小匠第一周期打卡笔记-Task01
一、线性回归
知识点记录
线性回归输出是一个连续值,因此适用于回归问题。如预测房屋价格、气温、销售额等连续值的问题。是单层神经网络。
线性判别模型
判别模型
性质:建模预测变量和观测变量之间的关系,亦称作条件模型
分类:确定性判别模型:y=fθ(x)
概率判别模型:pθ(y|x)
线性判别模型(linear regression)
y=fθ(x)= θo +【(d,i=1),加和】θjxj = θTx ,x= (x1,x2,x3,...,xd)
学习目标:
使预测值和真实值的距离越近越好, min 1((【N,i=1】)加和)&(yi,fθ(xi)))/N
损失函数:&(yi,fθ(xi))测量预测值与真实值之间的误差,越小越好(方差最小),
具体损失函数的定义依赖于具体数据和任务
最广泛使用的损失的回归函数:平方误差(squared loss),&(yi,fθ(xi)) = 1(yi-fθ(xi))*(yi-fθ(xi))/2
最小均方误差回归
优化目标是最小化训练数据上的均方误差 jθ = 1(【N,i=1】加和)(yi -fθ(xi))*(yi -fθ(xi))/2N min jθ
模型:
假设价格只取决于房屋状况的面积和房龄因素,加下来探索价格与此俩因素具体关系。线性回归假设输出与各个输入之间是线性关系: price = warea · area + wage · age + b
数据集:
收集一些真实数据(多栋房屋真实售价和它们对应的面积和房龄。我们在此数据上寻找模型参数是模型的预测价格与真实价格的误差最小,称为:训练数据集或者训练集,一栋房屋称为一个样本,真实售价叫做标签,用于预测的因素叫特征,特征用来表征样本的特点。
优化函数-随机梯度下降:
当模型和损失函数形式较为简单时,上面的误差最小化问题的解可以直接用公式表达出来。这类解叫作解析解,大多数深度学习模型并没有解析解,只能通过优化算法有限次迭代模型参数来尽可能降低损失函数的值。这类解叫作数值解。
总结一下,优化函数的有以下两个步骤:
- (i)初始化模型参数,一般来说使用随机初始化;
- (ii)我们在数据上迭代多次,通过在负梯度方向移动参数来更新每个参数
模型实例:线性回归从零实现
# import packages and modules
%matplotlib inline
import torch
from IPython import display
from matplotlib import pyplot as plt
import numpy as np
import random print(torch.__version__)
生成数据集:
使用线性模型来生成数据集,生成一个1000样本的数据集,下面是用力来生成数据的线性关系:
price = warea · area + wage · age +b
# set input feature number
num_inputs = 2
# set example number
num_examples = 1000 # set true weight and bias in order to generate corresponded label
true_w = [2, -3.4]
true_b = 4.2 features = torch.randn(num_examples, num_inputs,
dtype=torch.float32)
labels = true_w[0] * features[:, 0] + true_w[1] * features[:, 1] + true_b
labels += torch.tensor(np.random.normal(0, 0.01, size=labels.size()),
dtype=torch.float32)
使用图像来展示生成的数据:
plt.scatter(features[:,1].numpy(), labels.numpy(), 1);
读取数据集:
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
random.shuffle(indices) # random read 10 samples
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)]) # the last time may be not enough for a whole batch
yield features.index_select(0, j), labels.index_select(0, j)
batch_size = 10 for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
break
初始化模型参数:
w = torch.tensor(np.random.normal(0, 0.01, (num_inputs, 1)), dtype=torch.float32)
b = torch.zeros(1, dtype=torch.float32) w.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
定义模型:
定义用来训练参数的训练模型: price = warea · area + wage · age +b
def linreg(X, w, b):
return torch.mm(X, w) + b
定义损失函数:
使用均方误差损失函数: l(i)(w,b) = 1(ˆy帽(i)-y(i))2
def squared_loss(y_hat, y):
return (y_hat - y.view(y_hat.size())) ** 2 / 2
定义优化函数:
使用小批量随机梯度下降: (w,b)← (w,b) - 【η·∑i∂(w,b)l(i)(w,b)】/|β|
def sgd(params, lr, batch_size):
for param in params:
param.data -= lr * param.grad / batch_size # ues .data to operate param without gradient track
训练:
当数据集、模型、损失函数和优化函数定义之后即可以准备进行模型训练
# super parameters init
lr = 0.03
num_epochs = 5 net = linreg
loss = squared_loss # training
for epoch in range(num_epochs): # training repeats num_epochs times
# in each epoch, all the samples in dataset will be used once # X is the feature and y is the label of a batch sample
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y).sum()
# calculate the gradient of batch sample loss
l.backward()
# using small batch random gradient descent to iter model parameters
sgd([w, b], lr, batch_size)
# reset parameter gradient
w.grad.data.zero_()
b.grad.data.zero_()
train_l = loss(net(features, w, b), labels)
print('epoch %d, loss %f' % (epoch + 1, train_l.mean().item()))
w, true_w, b, true_b
小结:
- 和大多数深度学习模型一样,对于线性回归这样一种单层神经网络,它的基本要素包括模型、训练数据、损失函数和优化算法。
- 既可以用神经网络图表示线性回归,又可以用矢量计算表示该模型。
- 应该尽可能采用矢量计算,以提升计算效率。
二、softmax和分类模型
与回归问题不同,分类问题中模型的最终输出是一个离散值,我们所说的图像分类,垃圾邮件识别,疾病监测等输出为离散值的问题都属于分类问题的范畴。softmax回归则适用于分类问题。也是单层神经网络。
softmax基本概念:
分类问题
图像分类:
输入的图像高宽均为2像素,色彩为灰度。图像的4像素分别记为x1,x2,x3,x4。
假设真实值标签为猫、狗或鸡,这些标签对应离散值为y1,y2,y3。
权重矢量
o1 = x1w11 + x2w21 + x3w31 + x4w41 + b1
o2 = x2w12 + x2w22 + x3w22 + x4w42 + b2
o3 = x3w13 + x2w23 + x3w33 + x4w43 + b3
神经网络图
每个输出o1,o2,o3计算都要依赖于所有的输入x1,x2,x3,x4,softmax回归输出层也是一个全连接层
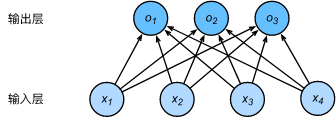
将输出值oi当预测类别是i的置信度,并将最大的输出所对应的类作为预测输出(argimaxoi)。
输出:
softmax通过【ˆy1,ˆy2,ˆy3 = softmax(o1,o2,o3)】将输出值变为值为正且和为1的概率分布。其中,ˆy1 =
ˆy3 =
模型训练和预测
在训练好softmax回归模型后,给定任一样本特征,就可以预测每个输出类别的概率。通常,我们把预测概率最大的类别作为输出类别。如果它与真实类别(标签)一致,说明这次预测是正确的。在3.6节的实验中,我们将使用准确率(accuracy)来评价模型的表现。它等于正确预测数量与总预测数量之比。
获取Fashion-MNIST训练集和读取数据
softmax从零开始实现
import torch
import torchvision
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l print(torch.__version__)
print(torchvision.__version__)
获取训练集数据和测试集数据
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, root='/home/kesci/input/FashionMNIST2065')
模型参数初始化
num_inputs = 784
print(28*28)
num_outputs = 10 W = torch.tensor(np.random.normal(0, 0.01, (num_inputs, num_outputs)), dtype=torch.float)
b = torch.zeros(num_outputs, dtype=torch.float
W.requires_grad_(requires_grad=True)
b.requires_grad_(requires_grad=True)
对多维Tensor按维度操作
X = torch.tensor([[1, 2, 3], [4, 5, 6]])
print(X.sum(dim=0, keepdim=True)) # dim为0,按照相同的列求和,并在结果中保留列特征
print(X.sum(dim=1, keepdim=True)) # dim为1,按照相同的行求和,并在结果中保留行特征
print(X.sum(dim=0, keepdim=False)) # dim为0,按照相同的列求和,不在结果中保留列特征
print(X.sum(dim=1, keepdim=False)) # dim为1,按照相同的行求和,不在结果中保留行特征
定义softmax操作 ˆyj = exp(oj) ⁄ ∑ 3i=1 exp(oi)
def softmax(X):
X_exp = X.exp()
partition = X_exp.sum(dim=1, keepdim=True)
# print("X size is ", X_exp.size())
# print("partition size is ", partition, partition.size())
return X_exp / partition # 这里应用了广播机制
X = torch.rand((2, 5))
X_prob = softmax(X)
print(X_prob, '\n', X_prob.sum(dim=1))
softmax回归模型 o(i) = x(i) W + b , ˆy(i) = softmax(o(i)).
def net(X):
return softmax(torch.mm(X.view((-1, num_inputs)), W) + b)
定义损失函数
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]])
y = torch.LongTensor([0, 2])
y_hat.gather(1, y.view(-1, 1))
def cross_entropy(y_hat, y):
return - torch.log(y_hat.gather(1, y.view(-1, 1)))
定义准确率
def accuracy(y_hat, y):
return (y_hat.argmax(dim=1) == y).float().mean().item()
print(accuracy(y_hat, y))
# 本函数已保存在d2lzh_pytorch包中方便以后使用。该函数将被逐步改进:它的完整实现将在“图像增广”一节中描述
def evaluate_accuracy(data_iter, net):
acc_sum, n = 0.0, 0
for X, y in data_iter:
acc_sum += (net(X).argmax(dim=1) == y).float().sum().item()
n += y.shape[0]
return acc_sum / n
print(evaluate_accuracy(test_iter , net))
训练模型
num_epochs, lr = 5, 0.1 # 本函数已保存在d2lzh_pytorch包中方便以后使用
def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
params=None, lr=None, optimizer=None):
for epoch in range(num_epochs):
train_l_sum, train_acc_sum, n = 0.0, 0.0, 0
for X, y in train_iter:
y_hat = net(X)
l = loss(y_hat, y).sum() # 梯度清零
if optimizer is not None:
optimizer.zero_grad()
elif params is not None and params[0].grad is not None:
for param in params:
param.grad.data.zero_() l.backward()
if optimizer is None:
d2l.sgd(params, lr, batch_size)
else:
optimizer.step() train_l_sum += l.item()
train_acc_sum += (y_hat.argmax(dim=1) == y).sum().item()
n += y.shape[0]
test_acc = evaluate_accuracy(test_iter, net)
print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
% (epoch + 1, train_l_sum / n, train_acc_sum / n, test_acc)) train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, batch_size, [W, b], lr)
模型预测
模型训练完进行一下预测。演示如何对图像进行分类。给定一系列图像(第三行图像输出),比较一下它们的真实标签(第一行文本输出)和模型预测结果(第二行文本输出)。
X, y = iter(test_iter).next() true_labels = d2l.get_fashion_mnist_labels(y.numpy())
pred_labels = d2l.get_fashion_mnist_labels(net(X).argmax(dim=1).numpy())
titles = [true + '\n' + pred for true, pred in zip(true_labels, pred_labels)] d2l.show_fashion_mnist(X[0:9], titles[0:9])
- 可以使用softmax回归做多类别分类。与训练线性回归相比,你会发现训练softmax回归的步骤和它非常相似:获取并读取数据、定义模型和损失函数并使用优化算法训练模型。事实上,绝大多数深度学习模型的训练都有着类似的步骤。
三、多层感知机
知识点记录
在深度学习中主要关注多层模型,线性回归和softmax回归是单层神经网络,多层感知机是多层神经网络
隐藏层
多层感知机在单层神经网络的基础上引入了一道多的隐藏层,位于输入层和输出层之间。
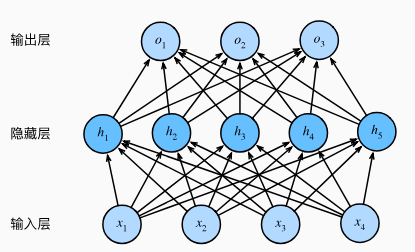 其中含有一个隐藏层,该层中有5个隐藏单元。输入层不涉及计算,所以图所示感知机层数为2.隐藏层中的神经元和输入层中的各个输入完全链接,输出层中的神经元和隐藏层中的各个神经元也完全连接,因此,多层感知机中的隐藏层和输出层都是全连接层。
其中含有一个隐藏层,该层中有5个隐藏单元。输入层不涉及计算,所以图所示感知机层数为2.隐藏层中的神经元和输入层中的各个输入完全链接,输出层中的神经元和隐藏层中的各个神经元也完全连接,因此,多层感知机中的隐藏层和输出层都是全连接层。

由式子看出,神经网络引入了隐藏层,依然等价于一个单层神经网络:其中输出权重参数为WhWo,偏差参数为bhWo + bo
激活函数
多层感知机
含有至少一个隐藏层的由全连接层组成的神经网络,且每个隐藏层的输出通过记过函数进行变换。多层感知机的层数和各隐藏层中隐藏单元个数都是超参数。以单隐藏层为例:H =Ø(XWh + bh), O = HWo +bo ,
小结
- 多层感知机在输出层与输入层之间加入了一个或多个全连接隐藏层,并通过激活函数对隐藏层输出进行变换。
- 常用的激活函数包括ReLU函数、sigmoid函数和tanh函数。
import torch
import numpy as np
import sys
sys.path.append("/home/kesci/input")
import d2lzh1981 as d2l
print(torch.__version__)
获取训练集
batch_size =
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size,root='/home/kesci/input/FashionMNIST2065')
num_inputs, num_outputs, num_hiddens = , , W1 = torch.tensor(np.random.normal(, 0.01, (num_inputs, num_hiddens)), dtype=torch.float)
b1 = torch.zeros(num_hiddens, dtype=torch.float)
W2 = torch.tensor(np.random.normal(, 0.01, (num_hiddens, num_outputs)), dtype=torch.float)
b2 = torch.zeros(num_outputs, dtype=torch.float) params = [W1, b1, W2, b2]
for param in params:
param.requires_grad_(requires_grad=True)
定义激活函数
def relu(X):
return torch.max(input = X, other=torch.tensor(,))
定义网络
def net(X):
X = X.view((-, num_inputs))
H = relu(torch.matmul(X, W1) + b1)
return torch.matmul(H, W2) + b2
1 loss = torch.nn.CrossEntropyLoss()
训练
num_epochs, lr = , 100.0
# def train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size,
# params=None, lr=None, optimizer=None):
# for epoch in range(num_epochs):
# train_l_sum, train_acc_sum, n = 0.0, 0.0,
# for X, y in train_iter:
# y_hat = net(X)
# l = loss(y_hat, y).sum()
#
# # 梯度清零
# if optimizer is not None:
# optimizer.zero_grad()
# elif params is not None and params[].grad is not None:
# for param in params:
# param.grad.data.zero_()
#
# l.backward()
# if optimizer is None:
# d2l.sgd(params, lr, batch_size)
# else:
# optimizer.step() # “softmax回归的简洁实现”一节将用到
#
#
# train_l_sum += l.item()
# train_acc_sum += (y_hat.argmax(dim=) == y).sum().item()
# n += y.shape[]
# test_acc = evaluate_accuracy(test_iter, net)
# print('epoch %d, loss %.4f, train acc %.3f, test acc %.3f'
# % (epoch + , train_l_sum / n, train_acc_sum / n, test_acc)) d2l.train_ch3(net, train_iter, test_iter, loss, num_epochs, batch_size, params, lr)
小匠第一周期打卡笔记-Task01的更多相关文章
- 小匠第一周期打卡笔记-Task02
一.文本预处理 预处理通常包括四个步骤: 读入文本 分词 建立字典,将每个词映射到一个唯一的索引(index) 将文本从词的序列转换为索引的序列,方便输入模型 读入文本: import collect ...
- 小匠第二周期打卡笔记-Task05
一.卷积神经网络基础 知识点记录: 神经网络的基础概念主要是:卷积层.池化层,并解释填充.步幅.输入通道和输出通道之含义. 二维卷积层: 常用于处理图像数据,将输入和卷积核做互相关运算,并加上一个标量 ...
- 小匠第二周期打卡笔记-Task03
一.过拟合欠拟合及其解决方案 知识点记录 模型选择.过拟合和欠拟合: 训练误差和泛化误差: 训练误差 :模型在训练数据集上表现出的误差, 泛化误差 : 模型在任意一个测试数据样本上表现出的误差的期望, ...
- 小匠第二周期打卡笔记-Task04
一.机器翻译及相关技术 机器翻译(MT):将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经网络翻译(NMT). 主要特征:输出是单词序列而不是单个单词.输出序列的长度可能与 ...
- 《Linux内核设计与实现》 第一二章学习笔记
<Linux内核设计与实现> 第一二章学习笔记 第一章 Linux内核简介 1.1 Unix的历史 Unix的特点 Unix很简洁,所提供的系统调用都有很明确的设计目的. Unix中一切皆 ...
- 微信小程序生命周期详解
文章出处:https://blog.csdn.net/qq_29712995/article/details/79784222 在我看来小程序的生命周期虽然简单,但是他渗透了小程序开发的整个过程,对于 ...
- 自定义View4-塔防小游戏第一篇:一个防御塔+多个野怪(简易版)*
塔防小游戏 第一篇:一个防御塔+多个野怪(简易版) 1.canvas画防御塔,妖怪大道,妖怪行走路线 2.防御塔攻击范围是按照妖怪与防御塔中心距离计算的,大于防御塔半径则不攻击,小于则攻击 ...
- 微信小程序消息通知-打卡考勤
微信小程序消息通知-打卡考勤 效果: 稍微改一下js就行,有不必要的错误,我就不改了,哈哈! index.js //index.js const app = getApp() // 填写微信小程序ap ...
- 微信小程序生命周期——小程序的生命周期及页面的生命周期。
最近在做微信小程序开发,也发现一些坑,分享一下自己踩过的坑. 生命周期是指一个小程序从创建到销毁的一系列过程. 在小程序中 ,通过App()来注册一个小程序 ,通过Page()来注册一个页面. 首先来 ...
随机推荐
- 2020牛客寒假算法基础集训营4-D子段异或
思路 CODE #include <bits/stdc++.h> #define dbg(x) cout << #x << "=" <&l ...
- 深入浅出Mybatis系列五-TypeHandler简介及配置(mybatis源码篇)
注:本文转载自南轲梦 注:博主 Chloneda:个人博客 | 博客园 | Github | Gitee | 知乎 上篇文章<深入浅出Mybatis系列(四)---配置详解之typeAliase ...
- 基于EFCore3.0+Dapper 封装Repository
Wei.Repository 基于EFCore3.0+Dapper 封装Repository,实现UnitOfWork,提供基本的CURD操作,可直接注入泛型Repository,也可以继承Repos ...
- CSS的模板资源+编辑图像大小
模板资源 源码之家搜登录页面,链接:https://www.mycodes.net/190/10144.htm (或者搜门户网站 模板之家,里面页面更强大!) 编辑图像大小 然 ...
- 【C语言】输出半径1到10的圆的面积,当面积值超过100时,停止执行本程序
#include<stdio.h> #define PI 3.142 int main() { int r; float area; ; r <= ; r++) { area = P ...
- Selenium原理
from selenium import webdriver:导入webdriver模块 当导入webdriver模块时,会执行\selenium\webdriver目录下的__init__.py ...
- 浅谈C#委托的用法-delegate
2018年11月7日 小雨 一.委托的概念 委托和类一样是一种用户自定义类型,它存储的就是一系列具有相同签名和返回类型的方法的地址,调用委托的时候,它所包含的所有方法都会被执行. 借用百度上的 ...
- Python之二:基础知识
1.常量: 1.1.数:5.1.23.9.25e-3 4种类型的数——整数.长整数.浮点数和复数 2是一个整数的例子. 长整数不过是大一些的整数. 3.23和52.3E-4是浮点数的例子.E标记表示1 ...
- JavaScript函数、对象和数组
一.JavaScript函数 1.定义函数:函数的通用语法如下 function function_name([parameter [, ...]]) { statements; } 由关键字func ...
- javascript脚本混淆
javascript脚本混淆 脚本病毒是一个一直以来就存在,且长期活跃着的一种与PE病毒完全不同的一类病毒类型,其制作的门槛低.混淆加密方式的千变万化,容易传播.容易躲避检测,不为广大网民熟知等诸多 ...