python_基础算法
本篇主要实现九(八)大排序算法,分别是冒泡排序,插入排序,选择排序,希尔排序,归并排序,快速排序,堆排序,计数排序。希望大家回顾知识的时候也能从我的这篇文章得到帮助。
概述
十种常见排序算法可以分为两大类:
- 非线性时间比较类排序:通过比较来决定元素间的相对次序,由于其时间复杂度不能突破O(nlogn),因此称为非线性时间比较类排序。
- 线性时间非比较类排序:不通过比较来决定元素间的相对次序,它可以突破基于比较排序的时间下界,以线性时间运行,因此称为线性时间非比较类排序。
基础定义
- 稳定:如果a原本在b前面,而a=b,排序之后a仍然在b的前面。
- 不稳定:如果a原本在b的前面,而a=b,排序之后 a 可能会出现在 b 的后面。
- 时间复杂度:对排序数据的总的操作次数。反映当n变化时,操作次数呈现什么规律。
- 空间复杂度:是指算法在计算机内执行时所需存储空间的度量,它也是数据规模n的函数。
图示
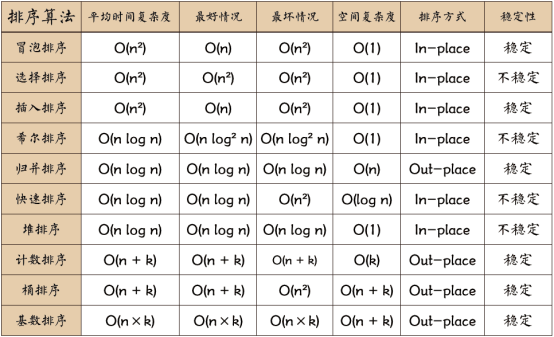
为了防止误导读者,本文所有概念性内容均截取自对应Wiki。
冒泡排序
原理
冒泡排序(Bubble Sort)是一种简单的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。走访数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成。这个算法的名字由来是因为越小的元素会经由交换慢慢“浮”到数列的顶端。
步骤
冒泡排序算法的运作如下:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
代码
def bubble_sort(list):
length = len(list)
# 第一级遍历
for index in range(length):
# 第二级遍历
for j in range(1, length - index):
if list[j - 1] > list[j]:
# 交换两者数据,这里没用temp是因为python 特性元组。
list[j - 1], list[j] = list[j], list[j - 1]
return list
这种排序其实还可以稍微优化一下,添加一个标记,在排序已完成时,停止排序。
def bubble_sort_flag(list):
length = len(list)
for index in range(length):
# 标志位
flag = True
for j in range(1, length - index):
if list[j - 1] > list[j]:
list[j - 1], list[j] = list[j], list[j - 1]
flag = False
if flag:
# 没有发生交换,直接返回list
return list
return list
选择排序
原理
选择排序(Selection sort)是一种简单直观的排序算法。它的工作原理比较好理解,好像是在一堆大小不一的球中进行选择(以从小到大,先选最小球为例)
步骤
1.选择一个基准球
2.将基准球和余下的球进行一一比较,如果比基准球小,则进行交换
3.第一轮过后获得最小的球
4.再挑一个基准球,执行相同的动作得到次小的球
5.继续执行4,知道排序好
代码
def selection_sort(list):
len_li = len(list)
for i in range(0, len_li-1):
min = i
for j in range(i + 1, len_li):
if list[j] < list[min]:
list[min], list[j] = list[j], list[min] return list
插入排序
原理
插入排序(Insertion Sort)是一种简单直观的排序算法。它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
步骤
- 从第一个元素开始,该元素可以认为已经被排序
- 取出下一个元素,在已经排序的元素序列中从后向前扫描
- 如果该元素(已排序)大于新元素,将该元素移到下一位置
- 重复步骤3,直到找到已排序的元素小于或者等于新元素的位置
- 将新元素插入到该位置后
- 重复步骤2~5
代码
def insert_sort(list):
n = len(list)
for i in range(1, n):
# 后一个元素和前一个元素比较
# 如果比前一个小
if list[i] < list[i - 1]:
# 将这个数取出
temp = list[i]
# 保存下标
index = i
# 从后往前依次比较每个元素
for j in range(i - 1, -1, -1):
# 和比取出元素大的元素交换
if list[j] > temp:
list[j + 1] = list[j]
index = j
else:
break
# 插入元素
list[index] = temp
return list
希尔排序
原理
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率
但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位。
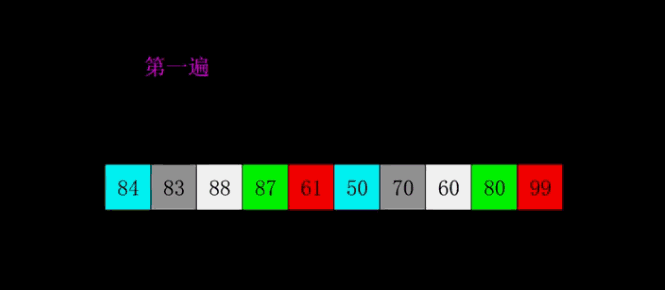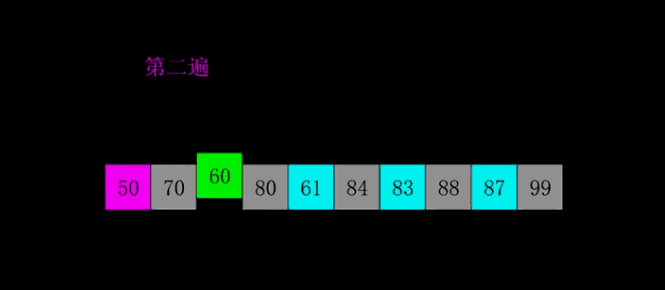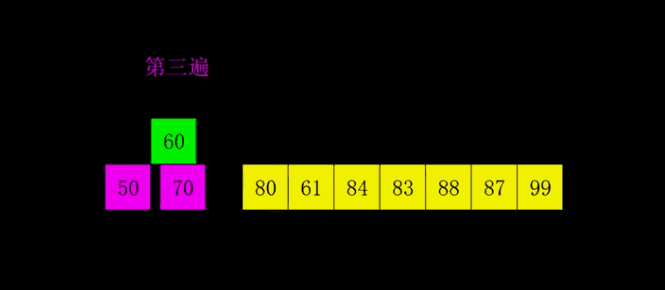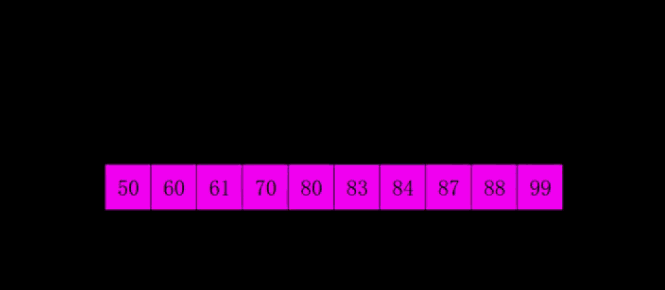
步骤
每次以一定步长(就是跳过等距的数)进行排序,直至步长为1.
代码
def shell_sort(list):
n = len(list)
# 初始步长
gap = n // 2
while gap > 0:
for i in range(gap, n):
# 每个步长进行插入排序
temp = list[i]
j = i
# 插入排序
while j >= gap and list[j - gap] > temp:
list[j] = list[j - gap]
j -= gap
list[j] = temp
# 得到新的步长
gap = gap // 2
return list
步长使用的是Donald Shell的建议,另外步长还可以使用Sedgewick提出的(1, 5, 19, 41, 109,…)。
也可以使用斐波那契数列除去0和1将剩余的数以黄金分区比的两倍的幂进行运算得到的数列
归并排序
原理
归并操作(归并算法),指的是将两个已经排序的序列合并成一个序列的操作。归并排序算法依赖归并操作。
步骤
1.迭代法
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置
- 重复步骤3直到某一指针到达序列尾
- 将另一序列剩下的所有元素直接复制到合并序列尾
递归法
先分开再合并,分开成单个元素,合并的时候按照正确顺序合并 假如我们有一个n个数的数列,下标从0到n-1
首先是分开的过程:
1.我们按照 n//2 把这个数列分成两个小的数列
2.把两个小数列 再按照新长度的一半 把每个小数列都分成两个更小的
。。。一直这样重复,一直到每一个数分开了
比如: 6 5 4 3 2 1
第一次 n=6 n//2=3 分成 6 5 4 3 2 1
第二次 n=3 n//2=1 分成 6 5 4 3 2 1
第三次 n=1的部分不分了
n=2 n//2=1 分成 5 4 2 1 之后是合并排序的过程:
3.分开之后我们按照最后分开的两个数比较大小形成正确顺序后组合绑定
刚刚举得例子 最后一行最后分开的数排序后绑定 变成 4 5 1 2
排序后倒数第二行相当于把最新分开的数排序之后变成 6 4 5 3 12
4.对每组数据按照上次分开的结果,进行排序后绑定
6 和 4 5(两个数绑定了) 进行排序
3 和 1 2(两个数绑定了) 进行排序
排完后 上述例子第一行待排序的 4 5 6 1 2 3 两组数据
5.对上次分开的两组进行排序
拿着 4 5 6 1 2 3两个数组,进行排序,每次拿出每个数列中第一个(最小的数)比较,把较小的数放入结果数组。再进行下一次排序。
每个数组拿出第一个数,小的那个拿出来放在第一位 1 拿出来了, 变成4 5 6 2 3
每个数组拿出第一个书比较小的那个放在下一个位置 1 2被拿出来, 待排序 4 5 6 2
每个数组拿出第一个书比较小的那个放在下一个位置 1 2 3 被拿出来, 待排序 4 5 6
如果一个数组空了,说明另一个数组一定比排好序的数组最后一个大 追加就可以结果 1 2 3 4 5 6
相当于我们每次拿到两个有序的列表进行合并,分别从两个列表第一个元素比较,把小的拿出来,在拿新的第一个元素比较,把小的拿出来
这样一直到两个列表空了 就按顺序合并了两个列表
代码
def merge_sort(li):
# 不断递归调用自己一直到拆分成成单个元素的时候就返回这个元素,不再拆分了
if len(li) == 1:
return li # 取拆分的中间位置
mid = len(li) // 2
# 拆分过后左右两侧子串
left = li[:mid]
right = li[mid:] # 对拆分过后的左右再拆分 一直到只有一个元素为止
# 最后一次递归时候ll和lr都会接到一个元素的列表
# 最后一次递归之前的ll和rl会接收到排好序的子序列
ll = merge_sort(left)
rl = merge_sort(right) # 我们对返回的两个拆分结果进行排序后合并再返回正确顺序的子列表
# 这里我们调用拎一个函数帮助我们按顺序合并ll和lr
return merge(ll, rl) # 这里接收两个列表
def merge(left, right):
# 从两个有顺序的列表里边依次取数据比较后放入result
# 每次我们分别拿出两个列表中最小的数比较,把较小的放入result
result = []
while len(left) > 0 and len(right) > 0:
# 为了保持稳定性,当遇到相等的时候优先把左侧的数放进结果列表,因为left本来也是大数列中比较靠左的
if left[0] <= right[0]:
result.append(left.pop(0))
else:
result.append(right.pop(0))
# while循环出来之后 说明其中一个数组没有数据了,我们把另一个数组添加到结果数组后面
result += left
result += right
return result
快速排序
原理
快速排序使用分治法(Divide and conquer)策略来把一个序列(list)分为两个子序列(sub-lists)。
步骤
- 从数列中挑出一个元素,称为”基准”(pivot),
- 重新排序数列,所有元素比基准值小的摆放在基准前面,所有元素比基准值大的摆在基准的后面(相同的数可以到任一边)。在这个分区结束之后,该基准就处于数列的中间位置。这个称为分区(partition)操作。
- 递归地(recursive)把小于基准值元素的子数列和大于基准值元素的子数列排序。
代码
普通版
def quick_sort(list):
less = []
pivotList = []
more = []
# 递归出口
if len(list) <= 1:
return list
else:
# 将第一个值做为基准
pivot = list[0]
for i in list:
# 将比急转小的值放到less数列
if i < pivot:
less.append(i)
# 将比基准打的值放到more数列
elif i > pivot:
more.append(i)
# 将和基准相同的值保存在基准数列
else:
pivotList.append(i)
# 对less数列和more数列继续进行排序
less = quick_sort(less)
more = quick_sort(more)
return less + pivotList + more
咳咳,下面这段代码出自《Python cookbook 第二版》传说中的三行实现python快速排序。
def qsort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0]
less = [x for x in arr[1:] if x < pivot]
greater = [x for x in arr[1:] if x >= pivot]
return qsort(less) + [pivot] + qsort(greater)
当然还有一行语法糖版本:
def qsort(L):
if len(L) <= 1:
return L
return qsort([lt for lt in L[1:] if lt < L[0]]) + L[0:1] + qsort([ge for ge in L[1:] if ge >= L[0]])
是不是感受到了Python的魅力?
堆排序
原理
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。

步骤
- 创建最大堆:将堆所有数据重新排序,使其成为最大堆
- 最大堆调整:作用是保持最大堆的性质,是创建最大堆的核心子程序
- 堆排序:移除位在第一个数据的根节点,并做最大堆调整的递归运算
代码
def heap_sort(list):
# 创建最大堆
for start in range((len(list) - 2) // 2, -1, -1):
sift_down(list, start, len(list) - 1) # 堆排序
for end in range(len(list) - 1, 0, -1):
list[0], list[end] = list[end], list[0]
sift_down(list, 0, end - 1)
return list # 最大堆调整
def sift_down(lst, start, end):
root = start
while True:
child = 2 * root + 1
if child > end:
break
if child + 1 <= end and lst[child] < lst[child + 1]:
child += 1
if lst[root] < lst[child]:
lst[root], lst[child] = lst[child], lst[root]
root = child
else:
break
计数排序
原理
当输入的元素是n个0到k之间的整数时,它的运行时间是Θ(n + k)。计数排序不是比较排序,排序的速度快于任何比较排序算法。
由于用来计数的数组C的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。例如:计数排序是用来排序0到100之间的数字的最好的算法,但是它不适合按字母顺序排序人名。但是,计数排序可以用在基数排序算法中,能够更有效的排序数据范围很大的数组。
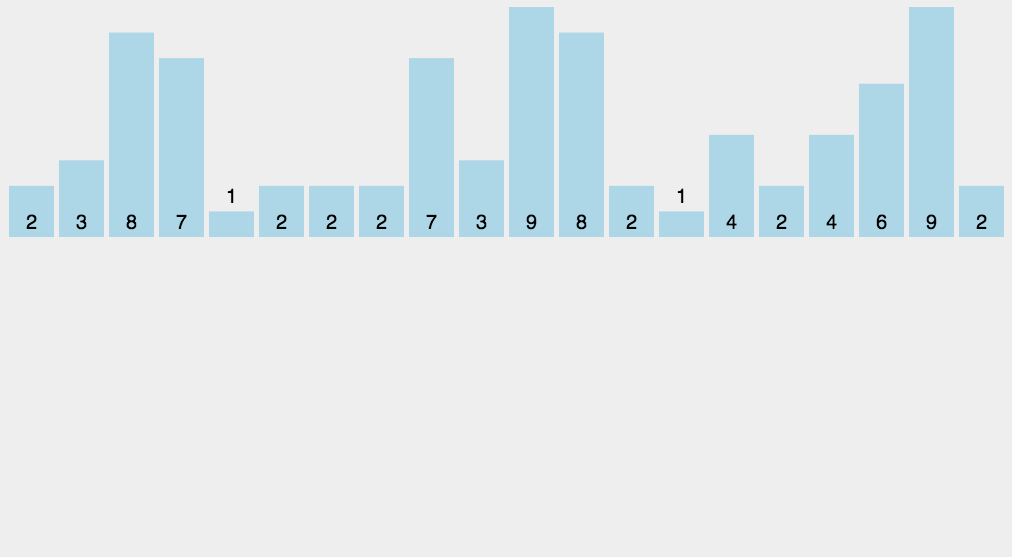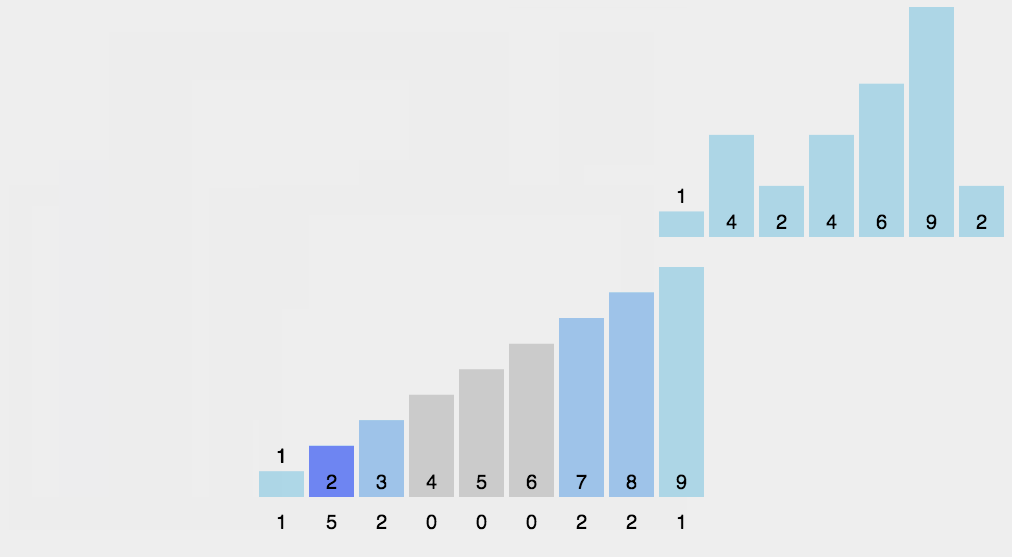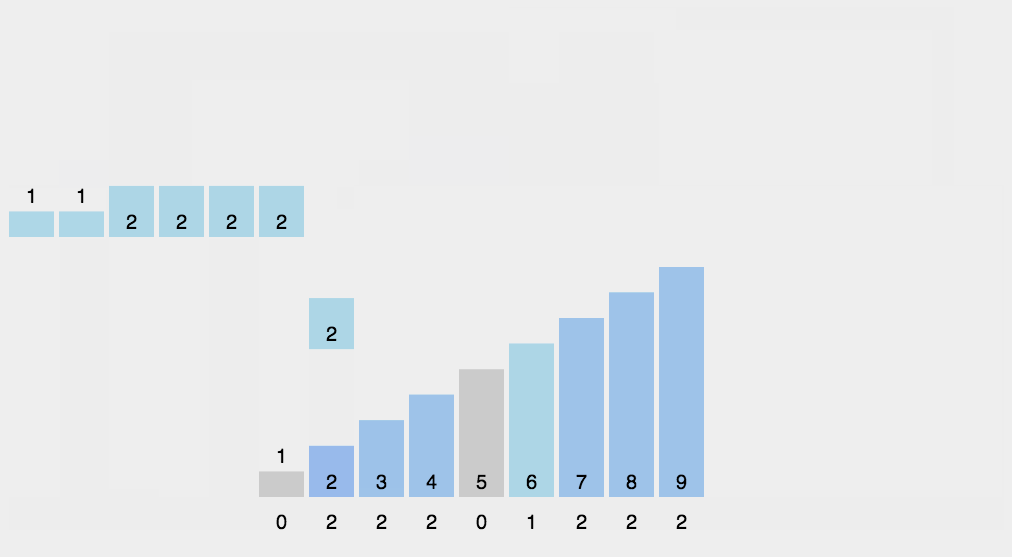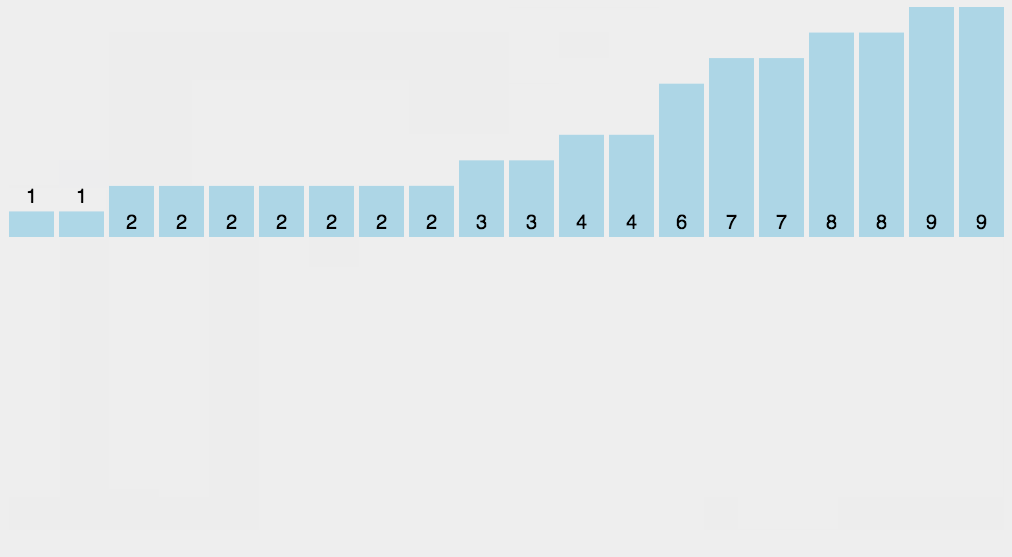
步骤
- 找出待排序的数组中最大和最小的元素
- 统计数组中每个值为i的元素出现的次数,存入数组 C 的第 i 项
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加)
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1
代码
def count_sort(list):
min = 2147483647
max = 0
# 取得最大值和最小值
for x in list:
if x < min:
min = x
if x > max:
max = x
# 创建数组C
count = [0] * (max - min +1)
for index in list:
count[index - min] += 1
index = 0
# 填值
for a in range(max - min+1):
for c in range(count[a]):
list[index] = a + min
index += 1
return list
第九种排序
None?
当然不会
自然就是系统自带的
list.sort()
python_基础算法的更多相关文章
- PHP基础算法
1.首先来画个菱形玩玩,很多人学C时在书上都画过,咱们用PHP画下,画了一半. 思路:多少行for一次,然后在里面空格和星号for一次. <?php for($i=0;$i<=3;$i++ ...
- 10个经典的C语言面试基础算法及代码
10个经典的C语言面试基础算法及代码作者:码农网 – 小峰 原文地址:http://www.codeceo.com/article/10-c-interview-algorithm.html 算法是一 ...
- Java基础算法集50题
最近因为要准备实习,还有一个蓝桥杯的编程比赛,所以准备加强一下算法这块,然后百度了一下java基础算法,看到的都是那50套题,那就花了差不多三个晚自习的时间吧,大体看了一遍,做了其中的27道题,有一些 ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门
1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生,要么不发生,从来不会去考虑某件事情发生的概率有多大,不发生的概率又是多大.而且概率虽然未知,但最起码是一个确定 ...
- 贝叶斯公式由浅入深大讲解—AI基础算法入门【转】
本文转载自:https://www.cnblogs.com/zhoulujun/p/8893393.html 1 贝叶斯方法 长久以来,人们对一件事情发生或不发生的概率,只有固定的0和1,即要么发生, ...
- java入门学习(3)—循环,选择,基础算法,API概念
1.顺序结构:也就是顺着程序的前后关系,依次执行.2.选择分支:利用if..else , / switch(){case [ 这个必须是常量]:}; / if..else if….. ….else.. ...
- Java - 冒泡排序的基础算法(尚学堂第七章数组)
/** * 冒泡排序的基础算法 */ import java.util.Arrays; public class TestBubbleSort1 { public static void main(S ...
- c/c++面试总结---c语言基础算法总结2
c/c++面试总结---c语言基础算法总结2 算法是程序设计的灵魂,好的程序一定是根据合适的算法编程完成的.所有面试过程中重点在考察应聘者基础算法的掌握程度. 上一篇讲解了5中基础的算法,需要在面试之 ...
- c/c++面试指导---c语言基础算法总结1
c语言基础算法总结 1 初学者学习任何一门编程语言都必须要明确,重点是学习编程方法和编程思路,不是学习语法规则,语法规则是为编程实现提供服务和支持.所以只要认真的掌握了c语言编程方法,在学习其它的语 ...
随机推荐
- ARM裸板开发:07_IIC 通过IIC总线接口读写时钟芯片时间参数实现的总结
问题一:程序直接在iRAM内部可正常执行,而程序搬移(Nand ->SDRAM)之后,就不能正常运行了 #define NAND_SECTOR_SIZE 2048 /* 读函数 */ void ...
- SWIFT中获取配置文件路径的方法
在项目中有时候要添加一些配置文件然后在程序中读取相应的配置信息,以下为本人整理的获取项目配置文件(.plist)路径的方法: 1.获取沙盒路径后再APPEND配置文件 func documentsDi ...
- HRBUST单词接龙
题目描述 单词接龙是一个与我们经常玩的成语接龙相类似的游戏,现在我们已知一组单词,且给定一个开头的字母,要求出以这个字母开头的最长的“龙”(每个单词都最多在“龙”中出现两次),在两个单词相连时,其重合 ...
- Android 引入外部模块编译选择
/********************************************************************************* * Android 引入外部模块编 ...
- Redis的持久化策略
Redis 持久化: 提供了多种不同级别的持久化方式:一种是RDB,另一种是AOF. RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照(point-in-time snapshot). AO ...
- [LeetCode&Python] Problem 561. Array Partition I
Given an array of 2n integers, your task is to group these integers into n pairs of integer, say (a1 ...
- 20分钟打造你的Bootstrap站点
来源:http://www.w3cplus.com/css/twitter-bootstrap-tutorial.html 特别声明:此篇文章由白牙根据Leon Revill的英文文章原名<Tw ...
- BZOJ5091: [Lydsy1711月赛]摘苹果【期望DP】
Description 小Q的工作是采摘花园里的苹果.在花园中有n棵苹果树以及m条双向道路,苹果树编号依次为1到n,每条道路的两 端连接着两棵不同的苹果树.假设第i棵苹果树连接着d_i条道路.小Q将会 ...
- ConfigUtil读取配置文件
package utils; import java.util.ResourceBundle; public class ConfigUtil { private static ResourceBun ...
- Windows10中启用原来的Windows照片查看器方法
前言: ============================================== Windows10 版系统自带很多垃圾应用,图片查看器弄得很不好用,还是习惯Windows7的,自 ...