springbatch---->springbatch的使用(二)
这里我们对springbatch做一个比较深入的学习例子,解压文件,读取文件内容过滤写入到数据库中。如果你掉进了黑暗里,你能做的,不过是静心等待,直到你的双眼适应黑暗。
springbatch的使用案例
首先,我们来列举一下spring batch里面所涉及到的概念。
1、Job repository
An infrastructure component that persists job execution metadata
2、Job launcher
An infrastructure component that starts job executions
3、Job
An application component that represents a batch process
4、Step
A phase in a job; a job is a sequence of steps
5、Tasklet
A transactional, potentially repeatable process occurring in a step
6、Item
A record read from or written to a data source
7、Chunk
A list of items of a given size
8、Item reader
A component responsible for reading items from a data source
9、Item processor
A component responsible for processing (transforming, validating, or filtering) a read item before it’s written
10、Item writer
A component responsible for writing a chunk to a data source
我们的项目是基于上篇博客的,具体的可以参考博客:springbatch---->springbatch的使用(一)。流程:将得到的zip文件解压成txt文件,根据里面的信息。我们过滤到年龄大于30的数据,并把过滤后的数据按格式存放到数据库中。以下我们只列出新增或者修改的文件内容。
一、关于xml文件的修改,增加一个job.xml文件和修改batch.xml文件
- batch.xml文件增加内容:
<!-- 读取文件写入到数据库的job -->
<job id="readFlatFileJob">
<step id="decompress" next="readWriter">
<tasklet ref="decompressTasklet"/>
</step>
<step id="readWriter" next="clean">
<tasklet>
<chunk reader="reader" writer="writer" commit-interval="100" processor="processor"/>
</tasklet>
</step>
<step id="clean">
<tasklet ref="cleanTasklet"/>
</step>
</job>
关于commit-interval:Number of items to process before issuing a commit. When the number of items read reaches the commit interval number, the entire corresponding chunk is written out through the item writer and the transaction is committed.
- 新增的job.xml文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd"> <!-- 对压缩文件进行解压 -->
<bean id="decompressTasklet" class="spring.batch.readFile.DecompressTasklet">
<property name="inputResource" value="file:file/file.zip"/>
<property name="targetDirectory" value="file"/>
<property name="targetFile" value="file.txt"/>
</bean> <!-- 读取文本文件 -->
<bean id="reader" class="org.springframework.batch.item.file.FlatFileItemReader">
<property name="lineMapper" ref="lineMapper"/>
<property name="linesToSkip" value="1"/> <!-- 跳过第一行,也就是从第二行开始读 -->
<property name="resource" value="file:file/file.txt"/>
</bean> <!-- 对读取的内容做过滤处理 -->
<bean id="processor" class="spring.batch.readFile.FileProcessor"/> <!-- 将读取的内容写到数据库中 -->
<bean id="writer" class="spring.batch.readFile.FileWriter">
<constructor-arg ref="dataSource"/>
</bean> <!-- 清除压缩文件-->
<bean id="cleanTasklet" class="spring.batch.readFile.FileCleanTasklet">
<property name="resource" value="file:file/file.zip"/>
</bean> <!-- 对文件里面的数据进行|分割,映射成一个类 -->
<bean id="lineMapper" class="org.springframework.batch.item.file.mapping.DefaultLineMapper">
<property name="lineTokenizer" ref="delimitedLineTokenizer"/>
<property name="fieldSetMapper">
<bean class="spring.batch.readFile.ReadFileMapper"/>
</property>
</bean>
<bean id="delimitedLineTokenizer" class="org.springframework.batch.item.file.transform.DelimitedLineTokenizer">
<constructor-arg name="delimiter" value="|"/>
</bean> <!-- 简单的数据源配置 -->
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://127.0.0.1:3306/csiilearn"/>
<property name="username" value="root"/>
<property name="password" value="*****"/>
</bean>
</beans>
其实关于有格式的文件的读写,springbatch为我们提供了FlatFileItemWriter和FlatFileItemReader类。我们可以直接使用,只需要配置它的属性就行。
二、新增加的java类,如下所示
- DecompressTasklet:对zip文件进行解压
package spring.batch.readFile; import org.apache.commons.io.FileUtils;
import org.apache.commons.io.IOUtils;
import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.core.io.Resource; import java.io.BufferedInputStream;
import java.io.BufferedOutputStream;
import java.io.File;
import java.io.FileOutputStream;
import java.util.zip.ZipInputStream; /**
* @Author: huhx
* @Date: 2017-11-01 上午 9:39
*/
public class DecompressTasklet implements Tasklet {
private Resource inputResource;
private String targetDirectory;
private String targetFile; @Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
System.out.println("file path: " + inputResource.getFile().getAbsolutePath());
ZipInputStream zis = new ZipInputStream(
new BufferedInputStream(
inputResource.getInputStream()));
File targetDirectoryAsFile = new File(targetDirectory);
if (!targetDirectoryAsFile.exists()) {
FileUtils.forceMkdir(targetDirectoryAsFile);
}
File target = new File(targetDirectory, targetFile);
BufferedOutputStream dest = null;
while (zis.getNextEntry() != null) {
if (!target.exists()) {
target.createNewFile();
}
FileOutputStream fos = new FileOutputStream(target);
dest = new BufferedOutputStream(fos);
IOUtils.copy(zis, dest);
dest.flush();
dest.close();
}
zis.close();
if (!target.exists()) {
throw new IllegalStateException("Could not decompress anything from the archive!");
}
return RepeatStatus.FINISHED;
} public void setInputResource(Resource inputResource) {
this.inputResource = inputResource;
} public void setTargetDirectory(String targetDirectory) {
this.targetDirectory = targetDirectory;
} public void setTargetFile(String targetFile) {
this.targetFile = targetFile;
}
}
- People:数据库映射的javaBean类
public class People implements Serializable {
private String username;
private int age;
private String address;
private Date birthday;
..get...set...
}
- ReadFileMapper:读取文件字段的映射
package spring.batch.readFile; import org.springframework.batch.item.file.mapping.FieldSetMapper;
import org.springframework.batch.item.file.transform.FieldSet;
import org.springframework.validation.BindException; /**
* @Author: huhx
* @Date: 2017-11-01 上午 10:11
*/
public class ReadFileMapper implements FieldSetMapper<People> { @Override
public People mapFieldSet(FieldSet fieldSet) throws BindException {
People people = new People();
people.setUsername(fieldSet.readString(0));
people.setAge(fieldSet.readInt(1));
people.setAddress(fieldSet.readString(2));
people.setBirthday(fieldSet.readDate(3));
return people;
}
}
- FileProcessor:对读取的数据做进一步的处理,这里我们是过滤操作
package spring.batch.readFile; import org.springframework.batch.item.ItemProcessor; /**
* @Author: huhx
* @Date: 2017-11-01 上午 9:43
*/
public class FileProcessor implements ItemProcessor<People, People> {
@Override
public People process(People item) throws Exception {
return needsToBeFiltered(item) ? null : item;
} private boolean needsToBeFiltered(People item) {
int age = item.getAge();
return age > 30 ? true : false;
}
}
- FileWriter:对最终过滤后的数据写入数据库中
package spring.batch.readFile; import org.springframework.batch.item.ItemWriter;
import org.springframework.jdbc.core.JdbcTemplate; import javax.sql.DataSource;
import java.util.List; /**
* @Author: huhx
* @Date: 2017-11-01 上午 9:42
*/
public class FileWriter implements ItemWriter<People> {
private static final String INSERT_PRODUCT = "INSERT INTO batch_user (user_name, age, address, birthday) VALUES(?, ?, ?, ?)"; private JdbcTemplate jdbcTemplate; public FileWriter(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
} @Override
public void write(List<? extends People> items) throws Exception {
for (People people : items) {
jdbcTemplate.update(INSERT_PRODUCT, people.getUsername(), people.getAge(), people.getAddress(), people.getBirthday());
}
}
}
- FileCleanTasklet:做流程最后的清理处理,删除zip文件
package spring.batch.readFile; import org.springframework.batch.core.StepContribution;
import org.springframework.batch.core.scope.context.ChunkContext;
import org.springframework.batch.core.step.tasklet.Tasklet;
import org.springframework.batch.repeat.RepeatStatus;
import org.springframework.core.io.Resource; import java.io.File; /**
* @Author: huhx
* @Date: 2017-11-01 上午 9:44
*/
public class FileCleanTasklet implements Tasklet {
private Resource resource; public void setResource(Resource resource) {
this.resource = resource;
} @Override
public RepeatStatus execute(StepContribution contribution, ChunkContext chunkContext) throws Exception {
File file = resource.getFile();
file.deleteOnExit();
return RepeatStatus.FINISHED;
}
}
三、修改JobLaunch.java文件里面的内容
Job job = (Job) context.getBean("readFlatFileJob");
- zip解压后的文件内容:
姓名|年龄|地址|生日
李元芳||黄冈|--
王昭君||武汉|--
狄仁杰||天津|--
孙悟空||黄冈|--
牛魔王||武汉|--
孙尚香||天津|--
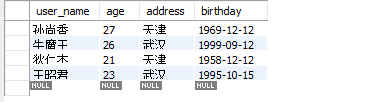
- 运行后的数据库batch_user表的数据:
友情链接
springbatch---->springbatch的使用(二)的更多相关文章
- SpringBatch Sample (二)(CSV文件操作)
本文将通过一个完整的实例,与大家一起讨论运用Spring Batch对CSV文件的读写操作.此实例的流程是:读取一个含有四个字段的CSV文件(ID,Name,Age,Score),对读取的字段做简单的 ...
- YII内置验证规则
required: 必填字段验证, 来自 CRequiredValidator类的别名 array(‘字段名列表用逗号隔开’, ‘required’), 就这样的一个小小的写法,可以让字段前面加 ...
- Spring Batch介绍
简介 SpringBatch 是一个大数据量的并行处理框架.通常用于数据的离线迁移,和数据处理,⽀持事务.并发.流程.监控.纵向和横向扩展,提供统⼀的接⼝管理和任务管理;SpringBatch是Spr ...
- springbatch操作CSV文件
一.需求分析 使用Spring Batch对CSV文件进行读写操作: 读取一个含有四个字段的CSV文件(id, name, age, score), 对文件做简单的处理, 然后输出到还有一个csv文件 ...
- SpringBatch的初步了解
一.SpringBatch是一个批处理的框架,作为一个Spring组件,提供了通过使用Spring的依赖注入来处理批处理的条件. 什么是批处理呢? 在现代企业应用当中,面对复杂的业务以及海量的数据,除 ...
- springbatch操作DB
一.需求分析 使用Spring Batch对DB进行读写操作: 从一个表中读取数据, 然后批量的插入另外一张表中. 二.代码实现 1. 代码结构图: 2. applicationContext.xml ...
- SpringBoot整合SpringBatch
一.引入依赖 pom.xml <?xml version="1.0" encoding="UTF-8"?> <project xmlns=&q ...
- SpringBatch的核心组件JobLauncher和JobRepository
Spring Batch的框架包括启动批处理作业的组件和存储Job执行产生的元数据.因此只需掌握配置这个基础框架在批处理应用程序中即启动Jobs并存储Job元数据. 组件:Job Launcher和J ...
- SpringBatch简介
spring Batch是一个轻量级的.完善的批处理框架,旨在帮助企业建立健壮.高效的批处理应用.SpringBatch是Spring的一个子项目,使用Java语言并基于Spring框架为基础开发,使 ...
- spring-boot-oracle spring-batch
Install/Configure Oracle express Oracle xe installer for linux (I don't care if you're running linux ...
随机推荐
- 目标检测之rcnn---开启检测新高度优于dpm
http://www.cnblogs.com/louyihang-loves-baiyan/p/4839869.html http://www.cnblogs.com/louyihang-loves- ...
- EF学习和使用综合
一.(引)你必须知道的EF知识和经验 二.(引)EF学习和使用(七)EF性能优化篇 三.(引)采用EntityFramework.Extended 对EF进行扩展(Entity Framework 延 ...
- Linq中string转int的方法
Linq中string转int的方法 在做批量删除时,需把一串id值所对应的数据删除,调试出现问题: Linq语句中如果使用ToString()进行类型转换,编译时不会报错,但执行时会出现如下错误 ...
- u3d外部资源 打包与加载的问题
被坑了一下午,调bug,u3d外部加载资源一会可以,一会不行,始终找不到问题,最后快下班的时候,重新试了一下,原来是资源打包之前的文件名,和之后的加载资源名必须一样 [MenuItem("C ...
- 消息中间件activemq-5.13.0整合spring
首先说明这里是在qctivemq配置好并启动服务的情况下进行,请先自行配置好.也可关注我的博文(消息中间件qctivemq安全验证配置)进行配置. 1.首先看一下项目结构 2.所需jar包,这里只列出 ...
- Ruby gem: Mac 系统下的安装与更新
官方链接:https://rubygems.org/pages/download#formats 下载安装: 1.点击上面链接进入到官网,从顶部的链接下载压缩包: 2.解压缩到指定文件夹,并通过 “c ...
- PHP和Apache结合 Apache默认虚拟主机
- LR进行接口测试
其实无论用那种测试方法,接口测试的原理是通过测试程序模拟客户端向服务器发送请求报文,服务器接收请求报文后对相应的报文做出处理然后再把应答报文发送给客户端,客户端接收应答报文这一个过程. 方法一.用Lo ...
- ubuntu:如何制作类似jeso的系统?
chroot 下载ubuntu的core包或base包 chroo后,先安装grub,再kernel,基本就ok了! 提示:mount --bind /proc newroot/proc 可能的问题 ...
- QT中C++与Html端通信例子
C++(服务端)和HTML(客户端)通过websocket通信,通过qwebchannel.js实现 C++ -> HTML,通过信号. HTML -> C++,直接调用函数. Main函 ...