【java】详解I/O流
目录结构:
1. File类
Java用File来访问文件、目录,以及对它们的删除、创建等。
接下来列出File类中常用的方法:
1. 访问文件名相关的方法
Sring getName():返回此File对象所表示的文件名或路径名(如果是路径则返回最后一级子路径)
String getPath():返回此File对象所对应的路径名
File getAbsoluteFile():返回此File对象所对应的绝对路径名称
String getParent():返回此File对象所对应的目录(最后一级子目录)的父目录名。
boolean renameTo(File newName):重命名此File对象所对应的的文件或是目录,如果重命名成功,则返回true,否则返回false。
2.文件检查相关的方法
boolean exists():判断File对象所对应的文件或目录是否存在。
boolean canWrite():判断File对象所对应的文件或目录是否可写。
boolean canRead():判断File对象所对应的文件或目录是否可读。
boolean isFile():判断File对象所对应的是否是文件。
boolean isDirectory():判断FIle对象所对应的是否是目录。
boolean isAbsolute():判断File所对应的文件或目录是否是绝对路径。该方法消除了不同平台的差异,可以直接判断FIle对象是否为绝对路径。在UNIX/Linux/BSD 等系统,如果路径名开头是一条斜线(/),则表明该File对象所对应一个绝对路径。在Window系统上,如果路径开头盘符,则说明它是一个绝对路径。
3.获取常规文件信息
boolean lastModified():返回文件的最后修改时间。
boolean length():返回文件内容的长度。
4.获取文件的常规信息
boolean createNewFile():当此File对象所对应的文件不存在时,该方法将新建一个该File对象所对应的新文件。如果创建成功则返回true,否则返回false。
boolean delete():删除File对象所对应的文件或是目录。
static File createTempFile(String prefix,String suffix) 在默认的临时文件目录中创建一个临时的空文件,使用给定前缀、系统生成的随机数和给定后缀做文件名。这是一个静态方法,可以直接通过File类来调用。Prefix参数必须至少是3字节长。建议前缀使用一个短的,有意义的字符串。suffix 可以为null,这种情况下默认使用后缀“.temp”。
static File createTempFile(String prefix,String suffix,File directory) 在directory指定的目录中创建一个临时的空文件,使用给定前缀、系统生成的随机数和给定后缀作为文件名。这是一个静态方法,可以直接通过File类来调用。
void deleteOnExit():注册一个删除勾子,指定当Java虚拟机退出时,删除File对象所对应的文件和目录。
5.目录操作相关的方法
boolean mkdir():试图创建一个File对象所对应的目录,如果创建成功,则返回true;否则返回false,调用方法时,File对象必须对应一个路径。
String[] list() 列出File对象的所有子文件名和路径名。
File[] listFiles() 列出File对象的所有子文件和路径。
static File[] listRoots() 列出系统所有的根目录。
下面使用使用递归打印某个目录下及其子目录下的所有的文件名:
public class TestDirPrint {
//打印指定目录中的内容,要求子目录中的内容也要打印出来
public static void dirPrint(File f){
//1.若f关联的是普通文件,则直接打印文件名即可
if(f.isFile()){
System.out.println(f.getName());
}
//2.若f关联的是目录文件,则打印目录名的同时使用[]括起来
if(f.isDirectory()){
System.out.println("[" + f.getName() + "]");
//3.获取该目录中的所有内容,分别进行打印
File[] ff = f.listFiles();
for(File ft : ff){
dirPrint(ft);
}
}
}
}
2. I/O流体系
2.1 流的基本介绍
首先介绍流的分类:
按照流的方向来分,可以分为字节流和字符流。
输入流:只能读取数据。
输出流:只能向其中写入数据。
输入流和输出流都是站在程序的角度进行考虑的。
按照流处理的数据单元不同,可以分为字节流和字符流。
字节流和字符流的用法几乎一致,区别是它们操作的数据单元不同。字节流操作的数据单元是一个字节,字符流操作的数据单元是2个字节。
按照流的角色,可以分为节点流和处理流。
节点流是可以直接向特定的IO设备进行读/写操作的流,这种流也被称为低级流。处理流则用于对一个已存在的流,通过封装后的流来实现数据读/写功能,处理流被称为装饰流或高级流。
java的输入/输出流提供了近40个类,下面按照流的功能进行分类:
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 访问管道 | PipedInptStream | PipedOutoutStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转化流 | InputStreamReader | OutputStreamWriter | ||
| 对象流 | ObjectInputStream | ObjectOutputStream | ||
| 抽象基类 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | |||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
我们已经知道字节流的数据单元是一个字节,字符流的数据单元是两个字节。通常情况下,如果访问的是文本内容,那么应该使用字符流,如果访问的是二进制内容,那么应该使用字节流。
使用字节流访问文本内容,如果一次访问不完,那么很有可能出现乱码的情况。
例如有GBK格式编码的文本文件test.txt,内容如下:
“do not give up.不要放弃。”
这段文本中“do not give up.”一共占据15个字节。“不要放弃。”一共占了10个字节。
如果使用如下的代码来访问:
String path="C:\\Users\\dell\\Desktop\\test.txt";
FileInputStream fis=new FileInputStream(new File(path));
byte[] bytes=new byte[1024];//一次读取1024个字节
int offset=0;
String result="";
while((offset=fis.read(bytes,0,bytes.length))!=-1){
result+=new String(bytes,0,offset);
}
System.out.println(result);
由于上面的文本没有1024个字节,所以可以一次性读完,并不会出现乱码情况。
而如果改为一次读取3个字节,那么就会出现乱码。我们甚至还可以推断出,那些字符会出现乱码,由于读取数据的单位为3个字节,所以前面的“do not give up.”会分为5次读完。后面的汉字“不要放弃。”每个汉字占两个字节,为了方便理解,我们把这10个字节用一下这些字符来表示“12 34 56 78 9A”,第一次读取了三个字节123,12可以被正常解析为“不”,后面有一个字节不能被正常解析。第二此又读取三个字节456,45不能被正常解析,6也不能被正常解析。第三次又读取三个字节789,78可以被正常解析,9不能。最后读取最后一个字节A,A也不能被正常解析。所以最终汉字中只有“不”、“弃”可以被正常解析。
2.2 访问文件
在前面介绍过访问文件主要涉及到FileInputStreaam、FileOutputStream、FileReader、FileWriter,如果是二进制文件,那么使用字节流。如果是文本文件,那么使用字符流。
接下使用FileInputStream、FileOutputStream实现对文件的复制:
public class TestFileCopy {
public static void main(String[] args) {
try{
//1.建立FileInputStream类的对象与源文件建立关联
FileInputStream fis
= new FileInputStream("D:/java09/day16/javaseday16-IO流常用的类-06.wmv");
//2.建立FileOutputStream类的对象与目标文件建立关联
FileOutputStream fos = new FileOutputStream("c:/javaseday16-IO流常用的类-06.wmv");
//3.不断地读取源文件中的内容并写入到目标文件中
/* 可以实现文件的拷贝,但是文件比较大时效率很低
int res = 0;
while((res = fis.read()) != -1){
fos.write(res);
}
*/
//第二种方案,根据源文件的大小准备对应的缓冲区(数组),可能导致内存溢出
//第三种方案,无论文件的大小是多少,每次都准备一个1024整数倍的数组
byte[] data = new byte[1024 * 8];
int res = 0;
while((res = fis.read(data)) != -1){
fos.write(data, 0, res);
}
System.out.println("拷贝文件结束!");
//4.关闭文件输入流对象
fis.close();
//5.关闭文件输出流对象
fos.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestFileCopy.java
2.3 转化流
转化流主要涉及到InputStreamReader和OutputStreamWriter,都是将字节流转化为字符流。
接下来结合输入转化流InputStreamReader和打印流PrintStream进行演示:
public class TestBufferedReaderPrintStream {
public static void main(String[] args) {
try{
//1.创建BufferedReader类型的对象与键盘输入(System.in)进行关联
BufferedReader br = new BufferedReader(
new InputStreamReader(System.in));
//有时候在这里读取网页中的中文的时候,会出现乱码,可以用如下的解决
// BufferedReader br = new BufferedReader(
// new InputStreamReader(new URL("http://www.baidu.com").openStream(),"utf-8"));
//2.创建PrintStream类型的对象与c:/a.txt文件进行关联
PrintStream ps = new PrintStream(new FileOutputStream("d:/a.txt"));
//3.不断地提示用户输入并读取一行本文,并且写入到d:/a.txt中
int flag = 1;
while(true){
System.out.println("请输入要发送的内容:");
//读取用户输入的一行文本
String str = br.readLine();
//4.当用户输入的是"bye"时,则结束循环
if("bye".equalsIgnoreCase(str)) break;
/*
//将发送消息的时间写入到文件中
Date d1 = new Date();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
ps.println(sdf.format(d1));//将时间转化为字符串,写入到文件中
//也可以将一个字符串转化为时间对象
Date d2=new Date();
String str2="2017-05-31 17:51:04";
d2=sdf.parse(str2);//将字符串解析为对应的Date对象
*/
//将str写入到文件中
ps.println(str);
flag++;
}
//5.关闭相关流对象
ps.flush();
ps.close();
br.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestBufferedReaderPrintStream.java
2.4 DataInputStream 和 DataOutputStream
这两流比较特殊,他们可以对基本数据类型进行操作。
DataInputStream测试:
public class TestDataOutputStream {
public static void main(String[] args) {
try{
//1.创建DataOutputStream的对象与参数指定的文件进行关联
DataOutputStream dos = new DataOutputStream(
new FileOutputStream("c:/a.txt"));
//2.将整数数据66写入文件
dos.writeInt(88);
//3.关闭输出流对象
dos.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestDataOutputStream.java
DataOutputStream测试:
public class TestDataInputStream {
public static void main(String[] args) {
try{
//1.创建DataInputStream类的对象与参数指定的文件关联
DataInputStream dis = new DataInputStream(
new FileInputStream("c:/a.txt"));
//2.读取文件中的一个int类型数据并打印出来
int res = dis.readInt();
System.out.println("res = " + res); // 88
//3.关闭流对象
dis.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestDataInputStream.java
2.5 对象流
对象流主要涉及到类是ObjectOutputStream和ObjectInputStream,ObjectOutputStream是用于将一个对象整体写入到输入流中,ObjectInputStream是用于从流中读取一个对象。
ObjectOutputStream测试:
public class TestObjectOutputStream {
public static void main(String[] args) {
try{
//1.创建ObjectOutputStream类的对象与指定的文件关联
ObjectOutputStream oos = new ObjectOutputStream(
new FileOutputStream("c:/user.dat"));
//2.准备User类型的对象并进行初始化
User user = new User("Mark", "123456", "xiaomg@163.com");
//3.将User类型的对象整体写入到文件中
oos.writeObject(user);
System.out.println("写入对象成功!");
//4.关闭输出流对象
oos.flush();
oos.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestObjectOutputStream.java
ObjectInputStream测试
public class TestObjectInputStream {
public static void main(String[] args) {
try{
//1.创建ObjectInputStream类型的对象与指定的文件关联
ObjectInputStream ois = new ObjectInputStream(
new FileInputStream("c:/user.dat"));
//2.读取文件中的一个对象并打印出来
Object obj = ois.readObject();
if(obj instanceof User){
User user = (User)obj;
System.out.println(user);
}
//3.关闭流对象
ois.close();
}catch(Exception e){
e.printStackTrace();
}
}
}
TestObjectInputStream.java
需要注意被writeObject和readObject的对象应该序列化,因为流不能传输对象,所以只能将其状态保存在一组字节进行传输,详情可以查看Java对象序列化。
2.6 推回输入流
在java体系中有两个特殊的流,就是PushbackInputStream和PushbackReader,他们都提供了如下三个方法:
void unread(byte[]/char[] buf):将一个字节/字符数组的内容推回到缓存区里,从而允许重复读取刚刚读取的内容。
void unread(byte[]/char[] buf,int off,int len):将一个字节/字符数组里从off开始,长度为len字节/字符推回到缓冲区里,从而允许重复读取刚刚读取的内容。
void unread(int b): 将一个字节/字符推回到缓存区里,从而允许重复读取刚刚读取的内容。
推回输入流都带有一个推回缓冲区,当程序调用这两个推回输入流的unread()方法时,系统将指定数组的内容推回到缓冲区里,而推回输入流每次调用read方法时总是先推回缓冲区里读取,只有完全读取了推回缓冲区的内容后,但还没有装满read()方法所需的数组时才会从原输入流中读取。

在创建PushbackInputStream和PushbackReader时指定了缓冲区的大小,如果没指定那么默认的缓冲区大小是1,如果程序中推回到缓冲区的内容超过了推回缓冲区的大小,那么将会引发Pushback buffer overflow的IOException异常。
下面的案例是打印“throws”前的32个字节的数据:
public class PushBackStreamTest {
public static void main(String[] args) throws IOException {
try {
// 创建PushbackReader对象,指定推回缓冲区的大小为64
PushbackReader pr = new PushbackReader(new FileReader("PushBackStreamTest.java"), 64);
char[] buf = new char[32];
// 用于保存上次读取到内容
String lastContent = "";
int hasRead = 0;
// 循环读取文件的内容
while ((hasRead = pr.read(buf)) > 0) {
// 将读取的内容转化为字符串
String content = new String(buf, 0, hasRead);
int targetIndex = 0;
if ((targetIndex = (lastContent + content).indexOf("throws")) > 0) {
// 将本次内容和上次内容一起推回缓冲区
pr.unread((lastContent + content).toCharArray());
// 重新定义一个长度为targetIndex的Char数组
if (targetIndex > 32) {
buf = new char[targetIndex];
}
// 再次读取指定长度的内容,也就是throws之前的内容
pr.read(buf, 0, targetIndex);
// 打印
System.out.println(new String(buf, 0, targetIndex));
break;
} else {
lastContent = content;
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
PushBackStreamTest.java
3.重定向标准输入/输出
Java的标准输入/输出是分别通过System.in和System.out来代表的,在默认情况下,它们默认代表键盘和显示器。当程序通过System.in来获取时,实际上是从键盘输入;当程序从System.out输出时,实际上是输出到屏幕。java提供可以调用系统脚本命令的实现。
System类提供了如下三个标准重定向输入/输出的方法
static void setErr(PrintStream) :从定向“标准”错误输出流
static void setIn(InputStream in):从定向“标准”输入流
static void setOut(PrintStream out):从定向“标准”输出流
下面的程序是重定向标准的输出流,将System.out的输出重定向到文件:
import java.io.File;
import java.io.IOException;
import java.io.PrintStream; public class RedirectOut {
public static void main(String[] args) {
PrintStream ps=null;
try{
//创建PrintStream输出流
ps=new PrintStream(new File("out.txt"));
//将标准数据流重定向到ps流
System.setOut(ps);
//向标准输出流输出一个字符串
System.out.println("hello world");
//向标准输出流输出一个对象
System.out.println(new RedirectOut());
}catch(IOException e){
e.printStackTrace();
}finally{
ps.close();
}
}
}
RedirectOut.java
下面的程序是重定向标准的输入流,将System.in的输入重定向到文件:
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.util.Scanner; public class RedirectIn {
public static void main(String[] args) throws IOException {
FileInputStream fis=null;
try{
fis=new FileInputStream(new File("RedirectIn.java"));
//将标准输入流重定向fis输入流
System.setIn(fis);
//使用System.in 创建 Scanner对象,用户获取标准输入
Scanner sc=new Scanner(System.in);
//把回车作为分割符
sc.useDelimiter("\n");
//判断是否还有下一个输入项
while(sc.hasNext()){
//输出输入项
System.out.println(sc.next());
}
}catch(IOException e)
{ }finally{
fis.close();
}
}
}
RedirectIn.java
4.Java虚拟机读写其他进程的数据
使用Runtime对象的exec()方法,可以运行平台上的其他程序,该方法产生一个Process对象,Process对象代表由该Java程序启动的子进程。通过该方法,java提供可以调用系统脚本命令的实现。
exec()方法提供了几个重载版本,如下:
public Process exec(String command)----- 在单独的进程中执行指定的字符串命令。
public Process exec(String [] cmdArray)--- 在单独的进程中执行指定命令和变量
public Process exec(String command, String [] envp)---- 在指定环境的独立进程中执行指定命令和变量
public Process exec(String [] cmdArray, String [] envp)---- 在指定环境的独立进程中执行指定的命令和变量
public Process exec(String command,String[] envp,File dir)---- 在有指定环境和工作目录的独立进程中执行指定的字符串命令
public Process exec(String[] cmdarray,String[] envp,File dir)---- 在指定环境和工作目录的独立进程中执行指定的命令和变量
Process类提供了如下三个进行通信的方法,用于让程序和其他子进程通信:
InputStream getErrorStream():获取子进程的错误流
InputStream getInputStream():获取子进程的输入流
OutputStream getOutputStream():获取子进程的输出流
例如:
1.RunTime.getRuntime().exec(String command);
//在windows下相当于直接调用 /开始/搜索程序和文件 的指令,比如
Runtime.getRuntime().exec("notepad.exe"); //打开windows下记事本。 2.public Process exec(String [] cmdArray);
Runtime.getRuntime().exec(new String[]{"/bin/sh","-c",command);//Linux下
Runtime.getRuntime().exec(new String[]{ "cmd", "/c",command});//Windows下
exec方法的返回值是一个Process类型的数据,通过这个返回值,通过这个返回值就可以获取到命令的执行信息。
Process的其余几种方法:
1.destroy():杀掉子进程
2.exitValue():返回子进程的出口值,值 0 表示正常终止
3.getErrorStream():获取子进程的错误流
4.getInputStream():获取子进程的输入流
5.getOutputStream():获取子进程的输出流
6.waitFor():导致当前线程等待,如有必要,一直要等到由该 Process 对象表示的进程已经终止。如果已终止该子进程,此方法立即返回。如果没有终止该子进程,调用的线程将被阻塞,直到退出子进程,根据惯例,0 表示正常终止
需要注意的是,在java中调用runtime线程执行脚本是非常消耗资源的,所以不要频繁调用。
需要说一说Process的waitFor方法,该方法的作用是等待子线程的结束。
Process p = Runtime.getRuntime().exec("notepad.exe");
p.waitFor();
System.out.println("--------------------------------------------我被执行了");//在手动关闭记事本软件后,才会被打印
需要注意,调用Runtime.getRuntime().exec()后,如果不及时捕捉进程的输出,会导致JAVA挂住,看似被调用进程没退出。所以,解决办法是,启动进程后,再启动两个JAVA线程及时的把被调用进程的输出截获。
class StreamGobbler extends Thread {
InputStream is;
String type;
public StreamGobbler(InputStream is, String type) {
this.is = is;
this.type = type;
}
public void run() {
try {
InputStreamReader isr = new InputStreamReader(is);
BufferedReader br = new BufferedReader(isr);
String line = null;
while ((line = br.readLine()) != null) {
if (type.equals("Error")) {
System.out.println("Error :" + line);
} else {
System.out.println("Debug:" + line);
}
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
}
StreamGobbler.java
调用代码:
try {
Process proc = Runtime.getRuntime().exec("cmd /k start dir");
StreamGobbler errorGobbler = new StreamGobbler(
proc.getErrorStream(), "Error");
StreamGobbler outputGobbler = new StreamGobbler(
proc.getInputStream(), "Output");
errorGobbler.start();
outputGobbler.start();
proc.waitFor();
} catch (Exception e) {
e.printStackTrace();
}
在实际的项目中,我们除了像上面那样调用,还会执行脚本文件。
public static void main(String[] args) {
executeCommand("dir");
}
// 执行一个命令并返回相应的信息
public static void executeCommand(String command) {
try {
// 在项目根目录下将命令生成一份bat文件, 再执行该bat文件
File batFile = new File("dump.bat");
if (!batFile.exists())
batFile.createNewFile();
// 将命令写入文件中
FileWriter writer = new FileWriter(batFile);
writer.write(command);
writer.close();
// 执行该bat文件
Process process = Runtime.getRuntime().exec(
"cmd /c " + batFile.getAbsolutePath());
process.waitFor();
// 将bat文件删除
batFile.delete();
} catch (Exception e) {
e.printStackTrace();
}
}
5 NIO
传统的I/O都是通过流的方式来访问数据的,输入流和输出流都是阻塞式的,比如InputStream,当调用数据的read方法时,若数据源没有数据,那么程序将会阻塞。传统的输入/输出流都是通过字节的移动来处理的(即使不直接处理字节流,但底层的实现还是依赖字节处理),也就是说,面向流的系统一次只能处理一个字节,因此面向流的输入/输出效率通常不高。
从JDK1.4开始,Java提供了一些列用于改进的输入/输出处理的新功能,这些功能被称为新IO(New IO,简称NIO),这些类都放在java.nio包及子包下面。
5.1 NIO简介
NIO和传统IO有相同的目的,都是进行输入/输出,但是新IO使用不同的方式来处理输入/输出,新IO采用内存映射文件的方式来处理输入/输出,新IO将文件或文件的一段区域映射到内存中,这样就可以像访问内存的方式来访问文件了,通过这种方式比传统的IO速度要快许多。
Channel(通道)和Buffer(缓冲)是新IO中的两个核心对象,Channel是对传统的输入/输出系统的模拟,在新IO系统中所有的数据都需要通过通道传输;Channel与传统的InputStream和OutputStream的最大区别就是提供了一个map()方法,通过该map()方法可以直接将“一块数据”映射到内存中。如果说传统的输入/输出系统是面向流的处理,则新IO是面向块的处理。
Buffer可以理解为容器,发送到Channel中的所有对象都必须先放到Buffer中,从Channel中读取到的数据也必须先放到Buffer中。
5.2 Buffer类
Buffer就像一个数组,可以保存多个相同类型的数据。Byte是一个抽象类,其最常用的的之类是ByteBuffer类,它可以在底层数组上执行get/set操作,除此之外,其他基本数据类型都有相应的Buffer类:CharBuffer,ShortBuffer,IntBuffer,LongBuffer,FloatBuffer,DoubleBuffer。
在Buffer中有三个比较重要的概念分别为:容量(capacity)、界限(limit)和位置(position)。
a.容量(capacity):缓冲区的容量表示该Buffer的最大数据容量。该值不可为负,创建后不能修改。
b.界限(limit):第一个不应该被读取或写入缓冲区的位置索引。位于Limit之后的数据,既不可被读,也不可被写。该值不能超过Capacity,或是小于0。
c.位置(position):用于指明下一个可以被读取数据的位置索引。
除此之外,还提供一个可选标记mark,Buffer运行直接将position定位到mark处。
他们之间的关系如下:
0<=mark<=position<=limit<=capacity
下面是读了一些数据的Buffer图: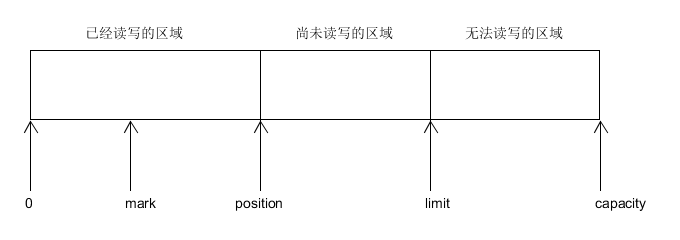
当调用flip()方法,该方法将limit设置为position所在位置,并将position重置为0,这样就是使Buffer的读写指针又移到了开始位置。也就是说,Buffer调用flip()方法之后,Buffer为输出数据做好准备。当调用Buffer的clear()方法时,它将position设置为0,将limit设置为capacity,这样再次为向Buffer重装数据做好准备。
示例:
public class Test {
public static void main(String[] args) {
CharBuffer buff=CharBuffer.allocate(8);
System.out.println("capacity:"+buff.capacity());//
System.out.println("limit:"+buff.limit());//
System.out.println("position:"+buff.position());//
buff.put('a');
buff.put('b');
buff.put('c');
System.out.println("capacity:"+buff.capacity());//
System.out.println("limit:"+buff.limit());//8
System.out.println("position:"+buff.position());//3
//调用flip()方法
buff.flip();
System.out.println("capacity:"+buff.capacity());//
System.out.println("limit:"+buff.limit());//3
System.out.println("position:"+buff.position());//
System.out.println("第一个元素:"+buff.get());//a
System.out.println("position:"+buff.position());//1
//调用clear()后
buff.clear();
System.out.println("capacity:"+buff.capacity());//
System.out.println("limit:"+buff.limit());//8
System.out.println("position:"+buff.position());//0
//取出第二个元素
System.out.println("执行clear()方法后,缓冲区并没有被清除,第三个数据:"+buff.get(1));//b
}
}
上面介绍了Buffer类的使用,下面介绍Channel类。
5.3 Channel类
Channel类似于传统的流对象,但与传统的流对象有两个主要区别:
a.Channel可以直接指定文件的部分或全部数据映射为Buffer
b.程序不能直接访问Channel中的数据,包括读取和写入都不行,Channel只能与Buffer进行交互。
java为Channel接口提供了DatagramChannel、FileChannel、Pipe.SinkChannel、Pipe.SourceChannel、SelectableChannel、ServerSocketChannel、SocketChannel等实现类,顾名思义,可以非常方便的理解这些Channel类。
所有的Channel都不应该通过构造器直接创建,而是通过传统的InputStream、OutputStream方法的getChannel来返回Channel,不同的节点流获得Channel也不一样。
下面的所有案例都是以FileChannel为介绍。
打印一个文件中的所有内容:
public class FileChannelTest {
public static void main(String[] args) {
File fileIn=new File("D:/test1.txt");
FileInputStream fis=null;//文件输入流
FileChannel fisChannel=null;//文件输入通道
try{
fis=new FileInputStream(fileIn);//创建文件输入流
fisChannel=fis.getChannel();//通过FileInputStream获得FileChannel对象
//将fisChannel里的所有的数据映射到buffer中
MappedByteBuffer buffer=fisChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileIn.length());
//使用GBK的字符集来创建解码器
Charset charset=Charset.forName("GBK");
CharBuffer cBuffer= charset.decode(buffer);
System.out.println(cBuffer);//打印
}catch(Exception e)
{
e.printStackTrace();
}finally{
try{
fisChannel.close();
fis.close();
}catch(Exception e)
{
e.printStackTrace();
}
}
}
}
上面的程序是一次性将文件的所有内容都加载到内存中,如果担心文件过大引起性能下降,那么可以分部分来获取。
例如:
File fileIn=new File("D:/test1.txt");
FileInputStream fis=null;//文件输入流
FileChannel fisChannel=null;//文件输入通道
try{
fis=new FileInputStream(fileIn);//创建文件输入流
fisChannel=fis.getChannel();//通过FileInputStream获得FileChannel对象
//设置每次取数据的大小
ByteBuffer bbf=ByteBuffer.allocate(8);
Charset charset=Charset.forName("GBK");
while(fisChannel.read(bbf)>0)
{
//锁定Buffer的空白区
bbf.flip();
CharBuffer cBuffer= charset.decode(bbf);
System.out.println(cBuffer);
//初始化Buffer,为下次取数据做好准备
bbf.clear();
}
}catch(Exception e)
{
e.printStackTrace();
}finally{
try{
fisChannel.close();
fis.close();
}catch(Exception e)
{
e.printStackTrace();
}
}
下面使用FileChanel实现文件的复制功能:
public class FileChannelCopyTest {
public static void main(String[] args) {
File fileIn=new File("D:/test1.txt");
File fileOut=new File("D:/test2.txt");
FileInputStream fis=null;//文件输入流
FileOutputStream fos=null;//文件输出流
FileChannel fisChannel=null;//文件输入通道
FileChannel fosChannel=null;//文件输出通道
try{
fis=new FileInputStream(fileIn);//创建文件输入流
fisChannel=fis.getChannel();//通过FileInputStream获得FileChannel对象、
fos=new FileOutputStream(fileOut);
fosChannel=fos.getChannel();//通过FileOutputStream获得FileChannel对象.
MappedByteBuffer buffer=fisChannel.map(FileChannel.MapMode.READ_ONLY, 0, fileIn.length());
fosChannel.write(buffer,0);
}catch(Exception e)
{
e.printStackTrace();
}finally{
try{
fisChannel.close();
fis.close();
}catch(Exception e)
{
e.printStackTrace();
}
}
}
}
FileChannelCopyTest.java
5.4 文件锁
文件锁在操作系统中是很平常的事情,如果多个运行的程序需要并发地同时修改同一个文件时,程序之间需要某种机制来通信,使用文件锁可以有效地阻止多个进程并发修改同一个文件。
在NIO中,java提供了FileLock来支持文件锁功能,在FileChannel中提供的lock()和tryLock()方法可以获得文件锁FileLock对象。
lock和tryLock方法的区别:
a.当lock试图锁定某个文件时,如果无法获得文件锁,程序将会一直阻塞;
b.tryLock是尝试锁定文件,它将直接返回而不是阻塞,如果获得文件锁,则返回文件锁,否则返回null。
lock和tryLock除了定义了无参方法,还定义了如下格式的方法:
lock(long position,long size,boolean shared):对文件从position开始,长度为size的内容加锁。
tryLock(long position,long size,boolean shared):非阻塞方式加锁,参数的作用与上一个方法类似。
当shared为true时,表明该锁是一个共享锁,它允许多个进程来读取文件,阻止其他进程获得对该文件的排他锁,shared为true只能使用在一个可读的Channel上。
当shared为false时,表明该锁是一个排他锁,它将锁住对该文件的写操作,shared为false只能使用在一个可写的Channel上。
FileLock还提供了一个isShared()方法来判断它获得的锁是否是共享锁。
下面是一个案例:
public class FileLockTest {
public static void main(String[] args) {
try{
File file=new File("D:/test1.txt");
FileChannel fc=new FileInputStream(file).getChannel();
FileLock flock= fc.tryLock();
Thread.sleep(10000);//锁定10秒钟
flock.release();
}catch(Exception e)
{
e.printStackTrace();
}
}
}
【java】详解I/O流的更多相关文章
- Java 详解 JVM 工作原理和流程
Java 详解 JVM 工作原理和流程 作为一名Java使用者,掌握JVM的体系结构也是必须的.说起Java,人们首先想到的是Java编程语言,然而事实上,Java是一种技术,它由四方面组成:Java ...
- 详解 I/O流
I/O流是用于处理设备之前信息传输的流,在我们今后的学习甚至是工作中,都是十分重要的. 在我们的日常生活中,也是很常见的,譬如:文件内容的合并.设备之键的文件传输,甚至是下载软件时的断点续传,都可以用 ...
- 2020你还不会Java8新特性?方法引用详解及Stream 流介绍和操作方式详解(三)
方法引用详解 方法引用: method reference 方法引用实际上是Lambda表达式的一种语法糖 我们可以将方法引用看作是一个「函数指针」,function pointer 方法引用共分为4 ...
- tomcat使用详解(week4_day2)--技术流ken
tomcat简介 Tomcat是Apache软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache.Sun和其他一些公司及个人共同开发 ...
- 逆向工程生成的Mapper.xml以及*Example.java详解
逆向工程生成的接口中的方法详解 在我上一篇的博客中讲解了如何使用Mybayis逆向工程针对单表自动生成mapper.java.mapper.xml.实体类,今天我们先针对mapper.java接口中的 ...
- 详解API Gateway流控实现,揭开ROMA平台高性能秒级流控的技术细节
摘要:ROMA平台的核心系统ROMA Connect源自华为流程IT的集成平台,在华为内部有超过15年的企业业务集成经验. 本文分享自华为云社区<ROMA集成关键技术(1)-API流控技术详解& ...
- 面试题:JavaIO流分类详解与常用流用法实例
Java流概念: Java把所有的有序数据都抽象成流模型,简化了输入输出,理解了流模型就理解了Java IO.可以把流想象成水流,里面的水滴有序的朝某一方向流动.水滴就是数据,且代表着最小的数据流动单 ...
- Java IO详解(二)------流的分类
一.根据流向分为输入流和输出流: 注意输入流和输出流是相对于程序而言的. 输出:把程序(内存)中的内容输出到磁盘.光盘等存储设备中 输入:读取外部数据(磁盘.光盘等存储设备的数据)到程序(内 ...
- Floyd算法(三)之 Java详解
前面分别通过C和C++实现了弗洛伊德算法,本文介绍弗洛伊德算法的Java实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3. 弗洛伊德算法的代码说明 4. 弗洛伊德算法的源码 转载请注明 ...
随机推荐
- Ubuntu通过 lshw 工具包查看物理网卡名称
步骤1:安装相关工具包 apt-get install lshw lshw-gtk 步骤2:执行lshw命令进行查看硬件信息
- CHtmlEditCtrl (3): More HTML Editor Options
In this version of our HTML Editor, we'll create a floating source view/edit window and we'll implem ...
- phpstudy 开启apache反向代理
vhosts.conf 1 2 3 4 5 6 7 8 9 10 11 <VirtualHost *:8080> ServerAdmin webmaster@dummy-host.exam ...
- MyCat - 使用篇
Mycat水平拆分之十种分片规则: http://www.cnblogs.com/756623607-zhang/p/6656022.html 数据库路由中间件MyCat - 使用篇(5) 配置MyC ...
- asp.net使用include包含文件
么?用asp.net使用include包含文件?……有必要吗?使用“用户控件”不是更好吗? 当然,绝大多数情况下,用户控件都能解决问题.但若要在用户控件中需包含其他公用块,即使用用户控件嵌套,老是出问 ...
- 忘记MySQL root密码重置MySQL root密码
(1)停止mysql# /etc/init.d/mysql stop(2)以不检查权限的方式启动# mysqld --skip-grant-tables &(3)登录mysql修改root用户 ...
- JERSEY中文翻译(第三章、模块和依赖)
Chapter 2 Modules and Dependencencies 2.1 Java SE 兼容 所有的Jersey组建都是基于Java6开发的,所以你的Java必须是Java6以上的版本才能 ...
- python获取自己的环境变量
1. import sys sys.path 2. from distutils.sysconfig import get_python_lib get_python_lib() 3. import ...
- MongoDB numa系列问题一:[initandlisten] connection refused because too many open connections:
1:Mongod日志有很多这样的报错: [initandlisten] connection refused because too many open connections: 2:查看系统的限制 ...
- Solidworks 2016中导出URDF文件
安装SolidWorks to URDF exporter插件 下载SolidWorks to URDF Exporter插件后按照网站上的步骤进行安装(目前该插件已经在Win 7 64位系统+Sol ...