【Python3爬虫】反反爬之解决前端反调试问题
一、前言
在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕:

此时网页暂停加载,也就没法运行代码了,直接中断掉了,难道这就能阻止我们爬取了?不存在的,还是会有解决方案的。至于怎么做,请慢慢往下看。
二、调试
我们在了解代码的功能的时候,一般使用 JavaScript 调试工具(例如 DevTools)通过设置断点的方式来中断或阻止脚本代码的执行,而断点也是代码调试中最基本的了。
在 Chrome 中打开 DevTools,切换到 Source 选项,找到 JS 文件并打开,左下角有一个“{}”代表格式化文件,可以更方便地查看代码。然后就是设置断点了,找到可能出现问题的地方打上断点,再刷新页面,就可以直接鼠标移动到相关变量名或者方法上面查看它的值。如果想在运行到断点位置执行其它逻辑,可以直接在console区域运行相关脚本。
三、反调试
反调试就是在打开 DevTools 的时候,就会出现“Paused in debugger”,这个 debugger 导致我们无法调试 JS。
在反调试中,有时候会将函数进行重定义,并且改变其行为,就会将某些信息隐藏起来或者改变其中的一部分信息。
除了进行重定义,有的会进行混淆,例如使用语法树,还有的会进行加密,例如"_0x5219a6"这样的变量名,能很好地隐藏信息。
四、示例1
1.问题分析
一种简单的反调试措施是通过在代码中添加 debugger 实现,通过 debugger 阻止非法用户调试代码,让其陷入死循环,甚至有的还会使用匿名函数,例如:
setInterval(function() {debugger}, 100);
打开 DevTools 时就会出现“Paused in debugger”,网页也就加载中断了。
2.解决方案
这种问题解决起来还是很容易的,总结起来就是四个字:禁止断点。
在 Source 页面右侧按钮找到“Deactivate breakpoints”,或者使用快捷键 Ctrl + F8,如下图:

除了这种解决方案,还可以找到 debugger 那一行,然后右键选择“Never pause here”,就会出现一盒黄色的箭头,如下图:
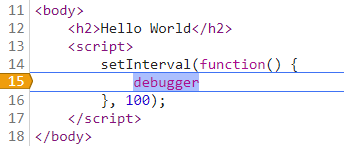
设置完之后,继续运行代码就行了。
不过这种方案和代码的编写风格有关系,例如下面这种情况,设置“Never pause here”就没用了。
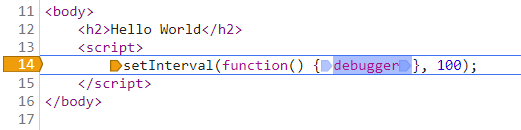
五、示例2
1.问题分析
复杂一点的反调试措施就不是直接在代码中加入 debugger 了,而是将其隐藏起来,这样就不会很轻易地被人发现了,例如下面这段代码:
function t() {try {var a = ["r", "e", "g", "g", "u", "b", "e", "d"].reverse().join("");! function e(n) {(1 !== ("" + n / n).length || 0 === n) && function() {}.constructor(a)(),e(++n)}(0)} catch (a) {setTimeout(t, 500)}}
这段代码首先是设置变量 a 表示字符串“debugger”,然后使用 constructor() 来实现调用 debugger 方法,再使用 setTimeout 实现每0.5秒中断一次。
2.解决方案
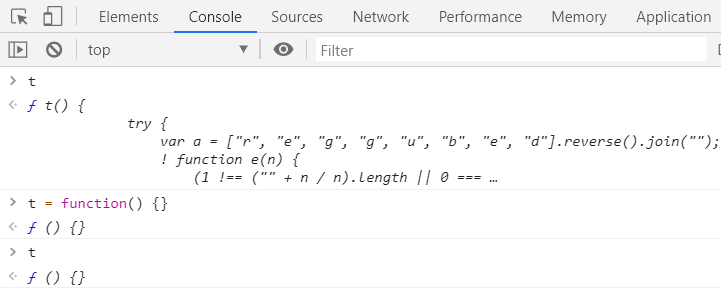
将反调试具名函数重新定义一遍,然后重新打开 DevTools,就能进行调试了。对于上面的例子,可以在控制台中输入以下内容:
t = function() {}
通过下面的截图可以发现我们确实已经修改了对于 t 的定义,因而也就不会进入 debugger 了:
【Python3爬虫】反反爬之解决前端反调试问题的更多相关文章
- 【Python3爬虫】突破反爬之应对前端反调试手段
一.前言 在我们爬取某些网站的时候,会想要打开 DevTools 查看元素或者抓包分析,但按下 F12 的时候,却出现了下面这一幕: 此时网页暂停加载,自动跳转到 Source 页面并打开了一个 ...
- python3爬虫-快速入门-爬取图片和标题
直接上代码,先来个爬取豆瓣图片的,大致思路就是发送请求-得到响应数据-储存数据,原理的话可以先看看这个 https://www.cnblogs.com/sss4/p/7809821.html impo ...
- python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言 作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始. 一.分析观察爬取网站结构 这里以广州链家二手房为例:http:/ ...
- python3爬虫-使用requests爬取起点小说
import requests from lxml import etree from urllib import parse import os, time def get_page_html(ur ...
- 【Python3 爬虫】14_爬取淘宝上的手机图片
现在我们想要使用爬虫爬取淘宝上的手机图片,那么该如何爬取呢?该做些什么准备工作呢? 首先,我们需要分析网页,先看看网页有哪些规律 打开淘宝网站http://www.taobao.com/ 我们可以看到 ...
- 【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一.写在前面 直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选 ...
- python3 [爬虫实战] selenium 爬取安居客
我们爬取的网站:https://www.anjuke.com/sy-city.html 获取的内容:包括地区名,地区链接: 安居客详情 一开始直接用requests库进行网站的爬取,会访问不到数据的, ...
- python3爬虫-通过requests爬取图虫网
import requests from fake_useragent import UserAgent from requests.exceptions import Timeout from ur ...
- 【Python3 爬虫】17_爬取天气信息
需求说明 到网站http://lishi.tianqi.com/kunming/201802.html可以看到昆明2018年2月份的天气信息,然后将数据存储到数据库. 实现代码 #-*-coding: ...
随机推荐
- 模板—tarjan求割点
int dfn[MAXN],low[MAXN],cnt,root; bool iscut[MAXN]; void tarjan(int x) { dfn[x]=low[x]=++cnt; ; for( ...
- 学linux内核与学linux操作系统有什么区别!?
linux内核包括:进程管理,存储管理,IO管理,文件系统等功能.linux操作系统则是linux内核再加上像shell或图形界面和其他的实用软件,比内核庞大的多.建议先学shell命令和linux下 ...
- 获取select文本框的下拉菜单文字内容的两种方式
<body> <div class="box"> <select id="sel"> <option value=&q ...
- Android 高仿微信(QQ)滑动弹出编辑、删除菜单效果,增加下拉刷新功能
不可否认,微信.QQ列表的滑动删除.编辑功能着实很经典(从IOS那边模仿过来的),然.Android这边,对列表的操作,其实大多还停留上下文菜单来实现. Android如何实现list item的滑动 ...
- Android 使用SystemBarTint设置状态栏颜色
做项目时,发现APP的状态栏是系统默认的颜色,突然想到,为啥别的APP是自己设置的颜色(和APP本身很相搭),于是也想给自己的APP设置系统状态栏的颜色,更加美美哒... 搜了下,发现原来设置状态栏居 ...
- day1-初识Python之变量
1.python安装与环境配置 1.1.Windows下的python解释器安装 打开官网 https://www.python.org/downloads/windows/ 下载中心 测试安装是否成 ...
- oracle 尽量多使用COMMIT
只要有可能,在程序中尽量多使用COMMIT, 这样程序的性能得到提高,需求也会因为COMMIT所释放的资源而减少: COMMIT所释放的资源: a. 回滚段上用于恢复数据的信息. b. ...
- [转][ASP.NET Core 3框架揭秘] 跨平台开发体验: Windows [中篇]
我们在<上篇>利用dotnet new命令创建了一个简单的控制台程序,接下来我们将它改造成一个ASP.NET Core应用.一个ASP.NET Core应用构建在ASP.NET Core框 ...
- poj 3278(hdu 2717) Catch That Cow(bfs)
Catch That Cow Time Limit: 5000/2000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)To ...
- scala资料总结,一些小技巧
scala资料总结,一些小技巧 1.得到每种数据类型所表示的范围 Short.MaxValue 32767 Short.MinValue -32768 Int.MaxValue 2147483647 ...