小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)

人生苦短,我用 Python
前文传送门:
小白学 Python 爬虫(2):前置准备(一)基本类库的安装
小白学 Python 爬虫(3):前置准备(二)Linux基础入门
小白学 Python 爬虫(4):前置准备(三)Docker基础入门
小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
小白学 Python 爬虫(10):Session 和 Cookies
小白学 Python 爬虫(11):urllib 基础使用(一)
小白学 Python 爬虫(12):urllib 基础使用(二)
小白学 Python 爬虫(13):urllib 基础使用(三)
小白学 Python 爬虫(14):urllib 基础使用(四)
小白学 Python 爬虫(15):urllib 基础使用(五)
小白学 Python 爬虫(16):urllib 实战之爬取妹子图
小白学 Python 爬虫(17):Requests 基础使用
小白学 Python 爬虫(18):Requests 进阶操作
小白学 Python 爬虫(21):解析库 Beautiful Soup(上)
小白学 Python 爬虫(22):解析库 Beautiful Soup(下)
小白学 Python 爬虫(23):解析库 pyquery 入门
小白学 Python 爬虫(26):为啥买不起上海二手房你都买不起
小白学 Python 爬虫(27):自动化测试框架 Selenium 从入门到放弃(上)
小白学 Python 爬虫(28):自动化测试框架 Selenium 从入门到放弃(下)
小白学 Python 爬虫(29):Selenium 获取某大型电商网站商品信息
小白学 Python 爬虫(31):自己构建一个简单的代理池
小白学 Python 爬虫(32):异步请求库 AIOHTTP 基础入门
引言
首先恭喜看到这篇文章的各位同学,从这篇文章开始,整个小白学 Python 爬虫系列进入最后一部分,小编计划是介绍一些常用的爬虫框架。
说到爬虫框架,首先绕不过去的必然是 Scrapy 。
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰,模块之间的耦合程度低,可扩展性极强,可以灵活完成各种需求。
当然第一件事儿还是各种官方地址:
Scrapy 官网: https://scrapy.org/
Github:https://github.com/scrapy/scrapy
架构概述
首先看一下 Scrapy 框架的架构体系图:
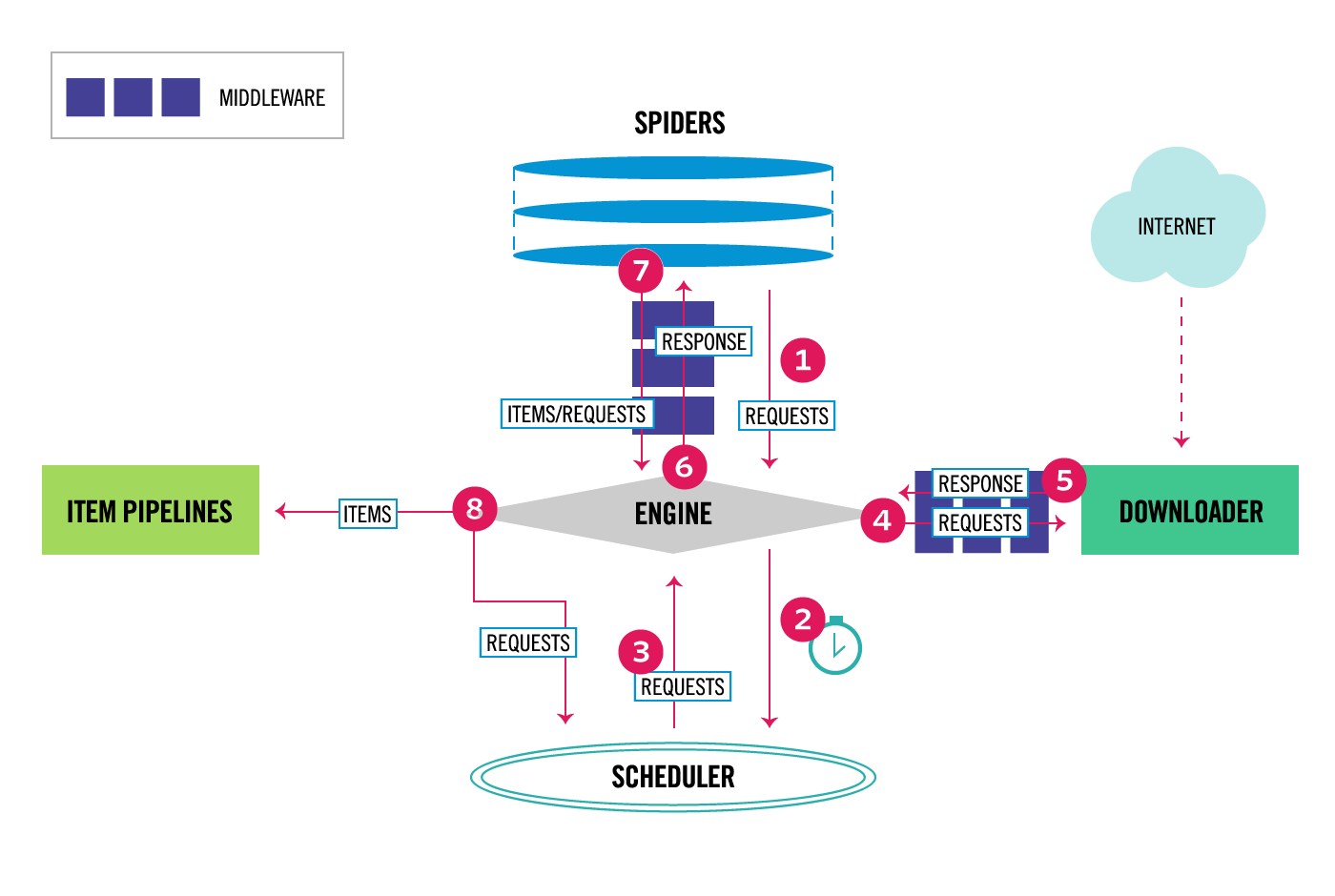
从这张图中,可以看到 Scrapy 分成了很多个组件,每个组件的含义如下:
- Engine 引擎:引擎负责控制系统所有组件之间的数据流,并在发生某些操作时触发事件。
- Item 项目:它定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
- Scheduler 调度器:用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。
- Downloader 下载器:下载器负责获取网页并将其馈送到引擎,引擎又将其馈给蜘蛛。
- Spiders 蜘蛛:其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
- Item Pipeline 项目管道:负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader Middlewares 下载器中间件:下载器中间件是位于引擎和Downloader之间的特定挂钩,它们在从引擎传递到Downloader时处理请求,以及从Downloader传递到Engine的响应。
- Spider Middlewares 蜘蛛中间件:蜘蛛中间件是位于引擎和蜘蛛之间的特定挂钩,并且能够处理蜘蛛的输入(响应)和输出(项目和请求)。
上面这张图的数据流程如下:
- 该引擎获取从最初请求爬行 蜘蛛。
- 该引擎安排在请求 调度程序和要求下一个请求爬行。
- 该计划返回下一请求的引擎。
- 该引擎发送请求到 下载器,通过 下载器中间件。
- 页面下载完成后, Downloader会生成一个带有该页面的响应,并将其发送到Engine,并通过 Downloader Middlewares。
- 该引擎接收来自响应 下载器并将其发送到所述 蜘蛛进行处理,通过蜘蛛中间件。
- 该蜘蛛处理响应并返回刮下的项目和新的要求(跟随)的 引擎,通过 蜘蛛中间件。
- 该引擎发送处理的项目,以 项目管道,然后把处理的请求的调度,并要求今后可能请求爬行。
- 重复该过程(从步骤1开始),直到不再有Scheduler的请求为止 。
这张图的名词有些多,记不住实属正常,不过没关系,后续小编会配合着示例代码,和各位同学一起慢慢的学习。
基础示例
先来个最简单的示例项目,在创建项目之前,请确定自己的环境已经正确安装了 Scrapy ,如果没有安装的同学可以看下前面的文章,其中有介绍 Scrapy 的安装配置。
首先需要创建一个 Scrapy 的项目,创建项目需要使用命令行,在命令行中输入以下命令:
scrapy startproject first_scrapy
然后一个名为 first_scrapy 的项目就创建成功了,项目文件结构如下:
first_scrapy/
scrapy.cfg # deploy configuration file
first_scrapy/ # project's Python module, you'll import your code from here
__init__.py
items.py # project items definition file
middlewares.py # project middlewares file
pipelines.py # project pipelines file
settings.py # project settings file
spiders/ # a directory where you'll later put your spiders
__init__.py
- scrapy.cfg:它是 Scrapy 项目的配置文件,其内定义了项目的配置文件路径、部署相关信息等内容。
- items.py:它定义 Item 数据结构,所有的 Item 的定义都可以放这里。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:它定义项目的全局配置。
- middlewares.py:它定义 Spider Middlewares 和 Downloader Middlewares 的实现。
- spiders:其内包含一个个 Spider 的实现,每个 Spider 都有一个文件。
到此,我们已经成功创建了一个 Scrapy 项目,但是这个项目目前是空的,我们需要再手动添加一只 Spider 。
Scrapy 用它来从网页里抓取内容,并解析抓取的结果。不过这个类必须继承 Scrapy 提供的 Spider 类 scrapy.Spider,还要定义 Spider 的名称和起始请求,以及怎样处理爬取后的结果的方法。
创建 Spider 可以使用手动创建,也可以使用命令创建,小编这里演示一下如何使用命令来创建,如下:
scrapy genspider quotes quotes.toscrape.com
将会看到在 spider 目录下新增了一个 QuotesSpider.py 的文件,里面的内容如下:
# -*- coding: utf-8 -*-
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
可以看到,这个类里面有三个属性 name 、 allowed_domains 、 start_urls 和一个 parse() 方法。
- name,它是每个项目唯一的名字,用来区分不同的 Spider。
- allowed_domains,它是允许爬取的域名,如果初始或后续的请求链接不是这个域名下的,则请求链接会被过滤掉。
- start_urls,它包含了 Spider 在启动时爬取的 url 列表,初始请求是由它来定义的。
- parse,它是 Spider 的一个方法。默认情况下,被调用时 start_urls 里面的链接构成的请求完成下载执行后,返回的响应就会作为唯一的参数传递给这个函数。该方法负责解析返回的响应、提取数据或者进一步生成要处理的请求。
到这里我们就清楚了, parse() 方法中的 response 是前面的 start_urls 中链接的爬取结果,所以在 parse() 方法中,我们可以直接对爬取的结果进行解析。
先看下网页的 DOM 结构:
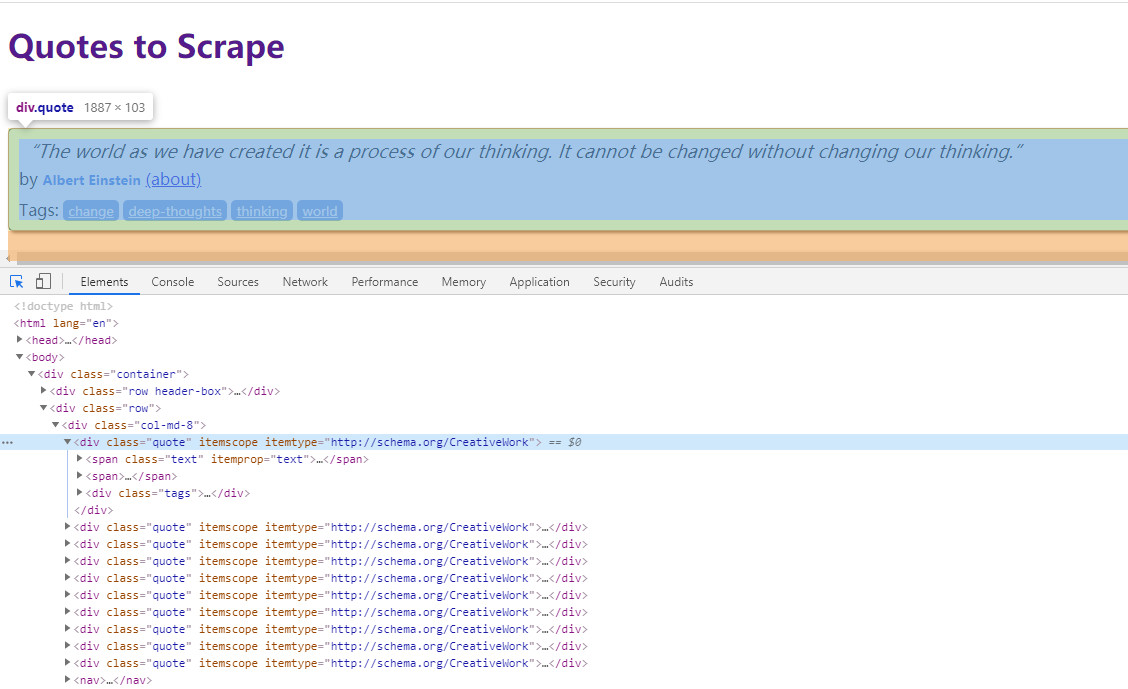
接下来要做的事情就比较简单了,获取其中的数据,然后将其打印出来。
数据提取的方式可以是 CSS 选择器也可以是 XPath 选择器,小编这里使用的是 CSS 选择器,将我们刚才的 parse() 方法进行一些简单的改动,如下:
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
author = quote.css('.author::text').extract_first()
tags = quote.css('.tags .tag::text').extract()
print("text:", text)
print("author:", author)
print("tags:", tags)
首先是获取到所有的 class 为 quote 的元素,然后将所有元素进行循环后取出其中的数据,最后对这些数据进行打印。
程序到这里就写完了,那么接下来的问题是,我们如何运行这只爬虫?
Scrapy 的运行方式同样适用适用命令行的,首先要到这个项目的根目录下,然后执行以下代码:
scrapy crawl quotes
结果如下:
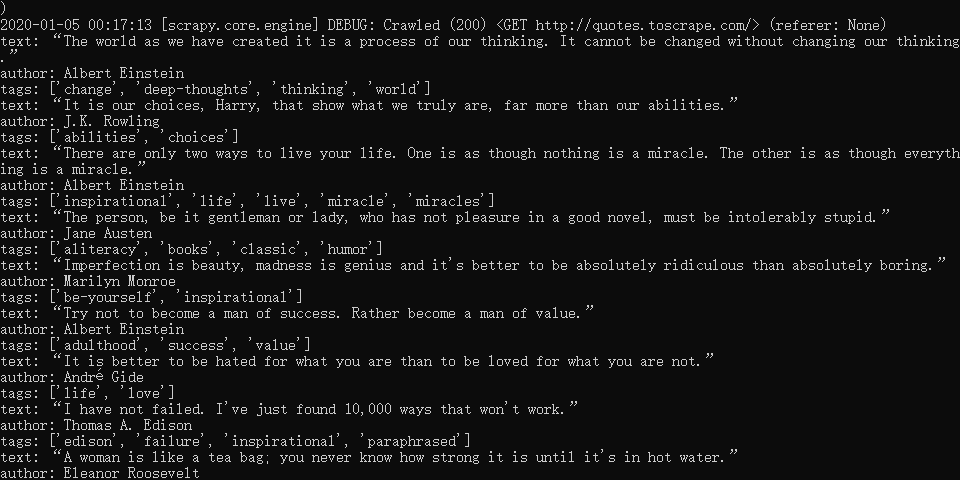
可以看到,我们刚才 print() 的内容正常的打印在了命令行中。
除了我们 print() 中的内容的打印,还可以看到在 Scrapy 启动的过程中, Scrapy 输出了当前的版本号以及正在启动的项目名称,并且在爬取网页的过程中,首先访问了 http://quotes.toscrape.com/robots.txt 机器人协议,虽然这个协议在当前这个示例中响应了 404的状态码,但是 Scrapy 会根据机器人协议中的内容进行爬取。
示例代码
本系列的所有代码小编都会放在代码管理仓库 Github 和 Gitee 上,方便大家取用。
参考
https://docs.scrapy.org/en/latest/intro/tutorial.html
https://docs.scrapy.org/en/latest/topics/architecture.html
https://cuiqingcai.com/8337.html
小白学 Python 爬虫(33):爬虫框架 Scrapy 入门基础(一)的更多相关文章
- 小白学 Python 爬虫(34):爬虫框架 Scrapy 入门基础(二)
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(35):爬虫框架 Scrapy 入门基础(三) Selector 选择器
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(36):爬虫框架 Scrapy 入门基础(四) Downloader Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(37):爬虫框架 Scrapy 入门基础(五) Spider Middleware
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(38):爬虫框架 Scrapy 入门基础(六) Item Pipeline
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(40):爬虫框架 Scrapy 入门基础(七)对接 Selenium 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 爬虫(41):爬虫框架 Scrapy 入门基础(八)对接 Splash 实战
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
- 小白学 Python 数据分析(1):数据分析基础
各位同学好,小编接下来为大家分享一些有关 Python 数据分析方面的内容,希望大家能够喜欢. 人工植入广告: PS:小编最近两天偷了点懒,好久没有发原创了,最近是在 CSDN 开通了一个付费专栏,用 ...
- 小白学 Python 爬虫(39): JavaScript 渲染服务 scrapy-splash 入门
人生苦短,我用 Python 前文传送门: 小白学 Python 爬虫(1):开篇 小白学 Python 爬虫(2):前置准备(一)基本类库的安装 小白学 Python 爬虫(3):前置准备(二)Li ...
随机推荐
- 如何使用jmeter调用soap协议
- java一般处理高并发的技术手段
应对高并发的解决方案: 1.将压力放在数据库上面,添加行级锁. select * from table for update; 2.将压力放在应用程序上面,对方法加synchronized同步.
- css样式书写规范
在工作当中css样式是非常重要的,但是咋样书写css样式更重要. 一.css书写规范 1.定位属性:position display float left top right bottom ...
- Java多线程遍历文件夹,广度遍历加多线程加深度遍历结合
复习IO操作,突然想写一个小工具,统计一下电脑里面的Java代码量还有注释率,最开始随手写了一个递归算法,遍历文件夹,比较简单,而且代码层次清晰,相对易于理解,代码如下:(完整代码贴在最后面,前面是功 ...
- 三种查看MySQL数据库版本的方法
https://blog.csdn.net/hj7jay/article/details/51921504 1.使用-V参数 首先我们想到的肯定就是查看版本号的参数命令,参数为-V(大写字母)或者-- ...
- Vue 父组件与子组件的传值
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- codeforce 379(div.2)
A.B略 C题 ——贪心,二分查找: 对于每一个a[i], 在d中二分查找 s-b[i],注意不要忘记计算速度为x时需要花费的最小时间,以及整数范围为64位整数 1 #include <cstd ...
- vue 使用webpack打包后路径报错以及 alias 的使用
一.vue 使用webpack打包后路径报错(两步解决) 1. config文件夹 ==> index.js ==> 把assetsPublicPath的 '/ '改为 './' 2. b ...
- MVC3 学习笔记 之(ajax表单)
mvc 提供了一种ajax提交表单的方式.与普通表单不同的是,它是一个异步表单. 在开始使用之前,需要引用以下文件: <script src="@Url.Content("~ ...
- BAT 脚本判断当前系统是 x86 还是 x64 系统
本文告诉大家在写 BAT 脚本的时候,如何判断当前的系统是 32 位系统的还是 64 位系统 通过注册表进行判断方法 @echo OFF reg Query "HKLM\Hardware\D ...