sklearn提供的自带数据集
sklearn 的数据集有好多个种
- 自带的小数据集(packaged dataset):sklearn.datasets.load_<name>
- 可在线下载的数据集(Downloaded Dataset):sklearn.datasets.fetch_<name>
- 计算机生成的数据集(Generated Dataset):sklearn.datasets.make_<name>
- svmlight/libsvm格式的数据集:sklearn.datasets.load_svmlight_file(...)
- 从买了data.org在线下载获取的数据集:sklearn.datasets.fetch_mldata(...)
①自带的数据集
其中的自带的小的数据集为:sklearn.datasets.load_<name>

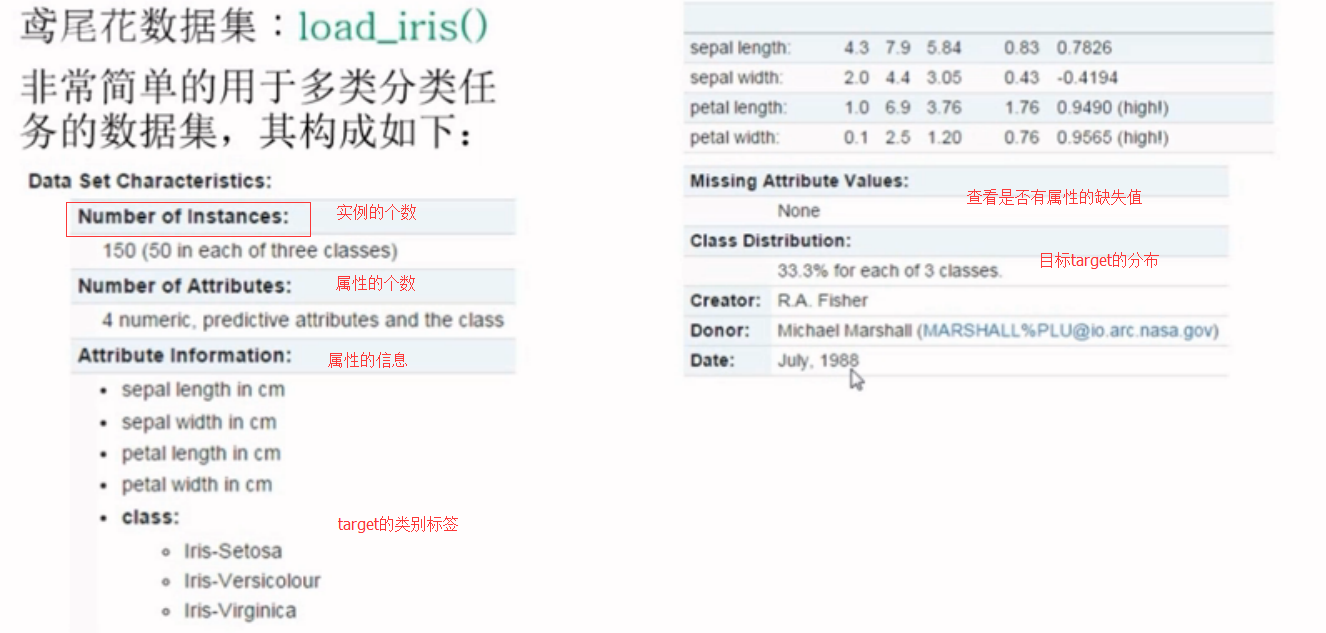
这些数据集都可以在官网上查到,以鸢尾花为例,可以在官网上找到demo,http://scikit-learn.org/stable/auto_examples/datasets/plot_iris_dataset.html

from sklearn.datasets import load_iris
#加载数据集
iris=load_iris()
iris.keys() #dict_keys(['target', 'DESCR', 'data', 'target_names', 'feature_names'])
#数据的条数和维数
n_samples,n_features=iris.data.shape
print("Number of sample:",n_samples) #Number of sample: 150
print("Number of feature",n_features) #Number of feature 4
#第一个样例
print(iris.data[0]) #[ 5.1 3.5 1.4 0.2]
print(iris.data.shape) #(150, 4)
print(iris.target.shape) #(150,)
print(iris.target)
"""
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
"""
import numpy as np
print(iris.target_names) #['setosa' 'versicolor' 'virginica']
np.bincount(iris.target) #[50 50 50] import matplotlib.pyplot as plt
#以第3个索引为划分依据,x_index的值可以为0,1,2,3
x_index=3
color=['blue','red','green']
for label,color in zip(range(len(iris.target_names)),color):
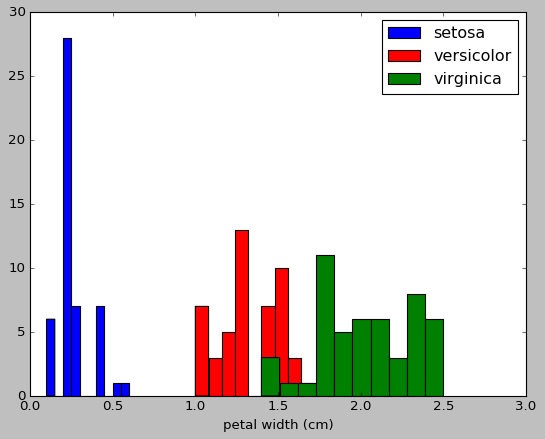
plt.hist(iris.data[iris.target==label,x_index],label=iris.target_names[label],color=color) plt.xlabel(iris.feature_names[x_index])
plt.legend(loc="Upper right")
plt.show()
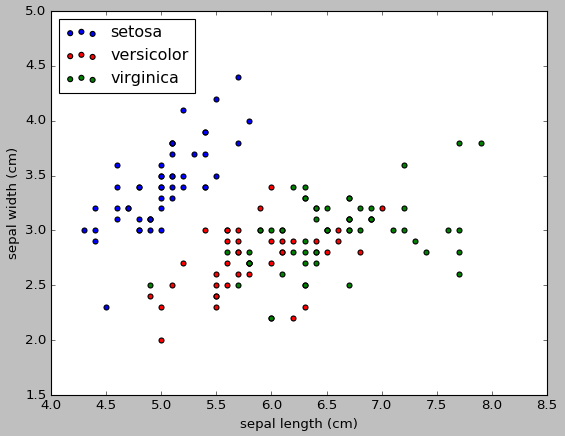
#画散点图,第一维的数据作为x轴和第二维的数据作为y轴
x_index=0
y_index=1
colors=['blue','red','green']
for label,color in zip(range(len(iris.target_names)),colors):
plt.scatter(iris.data[iris.target==label,x_index],
iris.data[iris.target==label,y_index],
label=iris.target_names[label],
c=color)
plt.xlabel(iris.feature_names[x_index])
plt.ylabel(iris.feature_names[y_index])
plt.legend(loc='upper left')
plt.show()
手写数字数据集load_digits():用于多分类任务的数据集
from sklearn.datasets import load_digits
digits=load_digits()
print(digits.data.shape)
import matplotlib.pyplot as plt
plt.gray()
plt.matshow(digits.images[0])
plt.show() from sklearn.datasets import load_digits
digits=load_digits()
digits.keys()
n_samples,n_features=digits.data.shape
print((n_samples,n_features)) print(digits.data.shape)
print(digits.images.shape) import numpy as np
print(np.all(digits.images.reshape((1797,64))==digits.data)) fig=plt.figure(figsize=(6,6))
fig.subplots_adjust(left=0,right=1,bottom=0,top=1,hspace=0.05,wspace=0.05)
#绘制数字:每张图像8*8像素点
for i in range(64):
ax=fig.add_subplot(8,8,i+1,xticks=[],yticks=[])
ax.imshow(digits.images[i],cmap=plt.cm.binary,interpolation='nearest')
#用目标值标记图像
ax.text(0,7,str(digits.target[i]))
plt.show()


乳腺癌数据集load-barest-cancer():简单经典的用于二分类任务的数据集
糖尿病数据集:load-diabetes():经典的用于回归认为的数据集,值得注意的是,这10个特征中的每个特征都已经被处理成0均值,方差归一化的特征值,
波士顿房价数据集:load-boston():经典的用于回归任务的数据集
体能训练数据集:load-linnerud():经典的用于多变量回归任务的数据集,其内部包含两个小数据集:Excise是对3个训练变量的20次观测(体重,腰围,脉搏),physiological是对3个生理学变量的20次观测(引体向上,仰卧起坐,立定跳远)
svmlight/libsvm的每一行样本的存放格式:
<label><feature-id>:<feature-value> <feature-id>:<feature-value> ....
这种格式比较适合用来存放稀疏数据,在sklearn中,用scipy sparse CSR矩阵来存放X,用numpy数组来存放Y
from sklearn.datasets import load_svmlight_file
x_train,y_train=load_svmlight_file("/path/to/train_dataset.txt","")#如果要加在多个数据的时候,可以用逗号隔开
②生成数据集
生成数据集:可以用来分类任务,可以用来回归任务,可以用来聚类任务,用于流形学习的,用于因子分解任务的
用于分类任务和聚类任务的:这些函数产生样本特征向量矩阵以及对应的类别标签集合
make_blobs:多类单标签数据集,为每个类分配一个或多个正太分布的点集
make_classification:多类单标签数据集,为每个类分配一个或多个正太分布的点集,提供了为数据添加噪声的方式,包括维度相关性,无效特征以及冗余特征等
make_gaussian-quantiles:将一个单高斯分布的点集划分为两个数量均等的点集,作为两类
make_hastie-10-2:产生一个相似的二元分类数据集,有10个维度
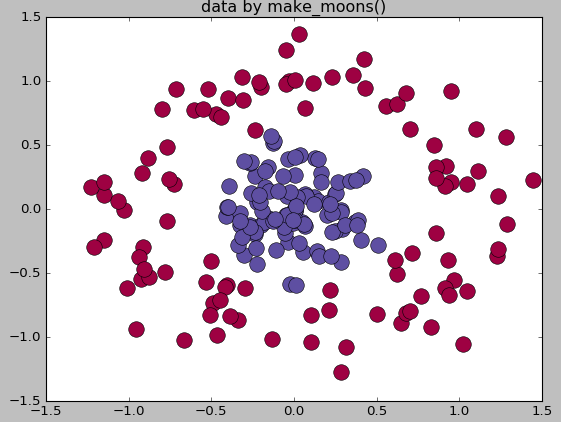
make_circle和make_moom产生二维二元分类数据集来测试某些算法的性能,可以为数据集添加噪声,可以为二元分类器产生一些球形判决界面的数据
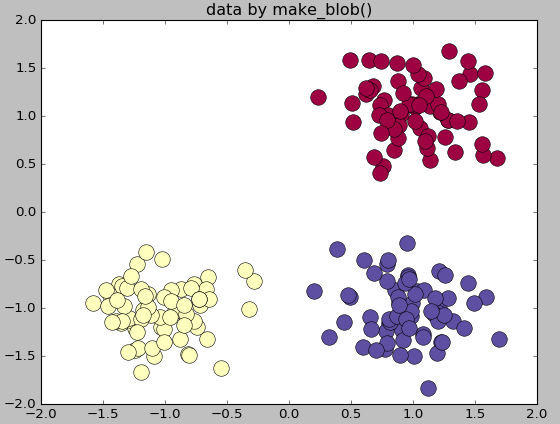
#生成多类单标签数据集
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets.samples_generator import make_blobs
center=[[1,1],[-1,-1],[1,-1]]
cluster_std=0.3
X,labels=make_blobs(n_samples=200,centers=center,n_features=2,
cluster_std=cluster_std,random_state=0)
print('X.shape',X.shape)
print("labels",set(labels)) unique_lables=set(labels)
colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
for k,col in zip(unique_lables,colors):
x_k=X[labels==k]
plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
markersize=14)
plt.title('data by make_blob()')
plt.show()
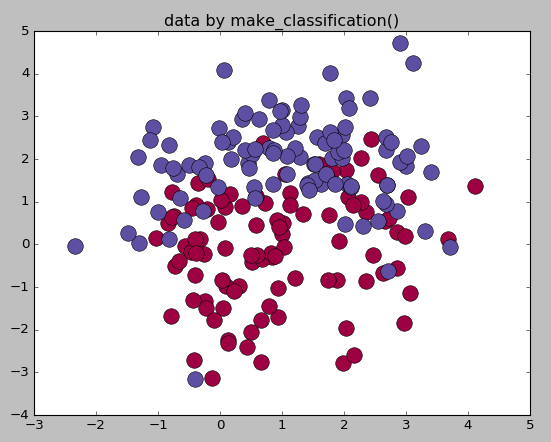
#生成用于分类的数据集
from sklearn.datasets.samples_generator import make_classification
X,labels=make_classification(n_samples=200,n_features=2,n_redundant=0,n_informative=2,
random_state=1,n_clusters_per_class=2)
rng=np.random.RandomState(2)
X+=2*rng.uniform(size=X.shape) unique_lables=set(labels)
colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
for k,col in zip(unique_lables,colors):
x_k=X[labels==k]
plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
markersize=14)
plt.title('data by make_classification()')
plt.show() #生成球形判决界面的数据
from sklearn.datasets.samples_generator import make_circles
X,labels=make_circles(n_samples=200,noise=0.2,factor=0.2,random_state=1)
print("X.shape:",X.shape)
print("labels:",set(labels)) unique_lables=set(labels)
colors=plt.cm.Spectral(np.linspace(0,1,len(unique_lables)))
for k,col in zip(unique_lables,colors):
x_k=X[labels==k]
plt.plot(x_k[:,0],x_k[:,1],'o',markerfacecolor=col,markeredgecolor="k",
markersize=14)
plt.title('data by make_moons()')
plt.show()
sklearn提供的自带数据集的更多相关文章
- Python——sklearn提供的自带的数据集
sklearn提供的自带的数据集 sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在线下 ...
- sklearn提供的自带的数据集
sklearn 的数据集有好多个种 自带的小数据集(packaged dataset):sklearn.datasets.load_<name> 可在线下载的数据集(Downloaded ...
- 『Sklearn』框架自带数据集接口
自带数据集类型如下: # 自带小型数据集# sklearn.datasets.load_<name># 在线下载数据集# sklearn.datasets.fetch_<name&g ...
- 2.sklearn库中的标准数据集与基本功能
sklearn库中的标准数据集与基本功能 下面我们详细介绍几个有代表性的数据集: 当然同学们也可以用sklearn机器学习函数来挖掘这些数据,看看可不可以捕捉到一些有趣的想象或者是发现: 波士顿房价数 ...
- TF:利用sklearn自带数据集使用dropout解决学习中overfitting的问题+Tensorboard显示变化曲线—Jason niu
import tensorflow as tf from sklearn.datasets import load_digits #from sklearn.cross_validation impo ...
- 关于无法下载sklearn中的MNIST original数据集的问题
在使用Sklearn进行加载自带的数据集MNIST时,总是报错,代码及相应的错误显示如下: from sklearn.datasets import fetch_mldata mnist = fetc ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- fmri的图像数据在matlab中显示,利用imagesc工具进行显示,自带数据集-by 西南大学xulei教授
这里包含了这样一个数据集:slice_data.mat. 这个数据集中包含的mri数据是:64*64*25.共有25个slice.每个slice的分辨率是64*64. 程序非常简短: load sli ...
- hibernate 为什么持久化类时必须提供一个不带参数的默认构造函数
因为hibernate框架会调用这个默认构造方法来构造实例对象..即Class类的newInstance方法 这个方法就是通过调用默认构造方法来创建实例对象的 ,另外再提醒一点,如果你没有提供任何构造 ...
随机推荐
- 配置Maven私服
Nexus 是“开箱即用”的系统,不需要数据库,它使用文件系统加 Lucene 来组织数据,支持 WebDAV 与 LDAP 安全身份认证.Nexus 还提供了强大的仓库管理功能,构件搜索功能,它基于 ...
- lamp+nginx代理+discuz+wordpress+phpmyadmin搭建
我们以模拟实际需求的形式来复习.需求如下:1. 准备两台centos 6,其中一台机器跑mysql,另外一台机器跑apache和nginx + php2. 同时安装apache和nginx,其中ngi ...
- 剑指offer——54数组中的逆序对
题目描述 在数组中的两个数字,如果前面一个数字大于后面的数字,则这两个数字组成一个逆序对.输入一个数组,求出这个数组中的逆序对的总数P.并将P对1000000007取模的结果输出. 即输出P%1000 ...
- Rollei SL66 使用说明
根据记忆,并用不规范的语言描述我对sl66的使用心得:一.上卷1.用摇把顺时针转到12点位置,再退回3点位置:2.安插刀:3.后背上方按钮向右拨,打开后背:4.取出,装卷,再放入:5.转动后背上旋钮, ...
- 2.4 Nginx服务器基础配置指令
2.4.1 nginx.conf文件的结构 2.4.2配置运行Nginx服务器用户(组) 2.4.3配置允许生成的worker process数 2.4.4 配置Nginx进程PID存放路径 2.4. ...
- 牛客练习赛48 D 小w的基站网络
链接:https://ac.nowcoder.com/acm/contest/923/D来源:牛客网 时间限制:C/C++ 2秒,其他语言4秒 空间限制:C/C++ 262144K,其他语言52428 ...
- pytest_fixture--scope="session"
import pytest@pytest.fixture(scope="session")def login(): print("\n输入用户名密码登陆! configt ...
- Aggregate report 聚合报告
- 笔记-Linux安装中文版man
使用环境为Ubuntu,安装中文版man,同时保留了英文原版,步骤如下: 第一种方法 sudo apt-get update # 更新你的下载源目录,此步骤可省略. sudo apt-get inst ...
- CSS案例2(一个简单的新闻网页)
知识点: 1.一般网页不用纯黑,用淡灰色 3c3c3c 2.text-align: center; /* 文字水平居中 */ 3.font-weight: normal; /* 清除加粗效果 ...