字符编码及字节串bytes类型
1 字符编码简介
ASCII码:美国人发明并使用,用1个字节(8位二进制)代表一个字符,ASCII码是其他任意编码表的子集(utf-16除外).
Unicode:包含和兼容全世界的语言,与全世界的语言都有映射关系,常用2个字节表示一个字符,1个生僻字用4个字节表示.
utf-8:可变长编码,英文用1个字节表示,汉字通常是3个字节,生僻字常用4-6个字节表示,uft-8比Unicode编码节省空间和I/O开销.
关于Unicode和utf-x格式之间的关系,可以认为utf-x是Unicode的一种特殊类型,在存取数据时,内部会自动在Unicode和utf-x之间转换.
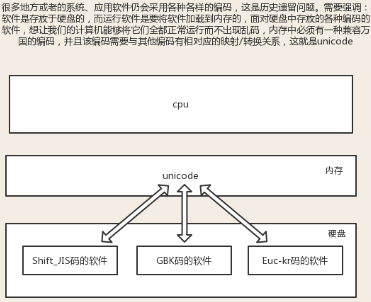
在内存中,统一使用的都是Unicode编码(固定,集成在操作系统中),所以可以转换为任意其他国家自定义的编码(这样就不会乱码);在将数据存入硬盘时,需要将Unicode转换为一种更精准的格式,即utf-8,将数据控制在最精准和节省空间;而磁盘数据读入缓存到内存中时,则需要将utf-8转换为Unicode.
在python2.x中,默认使用ASCII编码作为字符编码;而在python3.x中,默认使用Unicode作为默认字符编码.
import sys
print(sys.getdefaultencoding())
'ascii' #python2.x默认字符编码
---------------------------------
import sys
print(sys.getdefaultencoding())
'utf-8' #python3.x默认字符编码
---------------------------------
U=u'阿凡达' #3*3=9字节,8*9=72bytes
U1=bytes(U,'utf-8')
print(U1) # 构造Unicode字符,结果是 b'\xe9\x98\xbf\xe5\x87\xa1\xe8\xbe\xbe',\x代表16进制存储,1个字符代表4byte,18*4=72bytes
1.1 字符编码和解码
两张图读懂字符编码与解码之间的关系,编码和解码对应,就不会出现乱码了,参考资料及图片来源:
https://www.cnblogs.com/f-ck-need-u/p/10185965.html
https://www.cnblogs.com/linhaifeng/articles/5950339.html
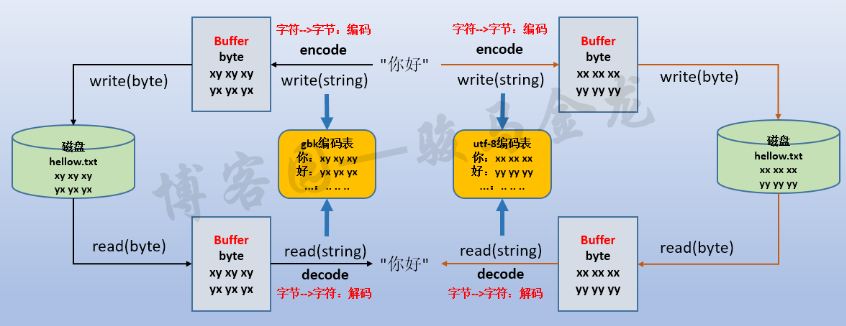
编码: str ---> bytes (encode)
解码: bytes ---> str (decode)
二进制格式的数据也常称为裸数据(raw data),str数据经过编码后得到raw data,raw data解码后得到的str.
内存中是unicode-------->encode编码保存-------->utf-8保存到磁盘(二进制)
utf-8磁盘里保存-------->decode解码缓存到内存中---------->unicode内存中
注意: 编码和解码的过程中,与软件指定的编码(字符集)也有关系,必须对应.
######################
print((set(dir(str)))-set(dir(bytes))) #字符串类型只有编码encode()方法,没有解码decode()
print((set(dir(bytes)))-set(dir(str))) #字节串类型只有解码decode()方法,没有编码encode()
--------------------
{'format', 'isdecimal', 'casefold', 'format_map', 'isidentifier', 'isnumeric', 'isprintable', 'encode'}
{'hex', 'decode', 'fromhex'}
1.2 str,bytes,bytearray类型
str:字符串类型,有序有索引,序列数据,可以迭代取值,但属于不可变类型,底层存储由一个个二进制组成,也就是bytes.python3.x中str默认是Unicode(uft-8)格式编码.
bytes:字节串类型,二进制字节数据,有序有索引,序列数据,可以迭代取值,也属于不可变类型;将字符串数据存到硬盘的的过程,实质上就是将Unicode转换为utf-8下的二进制字节这样就可以往硬盘存数据(二进制转换为十六进制存),或通过网络方式传输到其他地方.
bytearray:可变的字节串类型,属于可变的二进制数据(bytes),属于可变类型.
import sys #python3.x下查看默认字符编码为 utf-8
print(sys.getdefaultencoding()) #结果是 utf-8
----------------------------
B=b'aaa'
print(type(B),B) #构造bytes类型,需在字符串前加 b ,结果是<class 'bytes'> b'aaa'
----------------------------
B=b'aaa' # 构造bytearray类型及改值
By=bytearray(B)
print(type(By),By)
print(list(i for i in By))
By[0]=98 #改值
print(By) #By=b'baa',a子串值已改变
-------构造bytearray结果
<class 'bytearray'> bytearray(b'aaa')
[97, 97, 97]
bytearray(b'baa')
1.3 乱码的原因及解决办法
文件从内存写到硬盘的操作简称存文件,文件从硬盘读到内存的操作简称读文件.
乱码的原因:
1)存文件时就已经乱码(编辑的字符和编辑器设定保存的字符编码不一致)
2)存文件时不乱码而读文件时乱码(存时的文件字符编码和读时编辑器设定的字符编码不对应)
解决乱码的办法: 字符按照什么标准而编码的,就要按照什么标准解码,即编码和解码对应.
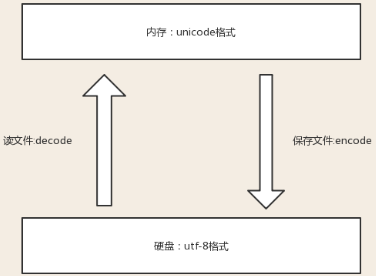
1.4 python文件头指定字符编码
为了避免乱码,在python文件中指定解释器和文件头也是一种方法,文件头指定的编码必须跟python文件存储时用的编码一致.
#!/usr/bin/env python <===指定解释器(限linux)
# -*- coding: utf-8 -*- <===指定字符编码(等同于#coding:utf-8)来将数据读入内存,由python解释器解释执行用的字符编码
字符编码及字节串bytes类型的更多相关文章
- 对于Python中的字节串bytes和字符串以及转义字符的新的认识
事情的起因是之前同学叫我帮他用Python修改一个压缩包的二进制内容用来做fuzz,根据他的要求,把压缩包test.rar以十六进制的方式打开,每次修改其中一个十六进制字符串并保存为一个新的rar用来 ...
- encode_utf8 把字符编码成字节 微信例子
##µ¼Èë encode_json decode_json use JSON qw/encode_json decode_json/; print "1111111111111111-\$ ...
- encode_utf8 把字符编码成字节 decode_utf8解码UTF-8到字符
encode_utf8 $octets = encode_utf8($string); Equivalent to "$octets = encode("utf8", $ ...
- 字符编码 and 字节和字符串转换(待补充)
ascii用一个字节(8位二进制)代表一个字符 Unicode常用2个字节(16位二进制)代表一个字符,生僻字需要用四个字节 汉字中已经超出了ASCII编码的范围,用Unicode, Unicode兼 ...
- Python中的字符串与字符编码
本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常谈的话题,同行们都写过很多这方面的文章. ...
- Python【第三篇】文件操作、字符编码
一.文件操作 文件操作分为三个步骤:文件打开.操作文件.关闭文件,但是,我们可以用with来管理文件操作,这样就不需要手动来关闭文件. 实现原理: import contextlib @context ...
- 【转】Python中的字符串与字符编码
[转]Python中的字符串与字符编码 本节内容: 前言 相关概念 Python中的默认编码 Python2与Python3中对字符串的支持 字符编码转换 一.前言 Python中的字符编码是个老生常 ...
- 补充:bytes类型以及字符编码转换
内容转自小猿圈链接:https://book.apeland.cn/details/41/ 定义 bytes类型是指一堆字节的集合,在python中以b开头的字符串都是bytes类型 b'\xe5\x ...
- python集合、字符编码、bytes与二进制
集合 用括号表示{ },可以包含多个元素,用逗号分割 用途 用于关系运算 集合特点 1.每个元素是不可变类型 2.没有重复的元素 3.无序 应用 1.set去重 set(names)的功能是将列表转换 ...
随机推荐
- 一些触发XSS的姿势(未完待续)
本文对一些能触发XSS的方式进行记录与学习. HTML5特性向量 通过formaction属性进行XSS - 需要用户进行交互 formaction 属性规定当表单提交时处理输入控件的文件的 URL. ...
- kubernetes基础概念知多少
kubernetes(简称k8s)是一种用于在一组主机上运行和协同容器化应用程序的管理平台,皆在提供高可用.高扩展性和可预测性的方式来管理容器应用的生命周期.通过k8s,用户可以定义程序运行方式.部署 ...
- ForkJoin统计文件夹中包含关键词的数量
2018-06-09总结: ForkJoin确实可以很快速的去解析文件并统计关键词的数量,但是如果文件过大就会出现内存溢出,是否可以通过虚拟内存方式解决内存溢出的问题呢? package com.ox ...
- IDEA 公司推出新字体,极度舒适~
这几天炒得沸沸扬扬的 Intellij IDEA 公司 JetBrains 推出了一种新字体:JetBrains Mono,据说它是专为开发人员设计的,下面栈长带大家一起来吃个瓜. JetBrains ...
- ORM基础4 跨表查询+原子性操作
一.跨表查询 1.# # 正向查找 对象查找 # book_obj = models.Book.objects.get(id=3) # print(book_obj) # ret = book_obj ...
- xhemj资料
Github https://github.com/xhemj Gitee码云 https://gitee.io/xhemj Cnblogs博客园 https://www.cnblogs.com/xh ...
- 双指针,BFS与图论(一)
(一)双指针 1.日志统计 小明维护着一个程序员论坛.现在他收集了一份”点赞”日志,日志共有 N 行. 其中每一行的格式是: ts id 表示在 ts 时刻编号 id 的帖子收到一个”赞”. 现在小明 ...
- Dynamics CRM CE 怎样从 UCI 改为 classic UI
dynamics 现在大力推UCI. 但是对于大部分人来说还是使用不习惯. 怎样从UCI改为classic UI呢 1. 快速的方法 https://xxx.crm.dynamics.com/main ...
- 工具之grep
转自:http://www.cnblogs.com/dong008259/archive/2011/12/07/2279897.html grep (global search regular exp ...
- springIOC源码接口分析(八):AutowireCapableBeanFactory
参考博文: https://blog.csdn.net/f641385712/article/details/88651128 一 接口规范 从宏观上看,AutowireCapableBeanFact ...