zyx0809/data/g_cageg ...
- java抽象类,接口(接口定义,实现接口,instanceof运算符,对象转换)
抽象类 在面向对象的概念中,所有的对象都是通过类来表述的,但并不是所有的类都能够完整的描绘对象,如果一个类中没有包含足够的信息来描绘一类具体的对象,这样的类就是抽象类.抽象类往往用来表征对问题领域进行 ...
- 二叉树的建立&&前中后遍历(递归实现)&&层次遍历
下面代码包含了二叉树的建立过程,以及三种遍历方法了递归实现,代码中还利用队列实现了层次遍历. import java.util.LinkedList; import java.util.Queue; ...
- Codeforces 题解 CF863A 【Quasi-palindrome】
此题本质上是:求一个数去掉后缀零后是否是回文串 因此,代码分为: >>> 读入 >>> 删除后缀0 >>> 判断回文 >>> 转 ...
- HashMap的常见问题
关于HashMap的一些常见的问题,自己总结一下: 首选HashMap在jdk1.7和jdk1.8里面的实现是不同的,在jdk1.7中HashMap的底层实现是通过数组+链表的形式实现的,在jdk1. ...
- 快速掌握zabbix配置
有人说zabbix难点在配置,面对很多的配置项,不知道所以然了,其实我觉得这是没掌握好zabbix的学习方法,要掌握了zabbix的学习思路,可以在一个小时内快速掌握zabbix的各种配置,下面我将重 ...
- 《吊打面试官》系列-ConcurrentHashMap & HashTable
你知道的越多,你不知道的越多 点赞再看,养成习惯 本文 GitHub https://github.com/JavaFamily 已收录,有一线大厂面试点思维导图,也整理了很多我的文档,欢迎Star和 ...
- PHP7 break和continue的区别
break:结束当前 for,foreach,while,do-while 或者 switch 结构的执行. continue:在循环结构用用来跳过本次循环中剩余的代码并在条件求值为真时开始执行下一次 ...
- linux 各目录 常用用处
/bin : 存储常 用用户指令 /boot : 存储 核心.模块 映像等启 动用文件/dev : 存储 设备文件/etc : 存储 系统. 服 务的配置目录 与 文件/home : 存放 个人主目录 ...