GNE: 4行代码实现新闻类网站通用爬虫
GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容、标题、作者、发布时间、正文中的图片地址和正文所在的标签源代码。GNE在提取今日头条、网易新闻、游民星空、 观察者网、凤凰网、腾讯新闻、ReadHub、新浪新闻等数百个中文新闻网站上效果非常出色,几乎能够达到100%的准确率。
使用方式非常简单:
from gne import GeneralNewsExtractor
extractor = GeneralNewsExtractor()
html = '网站源代码'
result = extractor.extract(html)
print(result)
GNE 的输入是经过 js 渲染以后的 HTML 代码,所以 GNE 可以配合Selenium 或者 Pyppeteer 使用。
下图是 GNE 配合 Selenium 实现的一个 Demo:
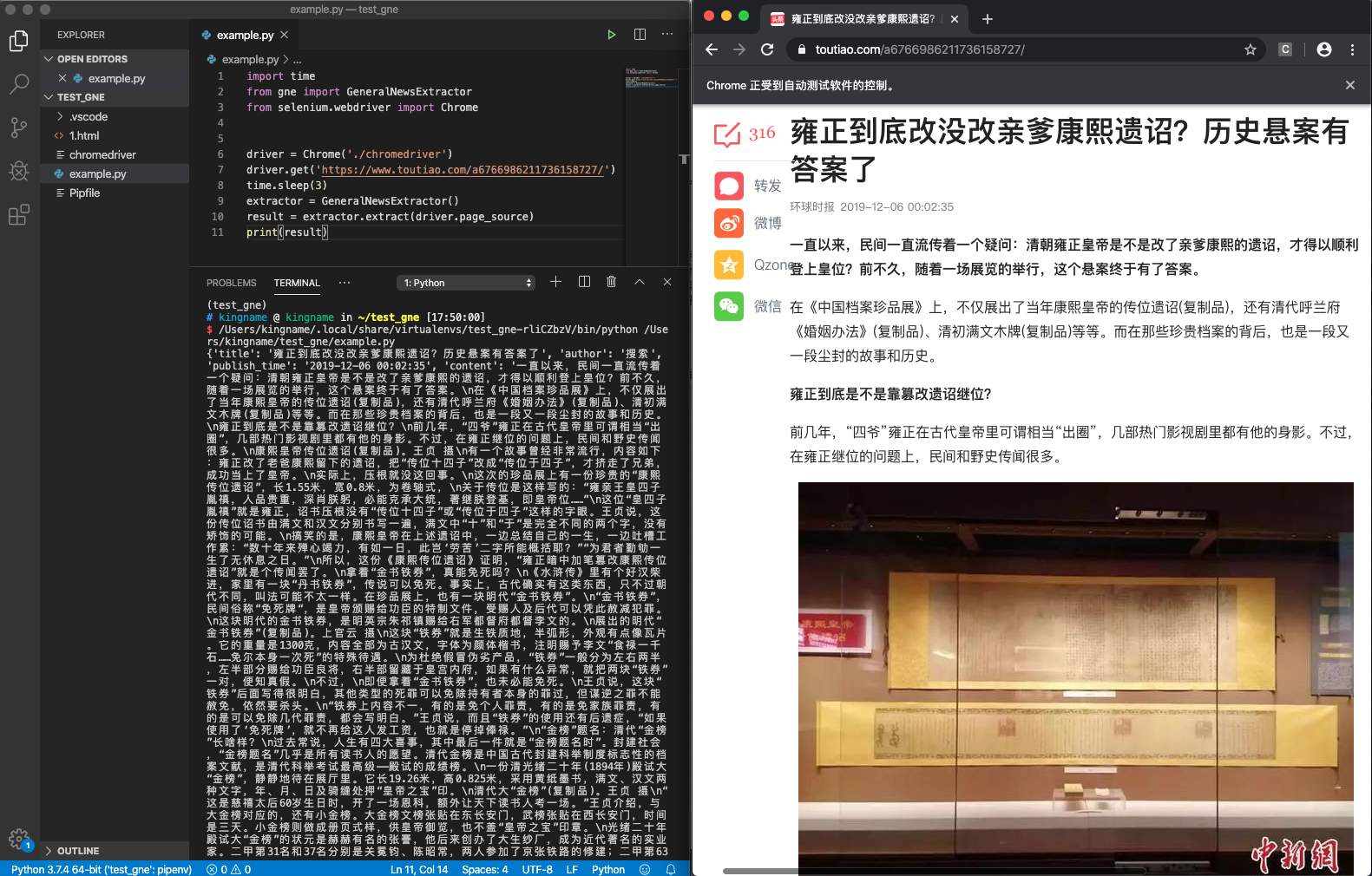
对应的代码为:
import time
from gne import GeneralNewsExtractor
from selenium.webdriver import Chrome
driver = Chrome('./chromedriver')
driver.get('https://www.toutiao.com/a6766986211736158727/')
time.sleep(3)
extractor = GeneralNewsExtractor()
result = extractor.extract(driver.page_source)
print(result)
下图是 GNE 配合 Pyppeteer 实现的 Demo:
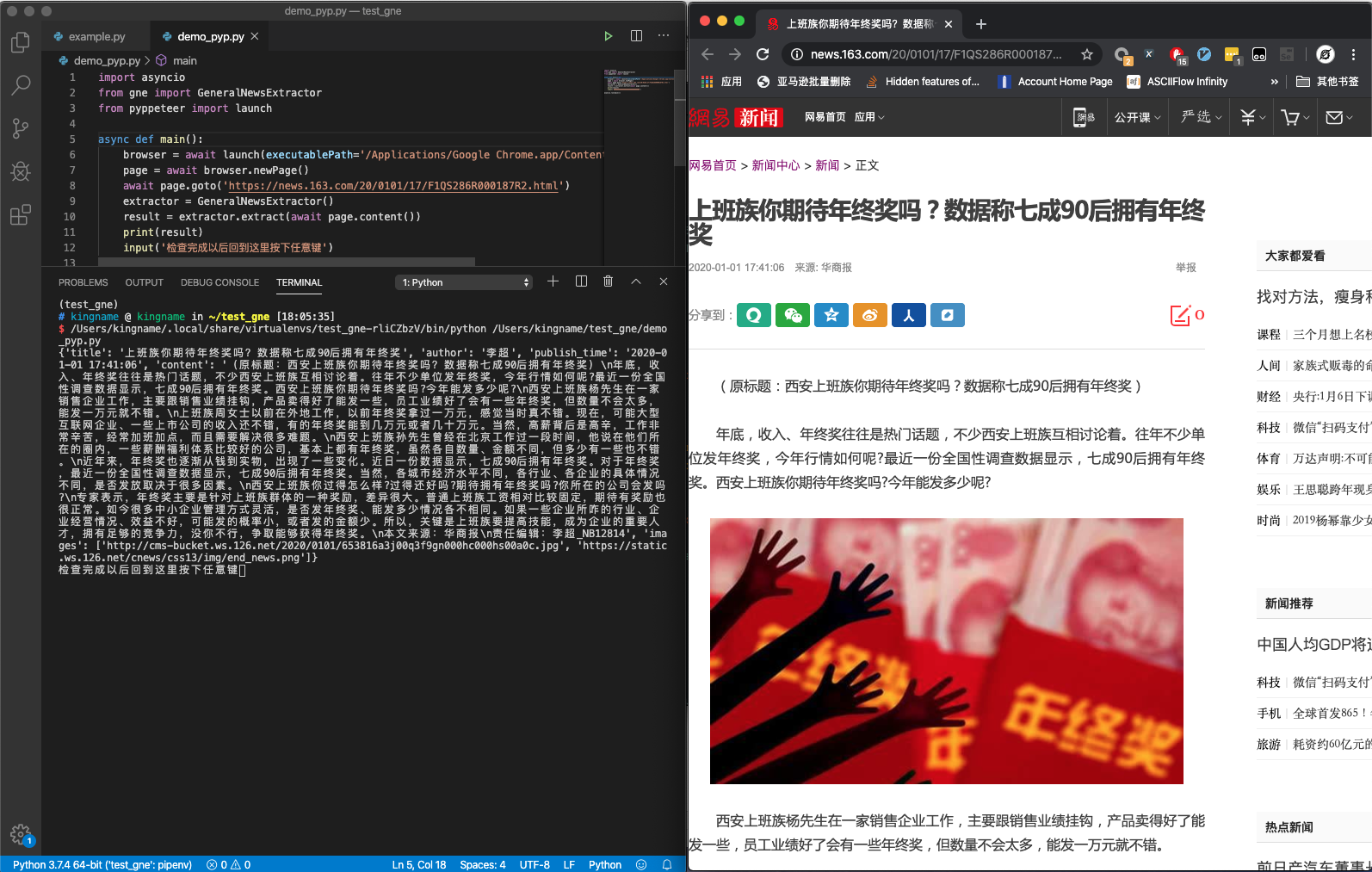
对应代码如下:
import asyncio
from gne import GeneralNewsExtractor
from pyppeteer import launch
async def main():
browser = await launch(executablePath='/Applications/Google Chrome.app/Contents/MacOS/Google Chrome')
page = await browser.newPage()
await page.goto('https://news.163.com/20/0101/17/F1QS286R000187R2.html')
extractor = GeneralNewsExtractor()
result = extractor.extract(await page.content())
print(result)
input('检查完成以后回到这里按下任意键')
asyncio.run(main())
如何安装 GNE
现在你可以直接使用 pip 安装 GNE 了:
pip install gne
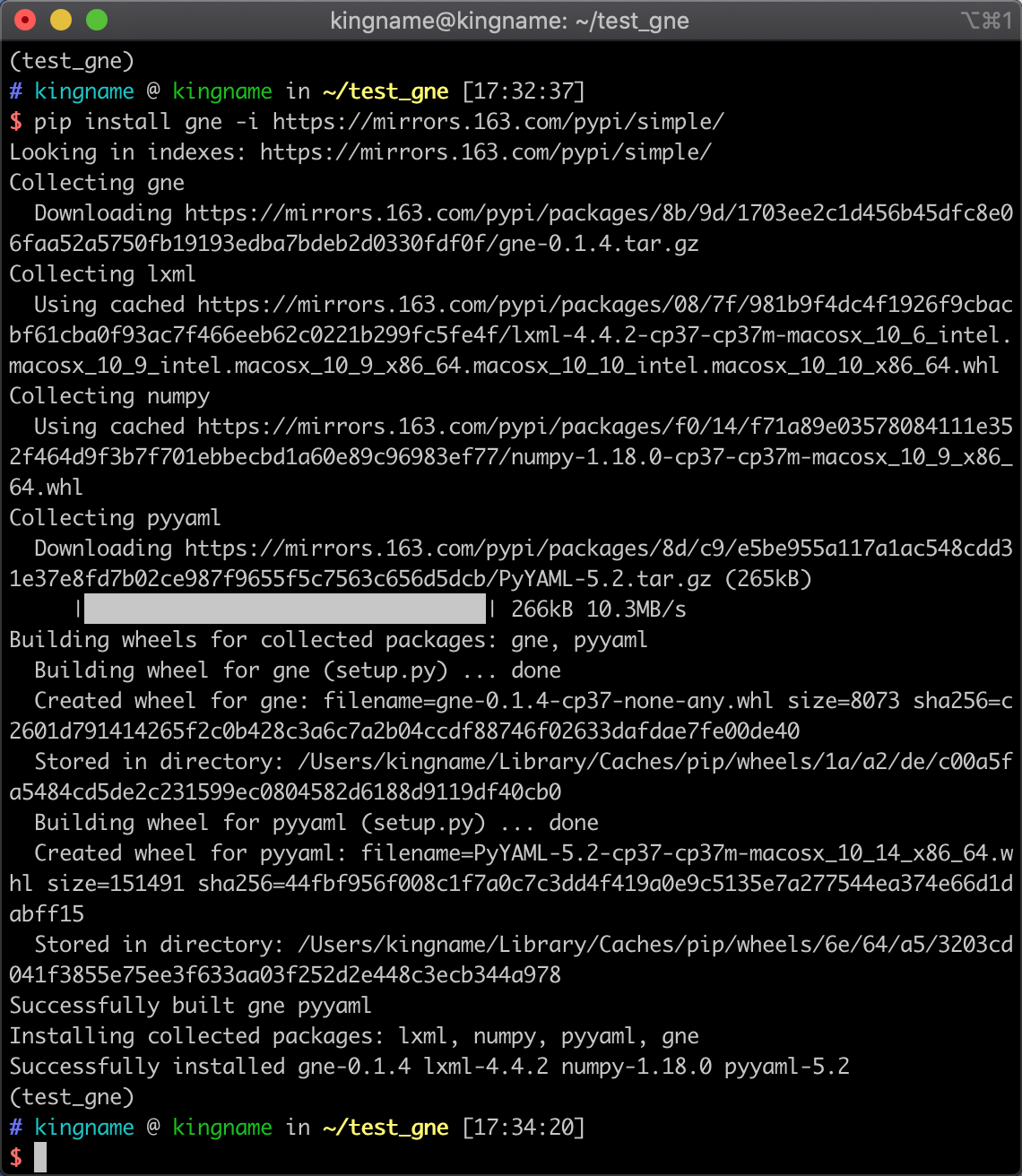
如果访问pypi 官方源太慢,你也可以使用网易源:
pip install gne -i https://mirrors.163.com/pypi/simple/
安装过程如下图所示:
功能特性
获取正文源代码
在extract()方法只传入网页源代码,不添加任何额外参数时,GNE 返回如下字段:
- title:新闻标题
- publish_time:新闻发布时间
- author:新闻作者
- content:新闻正文
- images: 正文中的图片(相对路径或者绝对路径)
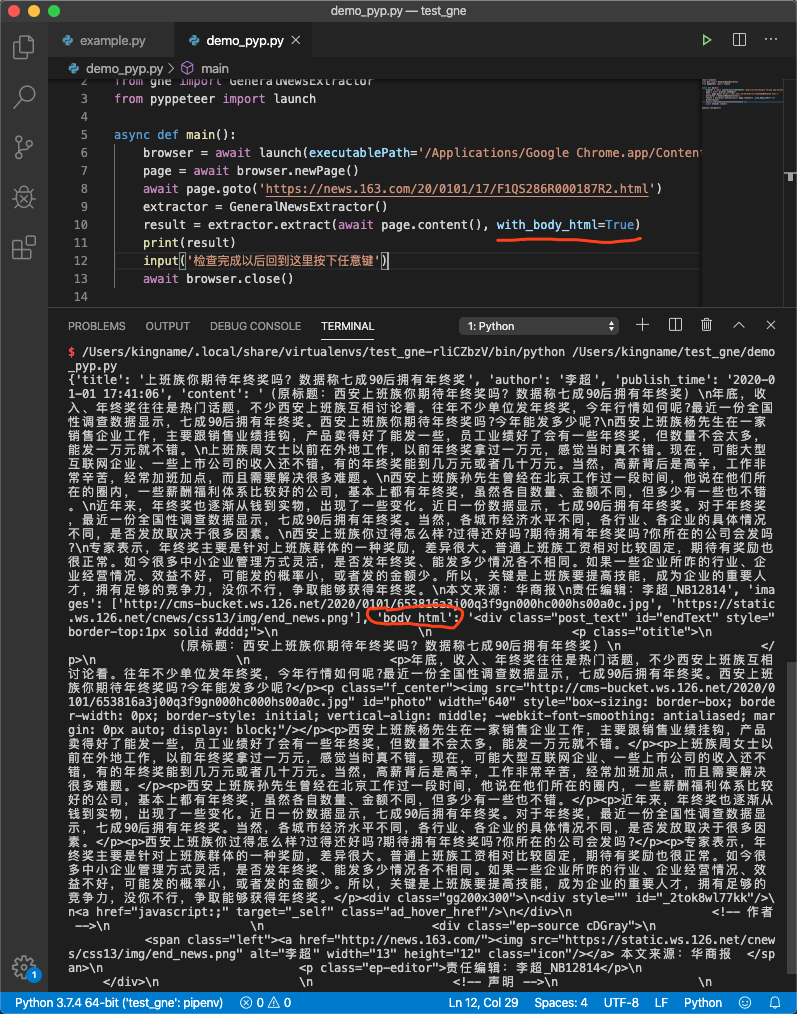
可能有些朋友希望获取新闻正文所在标签的源代码,此时可以给extract()方法传入with_body_html参数,设置为 True:
extractor = GeneralNewsExtractor()
extractor.extract(html, with_body_html=True)
返回数据中将会增加一个字段body_html,它的值就是正文对应的 HTML 源代码。
运行效果如下图所示:
总是返回图片的绝对路径
默认情况下,如果新闻中的图片使用的是相对路径,那么 GNE 返回的images字段对应的值也是图片相对路径的列表。
如果你想始终让 GNE 返回绝对路径,那么你可以给extract()方法增加host参数,这个参数的值是图片的域名,例如:
extractor = GeneralNewsExtractor()
extractor.extract(html, host='https://www.kingname.info')
这样,如果新闻中的图片是/images/pic.png,那么 GNE 返回时会自动把它变为https://www.kingname.info/images/pic.png。
指定新闻标题所在的 XPath
GNE 预定义了一组 XPath 和正则表达式用于提取新闻的标题。但某些特殊的新闻网站可能无法提取标题,此时,你可以给extract()方法指定title_xpath参数,用于提取新闻标题:
extractor = GeneralNewsExtractor()
extractor.extract(html, title_xpath='//title/text()')
提前移除噪声标签
某些新闻下面可能会存在长篇大论的评论,这些评论看起来比新闻正文“更像”正文,为了防止他们干扰新闻的提取,可以通过给extract()方法传入noise_node_list参数,提前把这些噪声节点移除。noise_node_list的值是一个列表,里面是一个或多个 XPath:
extractor = GeneralNewsExtractor()
extractor.extract(html, noise_node_list=['//div[@class="comment-list"]', '//*[@style="display:none"]'])
使用配置文件
API 中的参数 title_xpath、 host、 noise_node_list、 with_body_html除了直接写到 extract() 方法中外,还可以通过一个配置文件来设置。
请在项目的根目录创建一个文件 .gne,配置文件可以用 YAML 格式,也可以使用 JSON 格式。
- YAML 格式配置文件
title:
xpath: //title/text()
host: https://www.xxx.com
noise_node_list:
- //div[@class=\"comment-list\"]
- //*[@style=\"display:none\"]
with_body_html: true
- JSON 格式配置文件
{
"title": {
"xpath": "//title/text()"
},
"host": "https://www.xxx.com",
"noise_node_list": ["//div[@class=\"comment-list\"]",
"//*[@style=\"display:none\"]"],
"with_body_html": true
}
这两种写法是完全等价的。
配置文件与 extract() 方法的参数一样,并不是所有字段都需要提供。你可以组合填写你需要的字段。
如果一个参数,既在 extract() 方法中,又在 .gne 配置文件中,但值不一样,那么 extract() 方法中的这个参数的优先级更高。
FAQ
GeneralNewsExtractor(以下简称GNE)是爬虫吗?
GNE不是爬虫,它的项目名称General News Extractor表示通用新闻抽取器。它的输入是HTML,输出是一个包含新闻标题,新闻正文,作者,发布时间的字典。你需要自行设法获取目标网页的HTML。
GNE 现在不会,将来也不会提供请求网页的功能。
GNE支持翻页吗?
GNE不支持翻页。因为GNE不会提供网页请求的功能,所以你需要自行获取每一页的HTML,并分别传递给GNE。
GNE支持哪些版本的Python?
不小于Python 3.6.0
我用requests/Scrapy获取的HTML传入GNE,为什么不能提取正文?
GNE是基于HTML来提取正文的,所以传入的HTML一定要是经过JavaScript渲染以后的HTML。而requests和Scrapy获取的只是JavaScript渲染之前的源代码,所以无法正确提取。
另外,有一些网页,例如今日头条,它的新闻正文实际上是以JSON格式直接写在网页源代码的,当页面在浏览器上面打开的时候,JavaScript把源代码里面的正文解析为HTML。这种情况下,你在Chrome上面就看不到Ajax请求。
所以建议你使用Puppeteer/Pyppeteer/Selenium之类的工具获取经过渲染的HTML再传入GNE。
GNE 支持非新闻类网站吗(例如博客、论坛……)
不支持。
关于 GNE
GNE 官方文档:https://generalnewsextractor.readthedocs.io/
GNE 的项目源代码在:https://github.com/kingname/GeneralNewsExtractor。
关于作者

GNE: 4行代码实现新闻类网站通用爬虫的更多相关文章
- 新闻类网站的通用爬虫--GNE
GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容.标题.作者.发布时间.正文中的图片地址和正文所在的标签源代码.GNE在提 ...
- 新闻类网站rss接口的编写心得
使用的是Jdom中的相关API,具体步骤如下 要求的格式: <rss xmlns:content="http://purl.org/rss/1.0/modules/content/&q ...
- Python 教你 4 行代码开发新闻网站通用爬虫
\ GNE(GeneralNewsExtractor)是一个通用新闻网站正文抽取模块,输入一篇新闻网页的 HTML, 输出正文内容.标题.作者.发布时间.正文中的图片地址和正文所在的标签源代码.G ...
- 只写104行代码!在nopCommerce中如何实现自动生成网站地图
表告诉我说你不知道nopCommerce是什么.它是目前.NET中最流行的完全开源网上商城,由俄罗斯的团队在2008年开始立项一直开发到现在已经是3.3版本了.代码目前托管在codeplex上,有兴趣 ...
- 利用反射和泛型把Model对象按行储存进数据库以及按行取出然后转换成Model 类实例 MVC网站通用配置项管理
利用反射和泛型把Model对象按行储存进数据库以及按行取出然后转换成Model 类实例 MVC网站通用配置项管理 2018-3-10 15:18 | 发布:Admin | 分类:代码库 | 评论: ...
- java代码行数统计工具类
package com.syl.demo.test; import java.io.*; /** * java代码行数统计工具类 * Created by 孙义朗 on 2017/11/17 0017 ...
- Kotlin的数据类:节省很多行代码(KAD 10)
作者:Antonio Leiva 时间:Jan 25, 2017 原文链接:https://antonioleiva.com/data-classes-kotlin/ 在前面的文章中,我们已经见到了类 ...
- java处理高并发高负载类网站的优化方法
java处理高并发高负载类网站中数据库的设计方法(java教程,java处理大量数据,java高负载数据) 一:高并发高负载类网站关注点之数据库 没错,首先是数据库,这是大多数应用所面临的首个SPOF ...
- 用react开发一个新闻列表网站(PC和移动端)
最近在学习react,试着做了一个新闻类的网站,结合ant design框架, 并且可以同时在PC和移动端运行: 主要包含登录和注册组件.头部和脚部组件.新闻块类组件.详情页组件.评论和收藏组件等: ...
随机推荐
- 阿里大数据产品Dataphin上线公共云,将助力更多企业构建数据中台
日前,由阿里数据打造的智能数据构建与管理Dataphin,重磅上线阿里云-公共云,开启智能研发版本的公共云公测!在此之前,Dataphin以独立部署方式输出并服务线下客户,已助力多家大型客户高效自动化 ...
- redhat6.5安装oracle11_2R
参照前人一步一步操作: http://leihenzhimu.blog.51cto.com/3217508/1685164 遇到如下错误: This is a prerequisite conditi ...
- 【学生研究课题】CSDN博客数据获取、分析、分享
题记 这次<对象程序设计>课程设计,一共给定了8个选题(下载WORD版.PDF版),以及自由选题的机会.从大家初步选题结果来看(图1).绝大部分同学选择了"图形用户界面的 ...
- HZOJ visit
对于前30%的数据,可以考虑dp,f[i][j][k]表示时间为i,在i,j位置的方案数,枚举转移即可.要注意的是可以走到矩阵外. 对于另外30%数据,考虑推一下式子,设向右走y步,左z,上s,下x. ...
- Mybatis/Ibatis,数据库操作的返回值
该问题,我百度了下,根本没发现什么有价值的文章:还是看源代码(详见最后附录)中的注释,最有效了!insert,返回值是:新插入行的主键(primary key):需要包含<selectKey&g ...
- poj 1689 && zoj 1422 3002 Rubbery (Geometry + BFS)
ZOJ :: Problems :: Show Problem 1689 -- 3002 Rubbery 这题是从校内oj的几何分类里面找到的. 题意不难,就是给出一个区域(L,W),这个区域里面有很 ...
- 洛谷 2403 [SDOI2010] 所驼门王的宝藏
题目描述 在宽广的非洲荒漠中,生活着一群勤劳勇敢的羊驼家族.被族人恭称为“先知”的Alpaca L. Sotomon是这个家族的领袖,外人也称其为“所驼门王”.所驼门王毕生致力于维护家族的安定与和谐, ...
- 洛谷P1488 肥猫的游戏 题解 博弈论入门
题目链接:https://www.luogu.org/problem/P1488 其实这道题目我只需要 \(n\) 以及黑色三角形的三个端点编号就可以了. 我们假设在一个 \(n\) 边形中,黑色三角 ...
- SpringBoot2集成Activiti6
Activiti是领先的轻量级的,以Java为中心的开源BPMN(Business Process Modeling Notation)引擎,实现了真正的流程自动化.下面介绍如何在SpringBoot ...
- 微信小程序中 不点击picker 点击一个button 怎么调用picker 弹出选择框
把按钮放在picker区域里就好了 picker本身就是一个区域 <picker mode = "selector" class='info' bindchange=&quo ...