不就是SELECT COUNT语句吗,竟然能被面试官虐的体无完肤
数据库查询相信很多人都不陌生,所有经常有人调侃程序员就是CRUD专员,这所谓的CRUD指的就是数据库的增删改查。
在数据库的增删改查操作中,使用最频繁的就是查询操作。而在所有查询操作中,统计数量操作更是经常被用到。
关于数据库中行数统计,无论是MySQL还是Oracle,都有一个函数可以使用,那就是COUNT。
但是,就是这个常用的COUNT函数,却暗藏着很多玄机,尤其是在面试的时候,一不小心就会被虐。不信的话请尝试回答下以下问题:
1、COUNT有几种用法?
2、COUNT(字段名)和COUNT(*)的查询结果有什么不同?
3、COUNT(1)和COUNT(*)之间有什么不同?
4、COUNT(1)和COUNT(*)之间的效率哪个更高?
5、为什么《阿里巴巴Java开发手册》建议使用COUNT(*)
6、MySQL的MyISAM引擎对COUNT(*)做了哪些优化?
7、MySQL的InnoDB引擎对COUNT(*)做了哪些优化?
8、上面提到的MySQL对COUNT(*)做的优化,有一个关键的前提是什么?
9、SELECT COUNT(*) 的时候,加不加where条件有差别吗?
10、COUNT(*)、COUNT(1)和COUNT(字段名)的执行过程是怎样的?
以上10道题,如果您可以全部准确无误的回答的话,那说明你真的很了解COUNT函数了,如果有哪些知识点是不了解的,那么本文正好可以帮你答疑解惑。
认识COUNT
关于COUNT函数,在MySQL官网中有详细介绍:
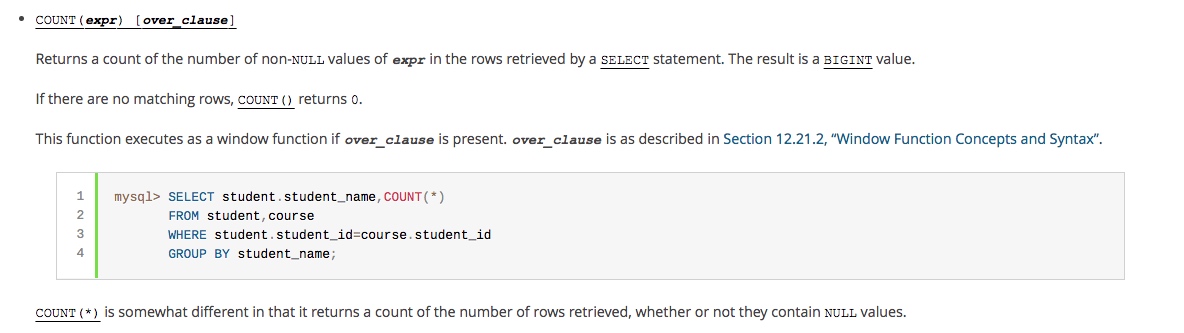
简单翻译一下:
1、COUNT(expr) ,返回SELECT语句检索的行中expr的值不为NULL的数量。结果是一个BIGINT值。
2、如果查询结果没有命中任何记录,则返回0
3、但是,值得注意的是,COUNT(*) 的统计结果中,会包含值为NULL的行数。
即以下表记录
create table #bla(id int,id2 int)
insert #bla values(null,null)
insert #bla values(1,null)
insert #bla values(null,1)
insert #bla values(1,null)
insert #bla values(null,1)
insert #bla values(1,null)
insert #bla values(null,null)
使用语句count(*),count(id),count(id2)查询结果如下:
select count(*),count(id),count(id2)
from #bla
results 7 3 2
除了COUNT(id)和COUNT(*)以外,还可以使用COUNT(常量)(如COUNT(1))来统计行数,那么这三条SQL语句有什么区别呢?到底哪种效率更高呢?为什么《阿里巴巴Java开发手册》中强制要求不让使用 COUNT(列名)或 COUNT(常量)来替代 COUNT(*)呢?

COUNT(列名)、COUNT(常量)和COUNT(*)之间的区别
前面我们提到过COUNT(expr)用于做行数统计,统计的是expr不为NULL的行数,那么COUNT(列名)、 COUNT(常量) 和 COUNT(*)这三种语法中,expr分别是列名、 常量 和 *。
那么列名、 常量 和 *这三个条件中,常量 是一个固定值,肯定不为NULL。*可以理解为查询整行,所以肯定也不为NULL,那么就只有列名的查询结果有可能是NULL了。
所以, COUNT(常量) 和 COUNT(*)表示的是直接查询符合条件的数据库表的行数。而COUNT(列名)表示的是查询符合条件的列的值不为NULL的行数。
除了查询得到结果集有区别之外,COUNT(*)相比COUNT(常量) 和 COUNT(列名)来讲,COUNT(*)是SQL92定义的标准统计行数的语法,因为他是标准语法,所以MySQL数据库对他进行过很多优化。
SQL92,是数据库的一个ANSI/ISO标准。它定义了一种语言(SQL)以及数据库的行为(事务、隔离级别等)。
COUNT(*)的优化
前面提到了COUNT(*)是SQL92定义的标准统计行数的语法,所以MySQL数据库对他进行过很多优化。那么,具体都做过哪些事情呢?
这里的介绍要区分不同的执行引擎。MySQL中比较常用的执行引擎就是InnoDB和MyISAM。
MyISAM和InnoDB有很多区别,其中有一个关键的区别和我们接下来要介绍的COUNT(*)有关,那就是MyISAM不支持事务,MyISAM中的锁是表级锁;而InnoDB支持事务,并且支持行级锁。
因为MyISAM的锁是表级锁,所以同一张表上面的操作需要串行进行,所以,MyISAM做了一个简单的优化,那就是它可以把表的总行数单独记录下来,如果从一张表中使用COUNT(*)进行查询的时候,可以直接返回这个记录下来的数值就可以了,当然,前提是不能有where条件。
MyISAM之所以可以把表中的总行数记录下来供COUNT(*)查询使用,那是因为MyISAM数据库是表级锁,不会有并发的数据库行数修改,所以查询得到的行数是准确的。
但是,对于InnoDB来说,就不能做这种缓存操作了,因为InnoDB支持事务,其中大部分操作都是行级锁,所以可能表的行数可能会被并发修改,那么缓存记录下来的总行数就不准确了。
但是,InnoDB还是针对COUNT(*)语句做了些优化的。
在InnoDB中,使用COUNT(*)查询行数的时候,不可避免的要进行扫表了,那么,就可以在扫表过程中下功夫来优化效率了。
从MySQL 8.0.13开始,针对InnoDB的SELECT COUNT(*) FROM tbl_name语句,确实在扫表的过程中做了一些优化。前提是查询语句中不包含WHERE或GROUP BY等条件。
我们知道,COUNT(*)的目的只是为了统计总行数,所以,他根本不关心自己查到的具体值,所以,他如果能够在扫表的过程中,选择一个成本较低的索引进行的话,那就可以大大节省时间。
我们知道,InnoDB中索引分为聚簇索引(主键索引)和非聚簇索引(非主键索引),聚簇索引的叶子节点中保存的是整行记录,而非聚簇索引的叶子节点中保存的是该行记录的主键的值。
所以,相比之下,非聚簇索引要比聚簇索引小很多,所以MySQL会优先选择最小的非聚簇索引来扫表。所以,当我们建表的时候,除了主键索引以外,创建一个非主键索引还是有必要的。
至此,我们介绍完了MySQL数据库对于COUNT(*)的优化,这些优化的前提都是查询语句中不包含WHERE以及GROUP BY条件。
COUNT(*)和COUNT(1)
介绍完了COUNT(*),接下来看看COUNT(1),对于,这二者到底有没有区别,网上的说法众说纷纭。
有的说COUNT(*)执行时会转换成COUNT(1),所以COUNT(1)少了转换步骤,所以更快。
还有的说,因为MySQL针对COUNT(*)做了特殊优化,所以COUNT(*)更快。
那么,到底哪种说法是对的呢?看下MySQL官方文档是怎么说的:
InnoDB handles SELECT COUNT(*) and SELECT COUNT(1) operations in the same way. There is no performance difference.
画重点:same way , no performance difference。所以,对于COUNT(1)和COUNT(*),MySQL的优化是完全一样的,根本不存在谁比谁快!
那既然COUNT(*)和COUNT(1)一样,建议用哪个呢?
建议使用COUNT(*)!因为这个是SQL92定义的标准统计行数的语法,而且本文只是基于MySQL做了分析,关于Oracle中的这个问题,也是众说纷纭的呢。
COUNT(字段)
最后,就是我们一直还没提到的COUNT(字段),他的查询就比较简单粗暴了,就是进行全表扫描,然后判断指定字段的值是不是为NULL,不为NULL则累加。
相比COUNT(*),COUNT(字段)多了一个步骤就是判断所查询的字段是否为NULL,所以他的性能要比COUNT(*)慢。
总结
本文介绍了COUNT函数的用法,主要用于统计表行数。主要用法有COUNT(*)、COUNT(字段)和COUNT(1)。
因为COUNT(*)是SQL92定义的标准统计行数的语法,所以MySQL对他进行了很多优化,MyISAM中会直接把表的总行数单独记录下来供COUNT(*)查询,而InnoDB则会在扫表的时候选择最小的索引来降低成本。当然,这些优化的前提都是没有进行where和group的条件查询。
在InnoDB中COUNT(*)和COUNT(1)实现上没有区别,而且效率一样,但是COUNT(字段)需要进行字段的非NULL判断,所以效率会低一些。
因为COUNT(*)是SQL92定义的标准统计行数的语法,并且效率高,所以请直接使用COUNT(*)查询表的行数!
参考资料:
https://dev.mysql.com/doc/refman/8.0/en/group-by-functions.html#function_count
《极客时间——MySQL实战45讲》
不就是SELECT COUNT语句吗,竟然能被面试官虐的体无完肤的更多相关文章
- SELECT COUNT语句
数据库查询相信很多人都不陌生,所有经常有人调侃程序员就是CRUD专员,这所谓的CRUD指的就是数据库的增删改查. 在数据库的增删改查操作中,使用最频繁的就是查询操作.而在所有查询操作中,统计数量操作更 ...
- select count的优化
select count的优化 2011-08-02 12:01:36 分类: Oracle 一般情况下,select count语句很难避免走全表扫描,对于上百万行的表这个语句使用起来就比较吃力了, ...
- SQL-49 针对库中的所有表生成select count(*)对应的SQL语句
题目描述 针对库中的所有表生成select count(*)对应的SQL语句CREATE TABLE `employees` (`emp_no` int(11) NOT NULL,`birth_dat ...
- SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好?
SQLSERVER 里SELECT COUNT(1) 和SELECT COUNT(*)哪个性能好? 今天遇到某人在我以前写的一篇文章里问到 如果统计信息没来得及更新的话,那岂不是统计出来的数据时错误的 ...
- select count(*)和select count(1)哪个性能高
select count(*).count(数字).count(字段名)在相同的条件下是没有性能差别的,一般我们在统计行数的时候都会把NULL值统计在内的,所以这样的话,最好就是使用COUNT(*) ...
- select count(distinct a)
我想对一个表里面字段a的个数进行进行统计,因为字段a有重复的记录,我想排除重复的记录,该sql语句为: select count(distinct a) 链接:http://www.w3school. ...
- mysql下的SELECT INTO语句
在mysql下使用SELECT INTO语句会产生ERROR 1327 (42000): Undeclared variable:new_tablename 此时要使用: CREATE TABLE C ...
- select count(*) 底层究竟做了什么?
阅读本文大概需要 6.6 分钟. SELECT COUNT( * ) FROM t是个再常见不过的 SQL 需求了.在 MySQL 的使用规范中,我们一般使用事务引擎 InnoDB 作为(一般业务)表 ...
- [Oracle] “表中有数据,但select count(*)的结果为0”问题的解决办法
一.问题 今天遇到了一个神奇的问题--表中有数据,但select count(*)的结果为0. 这个问题最初的表现形式是"查询报表没有分页". 最开始还以为是java端的问题.后来 ...
随机推荐
- 初始mqtt服务
MQTT入门 概念 mqtt意为消息队列遥测传输,是IBM开发的一个即时通讯协议.由于其维护一个长连接以轻量级低消耗著称,所以常用于移动端消息推送服务开发. 协议格式 mqtt协议控制报文的格式包含三 ...
- 高级部分_委托、Lambda表达式、事件
委托 (1)把方法当作参数来传递的话,就要用到委托: (2)委托是一个类型,这个类型可以赋值一个方法的引用. C#使用一个类分为两个阶段,首先定义这个类,告诉编译器这个类由什么字段和方法组成:然后使用 ...
- 深入理解three.js中平面光光源RectAreaLight
前言 之前有深入讲解过Three.js中光源,在那篇文章的最后也说了由于平面光光源的特殊性,所以会单独拿出来讲解,这篇文章会详细的讲解平面光光源的特性和实际应用该如何使用. 首先,平面光光源从一个矩形 ...
- NTP服务器实现
时间服务器是一种计算机网络仪器,它从参考时钟获取实际时间,再利用计算机网络把时间信息传递给用户.虽然还有一些比较少用或过时的协议仍然在使用,但现时最重要及广泛使用,作为时间信息发送和同步化的协议是网络 ...
- 新建web工程
1.选择新建Dynamic Web Project 2.选择服务器和版本(2.5) 3.WebContend目录下新建一个html文件 4.运行 工程的目录结构: WEB-INF目录时受保护的,不能 ...
- 初识数据库(MySql)
一.简介 1.MySql是关系型数据库. 2.是一种开放源码软件, 3.是一种关联数据库管理系统. 4.服务器工作于客户端/服务端模式之下,或者是嵌入系统中. 数据库管理软件分类: 分两大类: 关系型 ...
- 我用数据结构花了一夜给女朋友写了个h5走迷宫小游戏
目录 起因 分析 画线(棋盘) 画迷宫 方块移动 结语 @(文章目录) 先看效果图(在线电脑尝试地址http://biggsai.com/maze.html): 起因 又到深夜了,我按照以往在公众号写 ...
- EF指定更新字段
使用EF做更新时,若没有进行跟踪会默认全字段更新,那怎么做到只更新我们想要更新的字段呢? /// <summary> /// 修改指定属性的单条数据 /// </summary> ...
- python接口测试(post,get)-传参(data和json之间的区别)
python接口测试如何正确传参: POST 传data:data是python字典格式:传参data=json.dumps(data)是字符串类型传参 #!/usr/bin/env python3 ...
- 排列组合算法的Java实现
转载于:http://cgs1999.iteye.com/blog/2327664