神经网络损失函数中的正则化项L1和L2
神经网络中损失函数后一般会加一个额外的正则项L1或L2,也成为L1范数和L2范数。正则项可以看做是损失函数的惩罚项,用来对损失函数中的系数做一些限制。
正则化描述:
L1正则化是指权值向量w中各个元素的绝对值之和;
L2正则化是指权值向量w中各个元素的平方和然后再求平方根;
一般都会在正则化项之前添加一个系数,这个系数需要用户设定,系数越大,正则化作用越明显。
正则化作用:
L1正则化可以产生稀疏权值矩阵,即产生一个稀疏模型,可以用于特征选择,一定程度上,L1也可以防止过拟合;
L2正则化可以防止模型过拟合(overfitting);
何为稀疏矩阵
稀疏矩阵指的是很多元素为0,只有少数元素是非零值的矩阵。
神经网络中输入的特征数量是庞大的,如何选取有效的特征进行分类是神经网络的重要任务之一,如果神经网络是一个稀疏模型,表示只有少数有效的特征(系数非0)可以通过网络,绝大多数特征会被滤除(系数为0),这些被滤除的特征就是对模型没有贡献的“无关”特征,而少数系数是非0值的特征是我们需要额外关注的有效特征。也就是说,稀疏矩阵可以用于特征选择。
L1正则化是怎么做到产生稀疏模型的?
假设有如下带L1正则化的损失函数:
Loss_0是原始损失函数,L1是加的正则化项,α 是正则化系数,其中 L1 是 模型中权重 w 的绝对值之和。
神经网络训练的目标就是通过随机梯度下降等方法找到损失函数 Loss的最小值,加了L1之后,相当于对原始Loss_0做了一个约束,即在 L1 约束下求Loss_0最小值的解。
对于最简单的情况,假设模型中只有两个权值 w1 和 w2 ,对于梯度下降法,可以分别画出求解 Loss_0 和 L1 过程中的等值线,如下图:
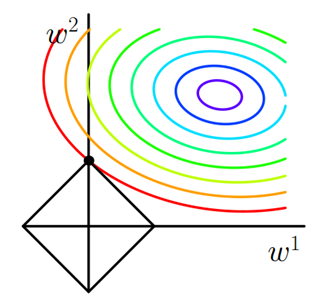
等值线是说在等值线上任一点处(取不同的w1和w2组合),模型计算的结果都是一样的。
图中彩色弧线是Loss_0的等值线,黑色方框是 L1的等值线。在图中,当Loss_0等值线与L1图形首次相交的地方就是一个最优解,这个相交的点刚好是L1的顶点。
注意到L1函数有很多个突出的点,二维情况下有4个,维数越多顶点越多,这些突出的点会比线段上的点有更大的几率首先接触到 Loss_0的等值线,而这些顶点正好对应有很多权值为0的矩阵, 即稀疏矩阵,这也就是为什么L1正则化可以用来产生稀疏矩阵进而用来进行特征选择的原因。
对于L1正则化前的系数α,是用来控制L1图形的大小,α越大,L1中各个系数就相对越小(因为优化目标之一是α×L1的值趋近于0。α大,L1系数取值就会小),L1的图形就越小; α越小,L1中各个系数就相对越大,L1的图形就越大。
L2正则化是怎么做到防止模型过拟合的?
仍以最简单的模型,只有两个权重w1 和 w2为例,Loss_0和L2分别对应的等值线形状如下图:
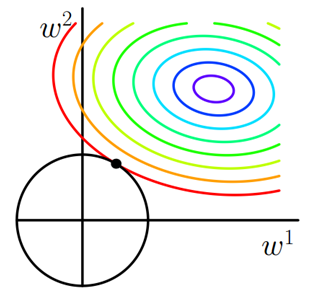
由于L2是w1和w2平方和再开方,所以L2的图形是一个圆。圆形相对方形来说没有顶点,Loss_0 和 L2图形相交使得 w1或者w2等于的概率大大减小,所以L2正则化项不适合产生稀疏矩阵,不适合用来选择特征。
相对来说,模型中所有矩阵系数都比较小的模型具有更强的抗干扰能力,也就是说可以避免过拟合。对于这种小系数的模型,特征会乘以很小的系数,使得特征的波动被压缩,所以泛化能力更好。
L2正则化项的公式是所有权重系数平方之后再开方,所以在每次迭代过程中, 都会使得权重系数在满足最小化Loss_0的基础上,一步一步使得权重系数w1和w2趋向于0,最终得到权重系数很小的矩阵模型,达到防止过拟合的作用。
对于L1正则化项,如果α系数取很大,也会得到系数极小的最优解,这时的L1也具有防止过拟合的作用。
L1和L2中的α系数的作用是类似的,α系数越大,正则化作用越明显(但同时也可能意味着模型越难以收敛),从等值图上直观看就是L图形越小,对应矩阵系数越小。
神经网络损失函数中的正则化项L1和L2的更多相关文章
- 机器学习中正则化项L1和L2的直观理解
正则化(Regularization) 概念 L0正则化的值是模型参数中非零参数的个数. L1正则化表示各个参数绝对值之和. L2正则化标识各个参数的平方的和的开方值. L0正则化 稀疏的参数可以防止 ...
- 正则化项L1和L2
本文从以下六个方面,详细阐述正则化L1和L2: 一. 正则化概述 二. 稀疏模型与特征选择 三. 正则化直观理解 四. 正则化参数选择 五. L1和L2正则化区别 六. 正则化问题讨论 一. 正则化概 ...
- 正则化项L1和L2的区别
https://blog.csdn.net/jinping_shi/article/details/52433975 https://blog.csdn.net/zouxy09/article/det ...
- 深度学习(五)正则化之L1和L2
监督机器学习问题无非就是“minimizeyour error while regularizing your parameters”,也就是在规则化参数的同时最小化误差.最小化误差是为了让我们的模型 ...
- 正则化,L1,L2
机器学习中在为了减小loss时可能会带来模型容量增加,即参数增加的情况,这会导致模型在训练集上表现良好,在测试集上效果不好,也就是出现了过拟合现象.为了减小这种现象带来的影响,采用正则化.正则化,在减 ...
- 机器学习中L1,L2正则化项
搞过机器学习的同学都知道,L1正则就是绝对值的方式,而L2正则是平方和的形式.L1能产生稀疏的特征,这对大规模的机器学习灰常灰常重要.但是L1的求解过程,实在是太过蛋疼.所以即使L1能产生稀疏特征,不 ...
- L1和L2:损失函数和正则化
作为损失函数 L1范数损失函数 L1范数损失函数,也被称之为最小绝对值误差.总的来说,它把目标值$Y_i$与估计值$f(x_i)$的绝对差值的总和最小化. $$S=\sum_{i=1}^n|Y_i-f ...
- 机器学习中的L1、L2正则化
目录 1. 什么是正则化?正则化有什么作用? 1.1 什么是正则化? 1.2 正则化有什么作用? 2. L1,L2正则化? 2.1 L1.L2范数 2.2 监督学习中的L1.L2正则化 3. L1.L ...
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
随机推荐
- WPF基础学习笔记整理 (二) XAML
基础知识: XAML:Extensible Application Markup Language, zammel: 用于实例化.NET对象的标记语言: XMAL使用树形逻辑结构描述UI: BAML: ...
- jq 插件写法
1.一次声明一个函数 $.fn.函数名 = function([options]){} $.fn.red=function(options){ var defaults = { 'color': 'r ...
- 新的请求方式 fetch和axios
参考链接:https://www.javascriptcn.com/read-5840.html axios使用文档: https://www.kancloud.cn/yunye/axios/2348 ...
- 绑定任意格式的XML文档到WPF的TreeView
Code highlighting produced by Actipro CodeHighlighter (freeware)http://www.CodeHighlighter.com/--> ...
- LeetCode--100--相同的树
问题描述: 给定两个二叉树,编写一个函数来检验它们是否相同. 如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的. 示例 1: 输入: 1 1 / \ / \ 2 3 2 3 [1,2, ...
- UVA557 汉堡 Burger
题面 https://www.luogu.org/problemnew/show/UVA557 这里顺便整理一下二维格点随机游走问题. 遇到这种问题时,需注意分母的计算问题. 设x为起点到终点的距离. ...
- President's Path CodeForces - 416E (最短路,计数)
大意: 给定无向图, 求任意两点间所有最短路经过的边数 刚开始想先用floyd跑出最短路, 然后在DAG上DP, 交了1发, 发现会算重复 贴一下题解的做法 #include <iostream ...
- 『PyTorch』第二弹重置_Tensor对象
『PyTorch』第二弹_张量 Tensor基础操作 简单的初始化 import torch as t Tensor基础操作 # 构建张量空间,不初始化 x = t.Tensor(5,3) x -2. ...
- scrapy微信爬虫使用总结
scrapy+selenium+Chrome+微信公众号爬虫 概述 1.微信公众号爬虫思路: 参考:记一次微信公众号爬虫的经历 2.scrapy框架图 3.scrapy经典教程 参考: python ...
- hdu多校(二) 1004 1007 1010
Game Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Submis ...