RabbitMQ入门(二)工作队列
在文章RabbitMQ入门(一)之Hello World,我们编写程序通过指定的队列来发送和接受消息。在本文中,我们将会创建工作队列(Work Queue),通过多个workers来分配耗时任务。
工作队列(Work Queue,也被成为Task Queue,任务队列)的中心思想是,避免立即执行一个资源消耗巨大且必须等待其完成的任务。相反地,我们调度好队列可以安排该任务稍后执行。我们将一个任务(task)封装成一个消息,将它发送至队列。一个在后台运行的work进程将会抛出该任务,并最终执行该任务。当你运行多个workers的时候,任务将会在它们之中共享。
这个概念在web开发中很有用,因为通过一个短的HTTP请求不可能处理复杂的任务。
在之前的文章中,我们发送了一个包含“Hello World!”的消息。现在我们将会发送代表复杂任务的字串符。我们并没有实际上的任务,比如重新调整图片的尺寸或者渲染PDF,我们假装有这样的复杂任务,通过使用time.sleep()函数。我们将会用字符串中的点(.)来代表复杂度;每一个点代表一秒中的任务。举例来说,字符串Hello...需要花费三秒。
我们需要稍微修改下sent.py中的代码,允许在命令中输入任意字符串。该程序会调度任务至工作队列,因此命名为new_task.py:
import sysmessage = ' '.join(sys.argv[1:]) or "Hello World!"channel.basic_publish(exchange='',routing_key='hello',body=message)print(" [x] Sent %r" % message)
我们原先的receive.py也需要改动:它需要在消息体中将字符串的每一个点代表1秒钟的任务。它会从队列中抛出消息并执行该消息,因此命名为task.py:
import timedef callback(ch, method, properties, body):print(" [x] Received %r" % body)time.sleep(body.count(b'.'))print(" [x] Done")
Round-Robin分发(轮询分发)
使用工作队列的一个好处就是它能够轻松实现并行工作。如果我们创建了一项积压的工作,那么我们可以增加更多的worker来使它的扩展性更好。
首先,我们同时运行两个worker.py脚本。他们都能够从队列中获取消息,但是具体是怎么实现的呢?让我们接着阅读。
你需要打开三个终端查看。两个终端用于运行worker.py脚本。这两个终端将会成为两个消费者——C1和C2。
# shell 1python worker.py# => [*] Waiting for messages. To exit press CTRL+C
# shell 2python worker.py# => [*] Waiting for messages. To exit press CTRL+C
在第三个终端中,我们将会产生新的任务。一旦你启动了这些消费者,你就可以发送一些消息了:
# shell 3python new_task.py First message.python new_task.py Second message..python new_task.py Third message...python new_task.py Fourth message....python new_task.py Fifth message.....
让我们看看这两个workers传递了什么:
# shell 1python worker.py# => [*] Waiting for messages. To exit press CTRL+C# => [x] Received 'First message.'# => [x] Received 'Third message...'# => [x] Received 'Fifth message.....'
# shell 2python worker.py# => [*] Waiting for messages. To exit press CTRL+C# => [x] Received 'Second message..'# => [x] Received 'Fourth message....'
RabbitMQ默认会将每个消息依次地发送给下一个消费者。因此总的来说,每个消费者将会同样数量的消息。这种消息分配的方法叫Round-Robin。你可以尝试三个或者更多的worker。
消息确认(Message Acknowledgement)
执行一项任务需要花费几秒钟。你也许会好奇,如果其中一个消费者执行一项耗时很长的任务,并且在执行了一部分的时候挂掉了,将会发生什么?根据我们现在的代码,一旦RabbitMQ将消息传送至消费者,那么RabbitMQ就会标志它为删除状态。在这种情况下,如果我们杀死某个worker,我们将会失去他正在处理的消息。我们也会失去所有分配至这个worker的消息,当然,这些消息还未被处理。
但是,我们不希望失去任何一项任务。如果有一个worker挂掉了,我们希望这些任务能够被传送至另一个worker。
为了确保消息不丢失,RabbitMQ支持消息确认。一个ack(nowledgement)是由消费者发送回来的,用于告诉RabbitMQ,这个特定的消息已经被接受,被处理,可以被删除了。
如果一个消费者挂了(它的channel关闭了,连接关闭了,或者TCP连接丢失)但是没有发送一个ack,RabbitMQ就会知道这个消息并未被完全处理,会将它重新塞进队列。如果同时还存在着其他在线消费者,RabbbitMQ将会将这个消息重新传送给另一个消费者。用这种方式可以确保没有消息丢失,即使workers偶尔会刮掉。
并不存在消息超时;如果消费者挂了,RabbitMQ将会重新传送消息。这样即使处理一个消息需要消耗很长很长的时间,也是可以的。
默认的消息确认方式为人工消息确认。在我们之前的例子中,我们清晰地将它关闭了,使用了auto_ack=True这个命令。当我们完成一项任务的时候,根据需要,移除这个标志,从worker中发送一个合适的确认。
def callback(ch, method, properties, body):print(" [x] Received %r" % body)time.sleep( body.count('.') )print(" [x] Done")ch.basic_ack(delivery_tag = method.delivery_tag)channel.basic_consume(queue='hello', on_message_callback=callback)
使用上述代码,我们可以确保,即使我们使用CTRL+C命令杀死了一个正在处理消息的woker,也不会丢失什么。这个worker挂掉后不久,所有未确认的消息将会被重新传送。
消息确认必须在同一个传输消息的channel中发送。尝试着在不同的channel中进行消息确认将会引发channel-level protocol exception。
消息持久化(Message Durability)
我们已经学习了如何在消费者挂掉的情况下,任务不会丢失。但是,当RabbitMQ server停止时,我们的任务仍然会丢失。
当RabbitMQ停止或崩溃时,它将会忘记所有的队列和消息,除非你告诉它不这么做。在这种情况下,需要做两个事情确保消息不会丢失:我们需要将队列和消息都设置为持久化。
首先,我们需要确保RabbitMQ不会丢失队列。为了实现这个,我们需要将队列声明为持久化:
channel.queue_declare(queue='hello', durable=True)
尽管这个命令是正确的,但他仍会不会起作用。这是因为,我们已经创建了一个叫为hello的非持久化队列。RabbitMQ不允许你重新定义一个已经存在的队列而参数不一样,所有这样做的程序只会引发错误。但是有一个快速的应变办法——我们可以创建一个不同名称的队列,比如task_queue:
channel.queue_declare(queue='task_queue', durable=True)
queue_declare需要同时应用于生产者和消费者。
在这点上我们可以确保task_queue队列不会丢失消息即使RabbitMQ重启。现在,我们需要声明消息为持久化——将delivery_mode这个参数设置为2。
channel.basic_publish(exchange='',routing_key="task_queue",body=message,properties=pika.BasicProperties(delivery_mode = 2, # make message persistent))
公平分发(Fair Dispatch)
你也许注意到了,刚才的消息分发机制并不会严格地按照我们所希望的方式进行。举这样一个例子,设想有两个worker,而所有的奇数消息都很重而偶数消息都是轻量级的,这样其中一个worker就会一直很忙而另一个worker几乎不做什么工作。然而,RabbitMQ对此一无所知,它仍然会平均分配消息。
这种情况的发生是因为RabbitMQ仅仅是当消息进入队列的时候就会分发这个消息。它并不会注意消费者所接收的未确认的消息数量。它盲目地将第n个消息发送至第n个消费者。
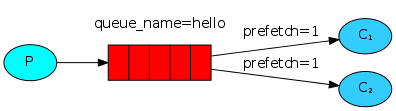
为了克服这种情况,我们可以在basic.qos方法中设置prefetch_count=1。这就告诉RabbitMQ一次不要将多于一个的消息发送给一个worker。换句话说,不要分发一个新的消息给worker除非这个worker已经处理好之前的消息并且进行了消息确认。也就说,RabbitMQ将会将这个消息分发给下一个不是很忙的worker。
channel.basic_qos(prefetch_count=1)
实战1
为了对上面的例子有一个好的理解,我们需要写代码进行实际操练一下。
生产者new_task.py的代码如下:
# -*- coding: utf-8 -*-import pikaimport sysconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)message = ' '.join(sys.argv[1:]) or "Hello World!"channel.basic_publish(exchange='',routing_key='task_queue',body=message,properties=pika.BasicProperties(delivery_mode=2, # make message persistent))print(" [x] Sent %r" % message)connection.close()
消费者worker.py的完整代码如下:
# -*- coding: utf-8 -*-import pikaimport timeconnection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)print(' [*] Waiting for messages. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] Received %r" % body)time.sleep(body.count(b'.'))print(" [x] Done")ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(queue='task_queue', on_message_callback=callback)channel.start_consuming()
开启三个终端,消息的发送和接收情况如下:

如果我们停掉其中一个worker,那么消息的接收情况如下:
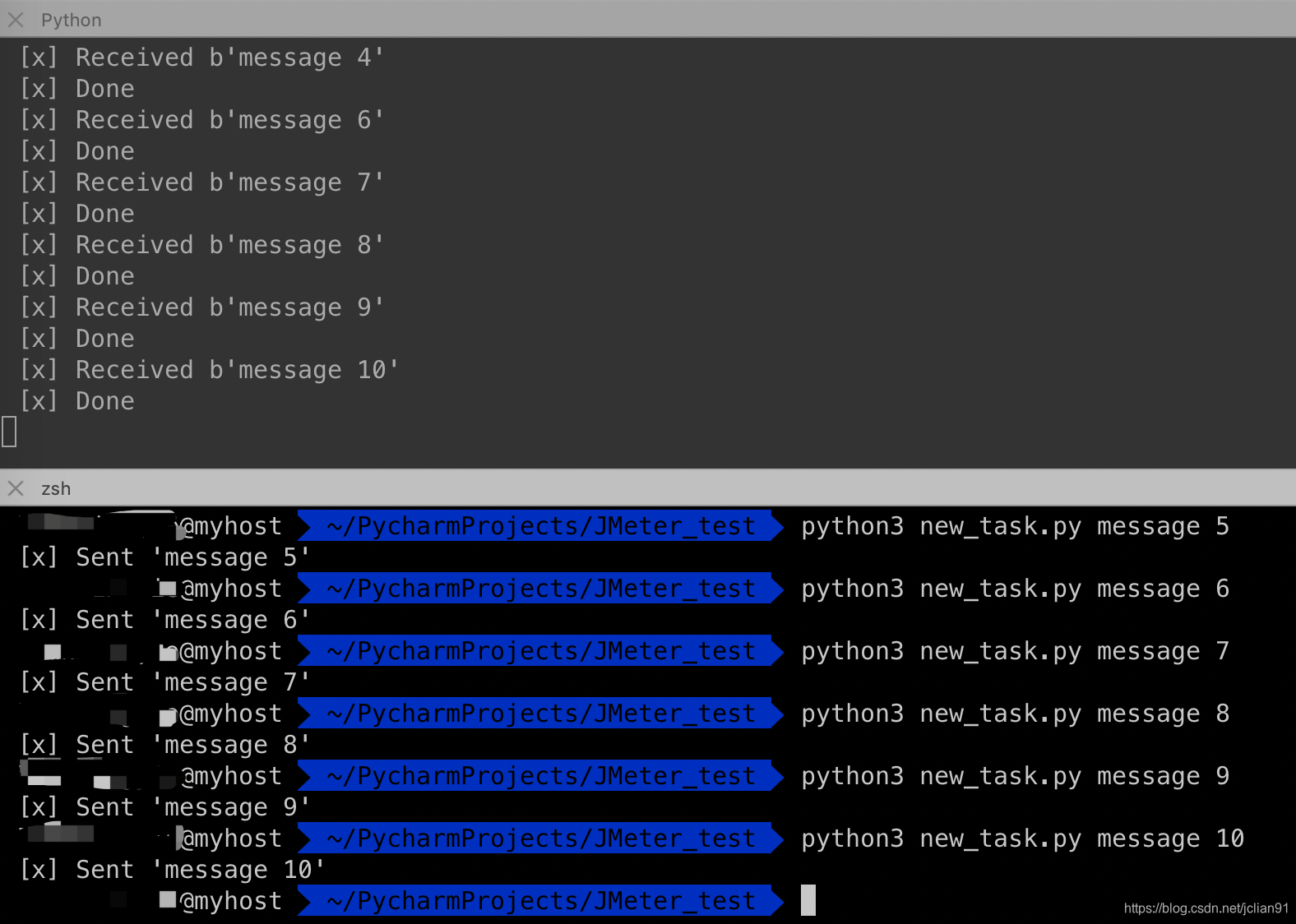
可以看到,现在所有发送的消息都会被这个仍在工作的worker接收到。
实战2
接下来,我们将会使用RabbitMQ的这种工作队列的方式往MySQL数据库中的表插入数据。
数据库为orm_test,表格为exam_user,表结构如下:

接下来,我们需要往这张表中插入随机创建的数据。如果我们利用Python的第三方模块pymysql,每一次插入一条记录,那么一分钟插入53237条记录。
利用RabbitMQ,我们的生产者代码如下:
# -*- coding: utf-8 -*-# author: Jclian91# place: Pudong Shanghai# time: 2020-01-13 23:23import pikafrom random import choicenames = ['Jack', 'Rose', 'Mark', 'Hill', 'Docker', 'Lilei', 'Lee', 'Bruce', 'Dark','Super', 'Cell', 'Fail', 'Suceess', 'Su', 'Alex', 'Bob', 'Cook', 'David','Ella', 'Lake', 'Moon', 'Nake', 'Zoo']places = ['Beijing', 'Shanghai', 'Guangzhou', 'Dalian', 'Qingdao']types = ['DG001', 'DG002', 'DG003', 'DG004', 'DG005', 'DG006', 'DG007', 'DG008','DG009', 'DG010', 'DG020']connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)for id in range(1, 20000001):name = choice(names)place = choice(places)type2 = choice(types)message = "insert into exam_users values(%s, '%s', '%s', '%s');" % (id, name, place, type2)channel.basic_publish(exchange='',routing_key='task_queue',body=message,properties=pika.BasicProperties(delivery_mode=2, # make message persistent))print(" [x] Sent %r" % message)connection.close()
消费者代码如下:
# -*- coding: utf-8 -*-# author: Jclian91# place: Pudong Shanghai# time: 2020-01-13 23:28# -*- coding: utf-8 -*-# author: Jclian91# place: Sanya Hainan# time: 2020-01-12 13:45import pikaimport timeimport pymysql# 打开数据库连接db = pymysql.connect(host="localhost", port=3306, user="root", password="", db="orm_test")# 使用 cursor() 方法创建一个游标对象 cursorcursor = db.cursor()connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)print(' [*] Waiting for messages. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] Received %r" % body)cursor.execute(body)db.commit()print(" [x] Insert successfully!")ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(queue='task_queue', on_message_callback=callback)channel.start_consuming()
我们开启9个终端,其中8个消费者1个生产者,先启动消费者,然后生产者,按照上面的数据导入方式,一分钟插入了133084条记录,是普通方式的2.50倍,效率有大幅度提升!
让我们稍微修改下生产者和消费者的代码,一次提交插入多条记录,减少每提交一次就插入一条记录的消耗时间。新的生产者代码如下:
# -*- coding: utf-8 -*-# author: Jclian91# place: Pudong Shanghai# time: 2020-01-13 23:23import pikafrom random import choiceimport jsonnames = ['Jack', 'Rose', 'Mark', 'Hill', 'Docker', 'Lilei', 'Lee', 'Bruce', 'Dark','Super', 'Cell', 'Fail', 'Suceess', 'Su', 'Alex', 'Bob', 'Cook', 'David','Ella', 'Lake', 'Moon', 'Nake', 'Zoo']places = ['Beijing', 'Shanghai', 'Guangzhou', 'Dalian', 'Qingdao']types = ['DG001', 'DG002', 'DG003', 'DG004', 'DG005', 'DG006', 'DG007', 'DG008','DG009', 'DG010', 'DG020']connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)for _ in range(1, 200001):values = []for i in range(100):name = choice(names)place = choice(places)type2 = choice(types)values.append([100*_+i+1, name, place, type2])message = json.dumps(values)channel.basic_publish(exchange='',routing_key='task_queue',body=message,properties=pika.BasicProperties(delivery_mode=2, # make message persistent))print(" [x] Sent %r" % message)connection.close()
新的消费者的代码如下:
# -*- coding: utf-8 -*-# author: Jclian91# place: Pudong Shanghai# time: 2020-01-13 23:28# -*- coding: utf-8 -*-# author: Jclian91# place: Sanya Hainan# time: 2020-01-12 13:45import pikaimport jsonimport timeimport pymysql# 打开数据库连接db = pymysql.connect(host="localhost", port=3306, user="root", password="", db="orm_test")# 使用 cursor() 方法创建一个游标对象 cursorcursor = db.cursor()connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))channel = connection.channel()channel.queue_declare(queue='task_queue', durable=True)print(' [*] Waiting for messages. To exit press CTRL+C')def callback(ch, method, properties, body):print(" [x] Received %r" % body)sql = 'insert into exam_users values(%s, %s, %s, %s)'cursor.executemany(sql, json.loads(body))db.commit()print(" [x] Insert successfully!")ch.basic_ack(delivery_tag=method.delivery_tag)channel.basic_qos(prefetch_count=1)channel.basic_consume(queue='task_queue', on_message_callback=callback)channel.start_consuming()
跟刚才一样,我们开启9个终端,其中8个消费者1个生产者,先启动消费者,然后生产者,按照上面的数据导入方式,一分钟插入了3170600条记录,是普通方式的59.56倍,是先前一次只提交一条记录的插入方式的23.82倍。这样的提速无疑是非常惊人的!
当然还有更高效的数据插入方法,本文的方法仅仅是为了演示RabbitMQ的工作队列以及在插入数据方面的提速。
本次分享到此结束,感谢大家阅读~
RabbitMQ入门(二)工作队列的更多相关文章
- RabbitMQ入门:工作队列(Work Queue)
在上一篇博客<RabbitMQ入门:Hello RabbitMQ 代码实例>中,我们通过指定的队列发送和接收消息,代码还算是比较简单的. 假设有这一些比较耗时的任务,按照上一次的那种方式, ...
- RabbitMQ入门教程——工作队列
什么是工作队列 工作队列是为了避免等待一些占用大量资源或时间操作的一种处理方式.我们把任务封装为消息发送到队列中,消费者在后台不停的取出任务并且执行.当运行了多个消费者工作进程时,队列中的任务将会在每 ...
- RabbitMQ入门(2)——工作队列
前面介绍了队列接收和发送消息,这篇将学习如何创建一个工作队列来处理在多个消费者之间分配耗时的任务.工作队列(work queue),又称任务队列(task queue). 工作队列的目的是为了避免立刻 ...
- RabbitMQ入门:发布/订阅(Publish/Subscribe)
在前面的两篇博客中 RabbitMQ入门:Hello RabbitMQ 代码实例 RabbitMQ入门:工作队列(Work Queue) 遇到的实例都是一个消息只发送给一个消费者(工作者),他们的消息 ...
- RabbitMQ入门到进阶(Spring整合RabbitMQ&SpringBoot整合RabbitMQ)
1.MQ简介 MQ 全称为 Message Queue,是在消息的传输过程中保存消息的容器.多用于分布式系统 之间进行通信. 2.为什么要用 MQ 1.流量消峰 没使用MQ 使用了MQ 2.应用解耦 ...
- RabbitMQ入门:总结
随着上一篇博文的发布,RabbitMQ的基础内容我也学习完了,RabbitMQ入门系列的博客跟着收官了,以后有机会的话再写一些在实战中的应用分享,多谢大家一直以来的支持和认可. RabbitMQ入门系 ...
- RabbitMQ入门(6)——远程过程调用(RPC)
在RabbitMQ入门(2)--工作队列中,我们学习了如何使用工作队列处理在多个工作者之间分配耗时任务.如果我们需要运行远程主机上的某个方法并等待结果怎么办呢?这种模式就是常说的远程过程调用(Remo ...
- RabbitMQ入门(3)——发布/订阅(Publish/Subscribe)
在上一篇RabbitMQ入门(2)--工作队列中,有一个默认的前提:每个任务都只发送到一个工作人员.这一篇将介绍发送一个消息到多个消费者.这种模式称为发布/订阅(Publish/Subscribe). ...
- RabbitMQ入门教程(四):工作队列(Work Queues)
原文:RabbitMQ入门教程(四):工作队列(Work Queues) 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:https:/ ...
随机推荐
- git 回滚到某个版本
首先使用git log 显示最近的代码提交记录 commit后面的内容,就是回滚的记录名 增加了加载条显示,提高用户体验 commit 47f45668e72e4deeccae85e9767c250d ...
- H3C查看CF卡内的文件
查看CF卡内的文件 <H3C>dir //查看文件及目录文件 Directory of cf:/ -------------查看的是CF卡的内容 0 ...
- NuGet 如何设置图标
在找 NuGet 的时候可以看到有趣的库都有有趣的图标,那么如何设置一个 NuGet 的图标 在开始之前,请在nuget官方网站下载 NuGet.exe 同时设置环境变量 环境变量设置的方法就是将 N ...
- 使用FluentEmail发送outlook邮件
一,邮箱账号相关设置 1,创建outLook邮箱. 2,进入邮箱设置->同步电子邮件->允许设备和应用使用pop 3,设置microsoft账号的应用程序密码->进入安全性页面-&g ...
- Qt和c/c++connect函数冲突解决方法
在使用c/c++的connect函数时在前面写::connect()这样就可以解决了
- Android7_安卓的知识体系梳理
最近梳理了一下安卓的知识体系,先构建一个整体性的认知,也作为以后的学习路线的依据. [一.从原理角度出发]1.Activity生命周期和启动模式2.View的事件体系与工作原理3.四大组件的工作过程4 ...
- c3p0连接池封装
在处理数据库事物时需要同一个Connection 但是dbcp无法获得 单独工具也显得繁琐,改进成c3p0工具类: package utils; import java.sql.Connectio ...
- torch or numpy
黄色:重点 粉色:不懂 Torch 自称为神经网络界的 Numpy, 因为他能将 torch 产生的 tensor 放在 GPU 中加速运算 (前提是你有合适的 GPU), 就像 Numpy 会把 a ...
- java中如何自动获取电脑的ip地址
String ip=InetAddress.getLocalHost().getHostAddress().toString(); 可以写一个main方法测试一下.
- DEVOPS技术实践_13:使用Jenkins持续传送设计-CD基础
1. 分支策略 持续集成中使用的分支策略包括以下三个: The master branch The integration branch The feature branch 而CD只在Integra ...