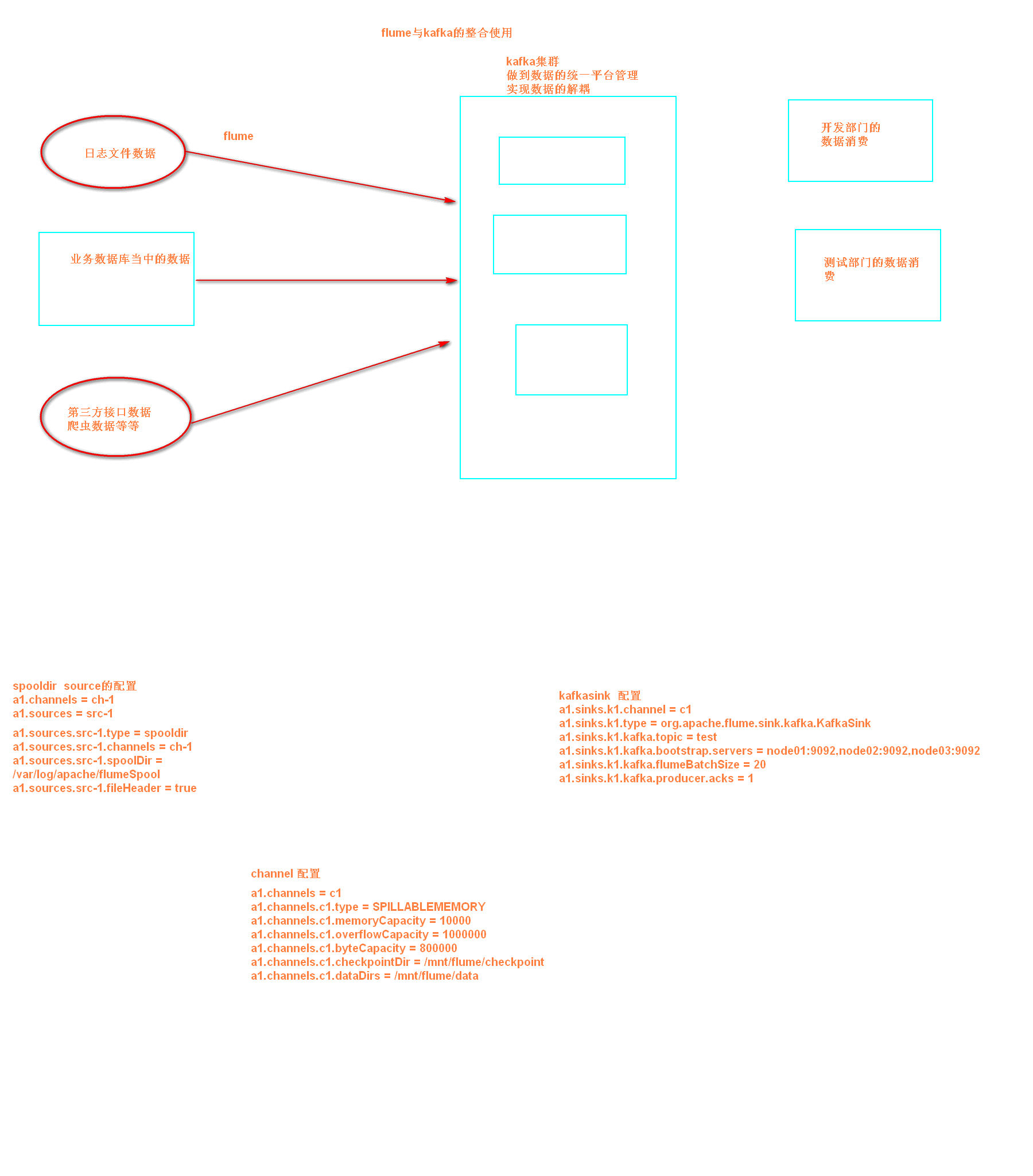
kafka和flume进行整合的日志采集的confi文件编写
配置flume.conf
为我们的source channel sink起名
a1.sources = r1
a1.channels = c1
a1.sinks = k1
指定我们的source收集到的数据发送到哪个管道
a1.sources.r1.channels = c1
指定我们的source数据收集策略
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /export/servers/flumedata
a1.sources.r1.deletePolicy = never
a1.sources.r1.fileSuffix = .COMPLETED
a1.sources.r1.ignorePattern = ^(.)*\.tmp$
a1.sources.r1.inputCharset = GBK
指定我们的channel为memory,即表示所有的数据都装进memory当中
a1.channels.c1.type = memory
指定我们的sink为kafka sink,并指定我们的sink从哪个channel当中读取数据
a1.sinks.k1.channel = c1
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = test
a1.sinks.k1.kafka.bootstrap.servers = node01:9092,node02:9092,node03:9092
a1.sinks.k1.kafka.flumeBatchSize = 20
a1.sinks.k1.kafka.producer.acks = 1
启动flume
bin/flume-ng agent --conf conf --conf-file conf/flume.conf --name a1 -Dflume.root.logger=INFO,console
kafka和flume进行整合的日志采集的confi文件编写的更多相关文章
- 基于Kafka的服务端用户行为日志采集
本文来自网易云社区 作者:李勇 背景 随着互联网的不断发展,用户所产生的行为数据被越来越多的网站重视,那么什么是用户行为呢?所谓的用户行为主要由五种元素组成:时间.地点.人物.行为.行为对应的内容.为 ...
- Filebeat7 Kafka Gunicorn Flask Web应用程序日志采集
本文的内容 如何用filebeat kafka es做一个好用,好管理的日志收集工具 放弃logstash,使用elastic pipeline gunicron日志格式与filebeat/es配置 ...
- Flume+Kafka+storm的连接整合
Flume-ng Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume的文档可以看http://flume.apache.org/FlumeUserGuide.html ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
- 【采集层】Kafka 与 Flume 如何选择--转自悟性的博文
[采集层]Kafka 与 Flume 如何选择 收藏 悟性 发表于 2年前 阅读 23167 收藏 16 点赞 4 评论 1 摘要: Kafka, Flume 采集层 主要可以使用Flume, Kaf ...
- 日志采集框架Flume以及Flume的安装部署(一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统)
Flume支持众多的source和sink类型,详细手册可参考官方文档,更多source和sink组件 http://flume.apache.org/FlumeUserGuide.html Flum ...
- 日志采集框架Flume
前言 在一个完整的大数据处理系统中,除了hdfs+mapreduce+hive组成分析系统的核心之外,还需要数据采集.结果数据导出.任务调度等不可或缺的辅助系统,而这些辅助工具在hadoop生态体系中 ...
- 日志采集框架 Flume
日志采集框架 Flume 1 概述 Flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统. Flume可以采集文件,socket数据包等各种形式源数据,又可以将采集到的数据输出到H ...
- Flume日志采集框架的使用
文章作者:foochane 原文链接:https://foochane.cn/article/2019062701.html Flume日志采集框架 安装和部署 Flume运行机制 采集静态文件到h ...
随机推荐
- Cesium指南针
cesium里面没有指南针 需要安装其他的插件: cesium-navigation-es6 npm i cesium-navigation-es6 -S 安装好之后在mainjs里引入 import ...
- leetcode-164周赛-1269-停在原地的方案数
题目描述: 自己的提交: class Solution: def numWays(self, steps: int, arrLen: int) -> int: l = min(steps,arr ...
- leetcode-163周赛-1260-二维网格迁移
题目描述: 自己的提交: class Solution: def shiftGrid(self, grid: List[List[int]], k: int) -> List[List[int] ...
- leetcood学习笔记-13
错误记录 class Solution: def romanToInt(self, s: str) -> int: d = {'I':1,'V':5,'X':10,'L':50,'C':100, ...
- Jmeter-【If控制器】-__jexl3函数&__groovy函数
一.使用场景 根据请求返回结果中某一字段的取值判断往下走的流程.例如: 二.__jexl3函数实现 格式:${__jexl3(,)} 三.__groovy函数实现 格式:${__groovy(,)}
- list 链表
#include <list> #include <iostream> using std::list; /* 双向环状链表 //每一个结点 一个数据域 一个前驱指针 一个后驱 ...
- Android 读取<meta-data>元素的数据
在AndroidManifest.xml中,<meta-data>元素可以作为子元素,被包含在<activity>.<application> .<servi ...
- Spring源码剖析3:Spring IOC容器的加载过程
本文转自五月的仓颉 https://www.cnblogs.com/xrq730 本系列文章将整理到我在GitHub上的<Java面试指南>仓库,更多精彩内容请到我的仓库里查看 https ...
- XSS漏洞的渗透利用另类玩法
XSS漏洞的渗透利用另类玩法 2017-08-08 18:20程序设计/微软/手机 作者:色豹 i春秋社区 今天就来讲一下大家都熟悉的 xss漏洞的渗透利用.相信大家对xss已经很熟悉了,但是很多安全 ...
- 1251 client does not support
1.mysql -uroot -p 123456 (用户root,密码123465) 2.use mysql: 3.ALTER USER 'root'@'localhost' IDENT ...