Elasticsearch系列---搜索执行过程及scroll游标查询
概要
本篇主要介绍一下分布式环境中搜索的两阶段执行过程。
两阶段搜索过程
回顾我们之前的CRUD操作,因为只对单个文档进行处理,文档的唯一性很容易确定,并且很容易知道是此文档在哪个node,哪个shard中。
但搜索比CRUD复杂,符合搜索条件的文档,可能散落在各个node、各个shard中,我们需要找到匹配的文档,并且把从各个node,各个shard返回的结果进行汇总、排序,组成一个最终的结果排序列表,才算完成一个搜索过程。我们将按两阶段的方式对这个过程进行讲解。
查询阶段
假定我们的ES集群有三个node,number_of_primary_shards为3,replica shard为1,我们执行一个这样的查询请求:
GET /music/children/_search
{
"from": 980,
"size": 20
}
查询阶段的过程示意图如下:
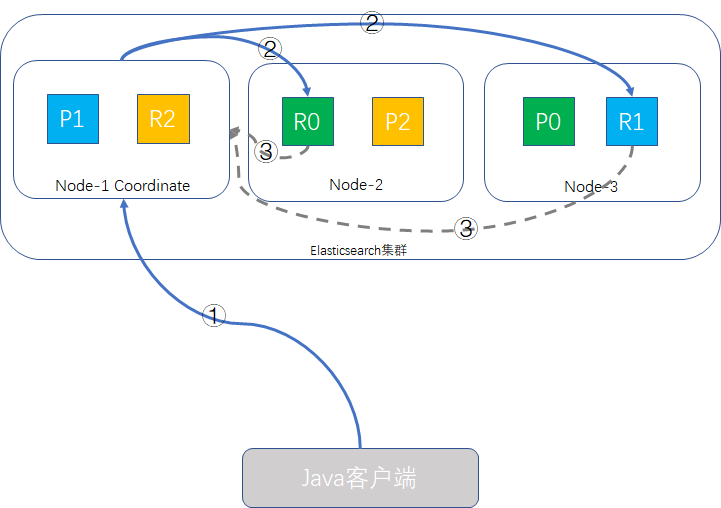
- Java客户端发起查询请求,接受请求的node-1成为Coordinate Node(协调者),该node会创建一个priority queue,长度为from + size即1000。
- Coordinate Node将请求分发到所有的primary shard或replica shard中,每个shard在本地创建一个同样大小的priority queue,长度也为from + size,用于存储该shard执行查询的结果。
- 每个shard将各自priority queue的元素返回给Coordinate Node,元素内只包含文档的ID和排序值(如_score),Coordinate Node将合并所有的元素到自己的priority queue中,并完成排序动作,最终根据from、size值对结果进行截取。
补充说明:
- 哪个node接收客户端的请求,该node就会成为Coordinate Node。
- Coordinate Node转发请求时,会根据负载均衡算法分配到同一分片的primary shard或replica shard上,为什么说replica值设置得大一些可以增加系统吞吐量的原理就在这里,Coordinate Node的查询请求负载均衡算法会轮询所有的可用shard,并发场景时就会有更多的硬件资源(CPU、内存,IO)会参与其中,系统整体的吞吐量就能提升。
- 此查询过程Coordinate Node得到是轻量级的元素信息,只包含文档ID和_score这些信息,这样可以减轻网络负载,因为分页过程中,大部分的数据是会丢弃掉的。
取回阶段
在完成了查询阶段后,此时Coordinate Node已经得到查询的列表,但列表内的元素只有文档ID和_score信息,并无实际的_source内容,取回阶段就是根据文档ID,取到完整的文档对象的过程。如下图所示:

- Coordinate Node根据from、size信息截取要取回文档的ID,如{"from": 980, "size": 20},则取第981到第1000这20条数据,其余丢弃,from/size为空则默认取前10条,向其他shard发出mget请求。
- shard接收到请求后,根据_source参数(可选)加载文档信息,返回给Coordinate Node。
- 一旦所有的shard都返回了结果,Coordinate Node将结果返回给客户端。
前面几篇有提到deep paging的问题,我们在这里又复习一遍,使用from和size进行分页时,传递信息给Coordinate Node的每个shard,都创建了一个from + size长度的队列,并且Coordinate Node需要对所有传过来的数据进行排序,工作量为number_of_shards * (from + size),然后从里面挑出size数量的文档,如果from值特别大,那么会带来极大的硬件资源浪费,鉴于此原因,强烈建议不要使用深分页。
不过深分页操作很少符合人的行为,翻几页还看不到想要的结果,人的第一反应是换一个搜索条件,只有机器人或爬虫才这么不知疲倦地一直翻页直到服务器崩溃。
preference设置
查询时使用preference参数,可以影响哪些shard可以用来执行搜索操作,6.1.0版本后,许多参数值已声明为弃用,我们挑几个目前还在使用的简单介绍一下:
- _only_local:只搜索当前node中的shard
- _local:优先搜索当前node中的shard,搜不到再去其他的shard
- _prefer_nodes:abc,xyz:优先从指定的abc/xyz节点上搜索,如果两个节点都有存在数据的shard,随机从里面挑一个节点执行搜索
- _only_nodes:abc,xyz,...:只在符合通配abc、xyz名称的节点上搜索,如果多个节点都有存在数据的shard,随机从里面挑一个节点执行搜索
- _shards:2,3:指定shard进行搜索,这个条件如与其他条件搭配使用,此条件要写在前面,如_shards:2,3|_local
- 自定义字符串:一般用sessionid或userid
bouncing results问题
假如两个文档有相同的字段值,并且时间戳也一样,如果按时间戳字段来排序,由于请求是在所有可用的shard上轮询的,可能存在一种情况:这两个文档记录在不同的shard之间保存的顺序不相同。结果就是同一个条件的查询,如果执行多次,分配在primary shard得到的是一种顺序,分配在replica shard又是另一个顺序,这个就是所谓的bouncing results问题。
如何避免:让同一个用户始终使用同一个shard,就可以避免这种问题,常见的做法是preference设置为sessionid或userid,如:
GET /music/children/_search?preference=10086
{
"from": 980,
"size": 20
}
超时问题
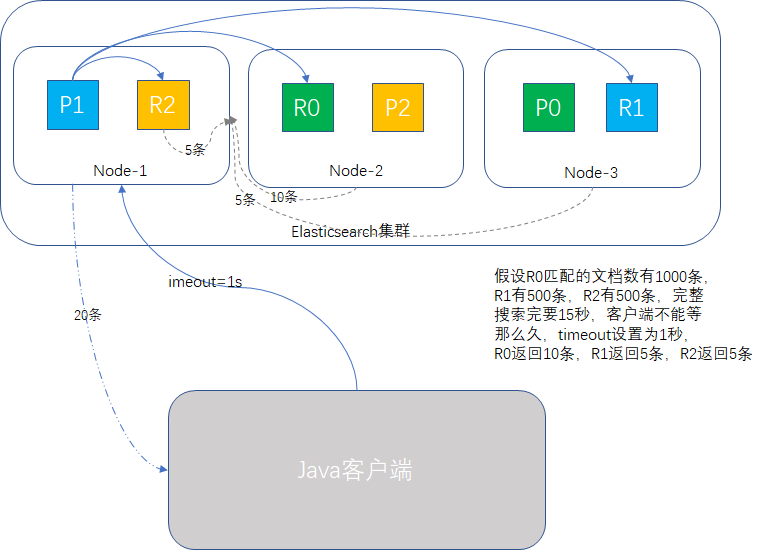
我们回顾查询阶段和取回阶段,必须所有的操作都完成了,才给客户端返回结果,如果中途有shard在执行特别重的任务,导致查询很慢怎么办?会拖慢整个集群吗?
如果是高并发场景,那极有可能,因为某一个节点慢,整个查询请求堆积,拖死集群都有可能。
为了防止这一情况,我们使用timeout参数,告诉shard允许处理数据的最大时间,时间一到,执行关门动作,能有多少数据返回多少数据,剩下的不要了,这样可以确保集群是稳定运行的,如下图所示:
routing
在设计大规模数据搜索时,我们为了实现数据集中性,索引时会按一定规则将数据进行存储,比如订单数据,我们会按userid为route key,每个userid的订单数据,都放在同一个shard上,既然存储时使用了route key,那么搜索时同样使用route key,可以让查询只搜索相关的shard,如:
GET /music/children/_search?routing=10086
{
"from": 980,
"size": 20
}
这样由于精准到具体的shard,可以极大的缩小搜索范围,数据量越大,效果越明显。
搜索类型
默认的搜索类型是query_then_fetch,我们还可以选择dfs_query_then_fetch,这个有预查询阶段,可以从所有相关shard中获取词频来计算全局词频,可以提升revelance sort精准度。
scroll游标查询
如果我们要把大批量的数据从ES集群中取出,用来执行一些计算,一次性取完肯定不合适,IO压力过大,性能容易出问题,分页查询又容易造成deep paging的问题。一般推荐使用scroll查询,一批一批的查,直到所有数据都查询完。
原理
- scroll查询会先做查询初始化,然后再批量地拉取结果,有点像数据库的cursor。
- scroll查询会取某个时间点的快照数据,查询初始化后索引上的数据发生了变化,快照数据还是原来的,有点像数据库的索引视图。
- scroll查询用字段_doc排序,去掉了全局排序,性能比较高。
- scroll查询要设置过期时间,每次搜索在这个时间内完成即可。
示例
我们假定每次取10条数据,时间窗口为1秒
请求如下:
GET /music/children/_search?scroll=1s
{
"size": 10
}
响应如下(结果有删减):
{
"_scroll_id": "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAABJQFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASUhZBMXMxdXVzN1RwdURTaVQ0eEZMT29RAAAAAAAAElMWQTFzMXV1czdUcHVEU2lUNHhGTE9vUQAAAAAAABJUFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASURZBMXMxdXVzN1RwdURTaVQ0eEZMT29R",
"took": 2,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 4,
"max_score": 1,
"hits": [
{
"_index": "music",
"_type": "children",
"_id": "2",
"_score": 1,
"_source": {
"name": "wake me, shark me",
"content": "don't let me sleep too late, gonna get up brightly early in the morning",
"language": "english",
"length": "55",
"likes": 0,
"author": "John Smith"
}
}
]
}
}
注意那个scroll_id,下次再查询时,只要带上这个就行了
GET /_search/scroll
{
"scroll": "1s",
"scroll_id" : "DnF1ZXJ5VGhlbkZldGNoBQAAAAAAABJQFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASUhZBMXMxdXVzN1RwdURTaVQ0eEZMT29RAAAAAAAAElMWQTFzMXV1czdUcHVEU2lUNHhGTE9vUQAAAAAAABJUFkExczF1dXM3VHB1RFNpVDR4RkxPb1EAAAAAAAASURZBMXMxdXVzN1RwdURTaVQ0eEZMT29R"
}
每次的查询,都把最新的scroll_id带上,直到数据查询完成为止。
scroll查询看起来像分页,但使用场景不一样,分页主要是按页展示数据,主要受众是人,scroll一批一批的获取数据,主要受众一般是数据分析的系统,是给系统用的。
性能也不同,前面我们了解后,分页查询随着页数的加深,压力越来越大,而scroll是基于_doc排序的数据处理,特别适用于大批量数据的获取分析。
小结
本篇详细介绍了查询的两阶段过程,以及能够影响查询行为的一些参数设置,历经多个版本迭代,有些preference参数已经不用了,了解一下就行,另外介绍了bouncing results产生的原理及规避办法,最后介绍了一下大批量数据查询利器scroll的简单用法。
专注Java高并发、分布式架构,更多技术干货分享与心得,请关注公众号:Java架构社区
可以扫左边二维码添加好友,邀请你加入Java架构社区微信群共同探讨技术

Elasticsearch系列---搜索执行过程及scroll游标查询的更多相关文章
- MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY)
在上一篇文章MySQL查询语句执行过程及性能优化-基本概念和EXPLAIN语句简介中介绍了EXPLAIN语句,并举了一个慢查询例子:
- Elasticsearch系列---搜索分页和deep paging问题
概要 本篇从介绍搜索分页为起点,简单阐述分页式数据搜索与原有集中式数据搜索思维方式的差异,就分页问题对deep paging问题的现象进行分析,最后介绍分页式系统top N的案例. 搜索分页语法 El ...
- [Elasticsearch] 全文搜索 (一) 基础概念和match查询
全文搜索(Full Text Search) 现在我们已经讨论了搜索结构化数据的一些简单用例,是时候开始探索全文搜索了 - 如何在全文字段中搜索来找到最相关的文档. 对于全文搜索而言,最重要的两个方面 ...
- SpringBoot整合Elasticsearch游标查询(scroll)
游标查询(scroll)简介 scroll 查询 可以用来对 Elasticsearch 有效地执行大批量的文档查询,而又不用付出深度分页那种代价. 游标查询会取某个时间点的快照数据. 查询初始化之后 ...
- MyBatis 源码分析 - SQL 的执行过程
* 本文速览 本篇文章较为详细的介绍了 MyBatis 执行 SQL 的过程.该过程本身比较复杂,牵涉到的技术点比较多.包括但不限于 Mapper 接口代理类的生成.接口方法的解析.SQL 语句的解析 ...
- MySQL查询语句执行过程及性能优化(JOIN/ORDER BY)-图
http://blog.csdn.net/iefreer/article/details/12622097 MySQL查询语句执行过程及性能优化-查询过程及优化方法(JOIN/ORDER BY) 标签 ...
- ElasticSearch - 解决ES的深分页问题 (游标 scroll)
https://www.jianshu.com/p/f4d322415d29 1.简介 ES为了避免深分页,不允许使用分页(from&size)查询10000条以后的数据,因此如果要查询第10 ...
- 【java虚拟机系列】从java虚拟机字节码执行引擎的执行过程来彻底理解java的多态性
我们知道面向对象语言的三大特点之一就是多态性,而java作为一种面向对象的语言,自然也满足多态性,我们也知道java中的多态包括重载与重写,我们也知道在C++中动态多态是通过虚函数来实现的,而虚函数是 ...
- 反爬虫:利用ASP.NET MVC的Filter和缓存(入坑出坑) C#中缓存的使用 C#操作redis WPF 控件库——可拖动选项卡的TabControl 【Bootstrap系列】详解Bootstrap-table AutoFac event 和delegate的分别 常见的异步方式async 和 await C# Task用法 c#源码的执行过程
反爬虫:利用ASP.NET MVC的Filter和缓存(入坑出坑) 背景介绍: 为了平衡社区成员的贡献和索取,一起帮引入了帮帮币.当用户积分(帮帮点)达到一定数额之后,就会“掉落”一定数量的“帮帮 ...
随机推荐
- java spring使用Jackson过滤
一.问题的提出. 项目使用Spring MVC框架,并用jackson库处理JSON和POJO的转换.在POJO转化成JSON时,希望动态的过滤掉对象的某些属性.所谓动态,是指的运行时,不同的cont ...
- H3C 启动包过滤防火墙功能
- python3在pycharm中为什么导入random模块不能用? TypeError: 'module' object is not callable
新手学python求大神指导,也用sys导入了random.py的路径,仍然不行. 刚刚排错貌似找到了问题的原因...那是因为我在pycharm中新建的python文件名就是random,所以当前目录 ...
- 手机web页面调用手机QQ实现在线聊天的效果
html代码如下: <a href="javascript:;" onclick="chatQQ()">QQ咨询</a> js代码如下: ...
- 【js】vue 2.5.1 源码学习 (十一) 模板编译compileToFunctions渲染函数
大体思路(九) 本节内容: 1. compileToFunctions定位 1. compileToFunctions定位 ==> createCompiler = createCompiler ...
- 前端小白-----ES6之字符串模板
前言:只要坚持就会胜利--Coldfront-小白菜 既是总结也是一种分享 分享内容:ES6 字符串模板 案例1:var Musics=[{music:"六月的雨",singer: ...
- 使用Ant Design写一个仿微软ToDo
实习期的第一份活,自己看Ant Design的官网学习,然后用Ant Design写一个仿微软ToDo. 不做教学目的,只是记录一下. 1.学习 Ant Design 是个组件库,想要会用,至少要知道 ...
- 洛谷4139 bzoj 3884 上帝与集合的正确用法
传送门 •题意 求$2^{2^{2^{2^{2^{2^{...^{2}}}}}}}$ (无穷个2) 对p取模的值 •思路 设答案为f(p) $2^{2^{2^{2^{2^{2^{...^{2}}}}} ...
- dotnet 使用 lz4net 压缩 Stream 或文件
在 dotnet 可以使用 LZ4 这个无损的压缩算法,这个压缩算法的压缩率不高但是速度很快.这个库支持在 .NET Standard 1.6 .NET Core .NET Framework Mon ...
- 2019-9-2-win10-uwp-获得焦点改变
title author date CreateTime categories win10 uwp 获得焦点改变 lindexi 2019-09-02 12:57:38 +0800 2018-2-13 ...