关于宽搜BFS广度优先搜索的那点事
以前一直知道深搜是一个递归栈,广搜是队列,FIFO先进先出LILO后进后出啥的。DFS是以深度作为第一关键词,即当碰到岔道口时总是先选择其中的一条岔路前进,而不管其他岔路,直到碰到死胡同时才返回岔道口并选择其他岔路。接下来将介绍的广度优先搜索(Breadth First Search, BFS)则是以广度为第一关键词,当碰到岔道口时,总是先一次访问从该岔道口能直接到达的所有节结点,然后再按这些结点被访问的顺序去依次访问它们能直接到达的所有结点,以此类推,直到所有结点都被访问为止。这就跟平静的水面中投入一颗小石子一样,水花总是以石子落水处为中心,并以同心圆的方式向外扩散至整个水面,从这点来看BFS和DFS那种沿着一条线前进的思路是完全不同的。
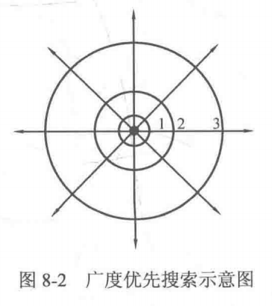
广度优先搜索BFS一般由队列实现,且总是按层次的顺序来进行遍历,其基本写法如下(可作模板用):
void BFS(int s)
{
queue<int> q;
q.push(s);
while(!q.empty())
{
取出队首元素top;
访问队首元素top;
将队首元素出队;
将top的下一层结点中未曾入队的结点全部入队,并设置为已入队;
}
}
(1)定义队列q,并将起点s入队。
(2)写一个while循环,循环条件是队列q非空。
(3)在while循环中,先取出队首元素top,然后访问它(访问可以是任何事情,例如将其输出)。访问完后将其出队。
(4)将top的下一层结点中所有未曾入队的结点入队,并标记它们的层号为now的层号+1,同时设置这些入队的结点已入过队。
(5)返回(2)继续循环。
例1:给出一个mxn的矩阵,矩阵中的元素为0或1。称位置(x,y)与其上下左右四个位置(x,y+1)、(x,y-1)、(x+1,y)、(x-1,y)是相邻的。如果矩阵中有若干个1是相邻的(不必两两相邻),那么称这些1构成了一个“块”。求给定的矩阵中“块”的个数。
【输入样例】
6 7
0 1 1 1 0 0 1
0 0 1 0 0 0 0
0 0 0 0 1 0 0
0 0 0 1 1 1 0
1 1 1 0 1 0 0
1 1 1 1 0 0 0
【输出样例】
4
【解题思路】
求解的基本思想是:枚举每一个位置的元素,如果为0,则跳过;如果为1,则使用BFS查询与该位置相邻的4个位置(前提是不出界),判段它们是否为1(如果某个相邻的位置为1,则同样去查询与该位置相邻的4个位置,直到整个“1”块访问完毕)。而为了防止走回头路,一般可以设置一个bool型数组inq来记录每个位置是否在BFS中已入过队。
对当前位置(x,y)来说,由于与其相邻的四个位置分别为(x,y+1)、(x,y-1)、(x+1,y)、(x-1,y),那么不妨设置两个增量数组,来表示四个方向。
int X[4] = {0,0,1,-1};
int Y[4] = {1,-1,0,0};
这样就可以使用for循环来枚举4个方向,以确定与当前坐标(nowX, nowY)相邻的4个位置,如下所示:
for(int i = 0;i<4;i++)
{
newX = nowX + X[i];
newY = nowY + Y[i];
}
#include <bits/stdc++.h>
#include <queue>
using namespace std;
const int maxn = ;
struct node {
int x,y; //位置(x,y)
}Node;
int n,m; //矩阵大小为n*m
int matrix[maxn][maxn]; //01矩阵
bool inq[maxn][maxn]; //记录位置(x,y)是否已入过队
int X[] = {,,,-}; //增量数组
int Y[] = {,-,,}; bool judge(int x,int y) //判段坐标(x,y)是否需要访问
{
//越界返回false
if(x>=n || x< || y>=m || y<)
return false;
//当前位置为0,或(x,y)已入过队,返回false
if(matrix[x][y] == || inq[x][y] == true) return false; //以上都不满足,说明需要访问,返回true
return true;
}
//BFS函数方位位置(x,y)所在的块,将该块中所有“1”的inq都设置为true
void bfs(int x, int y)
{
queue<node>Q; //定义队列
Node.x = x, Node.y = y; //当前结点的坐标为(x,y)
Q.push(Node); //将结点Node入队
inq[x][y] = true; //设置(x,y)已入过队
while(!Q.empty())
{
node top = Q.front(); //取出队首元素
Q.pop(); //队首元素出队
for(int i = ;i<;i++) //循环4次,得到4个相邻位置
{
int newX = top.x + X[i];
int newY = top.y + Y[i];
if(judge(newX,newY)) //如果新位置(newX,newY)需要访问
{
//设置Node的坐标为(newX,newY)
Node.x = newX, Node.y = newY;
Q.push(Node); //将结点Node加入队列
inq[newX][newY] = true; //设置位置(newX,newY)已入过队
}
}
}
} int main()
{
freopen("1.txt","r",stdin); //从文件读入
cin>>n>>m;
for(int x = ;x<n;x++)
for(int y = ;y<m;y++)
cin>>matrix[x][y]; //读入01矩阵 int ans = ; //存放块数
for(int x= ;x<n;x++) //枚举每一个位置
for(int y = ;y<m;y++)
//如果元素为1,且未入过队
if(matrix[x][y] == && inq[x][y] == false)
{
ans++; //块数加1
bfs(x,y); //访问整个块,将该块所有“1”的inq都标记为true
}
cout<<ans<<endl; return ;
}
例2
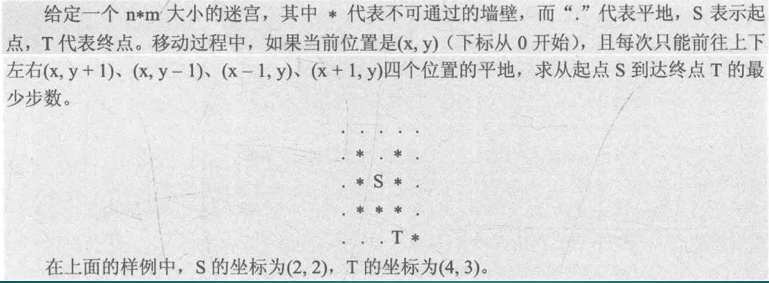
5 5
.....
.*.*.
.*S*.
.***.
...T*
2 2 4 3
#include <bits/stdc++.h>
using namespace std;
const int maxn = ;
struct node
{
int x,y; //位置(x,y)
int step;//step为从起点S到达该位置的最少步数(即层数)
}S,T,Node; //S为起点,T为终点,Node为临时结点
int n,m; //n行m列
char maze[maxn][maxn]; //迷宫信息,字符数组
bool inq[maxn][maxn] = {false}; //记录(x,y)是否已入过队
int X[] = {,,,-}; //增量数组
int Y[] = {,-,,}; //检测位置(x,y)是否有效
bool test(int x,int y)
{
if(x>=n || x < || y >= m || y < ) return false; //超过边界
if(maze[x][y] == '*') return false; //墙壁*
if(inq[x][y] == true) return false; //已入过队
return true; //有效位置
} int BFS()
{
queue<node> q; //定义队列
q.push(S); //将起点S入队
while(!q.empty())
{
node top = q.front(); //取出队首元素
q.pop(); //队首元素出队
if(top.x == T.x && top.y == T.y)
{
return top.step; //终点,直接返回最小步数
}
for(int i = ;i<;i++) //循环4次,得到4个相邻位置
{
int newX = top.x + X[i];
int newY = top.y + Y[i];
if(test(newX,newY)) //位置(newX,newY)有效
{
Node.x = newX;
Node.y = newY;
Node.step = top.step + ; //Node层数为top层数加1
q.push(Node); //将结点Node加入队列
inq[newX][newY] = true; //设置位置(newX,newY)已入过队
}
}
} return -; //无法到达终点T时返回-1
} int main()
{
freopen("2.txt","r",stdin);
cin>>n>>m;
for(int i = ;i<n;i++)
{
for(int j = ;j<m;j++)
cin>>maze[i][j];
}
cin>>S.x>>S.y>>T.x>>T.y;//起点和终点的坐标
S.step = ; //初始化的起点的层数为0,S到T的最少步数 cout<<BFS()<<endl;
return ;
}
例3


#include <bits/stdc++.h>
using namespace std;
struct node
{
int x,y,z;
}Node;
int n,m,L,T; //矩阵为n*m,共有L层,T为1的个数的下限
int pixel[][][]; //三位01矩阵
bool inq [][][] = {false};
int X[] = {,,,,,-}; //增量矩阵
int Y[] = {,,,-,,};
int Z[] = {,-,,,,};
bool judge(int x,int y,int z)
{
if(x>=n||x<||y>=m||y<||z>=L||z<)
return false;
if(pixel[x][y][z] == || inq[x][y][z] == true) return false;
return true;
}
int BFS(int x,int y,int z)
{
int tot = ; //计数当前块中1的个数
queue<node> Q; //定义队列
Node.x = x,Node.y = y,Node.z = z;
Q.push(Node); //将结点Node入队
inq[x][y][z] = true; //设置位置(x,y,z)已入过队
while(!Q.empty())
{
node top = Q.front(); //取出队首元素
Q.pop();
tot++;
for(int i = ;i<;i++)
{
int newX = top.x + X[i];
int newY = top.y + Y[i];
int newZ = top.z + Z[i];
if(judge(newX, newY,newZ))
{
Node.x = newX,Node.y=newY,Node.z = newZ;
Q.push(Node);
inq[newX][newY][newZ]= true;
}
} }
if(tot>=T) return tot;
else return ;
} int main()
{
freopen("3.txt","r",stdin);
cin>>n>>m>>L>>T;
for(int z = ;z<L;z++)
for(int x = ;x <n;x++)
for(int y = ;y<m;y++)
cin>>pixel[x][y][z]; int ans = ; //记录卒中核心区1的个数总和
for(int z =;z<L;z++)
for(int x = ;x<n;x++)
for(int y = ;y<m;y++)
if(pixel[x][y][z] == && inq[x][y][z] == false)
{
ans += BFS(x,y,z);
} printf("%d\n",ans);
return ;
}
关于宽搜BFS广度优先搜索的那点事的更多相关文章
- 算法竞赛——BFS广度优先搜索
BFS 广度优先搜索:一层一层的搜索(类似于树的层次遍历) BFS基本框架 基本步骤: 初始状态(起点)加到队列里 while(队列不为空) 队头弹出 扩展队头元素(邻接节点入队) 最后队为空,结束 ...
- BFS广度优先搜索 poj1915
Knight Moves Time Limit: 1000MS Memory Limit: 30000K Total Submissions: 25909 Accepted: 12244 Descri ...
- 0算法基础学算法 搜索篇第二讲 BFS广度优先搜索的思想
dfs前置知识: 递归链接:0基础算法基础学算法 第六弹 递归 - 球君 - 博客园 (cnblogs.com) dfs深度优先搜索:0基础学算法 搜索篇第一讲 深度优先搜索 - 球君 - 博客园 ( ...
- 图的遍历BFS广度优先搜索
图的遍历BFS广度优先搜索 1. 简介 BFS(Breadth First Search,广度优先搜索,又名宽度优先搜索),与深度优先算法在一个结点"死磕到底"的思维不同,广度优先 ...
- GraphMatrix::BFS广度优先搜索
查找某一结点的邻居: virtual int firstNbr(int i) { return nextNbr(i, n); } //首个邻接顶点 virtual int nextNbr(int i, ...
- 啊哈算法之宽搜BFS解救小哈
简述 本算法摘选自啊哈磊所著的<啊哈!算法>第四章第三节的题目——BFS算法再次解救小哈.文中代码使用C语言编写,博主通过阅读和理解,重新由Java代码实现了一遍,以此来理解BFS算法.关 ...
- 步步为营(十六)搜索(二)BFS 广度优先搜索
上一篇讲了DFS,那么与之相应的就是BFS.也就是 宽度优先遍历,又称广度优先搜索算法. 首先,让我们回顾一下什么是"深度": 更学术点的说法,能够看做"单位距离下,离起 ...
- [MIT6.006] 13. Breadth-First Search (BFS) 广度优先搜索
一.图 在正式进入广度优先搜索的学习前,先了解下图: 图分为有向图和无向图,由点vertices和边edges构成.图有很多应用,例如:网页爬取,社交网络,网络传播,垃圾回收,模型检查,数学推断检查和 ...
- DFS(深度优先搜索)和BFS(广度优先搜索)
深度优先搜索算法(Depth-First-Search) 深度优先搜索算法(Depth-First-Search),是搜索算法的一种. 它沿着树的深度遍历树的节点,尽可能深的搜索树的分支. 当节点v的 ...
随机推荐
- jQuery的12种选择器
jQuery的12种选择器 1.#id : 根据给定的ID匹配一个元素 显示(用加粗的代替颜色): 这是第一个p标签 2.* : 匹配所有元素,多用于结合上下文来搜索 显示 : 这是p标签 这是di ...
- (转)漫游Kafka入门篇之简单介绍
转自:http://blog.csdn.net/honglei915/article/details/37564521 原文地址:http://blog.csdn.net/honglei915/art ...
- open函数 文件设置缓冲
# 注释 将文件写入硬件设备时,使用系统调用,这类I/O操作一般时间很长 # 为了减少I/O次数操作,文件通常使用缓冲区(有足够的数据才进行系统调用) # 文件缓冲行为分为: # 全缓冲: open函 ...
- Hydra暴力破解工具
hydra [[[-l LOGIN|-L FILE] [-p PASS|-P FILE]] | [-C FILE]] [-e nsr] [-o FILE] [-t TASKS] [-M FILE [- ...
- Codeforces Round #610 (Div. 2) A-E简要题解
contest链接: https://codeforces.com/contest/1282 A. Temporarily unavailable 题意: 给一个区间L,R通有网络,有个点x,在x+r ...
- vue.js + element中el-select实现拼音匹配,分词、缩写、多音字匹配能力
1.既然要用到拼音搜索,我们就需要一个拼音库,在这里我推荐一个第三方包:https://github.com/xmflswood/pinyin-match,在这里首先对这个包的开发者表示万分的感谢. ...
- No Delegate set : lost message:libpng error: Not a PNG file
当出现这个问题时,是因为本来是jpg或其他格式的图片存成了png导致的.或者有的图片本来就是jpg的,Android Studio一编译,发现不是png才造成了这个问题.解决这个问题可以在Androi ...
- 基于pyqt5的图片素材批量处理工具
功能 分辨率的批量转换,文件夹递归查找 像素偏移量批量调整,文件夹单层查找 画布的大小的批量进行调整,不进行缩放,文件夹单层查找 界面 通过PyUIC生成的代码 # -*- coding: utf-8 ...
- L2-3 名人堂与代金券
题解 这题的话,每一个人都要占一个排名,即使排名并列了. 对于最后一个排名来说,即使人数超过了指定的k,也要加入. 代码 #include <bits/stdc++.h> using na ...
- js中float失精
https://juejin.im/post/5aa1395c6fb9a028df223516 把小数转为整数,然后计算 https://www.html.cn/archives/7340