Hadoop集群分布式安装
一 整体介绍
1.1 硬件环境
本文使用三台服务器搭建hadoop集群,使用Centos7.5系统,服务器均有独立ip
1.2 部署的软件
部署服务:namenode(HA),resourcemanager(HA),zookeeper,hbase(HA),spark,kafka,geomesa
版本:hadoop-2.7.4,zookeeper-3.4.14,hbase-1.3.6,kafka_2.11-1.0.1,scala-2.11.8,geomesa-hbase_2.11-2.1.3,spark-2.4.4-bin-hadoop2.7,jdk-8u221-linux-x64
使用root用户安装
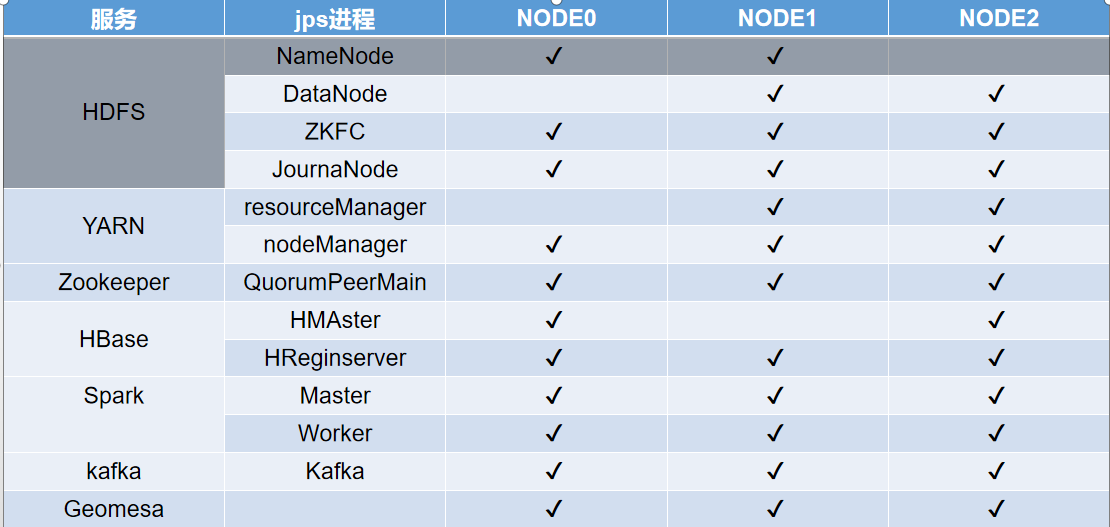
图1 集群部署情况
二 安装过程
2.1 安装前准备:配置ip,hostname,ntp,ssh免密登录,关闭防火墙和SELINUX,安装jdk
2.1.1 配置ip
修改配置文件,目录:/etc/sysconfig/network-scripts/ifcfg_xxx(网卡名)
参数 作用详解
DEVICE=“eth1” 网卡名称
NM_CONTROLLED=“yes” network mamager的参数 ,是否可以由NNetwork Manager托管
HWADDR= MAC地址
TYPE=Ethernet 类型
PREFIX=24 子网掩码24位
DEFROUTE=yes 就是default route,是否把这个eth设置为默认路由
ONBOOT=yes 设置为yes,开机自动启用网络连接
IPADDR=0.0.0.0 IP地址
BOOTPROTO=none 设置为none禁止DHCP,设置为static启用静态IP地址,设置为dhcp开启DHCP服务
NETMASK=255.255.255.0 子网掩码
DNS1=8.8.8.8 第一个dns服务器
BROADCAST 广播
UUID= 唯一标识
TYPE=Ethernet 网络类型为:Ethernet
GATEWAY= 设置网关
DNS2=8.8.8.8 第二个dns服务器
IPV6INIT=no 禁止IPV6
USERCTL=no 是否允许非root用户控制该设备,设置为no,只能用root用户更改
NAME=“System eth1” 这个就是个网络连接的名字
MASTER=bond1 指定主的名称
SLAVE 指定了该接口是一个接合界面的组件。
NETWORK 网络地址
ARPCHECK=yes 检测
PEERDNS 是否允许DHCP获得的DNS覆盖本地的DNS
PEERROUTES 是否从DHCP服务器获取用于定义接口的默认网关的信息的路由表条目
IPV6INIT 是否启用IPv6的接口。
IPV4_FAILURE_FATAL=yes 如果ipv4配置失败禁用设备
IPV6_FAILURE_FATAL=yes 如果ipv6配置失败禁用设备
修改完文件,重启网络服务:systemctl start network
2.1.2 修改服务器hostname(Centos7)
查看:hostname
临时修改:hostname newname
永久修改:hostnamectl set-hostname xxxh;或者修改/etc/hostname和/etc/hosts //三台服务器分别为node0,node1,node2
然后重启:reboot
2.1.3 安装ntp(时间同步)
安装:
三个节点安装ntp:
安装ntp:yum install ntp
启动服务:systemctl start ntpd.service
设置开机自启动:systemctl enable ntpd.service
配置:
一个节点设置为server,配置:vim /etc/ntp.conf
restrict 192.168.1.0 mask 255.255.255.0 #添加此行
另外两个设置client,配置:vim /etc/ntp.conf
server 192.168.1.190 #添加此行(server的ip)
# server 0.centos.pool.ntp.org iburst #以下四行注释掉
# server 1.centos.pool.ntp.org iburst
# server 2.centos.pool.ntp.org iburst
# server 3.centos.pool.ntp.org iburst
三台重启ntp.Server:systemctl restart ntpd
查看结果:ntpq -p(使用服务器状态)/ntpstat(是否同步)(server需要几秒生效,client需要十几分钟)
2.1.4 ssh安装和免密登录
安装
下载:yum -y install rmp;
yum -y install openssh;
启动:/etc/init.d/sshd start
修改配置文件: vim /etc/ssh/sshd_config 进入文件修改
Port 22 开启端口
78行 PasswordAuthentication no|yes 开启或关闭ssh的默认认证方式
48行 PermitRootLogin no|yes 开启或关闭root用户的登陆
重启:systemctl start sshd
查看服务:ps -e|grep sshd
配置免密登录(相互保存对方的公钥)
三台都配置节点名称:vim /etc/hosts添加
192.168.0.128 master
192.168.0.129 slave1
192.168.0.130 slave2
生成公私钥:cd ~; ssh-keygen -t rsa(一路回车)
生成authorized_keys文件:将client~/.ssh目录中的 id_rsa.pub 这个文件拷贝到server 的~/.ssh目录中authorized_keys(自己创建)
scp ~/.ssh/id_rsa.pub 192.168.0.101:~/.ssh/
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
将authorized_keys文件复制到其他节点~/.ssh,实现所有节点互联
# 另外要注意请务必要将服务器上 ~/.ssh权限设置为700
~/.ssh/authorized_keys的权限设置为600
chmod 700 ~/.ssh/
chmod 600 ~/.ssh/authorized_keys
2.1.5 关闭防火墙和SELINUX
关闭防火墙
查看:firewall-cmd --state
关闭:systemctl stop firewalld.service
禁止开机自启:systemctl disable firewalld.service
关闭SELINUX(SELinux 主要作用就是最大限度地减小系统中服务进程可访问的资源)
# vim /etc/selinux/config
-- 注释掉 #SELINUX=enforcing #SELINUXTYPE=targeted
-- 添加 SELINUX=disabled
2.1.6 安装jdk
查看是否已安装jdk:rpm -qa | grep java
删除所有显示的Java包:rpm -e –nodeps +包名 或者yum -y remove +包名
解压jdk包到安装目录:tar -xvf jdk-8u144-linux-x64.tar.gz -C /opt/java
改名:mv jdk1.8.0_144 jdk1.8
配置环境变量:vim /etc/profile
添加内容:export JAVA_HOME=/opt/java/jdk1.8
export JRE_HOME=/opt/java/jdk1.8/jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
export PATH=.:${JAVA_HOME}/bin:$PATH
环境变量生效:source /etc/profile
检查安装结果:java -version
2.2 安装zookeeper
1. 解压
tar -zxvf zookeeper-3.4.10.tar.gz -C /tools/zookeeper-3.4.10
mkdir /tools/zookeeper-3.4.10/data
2. 配置文件
-- 复制配置文件模板
Cp /usr/zookeeper-3.4.10/conf/zoo-sample.cfg /usr/zookeeper-3.4.10/conf/zoo.cfg
-- 修改配置文件 # vim /usr/zookeeper-3.4.10/conf/zoo.cfg
-- 添加如下内容
dataLogDir=/var/hadoop/zookeeper
dataDir=/usr/zookeeper-3.4.10/data --提前创建data目录
server.1=node0:2888:3888
server.2=node1:2888:3888
server.3=node2:2888:3888
3. 复制到node1,node2
# scp -r /usr/zookeeper-3.4.10 node1:/usr
# scp -r /usr/zookeeper-3.4.10 node2:/usr
4. 创建myid文件(三台 分别echo1,2,3 myid中的编号和zoo.cfg文件中的server.n一致)
# touch /usr/zookeeper-3.4.10/data/myid
# echo 1 > /usr/zookeeper-3.4.10/data/myid
5. 配置环境变量
export ZOOKEEPER_HOME=/tools/zookeeper-3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
6. 格式化(namenode节点):hdfs zkfc -formatZK
7. 启动(三台)
/tools/zookeeper-3.4.14/bin/zkServer.sh start
查看zkServer.sh status/jps
结果一台leader两台follow即启动成功
2.3 安装hadoop(namenode和resourcemanager HA安装)
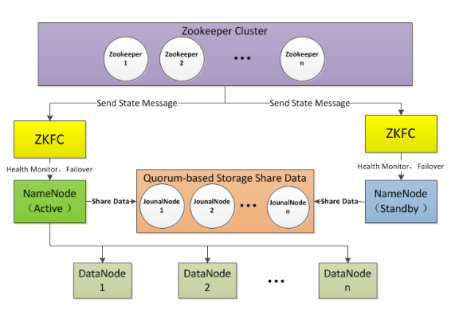
图2 namenode HA 原理
1.解压安装 tar -zxvf hadoop-2.7.4.tar.gz -C /tools/
2.修改配置文件:Core-site.xml,yarn-site.xml,Hdfs-site.xml,slaves
Core-site.xml
<property>
<name>fs.default.name</name>
<value>hdfs://ns</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--指定zookeeper地址-->
<property>
<name>ha.zookeeper.quorum</name>
<value>node0:2181,node1:2181,node2:2181</value>
</property>
Hdfs-site.xml(HA)
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<!--指定hdfs的nameservice为ns,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>ns</value>
</property>
<!-- ns下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.ns</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn1</name>
<value>node0:9000</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn1</name>
<value>node0:50070</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.ns.nn2</name>
<value>node1:9000</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.ns.nn2</name>
<value>node1:50070</value>
</property>
<!-- 指定NameNode的元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node0:8485;node1:8485;node2:8485/ns</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/data/hadoop/journaldata</value>
</property>
<!-- 开启NameNode故障时自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.ns</name> <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,如果ssh是默认22端口,value直接写sshfence即可 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
<property>
<name>ha.failover-controller.cli-check.rpc-timeout.ms</name>
<value>60000</value>
</property>
<!-- 配置namenode和datanode的工作目录-数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node0:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
yarn-site.xml(resourcemanager HA)
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node0</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node1</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node0:2181,node1:2181,node2:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>86400</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 制定resourcemanager的状态信息存储在zookeeper集群上 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.mapred.ShuffleHandler</value>
</property>
<!--每个节点可用内存,单位MB-->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<!--每个节点可用cpu-->
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>noed0:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node1:8088</value>
</property>
修改slaves:添加DataNode节点
Node0
Node1
Node2
3. 安装目录复制到node1和node2
# scp -r /usr/hadoop-2.7.3 slave1:/usr
# scp -r /usr/hadoop-2.7.3 slave2:/usr
4. 配置环境变量
# vim /etc/profile --
添加如下内容#hadoop
export HADOOP_HOME=/tools/hadoop-2.7.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HADOOP_LOG_DIR=/var/hadoop/hadoop/logs
export YARN_LOG_DIR=$HADOOP_LOG_DIR
-- 保存后执行 # source /etc/profile
5. 格式化 namenode
格式化步骤:(只要格式化一台,另一台同步,两台都格式化)
1)、格式化第一台:
$ bin/hdfs namenode -format
2)、启动刚格式化好的namenode:
$ sbin/hadoop-deamon.sh start namenode
3)、在第二台机器上同步namenode的数据:
$ bin/hdfs namenode -bootstrapStandby
4)、启动第二台的namenode:
$ sbin/hadoop-deamon.sh start namenode
6. 启动/关闭hadoop(node0)
sbin/start-all.sh
关闭 sbin/stop-all.sh
2.3 安装Hbase(HA)
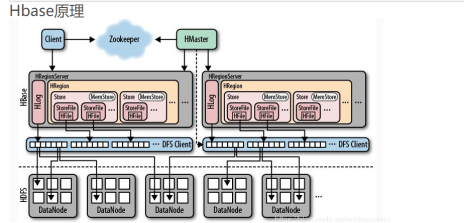
图3 hbase原理
1、解压缩hbase安装包
# tar -zxvf hbase-1.2.5-bin.star.gz -C /usr# mkdir /usr/hbase-1.2.5-bin/logs
2、修改Hbase启动时要使用的环境变量(hbase-env.sh)
-- 打开环境变量配置文件# vim /usr/hbase-1.2.5/conf/hbase-env.sh
-- 添加如下内容
设置java安装路径export JAVA_HOME=/usr/java/jdk1.8.0_131
设置hbase的日志地址export HBASE_LOG_DIR=${HBASE_HOME}/logs
设置是否使用hbase管理zookeeper(因使用zookeeper管理的方式,故此参数设置为false)export HBASE_MANAGES_ZK=false
设置hbase的pid文件存放路径export HBASE_PID_DIR=/var/hadoop/pids
3、添加所有的region服务器到regionservers文件中
# vim /usr/hbase-1.2.5/conf/regionserver
-- 删除localhost,新增如下内容
node0
node1
node2
注:hbase在启动或关闭时会依次迭代访问每一行来启动或关闭所有的region服务器进程
4、修改Hbase集群的基本配置信息(hbase-site.xml),该配置将会覆盖Hbase的默认配置
-- 打开配置文件
# vim /usr/hbase-1.2.5/conf/hbase-site.xml
-- 在configuration节点下添加如下内容
<!--和core.site.xml的fs.default.name一致-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node0,node1,node2</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/tools/zookeeper-3.4.14/data</value>
</property>
<!--主节点-->
<property>
<name>hbase.master</name>
<value>node0:60000</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
将hadoop配置文件core.site.xml和hdfs.site.xml复制到conf下
创建文件backup-masters,添加副节点的hostname
5、复制hbase到slave中
# scp -r /usr/hbase-1.2.5 slave1:/usr
# scp -r /usr/hbase-1.2.5 slave2:/usr
6、启动hbase(在两个节点启动master,配置文件中指定active节点)
在master节点启动master:hbase-daemon.sh start master
在regionserver节点启动regionserver:hbase-daemon.sh start regionserver
2.4 安装Scala(spark和kafka依赖)
下载地址:Scala地址:https://www.scala-lang.org/download/
安装配置
解压scala安装包
tar -xvf scala-2.12.6\ .tgz -C /usr/local/
修改配置文件:
vi /etc/profile
#scala
export SCALA_HOME=/usr/local/scala-2.12.6
export PATH=$PATH:$SCALA_HOME/bin
Source /etc/profile
2.4 安装Spark(HA)
Spark下载地址:http://spark.apache.org/downloads.html
解压安装
tar -xvf /opt/spark/spark-2.3.1-bin-hadoop2.7.tgz -C /usr/local
配置
添加环境变量
#spark
export SPARK_HOME=/opt/spark/spark-2.3.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
export SPARK_EXAMPLES_JAR=$SPARK_HOME/examples/jars/spark-examples_3.11-2.3.1.jar
修改spark-env.sh
cp spark-env.sh.template spark-env.sh
添加:export JAVA_HOME=/tools/java/jdk1.8
#export SCALA_HOME=/tools/scala-2.12.8
export HADOOP_HOME=/tools/hadoop-2.7.4
export HADOOP_CONF_DIR=/tools/hadoop-2.7.4/etc/hadoop
export SPARK_WORKER_MEMORY=500m
export SPARK_WORKER_CORES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node0:2181,node1:2181,node2:2181 -Dspark.deploy.zookeeper.dir=/spark"
将安装目录复制到其他节点
启动
启动worker:sbin/start-all.sh
启动master:哪台用start-master.sh启动即为master
在高可用模式下启动spark集群,现需要在任意一台节点上启动start-all,然后在另外一台节点上单独启动 master。命令:start-master.sh
2.5 安装Kafka
1. 依赖Scala,下载解压
2. 在kafka路径下创建其日志文件夹
mkdir logs
3. 进入config目录,进入server.properties文件修改配置信息
broker.id=0
delete.topic.enable=true
log.dirs=/root/hd/kafka/logs
zokeeper.connect=hd1-1:2181,hd1-2:2181,hd1-3:2181
保存并退出;
4. 将修改好的kafka文件夹发送到其他集群机器,并修改server.properties中的broker.id为1,2,3...
scp -r /root/hd/kafka hd09-01:/root/hd/
5. 启动zookeeper集群,再启动kafka集群
窗口启动:bin/kafka-server-start.sh config/server/properties
后台运行:nohup bin/kafka-server-start.sh config/server.properties & >nohup.out
jps查看有Kafka进程即启动成功
常用操作:
创建topic:./kafka-topics.sh --create --zookeeper node0:2181,node1:2181,node2:2181 -topic topicname -replication-factor 1 -partitions 6
查看topic:bin/kafka-topics.sh -zookeeper server221:2181 --list
启动生产者:./bin/kafka-console-producer.sh --broker-list localhost:9092 --topic taxi
启动消费者:./bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic taxi--from-beginning
2.6 安装Geomesa
1. 官网下载所需版本的geomesa,官网:https://www.geomesa.org/documentation/user/hbase/install.html
本文使用geomesa-hbase,下载后解压缩
2. 配置环境变量
export HADOOP_HOME=/path/to/hadoopexport
HBASE_HOME=/path/to/hbaseexport
GEOMESA_HBASE_HOME=/opt/geomesaexport
PATH="${PATH}:${GEOMESA_HOME}/bin"
GeoMesa 推荐在geomesa-hbase_2.11-$VERSION/conf/geomesa-env.sh文件中设置以上环境变量,也可以在.bashrc或/etc/profile中设置。
3. 手动安装插件
bin/install-jai.sh
bin/install-jline.sh
4. 复制jar包
GeoMesa for HBase需要使用本地过滤器来加速查询,因此需要将GeoMesa的runtime JAR包,复制到HBase的安装目录的lib文件夹中
hadoop fs -put ${GEOMESA_HBASE_HOME}/dist/hbase/geomesa-hbase-distributed-runtime-$VERSION.jar ${hbase.dynamic.jars.dir}/
5. 注册协处理器(Coprocessors)
注册的过程其实就是使HBase在运行时能够访问到geomesa-hbase-distributed-runtime的jar包。官网给出了几种方法实现这一目标,最方便的是在HBase的配置文件hbase-site.xml添加如下内容:
<property>
<name>hbase.coprocessor.user.region.classes</name>
<value>org.locationtech.geomesa.hbase.coprocessor.GeoMesaCoprocessor</value>
</property>
6. 设置命令行工具
在完成以上设置后,GeoMesa的主要部分就安装完成了。可以使用 bin/geomesa-hbase 命令调用GeoMesa的命令行工具,执行一系列的功能。
这里要额外设置的是使用如下命令,将HBase配置文件hbase-site.xml打包进geomesa-hbase-datastore_2.11-$VERSION.jar中:
zip -r lib/geomesa-hbase-datastore_2.11-$VERSION.jar hbase-site.xml
三 集群启动/停止方式
三种启动方式介绍
方式一:逐一启动(实际生产环境中的启动方式)
hadoop-daemon.sh start|stop namenode|datanode| journalnode|zkfc(DFSZKFailoverController)(依次顺序)
yarn-daemon.sh start |stop resourcemanager|nodemanager
方式二:分开启动
start-dfs.sh
start-yarn.sh
方式三:一起启动
start-all.sh
start-all.sh脚本:
说明:start-all.sh实际上是调用sbin/start-dfs.sh脚本和sbin/start-yarn.sh脚本
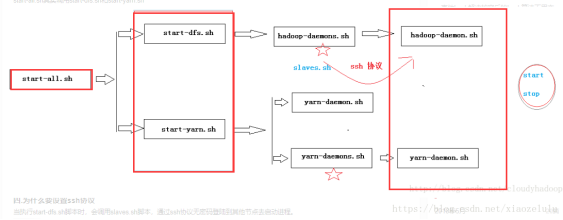
图4 集群启动调用过程

图5 单独启动、停止命令
四 安装过程遇到的问题
1. 配置好ssh免密登录还无法登录
答:known_host文件中保存了未修改前的其他节点公钥,手动删除known_hosts中内容
2. 配置好JAVA_HOME,启动hadoop报Error: JAVA_HOME is not set and could not be found.
答:修改/etc/hadoop/hadoop-env.sh和hadoop-env.sh中设JAVA_HOME。
应当使用绝对路径。
export JAVA_HOME=$JAVA_HOME //错误,不能这么改
export JAVA_HOME=/usr/java/jdk1.6.0_45 //正确,应该这么改
3. hadoop启动后无法用浏览器打开yarn管理8088

答:8088端口挂载到127.0.0.1下,
外网无法访问,修改yarn-site.xml文件
添加 <property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node0</value>
</property>
4. zookeeper启动查看状态报Error contacting service. It is probably not running.
答:查看输出日志:/bin/zookeeper.out
解决:将zoo.cfg自己节点名称改为0.0.0.0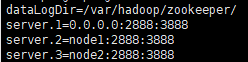
5. recourcemanager未启动成功

答:配置文件写错了(出问题先看配置文件)

6. Secondarynamenode未启动成功

答:配置了HA之后,secondaryname是不启动的,如果用hadoop-daemon强行启动,报错, Cannot use SecondaryNameNode in an HA cluster. The Standby Namenode will perform checkpointing.
standby的namenode一直在执行secondarynamenode的作用,不需要再启动secondarynamenode。
7. standby namenode无法启动

答:datanode cluesterID只有首次才会生成,namenode clusterID每格式化一次就会生成一次,所以会造成namenode clusterID与datanode clusterID不匹配
解决方法:1手动修改/data/hadoop/dfs/name/cuurent/VAERSION同步主节点的clusterID
2.删除掉dfs所有数据重新格式化namenode,格式化步骤如下。
Namenode格式化前先启动journalnode 命令:hadoop-daemon.sh start journalnode
格式化步骤:(只要格式化一台,另一台同步,两台都格式化)
1)、格式化第一台:
$ bin/hdfs namenode -format
2)、启动刚格式化好的namenode:
$ sbin/hadoop-deamon.sh start namenode
3)、在第二台机器上同步namenode的数据:
$ bin/hdfs namenode -bootstrapStandby
4)、启动第二台的namenode:
$ sbin/hadoop-deamon.sh start namenode
8.
·答:集群未启动,端口号连接失败
9.启动HBase失败

答:ntp有问题
10. 启动kafka报错:

答:清空kafka日志
11. 无法停止服务
答:没有配置pid文件,默认在/tmp会被清除
配置方法:
1 在集群各个节点的/var目录下面创建一个文件夹: sudo mkdir -p /var/hadoop/pids,记得更改这个文件夹的权限,chown -R hadoop:hadoop /var/hadoop,将这个目录及子目录的拥有者改为你的当前用户,我这是hadoop,不然执行start-all.sh的时候当前用户会没有权限创建pid文件
2 修改hadoop-env.sh 增加:export HADOOP_PID_DIR=/var/hadoop/pids
3 修改yarn-env.sh 增加:export YARN_PID_DIR=/var/hadoop/pids
4 修改hbase-env.sh ,增加:export HBASE_PID_DIR=/var/hadoop/pids
Hadoop集群分布式安装的更多相关文章
- 沉淀,再出发——在Hadoop集群之上安装hbase
在Hadoop集群之上安装hbase 一.安装准备 首先我们确保在ubuntu16.04上安装了以下的产品,java1.8及其以上,ssh,hadoop集群,其次,我们需要从hbase的官网上下载并安 ...
- Apache Hadoop集群离线安装部署(三)——Hbase安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(三)(图文详解---尽情点击!!!) 一.JDK的安装 安装位置都在同一位置(/usr/tools/jdk1.8.0_73) jdk的安装在克隆三台机器的时候可以提前安装 ...
- Hadoop集群搭建安装过程(二)(图文详解---尽情点击!!!)
Hadoop集群搭建安装过程(二)(配置SSH免密登录)(图文详解---尽情点击!!!) 一.配置ssh无密码访问 ®生成公钥密钥对 1.在每个节点上分别执行: ssh-keygen -t rsa(一 ...
- Ganglia监控Hadoop集群的安装部署[转]
Ganglia监控Hadoop集群的安装部署 一. 安装环境 Ubuntu server 12.04 安装gmetad的机器:192.168.52.105 安装gmond的机 器:192.168.52 ...
- Apache Hadoop集群离线安装部署(二)——Spark-2.1.0 on Yarn安装
Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS.YARN.MR)安装:http://www.cnblogs.com/pojishou/p/6366542.html Apac ...
- Apache Hadoop集群离线安装部署(一)——Hadoop(HDFS、YARN、MR)安装
虽然我已经装了个Cloudera的CDH集群(教程详见:http://www.cnblogs.com/pojishou/p/6267616.html),但实在太吃内存了,而且给定的组件版本是不可选的, ...
- 大数据: 完全分布式Hadoop集群-HBase安装
HBase 是一个开源的非关系(NoSQL)的可伸缩性分布式数据库.它是面向列的,并适合于存储超大型松散数据.HBase适合于实时,随机对Big数据进行读写操作的业务环境. 本文基 ...
- Hadoop集群环境安装
转载请标明出处: http://blog.csdn.net/zwto1/article/details/45647643: 本文出自:[zhang_way的博客专栏] 工具: 虚拟机virtual ...
随机推荐
- vue事件获取事件对象,vue获取事件源,vue event.currentTarget
js的事件,如点击事件,可以直接用this获取事件对象,而jQuery可以使用$(this)来获取事件对象.vue必须借助事件的 event 对象 的 currentTarget 才能获取事件对象 v ...
- jQuery 链
通过 jQuery,可以把动作/方法链接在一起. Chaining 允许我们在一条语句中运行多个 jQuery 方法(在相同的元素上). jQuery 方法链接 直到现在,我们都是一次写一条 jQue ...
- 实时计算轻松上手,阿里云DataWorks Stream Studio正式发布
Stream Studio是DataWorks旗下重磅推出的全新子产品.已于2019年4月18日正式对外开放使用.Stream Studi是一站式流计算开发平台,基于阿里巴巴实时计算引擎Flink构建 ...
- [Offer收割]编程练习赛108 - 树上的最短边 树链剖分
直接点权下放到边权,每次查询从dfs序的st[u]+1,ed[v]之间查询, #include<iostream> #include<stdio.h> #include< ...
- python基础之包的导入
包的导入 python是一门灵活性的语言 ,也可以说python是一门胶水语言,顾名思义,就是可一导入各类的包, python的包可是说是所有语言中最多的.当然导入包大部分是为了更方便,更简便,效率更 ...
- Oracle/PLSQL存储过程详解
原文链接:https://blog.csdn.net/zezezuiaiya/article/details/79557621 Oracle/PLSQL存储过程详解 2018-03-14 17:31: ...
- sql语句列名为变量(Spring Boot+mybitis实验环境)
之前用的#{参数},在列名.表明部分一直不能成为变量.折腾了很久,结果仅仅是改为${变量}就可以了.
- JavaScript 字符串转为数字
js中字符串转为数字主要4种,分别为转换函数,强制转换,js变量弱类型转换,正则表达式. 1.转换函数 JS中提供了两个转换函数parseInt()和parseFloat(),parseInt()将值 ...
- React与Vue的相同与不同点
我们知道JavaScript是世界上最流行的语言之一,React和Vue是JS最流行的两个框架.所以要想前端的开发那么必须掌握好这两个框架. 那么这两个框架有什么不同呢? React 和 Vue 相同 ...
- Python--day71--Cookie和Session
一.Cookie Cookie图示: 二.Session 引用:http://www.cnblogs.com/liwenzhou/p/8343243.html cookie Cookie的由来 大家都 ...