Cassandra 在 360 的实践与改进

分享嘉宾:王锋 奇虎360 技术总监
文章整理:王彦
内容来源:Cassandra Meetup
出品平台:DataFunTalk
注:欢迎转载,转载请留言。
导读:2010年,Dropbox 在线云存储在国外被用户熟知,同时国内如360、金山、百度等各个厂商也都陆续推出了自家的网盘类产品;而在 "360云盘" 背后的存储技术支撑之一就是以 Cassandra 为基础的云端存储方案。自此,Cassandra 在360实现技术落地和大规模生产应用,并被持续改进优化,最终形成高峰时期超 10k+ 物理节点的使用规模,成为互联网公司中 Cassandra 生产环境落地规模最大的公司。
本次分享的主要内容是 Cassandra 在360的落地实践过程中遇到的问题,以及一些重要的改进和优化,主要包括:
Cassandra 的特点简介
Cassandra 在360的选型
Cassandra 在360的应用场景
Cassandra 在360的技术演进
——Cassandra 的特点简介——
Cassandra 大致有以下的特点:

Cassandra 完全无中心化设计使得其具备极高的可用性和可平滑的拓展性,并且具有模式灵活,多数据中心,范围查询,列表数据结构,分布式写操作等优势:
❶ 由于其架构在中小规模部署时不需要主节点,相较于完全中心化的分布式存储设计具有更优的成本优势,从3台物理机开始一直拓展到几百台物理机,均可完全不停服情况下平滑拓展,整个过程只需要把拓展节点的进程启动加入集群;
❷ 模式灵活使得 Cassandra 可以在系统运行时随意添加或移除字段,这是一个很惊人的效率提升,特别是在大型部署上;
❸ 多数据中心是指可以调整节点布局来避免某一个数据中心失效,一个备用的数据中心将至少有每条记录的完全复制;
❹ 范围查询是指如果你不喜欢全部的键值查询,则可以设置键的范围来查询,对于每个用户的索引,这是非常方便的;
❺ 分布式写操作是指有可以在任何地方任何时间集中读或写任何数据,并且不会有任何单点失败。
除了以上几点,Cassandra 还有如下的优点:
❶ 海量数据,随时在线,分布式数据库,性能极优
❷ always online,无中心,无单点故障引发抖动
❸ 节点对等,配置一致,线性扩展,易于维护
❹ cql/sdk 能力,易用性好,开发者 & DBA 快速上手
❺ 功能强大,主要有以下几点功能,多 DC 两地三中心,在线更改 schema,丰富数据结构,丰富的索引,监控及工具。
——Cassandra 在360的选型——

选型之始,我们总结评估了云存储的技术需求特征和当时可承载大规模数据的分布式 K-V 数据库——Cassandra 和 HBase,最终权衡之后,使用 Cassandra 做为主要在线存储。对于 "网盘/云盘" 类产品,其主要流量特征为 "写多读少",要求服务可靠性和数据安全性极高,基本不可容忍服务中断和数据丢失的情况。具体选型分析如下:
❶ Cassandra 相较于 HBase,前者是完全无中心设计,而后者 ( 包括依赖的 HDFS ) 整体来看是强中心化设计,因此 Cassandra 与生俱来不存在关键单点故障影响服务的问题;
❷ Cassandra 使用最终一致性策略,而非 HBase 的强一致性策略,配合读写策略的处理,Cassandra 可以在确保数据安全性、可靠性、一致性的前提下,出现节点宕机而不需要恢复时间,集群读写不产生任何停顿,而此场景下,HBase 需要等待 region 重新分配过程,而这个过程大概会有数秒至数分钟的待分配 region 不可读写;
❸ 从技术细节上,虽然二者均采用了 LSM 的架构,但 Cassandra 直接操作本地磁盘,而 HBase 需要依赖 HDFS 共享存储,加之上述所说的架构设计差异,同等基础设施性能的 Cassandra 写入性能优于 HBase 近乎一个数量级,读性能基本持平。
综上所述,Cassandra 可以更好的适用于云盘在线场景。
——Cassandra 在360的应用场景——
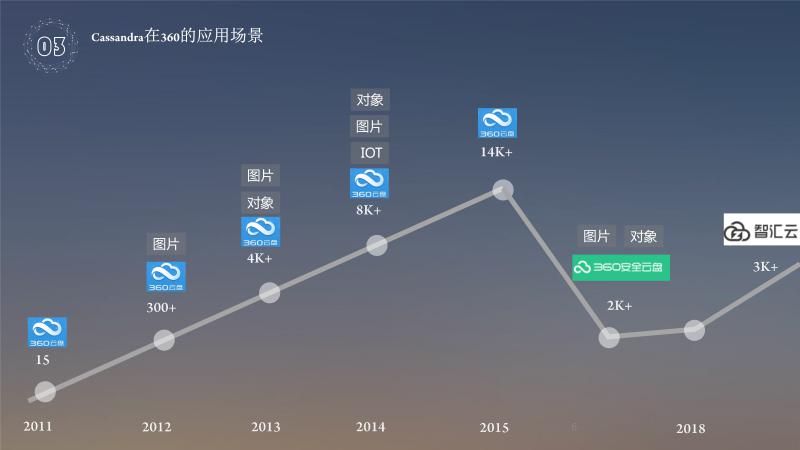
基于360云盘使用 Cassandra,云盘从15台机器一直到14000+台机器,应用场景主要是个人数据,自己产品中间的图片,内部视频对象等;在2015年,360云盘转型为企业云盘,机器数量就下降了,到2018年,智汇云又继续前行,目前机器差不多是3000左右的规模,以上是360的应用场景。
——Cassandra 在360的技术演进——
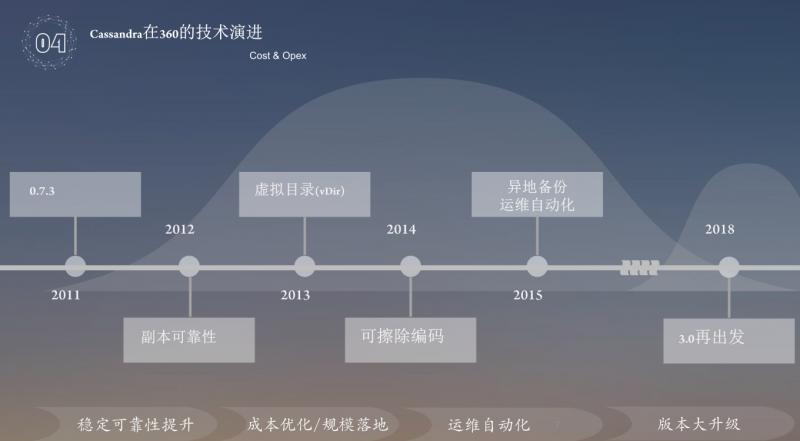
Cassandra 自2010在360开始调研技术落地;2011年使用 Cassandra 0.7.3作为基础版本应用于生产环境;2012年完善数据可靠性和安全性,实现不停机和不单纯依赖读修复的数据快速恢复;2013-2014年以节省成本为目的,实现可擦除编码技术应用于 Cassandra,在确保数据安全和可靠性的前提下实现成本降低60%;2014-2015年面对超大规模集群的超复杂性问题,实现运维自动化,集群具备自主自愈、自主风控等自主运维能力 ( 近 1w5 物理节点,89个集群,两人运维 );2018年,我们发现 Cassandra 社区版本与360版本相当于是不同场景殊途同归 ( 社区为轻 Value,360为重 Value ),并且社区很多好的思路非常值得考虑,因此我们重新调整研发策略,与社区共同成长。

Cassandra 是一种无中心的系统,对于消息的广播,有一些规模的限制,基本单节点到600台的时候就差不多了,当时云盘的集群规模,单集群是600台,Cassandra 集群规模达到了88个,磁盘使用率达到了90%,主要是为了成本考虑,把磁盘使用率达到了90%。这其中用的是预先划分 range,毕竟当时没有 VNode,使用预先划分首先是使用 RandomPartitioner,使用例如 hash,md5 让数据随机打到环上,这个是使用最多的;还有一种是 OrdePerservingPartitinoer,这是一种保序的方式,把一些 key 保序的存在环上,文件 I/O 使用的 standard 跟 Mmapped,Mmapped 理论上是减少内存拷贝,对性能很好,但是如果数据量涨到80%到90%的时候,Linux 内核页表的开销占用量很大,所以最后放弃了 Mmapped 的方式,使用了 standard 的方式。

对于 Cassandra 的改进,第一个就是进行可靠性的改进,使用 Local Repair 跟 Backup。影响数据可靠性的因素有:
❶ One/Quorum 存在新增副本不足的问题;
❷ 磁盘/扇区故障:文件损坏、数据丢失 ( 月均故障25-30块 );
❸ 现有数据恢复机制存在不完善之处。
因素 ❶ 是第三副本是否可以成功写入的问题,使用非 ALL 策略写入 Cassandra 时,只要满足写入策略即返回成功,例如 quorum 级别写入3副本数据,当两个节点写入成功即返回写入成功,虽然原始设计为了保障第三副本写入成功使用 hintedhandoff 机制来保证,但程序设计最多能支撑3小时的时间,虽然该项可配但也受限于接入节点的存储容量,因此360针对此问题做了优化,研发 proxycheck 功能将未成功写入打散到全集群,当故障节点恢复时,基于 proxycheck 会修复残缺副本;
因素 ❷ 是磁盘故障,虽然小规模磁盘很少见磁盘损坏,但对于极大规模的存储系统来说,磁盘故障就变得不可忽略了,而 Cassandra 的架构又决定了如果磁盘损坏造成了副本残缺很难发现,只能等待读修复触发或者 repair 工具修复,但对长时间不读取的冷数据很显然存在较大数据风险;
因素 ❸ 是修复机制,无论是因素 ❷ 导致的还是其他问题造成的数据残缺都需要恢复机制尽快恢复数据,但 Cassandra 读修复对冷数据不友好,repair 工具会耗尽整个集群的资源,对于这些挑战,除了读修复,我们实现了一套相当于 RowRepair 的机制。
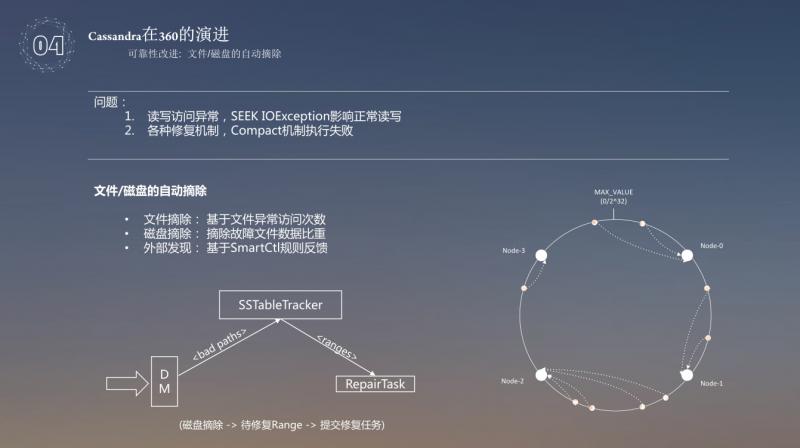
首先来说一下文件/磁盘的自动摘除, 存在的问题主要有两点,一点是读写异常,SEEKIOException 影响正常读写,另外一点是各种修复机制,Compact 机制执行失效,针对以上的两点问题,主要采用了基于文件异常访问次数的统计,摘除故障文件数据比重,外部发现基于 SmartCtl 规则反馈,将以上的问题反馈到系统中,就可以精确的知道哪块磁盘有哪些问题。
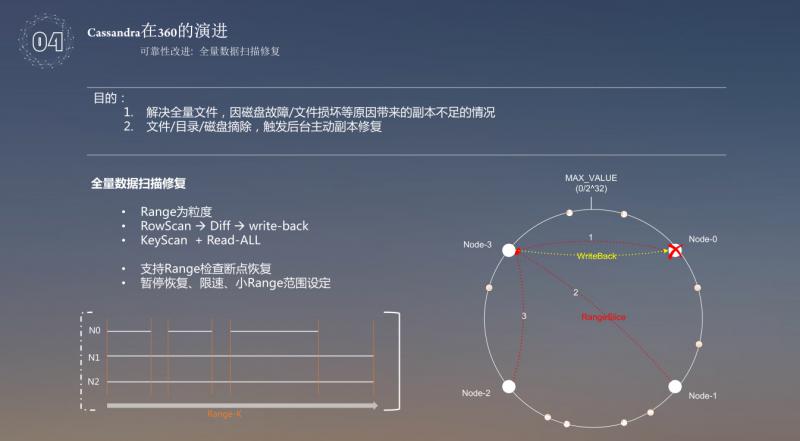
修复磁盘故障摘除,此处针对的是全量数据的磁盘故障摘除,使用全盘数据扫描恢复的目的主要有两点,一是用来解决全量文件,因磁盘故障/文件损坏等原因带来的副本不足的情况,二是文件/目录/磁盘摘除,触发后台主动副本修复。全盘数据扫描修复,从 Range 的开始,三个节点都读数据,如果数据存在冲突,就使用另外两个节点去解决数据冲突,最后把数据恢复。每个节点都会附一个 range,range 的主要作用就是从三个节点上把数据取过来进行比对,然后把解决冲突的数据恢复掉,另外一种方式使用 KeyScan+Read-All,使用 KeyScan 拿到的是一些 key,对于大量的插入,像云盘用户是大量的插入比较多,删除的操作很少,这种场景下数据存储使用的是 key-value 的数据格式存储,这种情况下,如果节点上丢掉了哪些数据,可以直接使用 key 来修复这些丢掉的数据。通过这两种方式可以解决文件丢失或者损坏的问题。

解决了全量数据,接着解决增量数据的检查修复问题。增量数据检查修复主要存在以下三个问题:
❶ 如何保证新写入的数据副本是足够的 ( 拒绝/超时 )
❷ 如何弥补 Hinted handoff 的缺点 ( 时间窗口 )
❸ Quorum 写存在 W<N
针对以上问题,Hinted handoff 对于 i/o 负载或者 i/o 假死没有考虑到,这种情况下,Hintedhandoff 没有去把出问题的东西记下来,时间窗口存在的问题是如果超时了,丢失的数据可能就记录不下来,所以需要把这两种情况记录下来,以便更好的解决增量数据存在的问题。其原理是:如果提供两种方式,第一种如果 proxycheck 把 value 记录进来以后,数据有问题,可以直接使用另外的副本进行数据修复,还有一种如果不记录的话,可以使用 all 级别读修复来对数据进行恢复。使用 Proxy 节点负责记录副本不全的 row,超时拒绝导致的三个副本可能只写成功了两个,这种情况也需要记录下来,这种情况下,实时的去做数据的恢复或者副本的补全,使用 proxycheck 表来存储辅助的 Keyspace,把所有检测到的副本不足的数据都记录到这张表中,Proxy 节点还用于记录数据的修复,把数据存储,proxycheck 用了两副本,这样做会加大系统的开销,但是数据的可靠性得到保证。
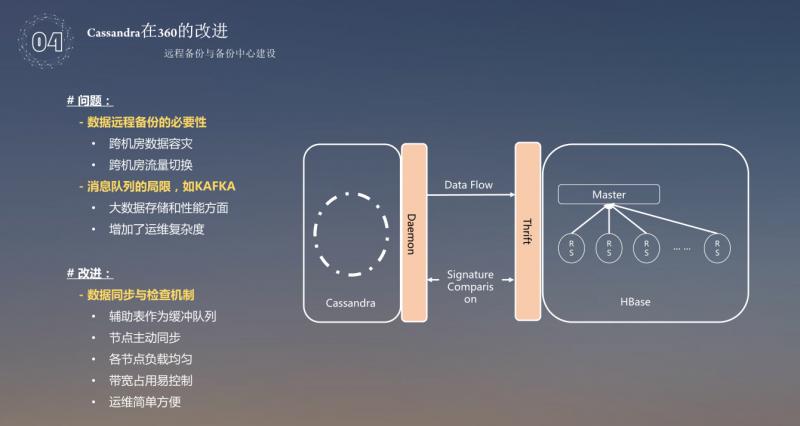
数据的恢复,涉及到存储,同时,还需要用到数据的备份。当时没有所谓的多 DC 方式,都是自研的备份系统,当时 Cassandra 的集群数量有88个,如果采用 Cassandra+Cassandra 的主备模式,那将又是88个集群,这是对运维和成本的巨大挑战;因此我们选择了在极大规模场景下扩展更好的 HBase 作为备份存储,使用 Cassandra ( 主 ) +HBase ( 备 ) 方案,这样全球88个集群数据备份集中至四大备份中心。大量的数据备份,经常使用的方式就是消息队列,数据的汇聚会增加运维的成本以及数据的落地然后再去做,这样操作的话,延时会比较高。所以在 Cassandra 中做了一个机制,每个节点负责自己的 range 管理,可以记录到自己的缓存表中,从缓冲表取出来备份到数据中心,使用 Thirft 接口,HBase 跟 Cassandra 的接口完全是兼容的,这样设计 HBase 备份中心就相当于一个 Cassandra 的数据中心了,如果数据大量丢失,或者数据出现大量的错误问题,可以直接无缝切换到 HBase 上提供服务,然后再使用 HBase 备份的数据慢慢恢复丢失的数据,用户完全不会感觉到服务异常,提高了用户的体验。
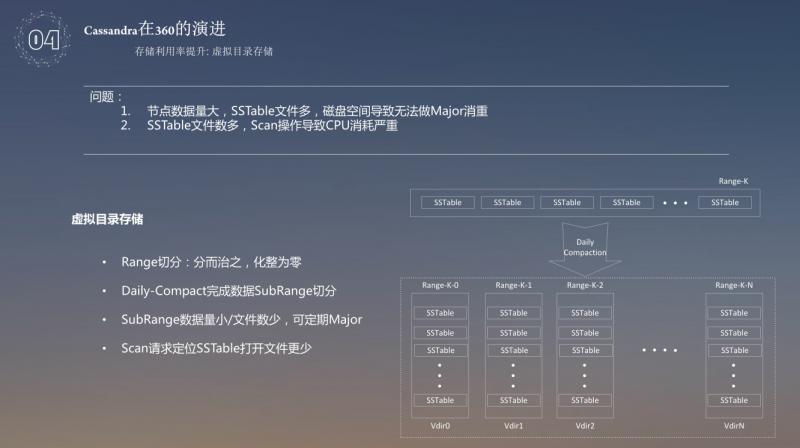
前面介绍的是数据方面的问题,下面介绍下如何提高磁盘的利用率也就是降低成本。主要是利用虚拟目录来提高磁盘的利用率,磁盘的利用率提高主要问题存在两点:
❶ 节点数量大,SSTable 文件多,磁盘空间导致无法做 major 消重;
❷ SSTable 文件数多,Scan 操作导致 CPU 消耗严重。
对于这两个问题,当时磁盘的利用率达到50%就无法再提高利用率,继而我们采用了分而治之的思想,把一个大 range 使用 Daily—Compact 完成数据 SubRange,切分为几个小 range,每个 range 代表一个目录,由于切分以后,数据量变小,每个 range 都可以做自己的 major,可以把重复的部分都清除掉 ( 但是如果在磁盘利用率90%以上,做一次 major 就很消耗 CPU 性能 ) ,这样做以后,对于 Scan 请求定位 SSTable 打开的文件会更少,效率就会更高,速度也会更快。
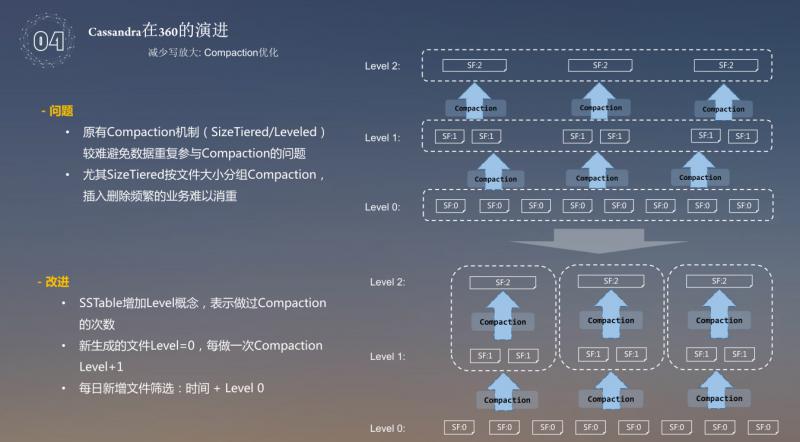
避免写放大的问题。对于如何减少写放大问题,主要存在以下两个问题:
❶ 原有的 Compaction 机制 ( SizeTiered/Leveled ) 较难避免数据重复参与 Compaction 的问题;
❷ 尤其在 SizeTiered 按文件大小分组 Compaction,插入删除频繁的业务难以消重。
针对上述问题,我们采用给 SSTable 增加 level 概念。正常的是给每层的数据从 level 0 -> level 2,到 level 2 后,compaction 就不会参加,也就说最多做两次。360对于这一块做了如下的改进:让每层的 compaction 结合虚拟目录,在 level 0 做 compaction 的时候,分成各种各样的虚拟目录进行 subrange,subrange 里边再去做 compaction,这样的话,就相当于虚拟目录没有重复的数据出现,控制文件参与 compaction 的次数,通过这两种方式,使磁盘的利用率达到了90%左右。
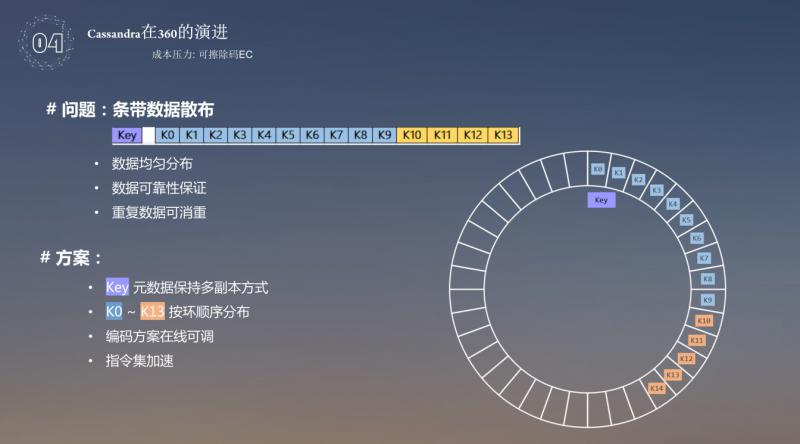
成本压力。基于成本的考量,使用了 EC 的方式,让3副本变成了1.4个副本,在较少副本数量的同时保证数据的可靠性,同时从数据可用性上考虑的话,数据可用性基本保持以下两点就可以:
❶ 副本方式,也就是连续3节点磁盘故障,数据必丢失;
❷ 条带方式,相邻的14节点故障任意4个数据仍可修复。
对于这个内容,EC 是把原有的数据进行块切分,算出校验块,然后校验块打散到整个集群中,如果丢失了几个块,可以用其他的10个块进行修复,再把分散的块 key 存储到 cfindex 的表中。对于前边的条带方式,主要使用切分 value,value 采用的是 512k 切成等份的4等份,可以得到4个校验块,需要全部打散到不同的数据块上,比如下图中的 k13,k14 不能放到一台机器上,这样才有意义,一旦数据丢失了,还可以方便恢复,如果四个块在一台机器上,坏了两台机器就没法恢复了,key 的数据有两部分,一个是元数据,一个是条带数据。元数据还是保持多副本的形式,但是算出来的条带数据实际上是按环分布,分成单副本的方式去存储,这样其实就可以达到三副本到1.4副本,编码可以在线调整,还可以使用指令集加速,通过指令集对 EC 进行加速,这块比较难的问题是如何把 Key 值分散在整个环上,而且还在不同的机器上,如果使用 Md5 算出来 value 值当作 key 值,还是有可能 Key 值存储在一台机器上,所以还是采用了 OrderPreservingPartitioner 保序的方式去存储。
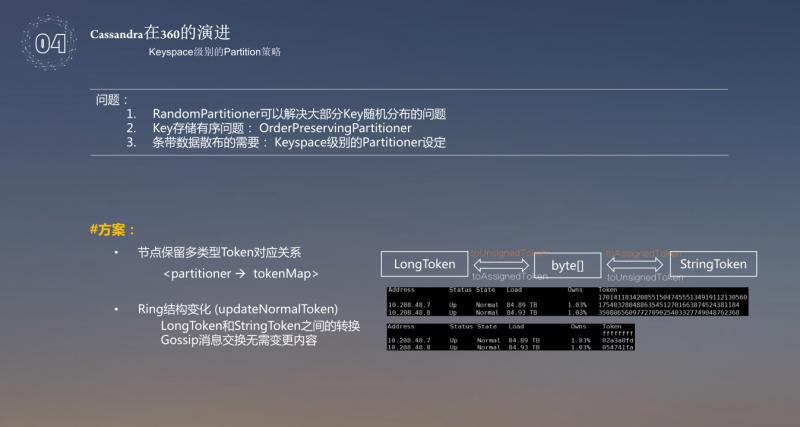
接着做了一个 Keyspace 级别的 Patition 策略,以前的 key 存在以下问题:
❶ RandomPartition 可以解决大部分 Key 随机分布的问题;
❷ key 存储有序问题,OrderPreservingPartitioner;
❸ 是条带数据散布的需要,Keyspace 级别的 Partitioner 设定。
前面说 key 存储用到了 OrderPreservingPartitioner,这样在一套系统里需要两套不同的 partition 机制,如果进行数据交互,就需要既要保持 RandomPartition 的结构,还要保持 OrderPreservingPartitioner 的结构。这样的话,数据交换会变的异常的复杂,所以做了一个消息传递,过程中还是使用 LongToken 去存,在使用时,还是需要维护两套,当撤出或者加入环中时,都要进行转化,所以系统会看到两套内容。

其他的改进点如下:
❶ Hinted handoff :外部工具,解决宕机时间过长,超过 Hinted 时间窗口;
❷ MemTable Flush 选盘策略:避免并发 dump MemTable 带来的 CPU 开销,避免小文件的产生;
❸ Cassandra 集群管控,配置自动加载,磁盘自动下线报修。
PS: DataFunTalk NLP交流群,跟同行零距离交流。如想进群,请加逃课儿同学的微信 ( 微信号:DataFunTalker ),回复:NLP,逃课儿会自动拉你进群。
Cassandra 在 360 的实践与改进的更多相关文章
- 国浩:Cassandra在360的最新进展
大家好,我是来自奇虎360的国浩.今天我给大家带来的是Cassandra在360的最新进展. 我会从四个方面来介绍Cassandra在360的应用情况:Cassandra在360的使用历史再结合两个案 ...
- 活动精彩实录 | 王峰:Cassandra在360的多场景应用及未来趋势
点击此处观看完整活动视频 大家好,我是360的王峰,我今天主要通过Cassandra在多场景下的应用来介绍一下Cassandra在360落地的情况. 我会从以下这几个方面进行介绍.首先介绍下Cassa ...
- Qihoo 360 altas 实践
Qihoo 360 altas 实践 简介 Atlas是由 Qihoo 360公司Web平台部基础架构团队开发维护的一个基于MySQL协议的数据中间层项目.它在MySQL官方推出的MySQL-Prox ...
- Cassandra之Docker环境实践
Cassandra简介 Cassandra是一个开源分布式NoSQL数据库系统. 它最初由Facebook开发,用于储存收件箱等简单格式数据,集GoogleBigTable的数据模型与Amazon D ...
- Cassandra学习&命令行实践
准备 按照Cassandra集群部署搭建两台测试机,环境信息如下: 名称 IP 数据中心名称 node-01 192.168.198.130 datacenter1 node-02 192.168.1 ...
- 华为刘腾:华为终端云Cassandra运维实践分享
点击此处观看完整活动视频 各位线上的嘉宾朋友大家好,我是来自华为消费者BG云服务部的刘腾,我今天给大家分享的主题是华为终端云Cassandra运维实践.和前面王峰老师提到的Cassandra在360中 ...
- Cassandra存储附带索引(SAI)全新上线
新一代Apache Cassandra索引现已在Astra和DataStax Enterprise 6.8.3中正式开放使用 (general availability or GA),很快您也将在开源 ...
- Cassandra 计数器counter类型和它的限制
文档基础 Cassandra 2.* CQL3.1 翻译多数来自这个文档 更新于2015年9月7日,最后有参考资料 作为Cassandra的一种类型之一,Counter类型算是限制最多的一个.Coun ...
- 一个小团队TDD游戏及实践
介绍的这个游戏是自己根据目前带的团队的实际情况来制定的, 在游戏实践过程中,收到了较好的效果,故打算把这个游戏分享出来,一是分享一下实践,而是集思广益,不断完善,更好的利用游戏来锻炼队伍.下面就将游戏 ...
随机推荐
- 每天玩转3分钟 MyBatis-Plus - 5. 高级查询(三)(条件构造器)
每天玩转3分钟 MyBatis-Plus - 1. 配置环境 每天玩转3分钟 MyBatis-Plus - 2. 普通查询 每天玩转3分钟 MyBatis-Plus - 3. 高级查询(一) 每天玩转 ...
- Python学习,第五课 - 列表、字典、元组操作
本篇主要详细讲解Python中常用的列表.字典.元组相关的操作 一.列表 列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储.修改等操作 通过下标获取元素 #先定义一个列表 le ...
- 史上最详细的二叉树、B树,看不懂怨我
今天我们要说的红黑树就是就是一棵非严格均衡的二叉树,均衡二叉树又是在二叉搜索树的基础上增加了自动维持平衡的性质,插入.搜索.删除的效率都比较高.红黑树也是实现 TreeMap 存储结构的基石. 1.二 ...
- HttpClient介绍和使用
HttpClient介绍和使用 今天有一个需求:后台访问一个接口,获取返回的数据.于是找到了HttpClient 1.介绍 SpringCloud中服务和服务之间的调用全部是使用HttpClient, ...
- node--->PHPStorm 停留在 Scanning files to index..
使用webpack时,敲了npm 一些命令后,PHPStorm 开始 Scanning files to index...,去建立文件索引,但是如果一直停留在这个状态,说明是npm install 后 ...
- php--->依赖注入(DI)实现控制反转(IOC)
依赖注入(DI)实现控制反转(IOC) DI和IOC概念理解 当一个类的实例需要另一个类的实例协助时,在传统的程序设计过程中,通常由调用者来创建被调用者的实例.而采用依赖注入的方式,创建被调用者的工作 ...
- MySQL 高可用之主从复制
MySQL主从复制简介 Mysql的主从复制方案,都是数据传输的,只不过MySQL无需借助第三方工具,而是自带的同步复制功能,MySQL的主从复制并不是磁盘上文件直接同步,而是将binlog日志发送给 ...
- Shell常用命令之yum
介绍 yum命令是在Fedora和RedHat以及SUSE中基于rpm的软件包管理器,它可以使系统管理人员交互和自动化地更细与管理RPM软件包,能够从指定的服务器自动下载RPM包并且安装,可以自动处理 ...
- vuex之Mutation(三)
说明 既然我们可以取出数据,就可以修改数据,而修改数据并不是像修改data的数据一样,直接 this.xxx = xxx,这样有一个问题,在实际开发中,state的数据一般会多个组件共享,如果可以使用 ...
- IntelliJ IDEA的这个接口调试工具真是太好用了!
你有一个思想,我有一个思想,我们交换后,一个人就有两个思想 If you can NOT explain it simply, you do NOT understand it well enough ...