k近邻算法-java实现
最近在看《机器学习实战》这本书,因为自己本身很想深入的了解机器学习算法,加之想学python,就在朋友的推荐之下选择了这本书进行学习。
一 . K-近邻算法(KNN)概述
最简单最初级的分类器是将全部的训练数据所对应的类别都记录下来,当测试对象的属性和某个训练对象的属性完全匹配时,便可以对其进行分类。但是怎么可能所有测试对象都会找到与之完全匹配的训练对象呢,其次就是存在一个测试对象同时与多个训练对象匹配,导致一个训练对象被分到了多个类的问题,基于这些问题呢,就产生了KNN。
KNN是通过测量不同特征值之间的距离进行分类。它的的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。K通常是不大于20的整数。KNN算法中,所选择的邻居都是已经正确分类的对象。该方法在定类决策上只依据最邻近的一个或者几个样本的类别来决定待分样本所属的类别。
下面通过一个简单的例子说明一下:如下图,绿色圆要被决定赋予哪个类,是红色三角形还是蓝色四方形?如果K=3,由于红色三角形所占比例为2/3,绿色圆将被赋予红色三角形那个类,如果K=5,由于蓝色四方形比例为3/5,因此绿色圆被赋予蓝色四方形类。
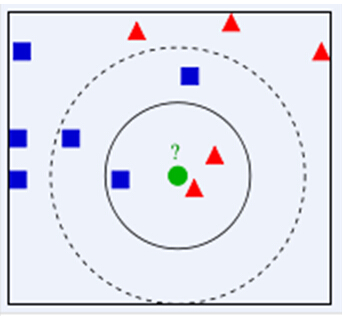
由此也说明了KNN算法的结果很大程度取决于K的选择。
在KNN中,通过计算对象间距离来作为各个对象之间的非相似性指标,避免了对象之间的匹配问题,在这里距离一般使用欧氏距离或曼哈顿距离:

同时,KNN通过依据k个对象中占优的类别进行决策,而不是单一的对象类别决策。这两点就是KNN算法的优势。
接下来对KNN算法的思想总结一下:就是在训练集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
1)计算测试数据与各个训练数据之间的距离;
2)按照距离的递增关系进行排序;
3)选取距离最小的K个点;
4)确定前K个点所在类别的出现频率;
5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
代码实现:
import java.util.*; /**
* code by me
* <p>
* Data:2017/8/17 Time:16:40
* User:lbh
*/
public class KNN { /**
* KNN数据模型
*/
public static class KNNModel implements Comparable<KNNModel> {
public double a;
public double b;
public double c;
public double distince;
String type; public KNNModel(double a, double b, double c, String type) {
this.a = a;
this.b = b;
this.c = c;
this.type = type;
}
/**
* 按距离排序
*
* @param arg
* @return
*/
@Override
public int compareTo(KNNModel arg) {
return Double.valueOf(this.distince).compareTo(Double.valueOf(arg.distince));
}
} /**
* 计算距离
*
* @param knnModelList
* @param i
*/
private static void calDistince(List<KNNModel> knnModelList, KNNModel i) {
double distince;
for (KNNModel m : knnModelList) {
distince = Math.sqrt((i.a - m.a) * (i.a - m.a) + (i.b - m.b) * (i.b - m.b) + (i.c - m.c) * (i.c - m.c));
m.distince = distince;
}
} /**
* 找出前k个数据中分类最多的数据
*
* @param knnModelList
* @return
*/
private static String findMostData(List<KNNModel> knnModelList) {
Map<String, Integer> typeCountMap = new HashMap<String, Integer>();
String type = "";
Integer tempVal = 0;
// 统计分类个数
for (KNNModel model : knnModelList) {
if (typeCountMap.containsKey(model.type)) {
typeCountMap.put(model.type, typeCountMap.get(model.type) + 1);
} else {
typeCountMap.put(model.type, 1);
}
}
// 找出最多分类
for (Map.Entry<String, Integer> entry : typeCountMap.entrySet()) {
if (entry.getValue() > tempVal) {
tempVal = entry.getValue();
type = entry.getKey();
}
}
return type;
} /**
* KNN 算法的实现
*
* @param k
* @param knnModelList
* @param inputModel
* @return
*/
public static String calKNN(int k, List<KNNModel> knnModelList, KNNModel inputModel) {
System.out.println("1.计算距离");
calDistince(knnModelList, inputModel);
System.out.println("2.按距离(近-->远)排序");
Collections.sort(knnModelList);
System.out.println("3.取前k个数据");
while (knnModelList.size() > k) {
knnModelList.remove(k);
}
System.out.println("4.找出前k个数据中分类出现频率最大的数据");
String type = findMostData(knnModelList);
return type;
} /**
* 测试KNN算法
*
* @param args
*/
public static void main(String[] args) {
// 准备数据
List<KNNModel> knnModelList = new ArrayList<KNNModel>();
knnModelList.add(new KNNModel(1.1, 1.1, 1.1, "A"));
knnModelList.add(new KNNModel(1.2, 1.1, 1.0, "A"));
knnModelList.add(new KNNModel(1.1, 1.0, 1.0, "A"));
knnModelList.add(new KNNModel(3.0, 3.1, 1.0, "B"));
knnModelList.add(new KNNModel(3.1, 3.0, 1.0, "B"));
knnModelList.add(new KNNModel(5.4, 6.0, 4.0, "C"));
knnModelList.add(new KNNModel(5.5, 6.3, 4.1, "C"));
knnModelList.add(new KNNModel(6.0, 6.0, 4.0, "C"));
knnModelList.add(new KNNModel(10.0, 12.0, 10.0, "M"));
// 预测数据
KNNModel predictionData = new KNNModel(5.1, 6.2, 2.0, "NB");
// 计算
String result = calKNN(3, knnModelList, predictionData);
System.out.println("预测结果:"+result);
}
}
结果:

k近邻算法-java实现的更多相关文章
- k近邻算法的Java实现
k近邻算法是机器学习算法中最简单的算法之一,工作原理是:存在一个样本数据集合,即训练样本集,并且样本集中的每个数据都存在标签,即我们知道样本集中每一数据和所属分类的对应关系.输入没有标签的新数据之后, ...
- 机器学习实战笔记--k近邻算法
#encoding:utf-8 from numpy import * import operator import matplotlib import matplotlib.pyplot as pl ...
- 基本分类方法——KNN(K近邻)算法
在这篇文章 http://www.cnblogs.com/charlesblc/p/6193867.html 讲SVM的过程中,提到了KNN算法.有点熟悉,上网一查,居然就是K近邻算法,机器学习的入门 ...
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- 机器学习之K近邻算法(KNN)
机器学习之K近邻算法(KNN) 标签: python 算法 KNN 机械学习 苛求真理的欲望让我想要了解算法的本质,于是我开始了机械学习的算法之旅 from numpy import * import ...
- k近邻算法
k 近邻算法是一种基本分类与回归方法.我现在只是想讨论分类问题中的k近邻法.k近邻算法的输入为实例的特征向量,对应于特征空间的点,输出的为实例的类别.k邻近法假设给定一个训练数据集,其中实例类别已定. ...
- KNN K~近邻算法笔记
K~近邻算法是最简单的机器学习算法.工作原理就是:将新数据的每一个特征与样本集中数据相应的特征进行比較.然后算法提取样本集中特征最相似的数据的分类标签.一般来说.仅仅提取样本数据集中前K个最相似的数据 ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 机器学习——KNN算法(k近邻算法)
一 KNN算法 1. KNN算法简介 KNN(K-Nearest Neighbor)工作原理:存在一个样本数据集合,也称为训练样本集,并且样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属分 ...
随机推荐
- Sqlite的多表连接更新
最近处理一个较大数据的sqlite库,基础表300万条,结果表30万条左右,我的笔记本跑起来还算流畅.最后结果,需要两个表连接,把另一个表的计算结果更新过来,却遇到麻烦.sqliter并不支持常见的连 ...
- OpenGL ES 3.0 and libGLESv2
note that libGLESv2 is the recommended Khronos naming convention for the OpenGL ES 3.0 library. This ...
- docker service ps打印出来的错误信息被截断了怎么办?
[解决方法] 用Format属性: 这个其实解决不了截断的问题,不过可以显示更少的列,看起来更清楚. Formatting The formatting options (--format) pr ...
- Android自定义一款带进度条的精美按键
Android中自定义View并没有什么可怕的,拿到一个需要自定义的View,首先要做的就是把它肢解,然后思考每一步是怎样实现的,按分析的步骤一步一步的编码实现,最后你就会发现达到了你想要的效果.本文 ...
- LNMP(Linux+Nginx+MySQL+PHP)centos6.4安装
nginx命令 停止nginx服务:# /etc/init.d/nginx stop 启动nginx服务:# /etc/init.d/nginx start 编辑nginx配置文件:# vim /et ...
- jQuery 用each后添加click
mydd = $('.plist'); mydd.each(function(i){ $(this).click(function(){ mydl.eq(i).hide("slow" ...
- (转)pip和easy_install使用方式
easy_install 跟 pip 都是 Python 的套件管理程式,有了它們,在使用 Python 開發程式的時候會帶來不少方便. easy_install 和 pip 有什麼不一樣?據 pip ...
- Active Directoty域服务安装
运行dcpromo命令,打开“Active Directoty域服务安装向导”
- MYSQL优化优化再优化!
1.数据库设计和表创建时就要考虑性能 2.sql的编写需要注意优化 3.分区 4.分表 5.分库 .数据库设计和表创建时就要考虑性能 mysql数据库本身高度灵活,造成性能不足,严重依赖开发人员能力. ...
- python之模块cmath
# -*- coding: utf-8 -*-#python 27#xiaodeng#python之模块cmath #复数的数学函数,如log.tan.sin等函数用法,针对我目前的情况用途较少,暂不 ...