php 爬虫采集
概述
现在爬虫技术算是一个普遍的技术了,各个语言的爬虫百家争鸣,但是根据笔者自己的感觉还是python是主流。爬虫涉及到太多的东西,笔者并不是专业的爬虫工程师,只不过个人兴趣分享一下。由于笔者是php工作,所以就使用php来进行简单爬虫。不过我的方法应该是很通用的,我相信java,C#等肯定有类似的函数,然后做法其实都一样了。
技术准备
看懂这段代码你需要对php的正则表达式函数以及正则表达式有一定的理解。
代码 注意实际代码就这么多
<?php
//这个是你网页正则匹配出来的字符串
$str = '<div class="title">
<h3><span>[小组] </span> <a href="链接内容1" target="_blank">标签内容1</a></h3>
<div class="info">
237059 成员
</div>
</div>
<div class="title">
<h3><span>[小组] </span> <a href="链接内容2" target="_blank">标签内容2</a></h3>
<div class="info">
237059 成员
</div>
</div>';
//这个是正则的输出结果
preg_match_all('/<div class="title">[\s\S]*?<h3>[\s\S]*?<a href="(.*?)"[\s\S]*?>(.*?)<\/a>/',$str,$match);
print_r($match);//根据打印的结果很明白了吧
//这个方法就是抓取网页内容的方法了可以吧需要抓取的页面传进去,然后正则匹配内容哦
function getUrlContent($url){//通过url获取html内容
$ch = curl_init();
curl_setopt($ch,CURLOPT_URL,$url);
curl_setopt($ch,CURLOPT_USERAGENT,"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1 )");
curl_setopt($ch,CURLOPT_HEADER,1);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
$output = curl_exec($ch);
curl_close($ch);
return $output;
}
?>
到这里就可以匹配你想要的数据了,如果还是不懂,就继续往下瞅瞅
流程图
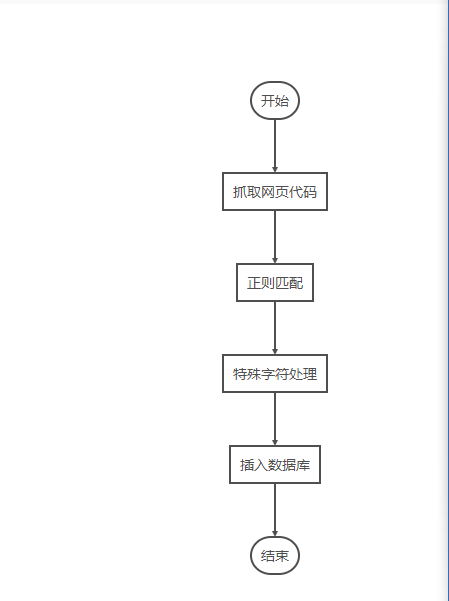
简单的爬虫,特殊字符处理就不进行了,保证插入数据库不出错就行了
思路
首先getUrlContent($url)函数,只需要穿一个url地址就行了,当然了因为各个网站都有反扒机制,不过笔者的这个函数并不是万能的,但是在豆瓣测试过,其他网站大家自行测试了。
任何网站都可以理解为一个很长的字符串,如果对html有研究无非就是:
<html>
<head>XXX</head>
<body>XXX</body>
</html>
我们需要的只是将body标签里的东西拿出来,笔者模拟了一段body里的代码
<html>
<head>XXX</head>
<body>
<div class="title">
<h3><span>[小组] </span> <a href="链接内容1" target="_blank">标签内容1</a></h3>
<div class="info">
237059 成员
</div>
</div>
<div class="title">
<h3><span>[小组] </span> <a href="链接内容2" target="_blank">标签内容2</a></h3>
<div class="info">
237059 成员
</div>
</div>
</body>
</html>
对于这段代码,可以理解为一个很长的字符串
$str = '<html>
<head>XXX</head>
<body>
<div class="title">
<h3><span>[小组] </span> <a href="链接内容1" target="_blank">标签内容1</a></h3>
<div class="info">
237059 成员
</div>
</div>
<div class="title">
<h3><span>[小组] </span> <a href="链接内容2" target="_blank">标签内容2</a></h3>
<div class="info">
237059 成员
</div>
</div>
</body>
</html>';
对这段字符串,只需要进行正则匹配拿出你想要的,假如需要a标签里的href与内容
preg_match_all('/<div class="title">[\s\S]*?<h3>[\s\S]*?<a href="(.*?)"[\s\S]*?>(.*?)<\/a>/',
$str,$match);
然后如果你不认识这段正则表达式还有preg_match_all函数,这里笔者就简单说下了,[\s\S]*?代表懒惰匹配任意字符,因为标签之间会用空格符换行符,这里又出现新问题什么叫懒惰匹配,简单来说就是匹配最少的内容。(.*?)代表非空字符,加括号的原因简单来说就是括号里的内容是你想要的,前面的[\s\S]*?匹配到的是一堆特殊符号,并没有什么作用,你不用把特殊符号记录下来,所以不加括号。
最后打印结果,也就是$match数组。
Array
(
[0] => Array
(
[0] => <div class="title">
<h3><span>[小组] </span> <a href="链接内容1" target="_blank">标签内容1</a>
[1] => <div class="title">
<h3><span>[小组] </span> <a href="链接内容2" target="_blank">标签内容2</a>
)
[1] => Array
(
[0] => 链接内容1
[1] => 链接内容2
)
[2] => Array
(
[0] => 标签内容1
[1] => 标签内容2
)
)
根据这个数组,需要什么自己遍历数组,然后拼装sql语句,插入到自己的数据库中即可。但是插入过程中可能会有一些单引号双引号捣乱,所以你用str_replace()把他们替换掉,或者加转义符号。
总结
只是针对php进行的简单爬虫,不过爬虫的思路我相信很多种语言都用得到。不过很多网站的内容是通过js返回的,或者需要登陆才能获取到数据,这些比较高级的部分,有兴趣的推荐自学python爬虫。
本文转载自https://blog.csdn.net/qq_35370923/article/details/82901220
php 爬虫采集的更多相关文章
- python爬虫采集
python爬虫采集 最近有个项目需要采集一些网站网页,以前都是用php来做,但现在十分流行用python做采集,研究了一些做一下记录. 采集数据的根本是要获取一个网页的内容,再根据内容筛选出需要的数 ...
- 利用Python网络爬虫采集天气网的实时信息—BeautifulSoup选择器
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10-20 ...
- 基于Python爬虫采集天气网实时信息
相信小伙伴们都知道今冬以来范围最广.持续时间最长.影响最重的一场低温雨雪冰冻天气过程正在进行中.预计,今天安徽.江苏.浙江.湖北.湖南等地有暴雪,局地大暴雪,新增积雪深度4-8厘米,局地可达10- ...
- 抖音爬虫教程,python爬虫采集反爬策略
一.爬虫与反爬简介 爬虫就是我们利用某种程序代替人工批量读取.获取网站上的资料信息.而反爬则是跟爬虫的对立面,是竭尽全力阻止非人为的采集网站信息,二者相生相克,水火不容,到目前为止大部分的网站都还是可 ...
- 去除爬虫采集到的\xa0、\u3000等字符
\xa0表示不间断空白符,爬虫中遇到它的概率不可谓不小,而经常和它一同出现的还有\u3000.\u2800.\t等Unicode字符串.单从对\xa0.\t.\u3000等含空白字符的处理来说,有以下 ...
- python爬虫采集网站数据
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- python爬虫-采集英语翻译
http://fanyi.baidu.com/?aldtype=85#en/zh/drughttp://fanyi.baidu.com/?aldtype=85#en/zh/cathttp://fa ...
- 编写python爬虫采集彩票网站数据,将数据写入mongodb数据库
1.准备工作: 1.1安装requests: cmd >> pip install requests 1.2 安装lxml: cmd >> pip install lxml ...
- Python爬虫——城市公交、地铁站点和线路数据采集
本篇博文为博主原创,转载请注明. 城市公交.地铁数据反映了城市的公共交通,研究该数据可以挖掘城市的交通结构.路网规划.公交选址等.但是,这类数据往往掌握在特定部门中,很难获取.互联网地图上有大量的信息 ...
随机推荐
- android系统webview使用input实现选择文件并预览
一般系统的实现方式: 代码实现 <!doctype html> <html> <head> <meta charset="utf-8"&g ...
- Python——格式输出,基本数据
一.问题点(有待解决) 1.Python中只有浮点数,20和20.0是否一样? from decimal import Decimal a = Decimal('1.3') round() 参考文章 ...
- 源码浅析:InnoDB聚集索引如何定位到数据的物理位置,并从磁盘读取
索引结构概述: MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址.这与Oracle的索引结构相似,比较好理解.那么,常用的Innodb聚集索引结构是怎样的呢? InnoDB的数据文 ...
- System.Text.Json 自定义Converter实现时间转换
Newtonsoft.Json与System.Text.Json区别 在 Newtonsoft.Json中可以使用例如 .AddJsonOptions(options => { options. ...
- 根据js轮播图原理写出合理的结构与样式、并实现js交互效果
在JS中,能用 . 的地方一般都可以用 [ ] 取代 index.html <!DOCTYPE html> <html lang="en"> <hea ...
- Openshift V3系列各组件版本
Openshift V3.* 系列各组件版本 Components 3.0 3.1 3.2 3.3 3.4 3.5 3.6 3.7 3.9 3.10 3.11 Core Components dock ...
- 通过sql的stuff 把一列几行的记录拼接在一行一个字段
---通过sql的stuff 把一列几行的记录拼接在一行一个字段 select FID,a.FCustomerID as 工地ID , 应验收节点 = (stuff((select ',' + isn ...
- P3884 [JLOI2009]二叉树问题
--------------------- 链接:Miku --------------------- 这一道题只需要在倍增lca的板子上改一改就可以了. 宽度和深度可以在倍增lca的dfs预处理的时 ...
- Mac 下如何快速重启 Dock 栏?
两种方法. 如果Dock栏出现了问题或是没有反应,请打开Launchpad并按下Command+D键. 这样就可以关闭Dock栏并重启它,效果和经常用到的killall Dock命令相同.
- IDEA创建mybatisDemo,并实现简单的CRUD
Mybatis 是支持普通SQL查询,存储过程和高级映射的优秀持久层框架.在Java或者Java Web项目中,添加Mybatis必须的核心包,就能对数据表进行增删改查操作了.下面以MySQL数据库o ...