java爬虫入门--用jsoup爬取汽车之家的新闻
概述
详细
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
jsoup的主要功能如下:
1. 从一个URL,文件或字符串中解析HTML;
2. 使用DOM或CSS选择器来查找、取出数据;
3. 可操作HTML元素、属性、文本;
jsoup是基于MIT协议发布的,可放心使用于商业项目
第一步:项目预览
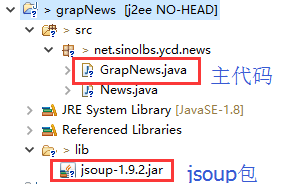
第二步:代码实现
主程序为GrapNews类,实现了从汽车网摘取相关内容的功能。GrapNews有main函数,执行即可。
package net.sinolbs.ycd.news; import java.net.URLEncoder;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern; import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements; /**
* TODO
* 2017年5月21日上午12:25:30
*/
public class GrapNews { public static boolean isContainChinese(String str) {
Pattern p = Pattern.compile("[\u4e00-\u9fa5]");
Matcher m = p.matcher(str);
if (m.find()) {
return true;
}
return false;
} /**
* 从笑话集抓取笑话
* @param size
* @param baseUrl
* @param domainName
* @param newsListClassOrId
* @param classOrId
* @param newsULIndex
* @param newsContentClassOrId
* @param titleTagOrClass
* @param dateTag
* @return
*/
public static ArrayList<News> getNewsFromJokeji(int size,String baseUrl,String domainName,
String newsListClassOrId,int newsULIndex,
String newsContentClassOrId,String titleTagOrClass,String dateTag){
ArrayList<News> newsList = new ArrayList<News>();
Document doc;
Element element =null;
Element title =null;
News news = null;
try {
doc = Jsoup.connect(baseUrl).timeout(10000).get();
element = (Element) doc.getElementsByClass(newsListClassOrId).first();
Elements elements = element.getElementsByTag("li");
if(elements!=null&&elements.size()>0){
for(Element ele:elements){
news = new News();
title = ele.select("a").first();
if(title==null){
continue;
}
news.setTitle(title.getElementsByTag(titleTagOrClass).text());
if(news.getTitle()==null||news.getTitle().equals("")){
continue;
}
news.setHref(domainName+title.attr("href"));
if(dateTag!=null){
String date=ele.select("i").text();
news.setDate(date);
}
String newsUrl =news.getHref();
if (isContainChinese(news.getHref())) {
newsUrl = URLEncoder.encode(news.getHref(), "utf-8")
.toLowerCase().replace("%3a", ":").replace("%2f", "/");
}
Document newsDoc = Jsoup.connect(newsUrl).timeout(10000).get();
String text=newsDoc.getElementById(newsContentClassOrId).html();
text=deleteImg(text);
text=deleteA(text);
StringBuffer textBuffer=new StringBuffer(5);
textBuffer.append("<!DOCTYPE html><html><head><meta name=\"content-type\" content=\"text/html; charset=UTF-8\">");
textBuffer.append("</head><body>");
textBuffer.append(deleteSource(text));
textBuffer.append("</body></html>");
news.setContent(textBuffer.toString());
news.setContent(textBuffer.toString());
System.out.println("标题====="+news.getTitle());
System.out.println("href====="+news.getHref());
System.out.println("content====="+news.getContent());
newsList.add(news);
if(newsList.size()==size){
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return newsList;
} /**
* 从汽车之家抓新闻
* @param size
* @param baseUrl
* @param domainName
* @param newsListId
* @param newsContentClass
* @param titleTagOrClass
* @param limitHref
* @param dateTag
* @param needDeleteAlt
* @return
*/
public static ArrayList<News> getNewsFromCarHome(int size,String baseUrl,String domainName,String newsListId,
String newsContentClass,String titleTag,String dateTag,String needDeleteAlt){
ArrayList<News> newsList = new ArrayList<News>();
Document doc;
Elements elements =null;
Element title =null;
News news = null;
try {
doc = Jsoup.connect(baseUrl).timeout(10000).get();
elements = (Elements) doc.getElementById(newsListId).children();
if(elements!=null&&elements.size()>0){
for(Element ele:elements){
news = new News();
title = ele.select("a").first();
if(title==null){
continue;
}
news.setTitle(title.getElementsByTag(titleTag).text());
if(news.getTitle()==null||news.getTitle().equals("")){
continue;
}
news.setHref(domainName+title.attr("href"));
if(dateTag!=null){
String date=ele.select("i").text();
news.setDate(date);
}
String newsUrl =news.getHref();
if (isContainChinese(news.getHref())) {
newsUrl = URLEncoder.encode(news.getHref(), "utf-8")
.toLowerCase().replace("%3a", ":").replace("%2f", "/");
}
Document newsDoc = Jsoup.connect(newsUrl).timeout(10000).get();
String text=newsDoc.getElementsByClass(newsContentClass).html();
if(text.indexOf("余下全文")>0||text.indexOf("未经许可")>0
||text.indexOf("禁止转载")>0||text.indexOf("公众号")>0||text.indexOf("公众账号")>0){
continue;
}
text=replaceImgSrcFromDataSrc(text,true,needDeleteAlt);
int index=text.lastIndexOf("(");
if(index>0){
text=text.substring(0,index);
}
StringBuffer textBuffer=new StringBuffer(5);
textBuffer.append("<!DOCTYPE html><html><head><meta name=\"content-type\" content=\"text/html; charset=UTF-8\">");
textBuffer.append("</head><body>");
textBuffer.append(deleteSource(text));
textBuffer.append("</body></html>");
news.setContent(textBuffer.toString());
news.setContent(textBuffer.toString());
System.out.println("标题====="+news.getTitle());
System.out.println("href====="+news.getHref());
System.out.println("content====="+news.getContent());
newsList.add(news);
if(newsList.size()==size){
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return newsList;
} public static String getVideoFromMiaoPai(String baseUrl) throws Exception{
Document doc= Jsoup.connect(baseUrl).timeout(10000).get();
String html=doc.html().trim();
return getUrlFromMiaoPaiHtml(html);
} public static String getUrlFromMiaoPaiHtml(String html){
int startIndex=html.indexOf("videoSrc");
int endIndex=html.indexOf("poster");
String videoUrl=html.substring(startIndex+11,endIndex+5);
int index=videoUrl.indexOf('"');
if(index>0){
return videoUrl.substring(0, index);
}
return videoUrl;
} public static String getVideoPhotoFromMiaoPaiHtml(String html){
System.out.println(html);
int startIndex=html.indexOf("poster");
int index=html.substring(startIndex).indexOf("jpg");
return html.substring(startIndex+9,startIndex+index+3);
} public static void main(String[] args) throws Exception{
getNewsFromCarHome(2,"http://m.autohome.com.cn/channel","http://m.autohome.com.cn","list","details","h4","time","汽车之家");
getNewsFromJokeji(3,"http://www.jokeji.cn/list.htm","http://www.jokeji.cn","list_title",1,"text110","a","i");
getNewsFromSouHu(20,"http://m.sohu.com/c/1592/","a",null,null);
}
/**
* 从秒拍抓视频
* @param size
* @param baseUrl
* @param domainName
* @param newsListId
* @param newsContentClass
* @param titleTagOrClass
* @param limitHref
* @param dateTag
* @param needDeleteAlt
* @return
*/
public static ArrayList<News> getVideoFromMiaopai(int size,String baseUrl){
ArrayList<News> newsList = new ArrayList<News>();
try {
News news = null;
Element videoEmement=null;
Document doc = null;
String videoUrl=null;
doc = Jsoup.connect(baseUrl).timeout(10000).get();
Elements elements = doc.getElementsByClass("videoCont");
String videoDetailUrl="";
if(elements!=null&&elements.size()>0){
for(Element ele:elements){
videoEmement=ele.getElementsByClass("MIAOPAI_player").first();
String videoId=videoEmement.attr("data-scid").toString();
String videoPhotoUrl=videoEmement.attr("data-img").toString();
String videoTitle=ele.getElementsByClass("viedoAbout").first().getElementsByTag("p").text();
System.out.println("视频id"+videoId);
System.out.println("视频封面url"+videoPhotoUrl);
System.out.println("视频标题"+videoTitle);
news = new News();
if(videoId!=null){
news.setTitle(videoTitle);
videoDetailUrl="http://www.miaopai.com/show/"+videoId+".html";
doc = Jsoup.connect("http://www.miaopai.com/show/"+videoId+".html").timeout(10000).get();
System.out.println("视频详情url========"+videoDetailUrl);
news.setHref("http://m.miaopai.com/show/"+videoId);
news.setPhotoUrl(videoPhotoUrl);
}
if(doc!=null){
videoUrl=getUrlFromMiaoPaiHtml(doc.html());
}
if(videoUrl!=null){
news.setContent(createVideoHtml(videoUrl, videoPhotoUrl));
System.out.println("视频url====="+videoUrl);
System.out.println("视频html======"+news.getContent());
newsList.add(news);
} }
}
} catch (Exception e) {
e.printStackTrace();
}
return newsList;
} public static String createVideoHtml(String videoUrl,String videoPhotoUrl) {
Document doc;
StringBuffer textBuffer = new StringBuffer(5);
textBuffer.append("<!DOCTYPE html><html><head><meta name=\"content-type\" content=\"text/html; charset=UTF-8\">");
textBuffer.append("</head><body>");
textBuffer.append("<div align=\"center\">");
textBuffer.append(" <video></video> </div>");
textBuffer.append("</body></html>");
doc = Jsoup.parse(textBuffer.toString());
doc.getElementsByTag("body").attr("style", "height:400px;");
doc.getElementsByTag("video").attr("style", "width:100%;max-height:400px;")
.attr("poster", videoPhotoUrl).attr("autoplay", "autoplay")
.attr("controls", "controls").attr("src", videoUrl);
return doc.toString();
} /**
* 从搜狐抓新闻
* @param size
* @param baseUrl
* @param domainName
* @param newsListId
* @param newsContentClass
* @param titleTagOrClass
* @param limitHref
* @param dateTag
* @param needDeleteAlt
* @return
*/
public static ArrayList<News> getNewsFromSouHu(int size,String baseUrl,
String titleTag,String dateTag,String needDeleteAlt){
ArrayList<News> newsList = new ArrayList<News>();
Document doc;
Element element =null;
Element title =null;
News news = null;
try {
doc = Jsoup.connect(baseUrl).timeout(10000).get();
element =doc.getElementsByTag("section").get(2);
element = element.getElementsByClass("headlines").get(0);
Elements elements=element.children();
if(elements!=null&&elements.size()>0){
for(Element ele:elements){
news = new News();
title = ele.select("a").first();
if(title==null){
continue;
}
news.setTitle(title.getElementsByTag(titleTag).text());
if(news.getTitle()==null||news.getTitle().equals("")
||news.getTitle().indexOf("广告")>0||news.getTitle().indexOf("视频")>0){
continue;
}
news.setHref("https://m.sohu.com"+title.attr("href"));
if(dateTag!=null){
String dateStr=ele.select(dateTag).first().text();
news.setDate(dateStr);
}
String newsUrl =news.getHref();
if (isContainChinese(news.getHref())) {
newsUrl = URLEncoder.encode(news.getHref(), "utf-8")
.toLowerCase().replace("%3a", ":").replace("%2f", "/");
}
Document newsDoc = Jsoup.connect(newsUrl).timeout(10000).get();
String text=newsDoc.getElementsByTag("article").html();
if(text.indexOf("未经许可")>0||text.indexOf("禁止转载")>0
||text.indexOf("公众号")>0||text.indexOf("公众账号")>0){
continue;
}
int index=text.indexOf("<p class=\"para\">");
int lastIndex=text.indexOf("<div class=\"expend-wp\"> ");
if(lastIndex>0){
text=text.substring(index,lastIndex);
}else if(index>0){
text=text.substring(index,text.length());
}
text=replaceImgSrcFromDataSrc(text,true,null);
if(text==null||text.length()==0){
continue;
}
StringBuffer textBuffer=new StringBuffer(5);
textBuffer.append("<!DOCTYPE html><html><head>"
+ "<meta name=\"content-type\" content=\"text/html; charset=UTF-8\">");
textBuffer.append("</head><body>");
textBuffer.append(deleteSource(text));
textBuffer.append("</body></html>");
news.setContent(textBuffer.toString());
news.setContent(textBuffer.toString());
System.out.println("标题====="+news.getTitle());
System.out.println("href====="+news.getHref());
System.out.println("content====="+news.getContent());
newsList.add(news);
if(newsList.size()==size){
break;
}
}
}
} catch (Exception e) {
e.printStackTrace();
}
return newsList;
} private static String deleteImg(String text) {
return text.replaceAll("<img [^>]*>", "");
} private static String deleteA(String text) {
return text.replaceAll("<a[^>]*>(.*?)</a>", "");
} private static String deleteSource(String text) {
return text.replaceAll("\\(.*?\\)|\\[.*?]", "");
}
/**
* 删除a标签中的href
* @param content
* @return
*/
public static String removeHref(String content){
Document document = Jsoup.parse(content);
Elements elements = document.select("a[href]");
for(Element el:elements){
el.removeAttr("href");
}
return document.html();
} /**
* 将htmlBody中所有img标签中的src内容替换为原data-src的内容, <br/>
* 如果不报含data-src,则src的内容不会被替换 <br/>
* @param htmlBody html内容
* @param needDeleteAlt 需要剔除的图片的alt信息
* @param imgUrlNeedAddProtocolPrefix 图片的url是否需要添加http协议前缀
* @return 返回替换后的内容
*/
public static String replaceImgSrcFromDataSrc(String htmlBody,
boolean imgUrlNeedAddProtocolPrefix,String needDeleteAlt) {
Document document = Jsoup.parseBodyFragment(htmlBody);
List<Element> nodes = document.select("img");
int nodeLenth = nodes.size();
if(nodeLenth==0){
return htmlBody;
}
for (int i = 0; i < nodeLenth; i++) {
Element e = nodes.get(i);
String dataSrc = e.attr("data-src");
if (isNotBlank(dataSrc)) {
e.attr("src", dataSrc);
e.removeAttr("data-src");
}
String originalSrc = e.attr("original");
if (isNotBlank(originalSrc)) {
e.attr("src", "http:"+originalSrc);
e.removeAttr("originalSrc");
}
String originalHiddenSrc = e.attr("original-hidden");
if (isNotBlank(originalHiddenSrc)) {
e.attr("src", "http:"+originalHiddenSrc);
e.removeAttr("original-hidden");
}
}
if (htmlBody.contains("<html>")) {
if(needDeleteAlt==null&&!imgUrlNeedAddProtocolPrefix){
return document.toString();
}else if(needDeleteAlt==null&&imgUrlNeedAddProtocolPrefix){
return document.toString().replace("src=\"//", "src=\"http://");
}else if(needDeleteAlt!=null&&imgUrlNeedAddProtocolPrefix){
return document.toString().replace("src=\"//", "src=\"http://")
.replace("alt="+needDeleteAlt, "");
}
return document.toString().replace("alt="+needDeleteAlt, "");
} else {
if(needDeleteAlt==null&&!imgUrlNeedAddProtocolPrefix){
return document.select("body>*").toString();
}else if(needDeleteAlt==null&&imgUrlNeedAddProtocolPrefix){
return document.select("body>*").toString().replace("src=\"//", "src=\"http://");
}else if(needDeleteAlt!=null&&imgUrlNeedAddProtocolPrefix){
return document.select("body>*").
toString().replace("src=\"//", "src=\"http://").replace("alt="+needDeleteAlt, "");
}
return document.select("body>*").toString().replace("alt="+needDeleteAlt, "");
} } private static boolean isNotBlank(String str){
if(str == null)
return false;
else if(str.trim().length() == 0)
return false;
else
return true;
}
}
还有一个载体类,用于把趴下来的网页内容进行封装到一个类里面。
package net.sinolbs.ycd.news; /**
* 新闻数据载体
*/
public class News {
private int id;
private String title;
private String href;
private String content;
private String date;
private String photoUrl;
public News() {
} public News(String title, String href, String content, int id) {
this.title = title;
this.content = content;
this.href = href;
this.id = id;
} public int getId() {
return id;
} public void setId(int id) {
this.id = id;
} public String getTitle() {
return title;
} public void setTitle(String title) {
this.title = title;
} public String getHref() {
return href;
} public void setHref(String href) {
this.href = href;
} public String getContent() {
return content;
} public void setContent(String content) {
this.content = content;
} public String getDate() {
return date;
} public void setDate(String date) {
this.date = date;
} public String getPhotoUrl() {
return photoUrl;
} public void setPhotoUrl(String photoUrl) {
this.photoUrl = photoUrl;
} }
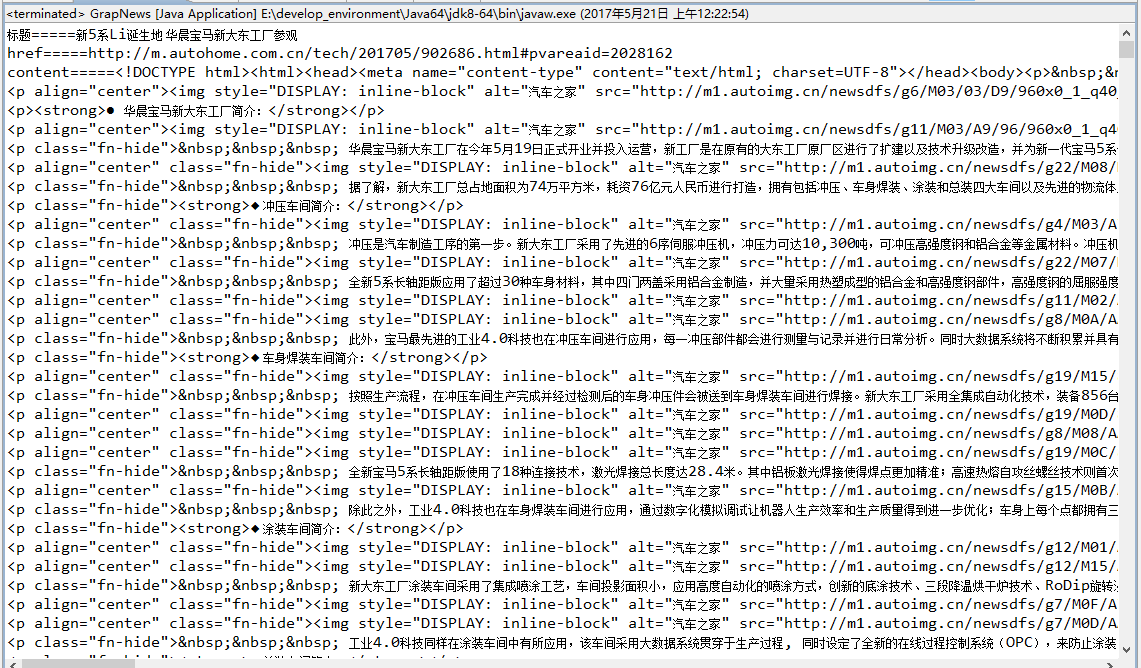
第三步:运行效果
运行GrapNews类(有main方法)。
注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
java爬虫入门--用jsoup爬取汽车之家的新闻的更多相关文章
- python3 爬取汽车之家所有车型数据操作步骤(更新版)
题记: 互联网上关于使用python3去爬取汽车之家的汽车数据(主要是汽车基本参数,配置参数,颜色参数,内饰参数)的教程已经非常多了,但大体的方案分两种: 1.解析出汽车之家某个车型的网页,然后正则表 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
- Java爬虫_资源网站爬取实战
对 http://bestcbooks.com/ 这个网站的书籍进行爬取 (爬取资源分享在结尾) 下面是通过一个URL获得其对应网页源码的方法 传入一个 url 返回其源码 (获得源码后,对源码进 ...
- java爬虫系列第二讲-爬取最新动作电影《海王》迅雷下载地址
1. 目标 使用webmagic爬取动作电影列表信息 爬取电影<海王>详细信息[电影名称.电影迅雷下载地址列表] 2. 爬取最新动作片列表 获取电影列表页面数据来源地址 访问http:// ...
- Python 爬虫实例(15) 爬取 汽车之家(汽车授权经销商)
有人给我吹牛逼,说汽车之家反爬很厉害,我不服气,所以就爬取了一下这个网址. 本片博客的目的是重点的分析定向爬虫的过程,希望读者能学会爬虫的分析流程. 一:爬虫的目标: 打开汽车之家的链接:https: ...
- python爬虫入门10分钟爬取一个网站
一.基础入门 1.1什么是爬虫 爬虫(spider,又网络爬虫),是指向网站/网络发起请求,获取资源后分析并提取有用数据的程序. 从技术层面来说就是 通过程序模拟浏览器请求站点的行为,把站点返回的HT ...
- Java爬虫——B站弹幕爬取
如何通过B站视频AV号找到弹幕对应的xml文件号 首先爬取视频网页,将对应视频网页源码获得 就可以找到该视频的av号aid=8678034 还有弹幕序号,cid=14295428 弹幕存放位置为 h ...
- Python爬虫入门教程 42-100 爬取儿歌多多APP数据-手机APP爬虫部分
1. 儿歌多多APP简单分析 今天是手机APP数据爬取的第一篇案例博客,我找到了一个儿歌多多APP,没有加固,没有加壳,没有加密参数,对新手来说,比较友好,咱就拿它练练手,熟悉一下Fiddler和夜神 ...
- Python 爬虫入门实例(爬取小米应用商店的top应用apk)
一,爬虫是什么? 爬虫就是获取网络上各种资源,数据的一种工具.具体的可以自行百度. 二,如何写简单爬虫 1,获取网页内容 可以通过 Python(3.x) 自带的 urllib,来实现网页内容的下载. ...
随机推荐
- 如何使用chrome自带的Javascript调试工具 【转】
http://zhangyongbluesky.blog.163.com/blog/static/1831941620113155739840/ 将写好的Javascript代码用chrome打开. ...
- CSV 数字转化文本
最近遇到一个Bug问题,csv 数值转化为文本的问题. 数据如下: 运行效果 如下: 大家看到“01720” 前面的0 没有显示出来.怎样才能显示出来了, 这里的csv文件格式也没有什么问题.后来找到 ...
- FastReport.Net 入门
任何一门编程技术入门体验都是以“Hello World”开始的,但我想再复杂一点的“Hello World”,才能算真正的入门. FastReport.Net V1.2.76 ,vs2008 在 ...
- Android传感器应用——重力传感器实现滚动的弹球
一. 问题描述 Android中有多达11种传感器,不同的手机设备支持的传感器类型也不尽相同 1. 重力传感器 GV-sensor 2. 加速度传感器 G-sensor 3. 磁力传感器 M-se ...
- pThreads线程(二) 线程同步--互斥量/锁
互斥量(Mutex)是“mutual exclusion”的缩写.互斥量是实现线程同步,和保护同时写共享数据的主要方法. 互斥量对共享数据的保护就像一把锁.在Pthreads中,任何时候仅有一个线程可 ...
- QuickXDev插件自己主动升级后player no exist
昨晚上QuickXDev插件执行还ok,今天打开电脑启动sublime text2后.右键run with player提示player no exist watermark/2/text/aHR ...
- apache 错误:The system cannot find the file specified.
在启动apache时出现了以下错误信息 Window日志里也记录了此错误信息 而出现此错误的原因是IIS占用了80端口 停止IIS再重新启动apache即可解决 参考: cannot find ...
- 设置Linux中的Mysql不区分表名大小写
1. MySQL数据库的表名在Linux系统下是严格区分大小写的,在Windows系统下开发的程序移植到Linux系统下,如果程序中SQL语句没有严格按照大小写访问数据库表,就可能会出现找不到表的错误 ...
- 【Python】使用hashlib进行MD5和sha1摘要计算
代码: import hashlib hash = hashlib.md5() hash.update('http://www.cnblogs.com/xiandedanteng'.encode('u ...
- 史上最全面的Buffalo WHR-G300N CH v2 刷OpenWrt教程
Buffalo WHR-G300N CH v2 刷OpenWrt.有两种办法.一种是Windows下刷.一种是在linux下使用tftp刷.Buffalo WHR-G300N-CH v2的openwr ...