NLP(二十一)人物关系抽取的一次实战
去年,笔者写过一篇文章利用关系抽取构建知识图谱的一次尝试,试图用现在的深度学习办法去做开放领域的关系抽取,但是遗憾的是,目前在开放领域的关系抽取,还没有成熟的解决方案和模型。当时的文章仅作为笔者的一次尝试,在实际使用过程中,效果有限。
本文将讲述如何利用深度学习模型来进行人物关系抽取。人物关系抽取可以理解为是关系抽取,这是我们构建知识图谱的重要一步。本文人物关系抽取的主要思想是关系抽取的pipeline(管道)模式,因为人名可以使用现成的NER模型提取,因此本文仅解决从文章中抽取出人名后,如何进行人物关系抽取。
本文采用的深度学习模型是文本分类模型,结合BERT预训练模型,取得了较为不错的效果。
本项目已经开源,Github地址为:https://github.com/percent4/people_relation_extract 。
本项目的项目结构图如下:
数据集介绍
在进行这方面的尝试之前,我们还不得不面对这样一个难题,那就是中文人物关系抽取语料的缺失。数据是模型的前提,没有数据,一切模型无从谈起。因此,笔者不得不花费大量的时间收集数据。
笔者利用大量自己业余的时间,收集了大约2900条人物关系样本,整理成Excel(文件名称为人物关系表.xlsx),其中几行如下:
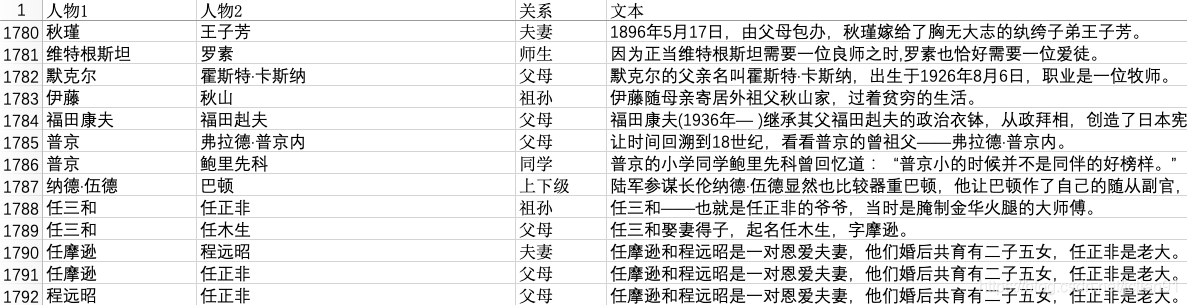
人物关系一共有14类,分别为unknown,夫妻,父母,兄弟姐妹,上下级,师生,好友,同学,合作,同人,情侣,祖孙,同门,亲戚,其中unknown类别表示该人物关系不在其余的13类中(人物之间没有关系或者为其他关系),同人关系指的是两个人物其实是同一个人,比如下面的例子:
邵逸夫(1907年10月4日—2014年1月7日),原名邵仁楞,生于浙江省宁波市镇海镇,祖籍浙江宁波。
上面的例子中,邵逸夫和邵仁楞就是同一个人。亲戚关系指的是除了夫妻,父母,兄弟姐妹,祖孙之外的亲戚关系,比如叔侄,舅甥关系等。
为了对该数据集的每个关系类别的数量进行统计,我们可以使用脚本data/relation_bar_chart.py,完整的Python代码如下:
# -*- coding: utf-8 -*-
# 绘制人物关系频数统计条形图
import pandas as pd
import matplotlib.pyplot as plt
# 读取EXCEL数据
df = pd.read_excel('人物关系表.xlsx')
label_list = list(df['关系'].value_counts().index)
num_list= df['关系'].value_counts().tolist()
# Mac系统设置中文字体支持
plt.rcParams["font.family"] = 'Arial Unicode MS'
# 利用Matplotlib绘制条形图
x = range(len(num_list))
rects = plt.bar(left=x, height=num_list, width=0.6, color='blue', label="频数")
plt.ylim(0, 500) # y轴范围
plt.ylabel("数量")
plt.xticks([index + 0.1 for index in x], label_list)
plt.xticks(rotation=45) # x轴的标签旋转45度
plt.xlabel("人物关系")
plt.title("人物关系频数统计")
plt.legend()
# 条形图的文字说明
for rect in rects:
height = rect.get_height()
plt.text(rect.get_x() + rect.get_width() / 2, height+1, str(height), ha="center", va="bottom")
plt.show()
运行后的结果如下:

unknown类别最多,有791条,其余的如祖孙, 亲戚, 情侣等较少,只有90多条,这是因为这类人物关系的数据缺失不好收集。因此,语料的收集费时费力,需要消耗大量的精力。
数据预处理
收集好数据后,我们需要对数据进行预处理,预处理主要分两步,一步是将人物关系和原文本整合在一起,第二步简单,将数据集划分为训练集和测试集,比例为8:2。
我们对第一步进行详细说明,将人物关系和原文本整合在一起。一般我们给定原文本和该文本中的两个人物,比如:
邵逸夫(1907年10月4日—2014年1月7日),原名邵仁楞,生于浙江省宁波市镇海镇,祖籍浙江宁波。
这句话中有两个人物:邵逸夫,邵仁楞, 这个容易在语料中找到。然后我们将原文本的这两个人物中的每个字符分别用'#'号代码,并通过'$'符号拼接在一起,形成的整合文本如下:
邵逸夫$邵仁楞$###(1907年10月4日—2014年1月7日),原名###,生于浙江省宁波市镇海镇,祖籍浙江宁波。
处理成这种格式是为了方便文本分类模型进行调用。
数据预处理的脚本为data/data_into_train_test.py,完整的Python代码如下:
# -*- coding: utf-8 -*-
import json
import pandas as pd
from pprint import pprint
df = pd.read_excel('人物关系表.xlsx')
relations = list(df['关系'].unique())
relations.remove('unknown')
relation_dict = {'unknown': 0}
relation_dict.update(dict(zip(relations, range(1, len(relations)+1))))
with open('rel_dict.json', 'w', encoding='utf-8') as h:
h.write(json.dumps(relation_dict, ensure_ascii=False, indent=2))
pprint(df['关系'].value_counts())
df['rel'] = df['关系'].apply(lambda x: relation_dict[x])
texts = []
for per1, per2, text in zip(df['人物1'].tolist(), df['人物2'].tolist(), df['文本'].tolist()):
text = '$'.join([per1, per2, text.replace(per1, len(per1)*'#').replace(per2, len(per2)*'#')])
texts.append(text)
df['text'] = texts
train_df = df.sample(frac=0.8, random_state=1024)
test_df = df.drop(train_df.index)
with open('train.txt', 'w', encoding='utf-8') as f:
for text, rel in zip(train_df['text'].tolist(), train_df['rel'].tolist()):
f.write(str(rel)+' '+text+'\n')
with open('test.txt', 'w', encoding='utf-8') as g:
for text, rel in zip(test_df['text'].tolist(), test_df['rel'].tolist()):
g.write(str(rel)+' '+text+'\n')
运行完该脚本后,会在data目录下生成train.txt, test.txt和rel_dict.json,该json文件中保存的信息如下:
{
"unknown": 0,
"夫妻": 1,
"父母": 2,
"兄弟姐妹": 3,
"上下级": 4,
"师生": 5,
"好友": 6,
"同学": 7,
"合作": 8,
"同人": 9,
"情侣": 10,
"祖孙": 11,
"同门": 12,
"亲戚": 13
}
简单来说,是给每种关系一个id,转化成类别型变量。
以train.txt为例,其前5行的内容如下:
4 方琳$李伟康$在生活中,###则把##看作小辈,常常替她解决难题。
3 佳子$久仁$12月,##和弟弟##参加了在东京举行的全国初中生演讲比赛。
2 钱慧安$钱禄新$###,生卒年不详,海上画家###之子。
0 吴继坤$邓新生$###还曾对媒体说:“我这个小小的投资商,经常得到###等领导的亲自关注和关照,我觉到受宠若惊。”
2 洪博培$乔恩·M·亨茨曼$###的父亲########是著名企业家、美国最大化学公司亨茨曼公司创始人。
10 夏乐$陈飞$两小无猜剧情简介:##和##是一对从小一起长大的青梅竹马。
在每一行中,空格之前的数字所对应的人物关系可以在rel_dict.json中找到。
模型训练
在模型训练前,为了将数据的格式更好地适应模型,需要再对trian.txt和test.txt进行处理。处理脚本为load_data.py,完整的Python代码如下:
# -*- coding: utf-8 -*-
import pandas as pd
# 读取txt文件
def read_txt_file(file_path):
with open(file_path, 'r', encoding='utf-8') as f:
content = [_.strip() for _ in f.readlines()]
labels, texts = [], []
for line in content:
parts = line.split()
label, text = parts[0], ''.join(parts[1:])
labels.append(label)
texts.append(text)
return labels, texts
# 获取训练数据和测试数据,格式为pandas的DataFrame
def get_train_test_pd():
file_path = 'data/train.txt'
labels, texts = read_txt_file(file_path)
train_df = pd.DataFrame({'label': labels, 'text': texts})
file_path = 'data/test.txt'
labels, texts = read_txt_file(file_path)
test_df = pd.DataFrame({'label': labels, 'text': texts})
return train_df, test_df
if __name__ == '__main__':
train_df, test_df = get_train_test_pd()
print(train_df.head())
print(test_df.head())
train_df['text_len'] = train_df['text'].apply(lambda x: len(x))
print(train_df.describe())
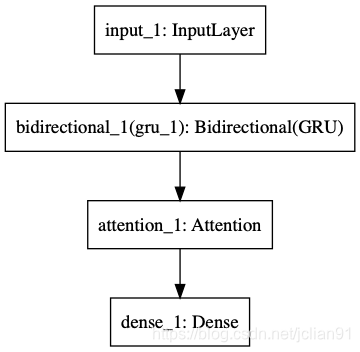
本项目所采用的模型为:BERT + 双向GRU + Attention + FC,其中BERT用来提取文本的特征,关于这一部分的介绍,已经在文章NLP(二十)利用BERT实现文本二分类中给出;Attention为注意力机制层,FC为全连接层,模型的结构图如下(利用Keras导出):
模型训练的脚本为model_train.py,完整的Python代码如下:
# -*- coding: utf-8 -*-
# 模型训练
import numpy as np
from load_data import get_train_test_pd
from keras.utils import to_categorical
from keras.models import Model
from keras.optimizers import Adam
from keras.layers import Input, Dense
from bert.extract_feature import BertVector
from att import Attention
from keras.layers import GRU, Bidirectional
# 读取文件并进行转换
train_df, test_df = get_train_test_pd()
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=80)
print('begin encoding')
f = lambda text: bert_model.encode([text])["encodes"][0]
train_df['x'] = train_df['text'].apply(f)
test_df['x'] = test_df['text'].apply(f)
print('end encoding')
# 训练集和测试集
x_train = np.array([vec for vec in train_df['x']])
x_test = np.array([vec for vec in test_df['x']])
y_train = np.array([vec for vec in train_df['label']])
y_test = np.array([vec for vec in test_df['label']])
# print('x_train: ', x_train.shape)
# 将类型y值转化为ont-hot向量
num_classes = 14
y_train = to_categorical(y_train, num_classes)
y_test = to_categorical(y_test, num_classes)
# 模型结构:BERT + 双向GRU + Attention + FC
inputs = Input(shape=(80, 768,))
gru = Bidirectional(GRU(128, dropout=0.2, return_sequences=True))(inputs)
attention = Attention(32)(gru)
output = Dense(14, activation='softmax')(attention)
model = Model(inputs, output)
# 模型可视化
# from keras.utils import plot_model
# plot_model(model, to_file='model.png')
model.compile(loss='categorical_crossentropy',
optimizer=Adam(),
metrics=['accuracy'])
# 模型训练以及评估
model.fit(x_train, y_train, batch_size=8, epochs=30)
model.save('people_relation.h5')
print(model.evaluate(x_test, y_test))
利用该模型对数据集进行训练,输出的结果如下:
begin encoding
end encoding
Epoch 1/30
1433/1433 [==============================] - 15s 10ms/step - loss: 1.5558 - acc: 0.4962
**********(中间部分省略输出)**************
Epoch 30/30
1433/1433 [==============================] - 12s 8ms/step - loss: 0.0210 - acc: 0.9951
[1.1099, 0.7709]
整个训练过程持续十来分钟,经过30个epoch的训练,最终在测试集上的loss为1.1099,acc为0.7709,在小数据量下的效果还是不错的。训练过程(加入了early stopping机制)生成的loss和acc图形如下:

模型预测
上述模型训练完后,利用保存好的模型文件,对新的数据进行预测。模型预测的脚本为model_predict.py,完整的Python代码如下:
# -*- coding: utf-8 -*-
# 模型预测
import json
import numpy as np
from bert.extract_feature import BertVector
from keras.models import load_model
from att import Attention
# 加载模型
model = load_model('people_relation.h5', custom_objects={"Attention": Attention})
# 示例语句及预处理
text = '赵金闪#罗玉兄#在这里,赵金闪和罗玉兄夫妇已经生活了大半辈子。他们夫妇都是哈密市伊州区林业和草原局的护林员,扎根东天山脚下,守护着这片绿。'
per1, per2, doc = text.split('#')
text = '$'.join([per1, per2, doc.replace(per1, len(per1)*'#').replace(per2, len(per2)*'#')])
print(text)
# 利用BERT提取句子特征
bert_model = BertVector(pooling_strategy="NONE", max_seq_len=80)
vec = bert_model.encode([text])["encodes"][0]
x_train = np.array([vec])
# 模型预测并输出预测结果
predicted = model.predict(x_train)
y = np.argmax(predicted[0])
with open('data/rel_dict.json', 'r', encoding='utf-8') as f:
rel_dict = json.load(f)
id_rel_dict = {v:k for k,v in rel_dict.items()}
print(id_rel_dict[y])
该人物关系输出的结果为夫妻。
接着,我们对更好的数据进行预测,输出的结果如下:
原文: 润生#润叶#不过,他对润生的姐姐润叶倒怀有一种亲切的感情。
预测人物关系: 兄弟姐妹
原文: 孙玉厚#兰花#脑子里把前后村庄未嫁的女子一个个想过去,最后选定了双水村孙玉厚的大女子兰花。
预测人物关系: 父母
原文: 金波#田福堂#每天来回二十里路,与他一块上学的金波和大队书记田福堂的儿子润生都有自行车,只有他是两条腿走路。
预测人物关系: unknown
原文: 润生#田福堂#每天来回二十里路,与他一块上学的金波和大队书记田福堂的儿子润生都有自行车,只有他是两条腿走路。
预测人物关系: 父母
原文: 周山#李自成#周山原是李自成亲手提拔的将领,闯王对他十分信任,叫他担任中军。
预测人物关系: 上下级
原文: 高桂英#李自成#高桂英是李自成的结发妻子,今年才三十岁。
预测人物关系: 夫妻
原文: 罗斯福#特德#果然,此后罗斯福的政治旅程与长他24岁的特德叔叔如出一辙——纽约州议员、助理海军部长、纽约州州长以至美国总统。
预测人物关系: 亲戚
原文: 詹姆斯#克利夫兰#詹姆斯担任了该公司的经理,作为一名民主党人,他曾资助过克利夫兰的再度竞选,两人私交不错。
预测人物关系: 上下级(预测出错,应该是好友关系)
原文: 高剑父#关山月#高剑父是关山月在艺术道路上非常重要的导师,同时关山月也是最能够贯彻高剑父“折中中西”理念的得意门生。
预测人物关系: 师生
原文: 唐怡莹#唐石霞#唐怡莹,姓他他拉氏,名为他他拉·怡莹,又名唐石霞,隶属于满洲镶红旗。
预测人物关系: 同人
总结
本文采用的深度学习模型是文本分类模型,结合BERT预训练模型,在小标注数据量下对人物关系抽取这个任务取得了还不错的效果。同时模型的识别准确率和使用范围还有待于提升,提升点笔者认为如下:
- 标注的数据量需要加大,现在的数据才2900条左右,如果数据量上去了,那么模型的准确率还有使用范围也会提升;
- 其他更多的模型有待于尝试;
- 在预测时,模型的预测时间较长,原因在于用BERT提取特征时耗时较长,可以考虑缩短模型预测的时间(比如使用ALBERT就能大大缩短预测时间);
- 其他问题欢迎补充。
感谢大家阅读~
本人的微信公众号: Python爬虫与算法(微信号为:easy_web_scrape),欢迎大家关注~
NLP(二十一)人物关系抽取的一次实战的更多相关文章
- 文本可视化[二]——《今生今世》人物关系可视化python实现
文本可视化[二]--<今生今世>人物关系可视化python实现 在文本可视化[一]--<今生今世>词云生成与小说分析一文中,我使用了jieba分词和wordcloud实现了,文 ...
- 一次关于关系抽取(RE)综述调研的交流心得
本文来自于一次交流的的记录,{}内的为个人体会. 基本概念 实事知识:实体-关系-实体的三元组.比如, 知识图谱:大量实时知识组织在一起,可以构建成知识图谱. 关系抽取:由于文本中蕴含大量事实知识,需 ...
- 凭借SpringBoot整合Neo4j,我理清了《雷神》中错综复杂的人物关系
原创:微信公众号 码农参上,欢迎分享,转载请保留出处. 哈喽大家好啊,我是Hydra. 虽然距离中秋放假还要熬过漫长的两天,不过也有个好消息,今天是<雷神4>上线Disney+流媒体的日子 ...
- Citrix 服务器虚拟化之二十一 桌面虚拟化之部署Provisioning Services
Citrix 服务器虚拟化之二十一 桌面虚拟化之部署Provisioning Services Provisioning Services 是Citrix 出品的一系列虚拟化产品中最核心的一个组件, ...
- 转:二十一、详细解析Java中抽象类和接口的区别
转:二十一.详细解析Java中抽象类和接口的区别 http://blog.csdn.net/liujun13579/article/details/7737670 在Java语言中, abstract ...
- WCF技术剖析之二十一:WCF基本异常处理模式[中篇]
原文:WCF技术剖析之二十一:WCF基本异常处理模式[中篇] 通过WCF基本的异常处理模式[上篇], 我们知道了:在默认的情况下,服务端在执行某个服务操作时抛出的异常(在这里指非FaultExcept ...
- Python基于共现提取《釜山行》人物关系
Python基于共现提取<釜山行>人物关系 一.课程介绍 1. 内容简介 <釜山行>是一部丧尸灾难片,其人物少.关系简单,非常适合我们学习文本处理.这个项目将介绍共现在关系中的 ...
- 中介者模式 调停者 Mediator 行为型 设计模式(二十一)
中介者模式(Mediator) 调度.调停 意图 用一个中介对象(中介者)来封装一系列的对象交互,中介者使各对象不需要显式地相互引用,从而使其耦合松散 而且可以独立地改变它们之间的交互. ...
- 二十一. Python基础(21)--Python基础(21)
二十一. Python基础(21)--Python基础(21) 1 ● 类的命名空间 #对于类的静态属性: #类.属性: 调用的就是类中的属性 #对象.属性: 先从自己的内存空间里找名 ...
随机推荐
- [白话解析] 深入浅出 极大似然估计 & 极大后验概率估计
[白话解析] 深入浅出极大似然估计 & 极大后验概率估计 0x00 摘要 本文在少用数学公式的情况下,尽量仅依靠感性直觉的思考来讲解 极大似然估计 & 极大后验概率估计,并且从名著中找 ...
- 1z0-062 题库解析6
You want execution of large database operations to suspend, and then resume, in the event of space a ...
- springboot集成restdocs输出接口文档
1.pom文件新增restdocs <dependency> <groupId>org.springframework.restdocs</groupId> ...
- 软件工程概论 网站开发要掌握的技术 &登录界面
1.网站系统开发需要掌握的技术 一.界面和用户体验(Interface and User Experience) 1.1 知道如何在基本不影响用户使用的情况下升级网站.通常来说,你必须有版本控制系统( ...
- java效率工具 Lombok
Java项目中,充斥着太多不友好的代码:POJO的getter/setter/toStringm异常处理,I/O流的关闭操作等等,这些样板代码既没有技术含量,又影响着代码的美观,Lombok应运而生. ...
- rabbitmq 实现延迟队列的两种方式
原文地址:https://blog.csdn.net/u014308482/article/details/53036770 ps: 文章里面延迟队列=延时队列 什么是延迟队列 延迟队列存储的对象肯定 ...
- 在qemu-kvm配置桥接网络
为了宿主机和虚拟机可以很好的通信,当然是选择桥接网络啦!!! 话不多说 ===========================配置桥接网络========================== 虚拟机虽 ...
- Set,Multiset,Iterator(迭代器)详解
Set,Multiset,Iterator(迭代器) Iterator:迭代器 我们可以发现所谓一些数据结构比如说数组和链表,它们都有一些相似的性质.我们看下面两个例子: 数组:定义数组\(int~a ...
- c#数字图像处理(三)灰度直方图
灰度直方图是灰度的函数,描述的是图像中具有该灰度级的像素的个数.如果用直角坐标系来表示,则它的横坐标是灰度级,纵坐标是该灰度出现的概率(像素的个数). using System; using Syst ...
- Python+Flask+MysqL的web技术建站过程
1.个人学期总结 时间过得飞快,转眼间2017年就要过去.这一年,我学习JSP和Python,哪一门都像一样新的东西,之前从来没有学习过. 这里我就用我学习过的Python和大家分享一下,我是怎么从一 ...