SQL Server 调优系列进阶篇 - 查询优化器的运行方式
前言
前面我们的几篇文章介绍了一系列关于运算符的基础介绍,以及各个运算符的优化方式和技巧。其中涵盖:查看执行计划的方式、几种数据集常用的连接方式、联合运算符方式、并行运算符等一系列的我们常见的运算符。有兴趣的童鞋可以点击查看。
本篇介绍在SQL Server中查询优化器的工作方式,也就是一个好的执行计划的形成,是如何评估出来的,作为该系列的进阶篇。
废话少说,开始本篇的正题。
技术准备
数据库版本为SQL Server2008R2,利用微软的一个更简洁的案例库(Northwind)进行分析。
正文内容
在我们将写好的一个T-SQL语句抛给SQL Server准备执行的时候,首选要经历的过程就是编译过程,当然如果此语句以前在SQL Server中执行过,那么将检测是否存在已经缓存的编译过的执行计划,用以重用。
但是,执行编译的过程需要执行一系列的优化过程,关于优化过程大致分为两个阶段:
1、首先,SQL Server对我们写的T-SQL语句先执行一些简化,通常由查询本身来寻找交互性及重新安排操作的顺序。
在此过程中,SQL Server侧重于语句写法调整,而不过多的考虑成本或者分析索引可用性的等,最重要的目标就是产生一个有效的查询。
然后,SQL Server才会加载元数据,包括索引的统计信息,进入第二个阶段。
2、在这个阶段才是SQL Server一个复杂的优化过程,这个阶段SQL Server会根据上一阶段形成的执行计划运算符进行评估和尝试,甚至于重组执行计划,所以相对这个优化过程是一个耗时的过程。
通过如下流程图,来理解该过程:

这个图看上去有点复杂,我们来详细分析下,其实就是将这个优化阶段分为3个子阶段
<1>这个阶段仅考虑串行计划,也就说单处理器运行,如果这个阶段找到了一个好的串行计划,优化器就不会进入下一阶段。所以对于数据量少的情况,或者执行语句简单的情况下,基本采用的都是串行计划。
当然,如果这个阶段开销比较大,那么会进入到第2个阶段,再进行优化。
<2>这个阶段首先对第1阶段的串行计划进行优化,然后如果环境支持并行化操作,则进行并行化操作,通过进行比较,然后进行优化后的成本如果比较低则输出执行计划,如果成本还是比较高,则进入第2阶段,再继续优化。
<3>其实到达这个阶段就是优化的最后一个阶段了,这个阶段会对第2个阶段中采用串行和并行的比较结果进行最后一步优化,如果串行执行好那就进一步优化,当然如果并行执行好的话,则再继续并行优化。
其实第3阶段是查询优化器的无奈之举,当到达第3阶段了就是一个补救阶段,只能最后做优化了,优化完好不好的就只能按照这个执行计划执行了。
那么上述过程中,各个阶段的优化的原则有哪些:
关于这些优化器的最重要原则的就是:尽可能的减少扫描范围,不管是表或者索引,当然走索引比表好,索引的量也是越少越好,最理想的情况是只有一条或者几条。
所以,SQL Server也尊重上述原则,一直围绕着这个原则去优化。
一、筛选条件分析
所谓的筛选条件,其实就是我们所写的T-SQL语句中的WHERE语句后面的条件,我们会通过这里面的语句进行尽量缩小数据扫描范围,SQL Server通过这些语句来优化。
一般格式如下:
column operator <constant or variable>
或者
<constant or variable> operator column
而这上面格式中operator包括:=、>、<、=>、<=、BETWEEN、LIKE
比如:name='liudehua'、price>4000、4000<price、name like 'liu%'、name='liudehua' AND price >1000
上面这些语句是我们写的语句中最常用的方式,并且这种方式也将被SQL Server用来减少扫描,并且这些列被索引覆盖,那将尽量采取索引进行获取值,但是SQL Server也不是万能的,有些写法它也是不能识别的,也是我们写语句要避免的:
a、where name like '%liu'这货就不能被SQL Server优化器识别,所以它只能通过全表扫描或者索引扫描执行。
b、name='liudehua' OR price >1000,这个同样也是失效的,因为它不能利用两个的筛选条件进行逐步减少扫描。
c、price+4>100这个同样不被识别
d、name not in ('liudehua'、‘zhourunfa’),当然还有类似的:NOT 、NOT LIKE
举个列子:
SELECT CustomerID FROM Orders
WHERE CustomerID='Vinet' SELECT CustomerID FROM Orders
WHERE UPPER(CustomerID)='VINET'
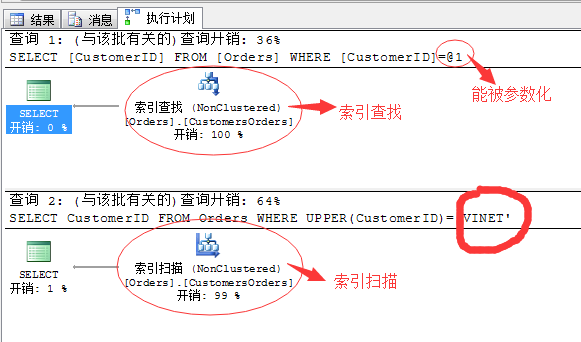
所以上述的方式写语句的时候需要尽量避免,或者采取变通的方式实现。
二、索引优化
经过上面的筛选范围的确定之后,SQL Server紧接着开始索引的选择,首先要确定的第一件事就是筛选字段是否存在索引项,也就是说是否被索引覆盖。
当然,如果查询项为索引覆盖最好,如果不被索引覆盖,那么为了充分利用索引的特性,就引入了书签查找(bookmark)部分。
所以,鉴于此,我们在创建索引的时候,所参考的属性值就为筛选条件的列了。
关于利用索引优化的选择:

CREATE INDEX EmployeesName ON Employees(FirstName,LastName)
INCLUDE(HIREDATE) WITH(ONLINE=ON)
GO SELECT FirstName,LastName,HireDate,EmployeeID
FROM Employees
WHERE FirstName='Anne'

当然也不尽然只要查询列存在索引覆盖就执行索引查找,这取决于扫描的内容的多少,所以对于索引的利用程度还取决获取内容的多少
来举个例子:
CREATE INDEX NameIndex ON person.contact(FirstName,LastName)
GO SELECT * FROM Person.Contact
WHERE FirstName LIKE 'K%' SELECT * FROM Person.Contact
WHERE FirstName LIKE 'Y%'
GO
完全相同的查询语句,来看执行计划:
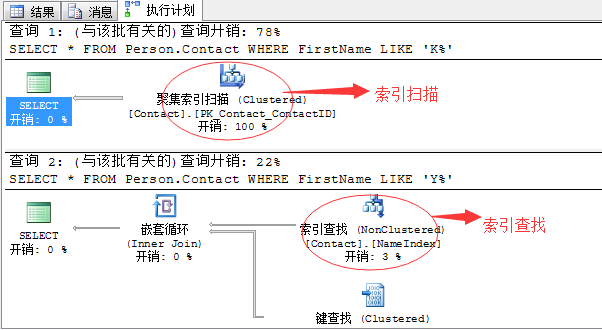
完全相同的查询语句,产生的查询计划完全不同,一个是索引扫描,一个则是高效的索引查找。
这里我只告诉你:FirstName like 'K%'的有1255行;而FirstName like 'Y%'只有37行,其中
其实,关于这里的原因就是统计信息在作怪了。
所以,特定的T-SQL语句不一定生成特定的查询计划,同样特定的查询计划不一定是最优的方式,影响的它的因素很多:关于索引、关于硬件、关于表内容、关于统计信息等诸多因素影响。
关于统计信息这块是大篇幅内容,我们放在以后的篇幅中介绍,有兴趣的可以提前关注。
SQL Server 调优系列进阶篇 - 查询优化器的运行方式的更多相关文章
- SQL Server调优系列进阶篇 - 查询优化器的运行方式
前言 前面我们的几篇文章介绍了一系列关于运算符的基础介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符. ...
- SQL Server调优系列进阶篇(查询语句运行几个指标值监测)
前言 上一篇我们分析了查询优化器的工作方式,其中包括:查询优化器的详细运行步骤.筛选条件分析.索引项优化等信息. 本篇我们分析在我们运行的过程中几个关键指标值的检测. 通过这些指标值来分析语句的运行问 ...
- SQL Server调优系列进阶篇(深入剖析统计信息)
前言 经过前几篇的分析,其实大体已经初窥到SQL Server统计信息的重要性了,所以本篇就要祭出这个神器了. 该篇内容会很长,坐好板凳,瓜子零食之类... 不废话,进正题 技术准备 数据库版本为SQ ...
- SQL Server调优系列进阶篇(如何索引调优)
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL Server调优系列进阶篇(如何维护数据库索引)
前言 上一篇我们研究了如何利用索引在数据库里面调优,简要的介绍了索引的原理,更重要的分析了如何选择索引以及索引的利弊项,有兴趣的可以点击查看. 本篇延续上一篇的内容,继续分析索引这块,侧重索引项的日常 ...
- SQL Server调优系列进阶篇(查询优化器的运行方式)
前言 前面我们的几篇文章介绍了一系列关于运算符的基础介绍,以及各个运算符的优化方式和技巧.其中涵盖:查看执行计划的方式.几种数据集常用的连接方式.联合运算符方式.并行运算符等一系列的我们常见的运算符. ...
- SQL Server调优系列进阶篇 - 如何索引调优
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL Server 调优系列进阶篇 - 如何索引调优
前言 上一篇我们分析了数据库中的统计信息的作用,我们已经了解了数据库如何通过统计信息来掌控数据库中各个表的内容分布.不清楚的童鞋可以点击参考. 作为调优系列的文章,数据库的索引肯定是不能少的了,所以本 ...
- SQL Server调优系列进阶篇 - 深入剖析统计信息
前言 经过前几篇的分析,其实大体已经初窥到SQL Server统计信息的重要性了,所以本篇就要祭出这个神器了. 该篇内容会很长,坐好板凳,瓜子零食之类... 不废话,进正题 技术准备 数据库版本为SQ ...
随机推荐
- CAN通信(STM32)
1.CAN是控制器局域网络(Controller Area Network, CAN)的简称 (理论知识不做讲解了,太多了) 2.芯片选用:TJA1050 差分信号输入, 这里的显性电平CANH和CA ...
- 使用PopupWindow弹窗提醒
一.新建view.xml 注意里面的控件要一个一个的定义离上一个控件的距离,即margin_top,不然最后的效果是紧缩的 二.在java中定义两个变量 1.View view=null: 2.pop ...
- HDU3085(双向BFS+曼哈顿距离)题解
Nightmare Ⅱ Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others) Tota ...
- springBoot 打包 dubbo jar包
参看链接:http://blog.csdn.net/cqdz_dj/article/details/51942681 http://blog.csdn.net/u014695188/art ...
- C#下载歌词文件
前段时间写了一篇c#解析Lrc歌词文件,对lrc文件进行解析,支持多个时间段合并.本文借下载歌词文件来探讨一下同步和异步方法. Lrc文件在网络上随处可见,我们可以通过一些方法获取,最简单的就是别人的 ...
- IIS Express 配置json minitype
IIS Express 配置json minitype 1.在命令窗口中cd到IIS Express安装目录,默认是“C:\Program Files\IIS Express”: 2.在IIS Exp ...
- R语言低级绘图函数-abline 转载
abline 函数的作用是在一张图表上添加直线, 可以是一条斜线,通过x或y轴的交点和斜率来确定位置:也可以是一条水平或者垂直的线,只需要指定与x轴或y轴交点的位置就可以了 常见用法: 1)添加直线 ...
- Codeforces 38B - Chess
38B - Chess 思路:懂点象棋的规则就可以,看看哪些点可以放马. 代码: #include<bits/stdc++.h> using namespace std; #define ...
- C#判断一个字符串是否全部为空格的一个简单方法
string nickName = " "; if (nickName.Trim() == string.Empty) { } else { }
- aria2c --enable-rpc --rpc-listen-all -D
在后台启动的方法,如题, 用来配合 web-aria2